HBase学习笔记
HBase![]()
一、概述
HBase是一个依据Hadoop的数据库,它可靠、分布式适合结构化大数据存储,是用来存储大数据集的存储系统,建立在Hadoop的HDFS的基础之上。
HBase是Google开源实现,它开源,分布式,数据多 版本,基于列存储的非关系型数据库,建立在Hadoop的HDFS的基础之上。
HDFS来源Google的GFS
MapReduce来源Google的MapReduce
HBase来源Google的bigTable
关系型数据库:Oracle,MySQL
非关系型数据库(弱化事务):redis
列存储和行存储
列存储和行存储是表中的数据在存储介质中的组织方式
【个人想:查询用非关系型,增改用关系型】
-
传统的关系型数据(行存储):Oracle,MySQL,db2,SQLServer等
-
1 张三 男 2 李四 男
-
优点:增(insert,直接追加)改(update,在一块好操作)【删呢?个人感觉也快】快(高效)
-
缺点:指定字段的查询(投影查询)需要查询所有数据再保存指定列,造成很多无效的IO【效率低】
-
操作事务要求高的增删改(大数据主要是查)
-
-
非关系型数据库(列存储):HBase等
-
按照列为单位进行数据的组织和管理
- 1 2 3 4 5 张三 李四 王五…
-
优点:
-
1、投影查询效率极高,不会浪费磁盘的IO(适合结构化的大数据处理,京东的超过三个月历史交易订单,滴滴每个订单的地理位置信息【行走路线】)
-
2、列数据类型一致,进行有效的数据压缩,减少磁盘空间的浪费
-
3、列即是索引(索引不是越多越好)
-
4、擅长结构化的大数据存储,效率比较高(弱化事务)
-
5、数据为NUll,列式存储系统不会占用实际的存储空间(关系型数据库,类型导致将存储空间沾满)
-
-
缺点:数据的插入和修改比较麻烦
-
HBase的数据模型(DataModel)(极为重要)
Big table
-
1、主键:RowKey(关系型数据库PrimaryKey),底层存储是字节数组byte[],获取数据的唯一标识,不能重复,默认按照字典顺序进行排序
-
2、列簇Column Family(列族):存放业务相似或者功能相近的多个列的集合
-
3、单元格Cell:实际存放数据(RowKey+Column Family+column定义一个单元格)
-
4、多版本Versions:一个Cell允许有多个数据版本,一个Cell默认有一个多版本,HBase默认会将最新版本的数据返回给用户
-
5、版本号时间戳timestamp:系统当前时间戳,默认将最新时间戳的数据返回给用户
-
6、列簇中的一个字段,用来存放某一类别的数据
-
一个BigTable由行构成
一行记录(rowKey)由列簇构成,列簇(通常一到三个)由列构成
列代表一列数据
单元格(rowkey+cf+column+version)
多版本:时间戳
HBase没有join,where,group by,order by
特点
-
大:一个表可以有上亿行,上百万列
-
面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
-
结构稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
-
无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列,结构非常灵活。
-
数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
-
数据类型单一:HBase中的数据在底层存储时都是byte[],没有类型,可以存放任意类型的数据。
二、基本使用
环境搭建
伪分布式集群
准备工作
-
保证HDFS集群运行正常
-
保证ZooKeeper集群运行正常
[root@hadoop ~]# jps 83920 SecondaryNameNode 83602 NameNode 83698 DataNode 2548 QuorumPeerMain
安装及配置
[root@hadoop ~]# tar -zxf hbase-1.2.4-bin.tar.gz -C /usr
-
conf/hbase-site.xml[root@hadoop ~]# vi /usr/hbase-1.2.4/conf/hbase-site.xml<property> <name>hbase.rootdirname> <value>hdfs://hadoop:9000/hbasevalue> property> <property> <name>hbase.cluster.distributedname> <value>truevalue> property> <property> <name>hbase.zookeeper.quorumname> <value>hadoopvalue> property> <property> <name>hbase.zookeeper.property.clientPortname> <value>2181value> property> -
conf/regionservers[root@hadoop ~]# vi /usr/hbase-1.2.4/conf/regionservers hadoop
修改环境变量
[root@hadoop hbase-1.2.4]# vi ~/.bashrc
# 将之前的环境变量配置删除 添加如下的环境变量配置
HBASE_MANAGES_ZK=false
HBASE_HOME=/usr/hbase-1.2.4
HADOOP_HOME=/usr/hadoop-2.6.0
JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin::$HBASE_HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
export HADOOP_HOME
export HBASE_HOME
export HBASE_MANAGES_ZK
[root@hadoop hbase-1.2.4]# source ~/.bashrc
启动服务
[root@hadoop hbase-1.2.4]# start-hbase.sh
验证HBase服务是否正常
方法一:
[root@hadoop hbase-1.2.4]# jps
83920 SecondaryNameNode
85104 HRegionServer # HBase集群的从节点
84963 HMaster # HBase集群的主节点
83602 NameNode
83698 DataNode
2548 QuorumPeerMain
85516 Jps
方法二:
http://hadoop:16010/master-status
方法三:

指令操作
使用客户端指令连接hbase server
[root@hadoop hbase-1.2.4]# hbase shell
在命令窗口使用help指令查看帮助说明
hbase(main):007:0> help "get" # help "命令" 查看指定命令的帮助说明
hbase(main):007:0> help "general" # help "命令组" 查看指定命令组下的命令帮助说明
COMMAND GROUPS:
Group name: general # 通用指令
Commands: status, table_help, version, whoami
Group name: ddl # 表操作指令
Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, locate_region, show_filters
Group name: namespace # 类似于mysql的数据库 组织管理表
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
Group name: dml # 数据的CRUD
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
General指令
-
status
hbase(main):010:0* status 1 active master, 0 backup masters, 1 servers, 0 dead, 2.0000 average load -
version
hbase(main):013:0* version 1.2.4, rUnknown, Wed Feb 15 18:58:00 CST 2017 -
whoami
hbase(main):014:0> whoami root (auth:SIMPLE) groups: root
NameSpace指令
Namespace非常类似于mysql中的数据库,是用来组织管理HBase表的,在HBase有一个默认的Namespace叫做default
-
alter_namespace
hbase(main):022:0* alter_namespace 'baizhi',{METHOD=>'set', 'AUTHOR'=>'GAOZHY'} 0 row(s) in 0.0440 seconds -
create_namespace
hbase(main):017:0> create_namespace 'baizhi' 0 row(s) in 0.0690 seconds -
describe_namespace
hbase(main):019:0> describe_namespace 'baizhi' DESCRIPTION {NAME => 'baizhi'} 1 row(s) in 0.0210 seconds -
drop_namespace
hbase(main):026:0> drop_namespace 'baizhi' 0 row(s) in 0.0460 seconds -
list_namespace
hbase(main):027:0> list_namespace NAMESPACE default hbase 2 row(s) in 0.0480 seconds -
list_namespace_tables
hbase(main):025:0> list_namespace_tables 'hbase' TABLE meta namespace 2 row(s) in 0.0280 seconds
DDL指令
表相关的操作
-
创建表:create
# 1. 语法: create '表名','列簇1',’列簇2‘... # 2. 语法: create 'namespace:表名',{NAME=>'列簇名',VERSIONS=>Cell允许出现的最多版本} hbase(main):002:0> create 't_user','cf1' 0 row(s) in 1.6240 seconds => Hbase::Table - t_user hbase(main):003:0> create 't_order',{NAME=>'cf1',VERSIONS=>3} 0 row(s) in 1.3200 seconds -
展示列表: list
=> Hbase::Table - t_order hbase(main):004:0> list TABLE t_order t_user 2 row(s) in 0.0510 seconds => ["t_order", "t_user"] -
修改表:alter
hbase(main):005:0* alter 't_user',NAME=>'cf1',TTL=>1800 Updating all regions with the new schema... 1/1 regions updated. Done. 0 row(s) in 2.3520 seconds hbase(main):006:0> describe 't_user' Table t_user is ENABLED t_user COLUMN FAMILIES DESCRIPTION {NAME => 'cf1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCOD ING => 'NONE', TTL => '1800 SECONDS (30 MINUTES)', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSI ZE => '65536', REPLICATION_SCOPE => '0'} 1 row(s) in 0.0340 seconds hbase(main):008:0* alter 't_user',{NAME=>'cf1',VERSIONS=>3} Updating all regions with the new schema... 1/1 regions updated. Done. 0 row(s) in 1.9960 seconds hbase(main):009:0> describe 't_user' Table t_user is ENABLED t_user COLUMN FAMILIES DESCRIPTION {NAME => 'cf1', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCOD ING => 'NONE', TTL => '1800 SECONDS (30 MINUTES)', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSI ZE => '65536', REPLICATION_SCOPE => '0'} 1 row(s) in 0.0370 seconds -
描述表:describe
hbase(main):001:0> describe 't_user' Table t_user is ENABLED t_user COLUMN FAMILIES DESCRIPTION {NAME => 'cf1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCOD ING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REP LICATION_SCOPE => '0'} -
禁用表:disable, disable_all
hbase(main):011:0* disable 't_user' 0 row(s) in 2.3580 seconds -
删除表:drop, drop_all
# 删除表时 首先需要禁用表 hbase(main):018:0> drop 't_user' ERROR: Table t_user is enabled. Disable it first. Here is some help for this command: Drop the named table. Table must first be disabled: hbase> drop 't1' hbase> drop 'ns1:t1' hbase(main):019:0> disable 't_user' 0 row(s) in 2.2830 seconds hbase(main):020:0> drop 't_user' 0 row(s) in 1.3090 seconds -
启动表:enable, enable_all
hbase(main):017:0* enable 't_user' 0 row(s) in 1.3400 seconds -
判断表是否存在:exists
hbase(main):021:0> exists 't_user' Table t_user does not exist 0 row(s) in 0.0240 seconds hbase(main):022:0> exists 't_order' Table t_order does exist 0 row(s) in 0.0240 seconds -
是不是:is_disabled, is_enabled
hbase(main):023:0> is_disabled 't_order' false 0 row(s) in 0.0150 seconds
DML指令(重点)
BigTable中的数据的增删改查操作
-
获得总记录数:count
hbase(main):051:0> count 'default:t_order' 2 row(s) in 0.0570 seconds => 2 -
删除: delete, deleteall
# delete指令用来删除某一个单元格数据 # deleteall 删除一行数据的 hbase(main):053:0> delete 't_order','order102','cf1:count' 0 row(s) in 0.0470 seconds hbase(main):054:0> get 'default:t_order','order102',{COLUMN=>'cf1',VERSIONS=>3} COLUMN CELL cf1:name timestamp=1566374163173, value=vivo cf1:name timestamp=1566374139746, value=oppo cf1:name timestamp=1566374045248, value=mix2s 3 row(s) in 0.0440 seconds hbase(main):055:0> delete 't_order','order102','cf1:name',1566374045248 0 row(s) in 0.0340 seconds hbase(main):056:0> get 'default:t_order','order102',{COLUMN=>'cf1',VERSIONS=>3} COLUMN CELL cf1:name timestamp=1566374163173, value=vivo cf1:name timestamp=1566374139746, value=oppo 2 row(s) in 0.0160 seconds hbase(main):059:0> deleteall 't_order','order102' 0 row(s) in 0.0140 seconds hbase(main):060:0> get 'default:t_order','order102',{COLUMN=>'cf1',VERSIONS=>3} COLUMN CELL 0 row(s) in 0.0220 seconds -
获得数据:get
# get 'namespace:table','rowkey num' hbase(main):033:0* get 'default:t_order','order101' COLUMN CELL cf1:count timestamp=1566373554307, value=2 cf1:name timestamp=1566373502504, value=iphone cf1:price timestamp=1566373537106, value=1999 3 row(s) in 0.0560 seconds hbase(main):034:0> get 'default:t_order','order102' COLUMN CELL cf1:count timestamp=1566373582394, value=1 cf1:name timestamp=1566373615024, value=HUAWEI P30 # 查看指定列簇中的所有列的数据 hbase(main):037:0> get 'default:t_order','order102',{COLUMN=>'cf1'} # 获取多版本数据 hbase(main):047:0> get 'default:t_order','order102',{COLUMN=>'cf1',VERSIONS=>3} COLUMN CELL cf1:count timestamp=1566373582394, value=1 cf1:name timestamp=1566374163173, value=vivo cf1:name timestamp=1566374139746, value=oppo cf1:name timestamp=1566374045248, value=mix2s # 获取指定版本的单元格数据 hbase(main):048:0> get 'default:t_order','order102',{COLUMN=>'cf1',TIMESTAMP=>1566374045248 ,VERSIONS=>3} COLUMN CELL cf1:name timestamp=1566374045248, value=mix2s 1 row(s) in 0.0240 seconds -
新增(修改)数据:put
hbase(main):026:0* put 'default:t_order','order101','cf1:name','iphone' 0 row(s) in 0.1220 seconds hbase(main):027:0> put 'default:t_order','order101','cf1:price',1999 0 row(s) in 0.0370 seconds hbase(main):028:0> put 'default:t_order','order101','cf1:count',2 0 row(s) in 0.0330 seconds hbase(main):029:0> put 'default:t_order','order102','cf1:count',1 0 row(s) in 0.0230 seconds hbase(main):030:0> put 'default:t_order','order102','cf1:name','HUAWEI P30' -
扫描表: scan
# 类似于查询所有 hbase(main):063:0> scan 't_order' ROW COLUMN+CELL order101 column=cf1:count, timestamp=1566373554307, value=2 order101 column=cf1:name, timestamp=1566373502504, value=iphone order101 column=cf1:price, timestamp=1566373537106, value=1999 order103 column=cf1:name, timestamp=1566374793825, value=Apple Watch -
截断表:truncate
截断指的删除表中的所有数据
hbase(main):065:0> truncate 't_order' truncate truncate_preserve hbase(main):065:0> truncate 't_order' Truncating 't_order' table (it may take a while): - Disabling table... - Truncating table... 0 row(s) in 3.5150 seconds hbase(main):066:0> scan 't_order' ROW COLUMN+CELL 0 row(s) in 0.1550 seconds
JAVA API
Maven依赖
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>1.2.4version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-commonartifactId>
<version>1.2.4version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-protocolartifactId>
<version>1.2.4version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>1.2.4version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
测试代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class HBaseClientTest {
// 管理员对象(负责DDL操作)
private Admin admin;
// 连接对象(负责DML操作)
private Connection connection;
@Before
public void doBefore() throws IOException {
// 配置对象
Configuration configuration = HBaseConfiguration.create();
// 声明HBase的连接参数
// HBase集群的入口信息 保存在ZK
configuration.set(HConstants.ZOOKEEPER_QUORUM, "hadoop:2181");
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}
/**
* 创建namespace
* @throws IOException
*/
@Test
public void testCreateNamespace() throws IOException {
NamespaceDescriptor namespaceDescriptor = NamespaceDescriptor.create("baizhi").addConfiguration("author", "gaozhy").build();
admin.createNamespace(namespaceDescriptor);
}
/**
* 创建table
*/
@Test
public void testCreateTable() throws IOException {
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("baizhi:t_user"));
HColumnDescriptor cf1 = new HColumnDescriptor("cf1");
cf1.setMaxVersions(5); // cell最多保留5个历史版本
HColumnDescriptor cf2 = new HColumnDescriptor("cf2");
cf2.setTimeToLive(3600); // ttl=1hours
hTableDescriptor.addFamily(cf1);
hTableDescriptor.addFamily(cf2);
admin.createTable(hTableDescriptor);
}
/**
* 新增(修改)数据 :
* put指令: put 'namespace:table','rowkey','cf1:name','value'
* @throws IOException
*/
@Test
public void testInsert() throws IOException {
Table table = connection.getTable(TableName.valueOf("baizhi:t_user"));
// Put put = new Put("user101".getBytes()); // rowkey
Put put = new Put(Bytes.toBytes("user103")); // HBase为了简化字节操作,提供了工具类 Bytes
put.addColumn(Bytes.toBytes("cf1"),Bytes.toBytes("name"),Bytes.toBytes("小胖子"));
table.put(put);
}
/**
* 获得数据:
* get指令:get 'namespace:table','rowkey','cf:column'
*/
@Test
public void testSelect() throws IOException {
Table table = connection.getTable(TableName.valueOf("baizhi:t_user"));
Get get = new Get("user101".getBytes());
// 查询指定单元格数据
// get.addColumn("cf1".getBytes(),"name".getBytes());
// 查指定列簇所有列数据
// get.addFamily("cf1".getBytes())
Result result = table.get(get);
String name = Bytes.toString(result.getValue(Bytes.toBytes("cf1"), Bytes.toBytes("name")));
System.out.println(name);
}
/**
* 测试删除数据:
* delete
* deleteall
*/
@Test
public void testDelete() throws IOException {
Table table = connection.getTable(TableName.valueOf("baizhi:t_user"));
Delete delete = new Delete(Bytes.toBytes("user101"));
ArrayList<Delete> list = new ArrayList<Delete>();
list.add(delete);
table.delete(list);
}
/**
* 扫描表
* scan 'namespace:table'
*/
@Test
public void testScan() throws IOException {
Table table = connection.getTable(TableName.valueOf("baizhi:t_user"));
Scan scan = new Scan();
// 包含start 不包含stop
scan.setStartRow(Bytes.toBytes("user101"));
scan.setStopRow(Bytes.toBytes("user103"));
ResultScanner rs = table.getScanner(scan);
Iterator<Result> iterator = rs.iterator();
while(iterator.hasNext()){
Result result = iterator.next();
String rowkey = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue(Bytes.toBytes("cf1"), Bytes.toBytes("name")));
System.out.println(rowkey + " | " +name);
}
}
@After
public void doAfter() throws IOException {
if(admin != null) admin.close();
if(connection != null) connection.close();
}
}
作业
- 使用HBase作为数据存储,完成用户信息的增删改查
- 预习明天要讲的内容
三、HBase On MapReduce
需求:某电商系统,统计计算用户年度消费订单
订单号:购买时间+随机数
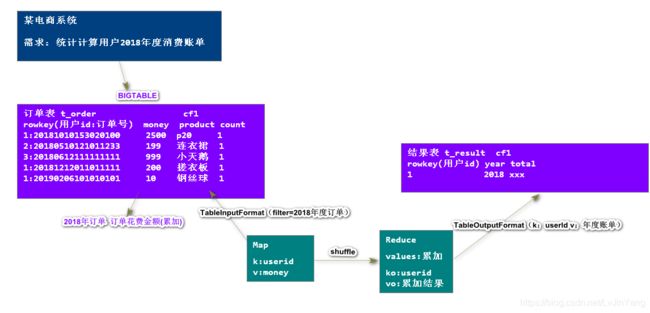
Maven依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.6.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.6.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-commonartifactId>
<version>2.6.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-coreartifactId>
<version>2.6.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-jobclientartifactId>
<version>2.6.0version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>1.2.4version>
dependency>
dependencies>
测试数据
@Test
public void testInsertSampleData() throws IOException {
Table table = connection.getTable(TableName.valueOf("t_order"));
Put put1 = new Put(Bytes.toBytes("1:20181010153020100"));
put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(2500.0D));
put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("p20"));
put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put2 = new Put(Bytes.toBytes("2:20180510121011233 "));
put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(199.0D));
put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("连衣裙"));
put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put3 = new Put(Bytes.toBytes("3:20180612111111111"));
put3.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(999.9D));
put3.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("小天鹅洗衣机"));
put3.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put4 = new Put(Bytes.toBytes("1:20181212011011111"));
put4.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(200.0D));
put4.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("搓衣板"));
put4.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put5 = new Put(Bytes.toBytes("1:20190206101010101"));
put5.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(10D));
put5.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("钢丝球"));
put5.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put6 = new Put(Bytes.toBytes("2:20180306101010101"));
put6.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(9.9D));
put6.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("丝袜"));
put6.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
ArrayList<Put> puts = new ArrayList<Put>();
puts.add(put1);
puts.add(put2);
puts.add(put3);
puts.add(put4);
puts.add(put5);
puts.add(put6);
table.put(puts);
}
创建输入表
@Test
public void testCreateOrderTable() throws IOException {
boolean exists = admin.tableExists(TableName.valueOf("t_order"));
if (exists) {
admin.disableTable(TableName.valueOf("t_order"));
admin.deleteTable(TableName.valueOf("t_order"));
}
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("t_order"));
HColumnDescriptor cf1 = new HColumnDescriptor("cf1");
hTableDescriptor.addFamily(cf1);
admin.createTable(hTableDescriptor);
}
创建输出表
hbase(main):001:0> create 't_result','cf1'
自定义Mapper
package com.baizhi.hbmr;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class HBMap extends TableMapper<Text, DoubleWritable>{
/**
*
* @param key rowKey
* @param value 一行数据
* @param context 上下文对象
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
String rowKey = Bytes.toString(key.get());
String userId = rowKey.split(":")[0];
double money = Bytes.toDouble(value.getValue("cf1".getBytes(), "money".getBytes()));
context.write(new Text(userId),new DoubleWritable(money));
}
}
自定义Reducer
package com.baizhi.hbmr;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import java.io.IOException;
import java.util.Iterator;
public class HBReducer extends TableReducer<Text, DoubleWritable, NullWritable> {
/**
*
* @param key userId
* @param values money集合
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
Double sum = 0d;
Iterator<DoubleWritable> iterator = values.iterator();
while (iterator.hasNext()){
sum+=iterator.next().get();
}
Put put = new Put(key.toString().getBytes());
put.addColumn("cf1".getBytes(),"total".getBytes(), Bytes.toBytes(sum));
context.write(null,put);
}
}
自定义初始化类
package com.baizhi.hbmr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.RegexStringComparator;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import javax.swing.*;
import java.io.IOException;
public class HBApplication {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = HBaseConfiguration.create();
configuration.set(HConstants.ZOOKEEPER_QUORUM,"hadoop:2181");
Job job = Job.getInstance(configuration, "order");
job.setJarByClass(HBApplication.class);
job.setInputFormatClass(TableInputFormat.class);
job.setOutputFormatClass(TableOutputFormat.class);
//map任务初始化
Scan scan = new Scan();
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^.*:2018.*$"));
scan.setFilter(rowFilter);
TableMapReduceUtil.initTableMapperJob(TableName.valueOf("t_order"),scan,HBMap.class, Text.class, DoubleWritable.class,job);
TableMapReduceUtil.initTableReducerJob("t_result",HBReducer.class,job);
job.waitForCompletion(true);
}
}
本地计算+查看计算结果
//查看一号用户的消费账单
@Test
public void testGetOrderTotal() throws IOException {
Table table = connection.getTable(TableName.valueOf("t_result"));
Result result = table.get(new Get(Bytes.toBytes("1")));
double total = Bytes.toDouble(result.getValue(Bytes.toBytes("cf1"), Bytes.toBytes("total")));
System.out.println("1号用户在2018年的年度消费账单为:"+total);
}
//查所有的总消费
@Test
public void testSelectAll() throws IOException {
Table table = connection.getTable(TableName.valueOf("t_result"));
Scan scan = new Scan();
ResultScanner results = table.getScanner(scan);
results.forEach(s-> {
byte[] value = s.getValue("cf1".getBytes(), "total".getBytes());
System.out.println(Bytes.toDouble(value));
});
}
完整版测试
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.ArrayList;
public class TestTable {
private Connection connection;
private Admin admin;
@Before
public void doBefore() throws IOException {
//调用静态方法创建配置对象
Configuration configuration = HBaseConfiguration.create();
configuration.set(HConstants.ZOOKEEPER_QUORUM,"hadoop:2181");
//从连接工厂中获得连接
connection = ConnectionFactory.createConnection(configuration);
admin = this.connection.getAdmin();
}
@After
public void doAfter() throws IOException {
if(admin!=null ) admin.close();
if(connection!=null) connection.close();
}
@Test
public void testCreateOrderTable() throws IOException {
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("t_order"));
tableDescriptor.addFamily(new HColumnDescriptor("cf1"));
admin.createTable(tableDescriptor);
}
@Test
public void testInsertSampleData() throws IOException {
Table table = connection.getTable(TableName.valueOf("t_order"));
Put put1 = new Put(Bytes.toBytes("1:20181010153020100"));
put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(2500.0D));
put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("p20"));
put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put2 = new Put(Bytes.toBytes("2:20180510121011233 "));
put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(199.0D));
put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("连衣裙"));
put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put3 = new Put(Bytes.toBytes("3:20180612111111111"));
put3.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(999.9D));
put3.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("小天鹅洗衣机"));
put3.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put4 = new Put(Bytes.toBytes("1:20181212011011111"));
put4.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(200.0D));
put4.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("搓衣板"));
put4.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put5 = new Put(Bytes.toBytes("1:20190206101010101"));
put5.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(10D));
put5.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("钢丝球"));
put5.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
Put put6 = new Put(Bytes.toBytes("2:20180306101010101"));
put6.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("money"), Bytes.toBytes(9.9D));
put6.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("product"), Bytes.toBytes("丝袜"));
put6.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("count"), Bytes.toBytes(1));
ArrayList<Put> puts = new ArrayList<Put>();
puts.add(put1);
puts.add(put2);
puts.add(put3);
puts.add(put4);
puts.add(put5);
puts.add(put6);
table.put(puts);
}
@Test
public void testGetOrderTotal() throws IOException {
Table table = connection.getTable(TableName.valueOf("t_result"));
Result result = table.get(new Get(Bytes.toBytes("1")));
double total = Bytes.toDouble(result.getValue(Bytes.toBytes("cf1"), Bytes.toBytes("total")));
System.out.println("1号用户在2018年的年度消费账单为:"+total);
}
//查所有的总消费
@Test
public void testSelectAll() throws IOException {
Table table = connection.getTable(TableName.valueOf("t_result"));
Scan scan = new Scan();
ResultScanner results = table.getScanner(scan);
results.forEach(s-> {
byte[] value = s.getValue("cf1".getBytes(), "total".getBytes());
System.out.println(Bytes.toDouble(value));
});
}
}
远程计算
开发完成HBase On MapReduce应用运行在远程的YARN集群中运行
查看集群运行状态
[root@hadoop ~]# jps
3424 QuorumPeerMain
51473 ResourceManager#YARN
16226 SecondaryNameNode
42563 Main
15988 NameNode
17428 HRegionServer#HBase
17290 HMaster#HBase
51852 Jps
51774 NodeManager#YARN
16079 DataNode
运行jar包
[root@hadoop ~]# hadoop jar hbase_day2.jar com.baizhi.hbmr.HBApplication
将应用打成JAR包
运行时依赖
应用在YARN集群中运行时需要依赖HBase第三方的JAR包

解决方案
-
将HBase应用依赖的jar包拷贝到
share/hadoop/yarn/lib -
配置
HADOOP_CLASSPATH环境变量[root@hadoop ~]# vi .bashrc # 在配置文件的末尾添加如下的第三方依赖的路径 export HADOOP_CLASSPATH=/usr/hbase-1.2.4/lib/* [root@hadoop ~]# source .bashrc
四、HBase完全分布式集群
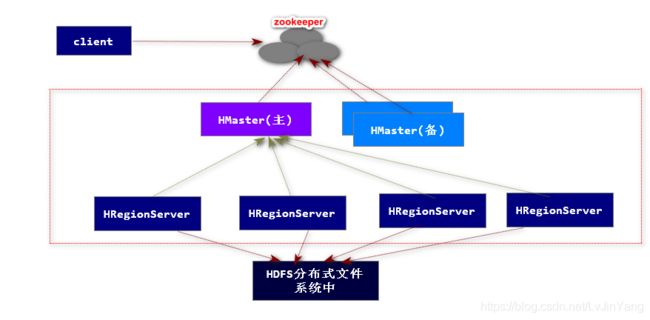
准备工作
-
启动之前搭建的Hadoop完全分布式集群
-
ZooKeeper集群服务运行正常
确认zookeper服务是否正常:方法一 [root@nodex ~]# jps 1777 QuorumPeerMain 1811 Jps -
HDFS集群服务运行正常
确认HDFS集群是否正常 http://node1IP:50070 http://node2IP:50070
环境搭建
-
时钟同步
注意: HBase集群节点和节点之间的时间误差最大允许为30s,如果大于30s需要对集群内的节点进行时间同步
[root@nodex ~]# date 2019年 08月 20日 星期二 17:13:53 CST [root@nodex ~]# date -s '2019-08-22 15:49:00' 2019年 08月 22日 星期四 15:49:00 CST [root@nodex ~]# date 2019年 08月 22日 星期四 15:49:03 CST [root@nodex ~]# clock -w -
上传HBase安装包
[root@node1 ~]# scp hbase-1.2.4-bin.tar.gz root@node2:~ hbase-1.2.4-bin.tar.gz 100% 74MB 100.8MB/s 00:00 [root@node1 ~]# scp hbase-1.2.4-bin.tar.gz root@node3:~ hbase-1.2.4-bin.tar.gz -
解压缩安装HBase
[root@nodex ~]# tar -zxf hbase-1.2.4-bin.tar.gz -C /usr -
修改配置文件
hbase-site.xml[root@nodex ~]# vi /usr/hbase-1.2.4/conf/hbase-site.xml <property> <name>hbase.rootdirname> <value>hdfs://mycluster/hbasevalue> property> <property> <name>hbase.cluster.distributedname> <value>truevalue> property> <property> <name>hbase.zookeeper.quorumname> <value>node1,node2,node3value> property> <property> <name>hbase.zookeeper.property.clientPortname> <value>2181value> property> -
修改配置文件
regionservers[root@nodex ~]# vi /usr/hbase-1.2.4/conf/regionservers node1 node2 node3 -
修改用户环境变量文件
.bashrc[root@nodex ~]# vi .bashrc HBASE_MANAGES_ZK=false HBASE_HOME=/usr/hbase-1.2.4 HADOOP_HOME=/usr/hadoop-2.6.0 JAVA_HOME=/usr/java/latest CLASSPATH=. PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin export JAVA_HOME export CLASSPATH export PATH export HADOOP_HOME export HBASE_HOME export HBASE_MANAGES_ZK [root@nodex ~]# source .bashrc
启动服务
-
启动HMaster
[root@nodex ~]# hbase-daemon.sh start master -
启动HRegionServer
[root@nodex ~]# hbase-daemon.sh start regionserver
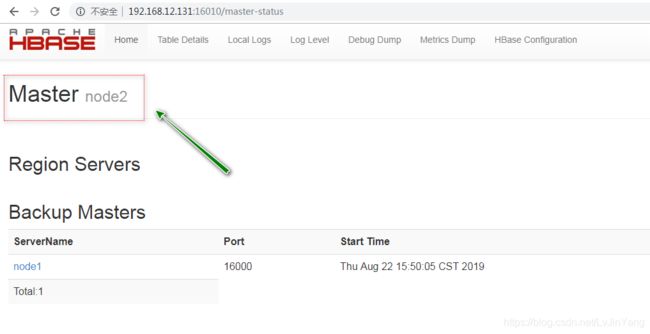
验证结果
五、HBase架构详解
自动分配主和备
-
HRegion
HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。HRegion由HMaster分配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。 -
HMaster
HMaster没有单点故障问题,可以启动多个HMaster,通过ZooKeeper的Master Election机制保证同时只有一个HMaster处于Active状态,其他的HMaster则处于热备份状态。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。要有两方面的职责:-
管理协调HRegionServer
-
管理HRegion的分配,以及负载均衡和修复时HRegion的重新分配。
-
监控集群中所有HRegionServer的状态(通过Heartbeat和监听ZooKeeper中的状态)。
-
-
Admin职能
- 创建、删除、修改Table的定义。
-
-
ZooKeeper
ZooKeeper为HBase集群提供协调服务,它管理着HMaster和HRegionServer的状态(available/alive等),并且会在它们宕机时通知给HMaster,从而HMaster可以实现HMaster之间的failover(故障转移),或对宕机的HRegionServer中的HRegion集合的修复(将它们分配给其他的HRegionServer)。ZooKeeper集群本身使用一致性协议(PAXOS协议)保证每个节点状态的一致性。
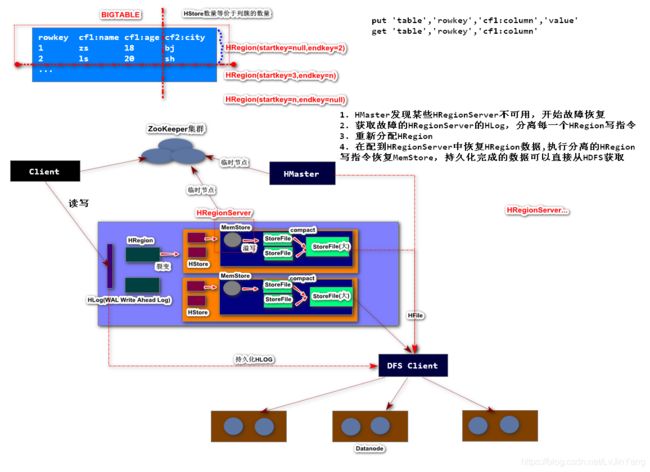
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由以下类型节点组成: HMaster 节点、HRegionServer 节点、 ZooKeeper 集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,总体结构如下:
HMaster节点用于:
- 管理HRegionServer,实现其负载均衡。
- 管理和分配HRegion,比如在HRegion Split时分配新的HRegion;
- 在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上。
- 实现DDL操作(Data Definition Language,namespace和table的增删改,column familiy的增删改等)。
- 管理namespace和table的元数据(实际存储在HDFS上)。
- 权限控制(ACL)。
HRegionServer节点用于:
- 存放和管理本地HRegion。
- 读写HDFS,管理Table中的数据。
- Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)。
- 实现数据的本地性(一个节点有HRegionServer,一个DataNode)
ZooKeeper集群用于:
-
存放整个 HBase集群的元数据以及集群的状态信息。
-
实现HMaster主从节点的failover(故障转移)
HBase集群中有主服务HMaster(管理HRegionServer)承担HRegionServer的负载均衡
HRegion:起始只有一个,有一个起始的key,一个结束的key,对大表水平切割后的产物
有多个HStore(按照列簇垂直切割后的产物,几个列簇就有几个HStore);一个HStore内部有一个MemStore(内存存储) ,MemStore达到阈值溢写到StoreFile ;多个小的 StoreFile 文件定期会被合并(conpact)产生大的StoreFile文件 (大到一定程度,HRegion会裂变,保证BigTable的横向扩展) ; StoreFile达到某些要求之后会调用DFS Client(类库),持久化到HDFS的DateNode 的数据块, StoreFile 在HDFS中叫HFile
HRegionServer:管理HRegion,里面有很多HRegion,一个HLog(写日志,也称为Write Ahead Log)
客户端发起写操作,先保存到HLog,再保存到MemStore,客户端请求立即返回
从DFSClient 到HDFS中获得Hlog文件
六、rowKey设计

列簇设计一个字符或两个字符,很多公司就一个字符
写:put ‘ns:table’,‘rk’,cf:column’,‘value’
rowKey设计避免数据热点问题(HRegion的负载均衡问题(忙的忙死,闲的闲死))
数据热点问题:用户的读写操作在同一个HRegion里,造成HRegionServer压力过大,导致HRegionServer服务不可用
rowKey特点:
1、唯一,类似primaryKey
2、有序,按照rowKey的字典顺序自动排序
null-->bb(ba)
bb -->cc(bc)
cc -->null
3、分解后的HRegion(rowKey的范围区间)
官方rowKey最大允许64kb,建议rowKey的大小控制在10M即100个字节以内,企业是20到30个字节
数据热点问题的解决方案:(为了让rowKey放入不同的region里)
1、唯一值+时间戳(多)+订单编号
订单表:user001:20180101141210101
2、哈希散列
原始rowKey:123456-->MD5加密产生32位的16进制的字符串,很随机
123457
问题:破坏rowKey的有序性
3、翻转reverse(多)
原始rowKey翻转,将翻转的结果作为新的rowKey
user10120180101-->10108102101resu
user10120180110
StringBuilder s= new StringBuilder("user10120180101").reverse();
4、预分区
根据系统自己业务的特点,提前创建HRegion
假如一个HBase由HRegion构成
第一个:null-->bb
第二个:bb -->cc
第三个:cc -->null
Shell操作:
# hbase shell
# create
创建表时指定HRegion的rowKey分区
#5个分区
# 创建表时指定HRegio的RowKey区间
hbase> create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt'
# 创建预分区的HBase表
hbase(main):002:0> create 't_split','cf1',SPLITS_FILE=>'/root/splits.txt'
=> Hbase::Table - t_split
裂变公式:min[regionNum^2*128M,maxFileSize(10GB)]
8^2*128=8192M
9^2*128=10368M
10GB=10240M
裂变比较耗资源
memstore溢写条件:
hbase-default.xml
flush
hbase.regionserver.global.memstore.size
<description>
一个HRegionServer就是一个java进程管理0-n个HRegion
1、默认HRegionServer所有的memstore达到堆内存的40%,进行溢写
2、默认一小时溢写一次
property
memstore.flsh.size 134217728bt=128M
3、当前的HRegionServer上所有的memstore数据之和达到128M,进行溢写
compact合并条件(小的溢写文件合并为大的StoreFile文件):
hbase.hregion.majorcomaction
1、默认604800000ms=7days
hbase.hregion.majorcomactionThreshold阈值(Thanslation翻译插件)3
2、StoreFile文件数量大于3,会自动合并为一个StoreFile
1、唯一值+时间戳(多)+订单编号
订单表:user001:20180101141210101
2、哈希散列
原始rowKey:123456–>MD5加密产生32位的16进制的字符串,很随机
123457
问题:破坏rowKey的有序性
3、翻转reverse(多)
原始rowKey翻转,将翻转的结果作为新的rowKey
user10120180101–>10108102101resu
user10120180110
StringBuilder s= new StringBuilder(“user10120180101”).reverse();
4、预分区
根据系统自己业务的特点,提前创建HRegion
假如一个HBase由HRegion构成
第一个:null–>bb
第二个:bb -->cc
第三个:cc -->null
Shell操作:
# hbase shell
# create
创建表时指定HRegion的rowKey分区
#5个分区
# 创建表时指定HRegio的RowKey区间
hbase> create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt'
# 创建预分区的HBase表
hbase(main):002:0> create 't_split','cf1',SPLITS_FILE=>'/root/splits.txt'
=> Hbase::Table - t_split
```java
裂变公式:min[regionNum^2*128M,maxFileSize(10GB)]
8^2*128=8192M
9^2*128=10368M
10GB=10240M
裂变比较耗资源
memstore溢写条件:
hbase-default.xml
flush
hbase.regionserver.global.memstore.size
<description>
一个HRegionServer就是一个java进程管理0-n个HRegion
1、默认HRegionServer所有的memstore达到堆内存的40%,进行溢写
2、默认一小时溢写一次
property
memstore.flsh.size 134217728bt=128M
3、当前的HRegionServer上所有的memstore数据之和达到128M,进行溢写
compact合并条件(小的溢写文件合并为大的StoreFile文件):
hbase.hregion.majorcomaction
1、默认604800000ms=7days
hbase.hregion.majorcomactionThreshold阈值(Thanslation翻译插件)3
2、StoreFile文件数量大于3,会自动合并为一个StoreFile