Transformer
Transformer:(Seq2Seq model)
有以下几种类型:
input跟output的长度一样;
output只是一个label或者class;
甚至不确定output多长,由机器决定output长度;
有以下几种应用:包括语音识别,机器翻译,和语音翻译(对于方言和无文字的语言很友好)

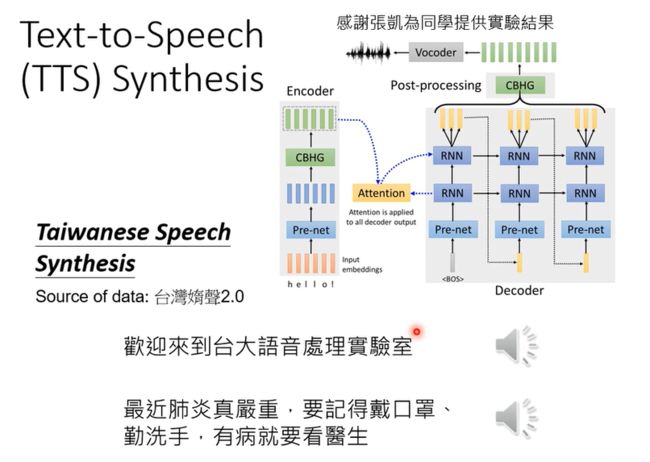
还有TTS,语音合成任务,输入文字,输出语音信号;
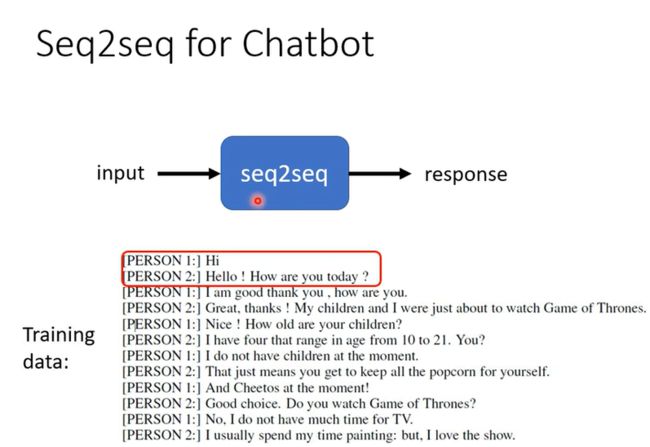
Seq2Seq也可以应用到对话机器人;
所以各式各样的NLP的问题,往往都可以看作是QA的问题,而QA的问题,就可以用Seq2Seq来解:

还可以可以做一些文法剖析,多标签分类,目标检测等等任务;
Seq2Seq model Encoder:
模型包括了一个Encoder模块和Decoder模块,很重要的一个模型就是Transformer;
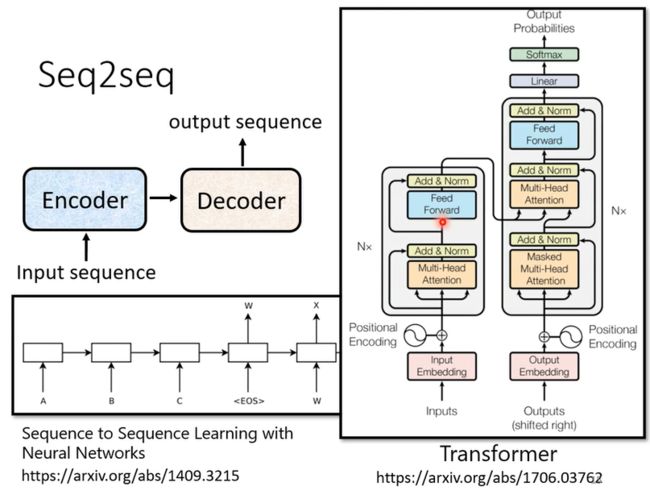
其中Encoder部分,就是给一排向量,输出另外一排向量,可以用Self-attention做到,但其实也可以用RNN或者CNN来完成,在Transformer模型中Encoder模块使用到了Multi-Head Attention来做;
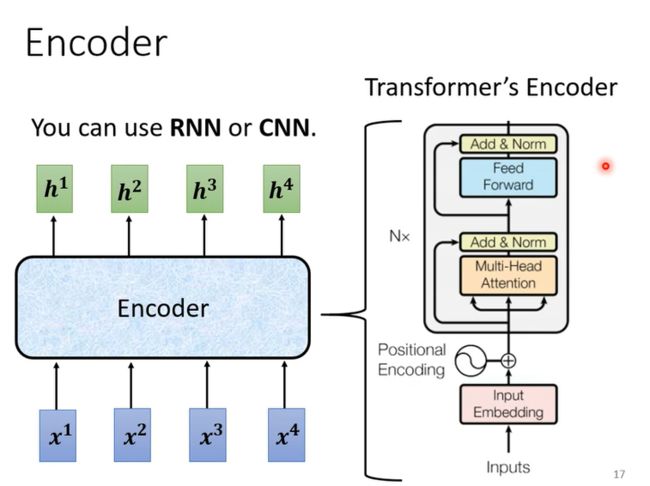
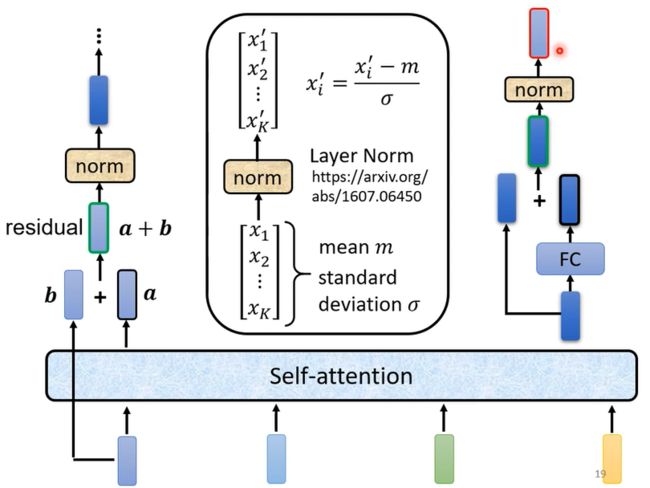
在Transformer中,用到了Self-attention的同时还使用了Add&Norm两个机制,其中Add就是使用了residual模块,将input和output相加,而norm是使用了更为简单的layer Norm, 这里没有用batch norm;而上图的中的Positional Encoding就是为输入添加位置信息;
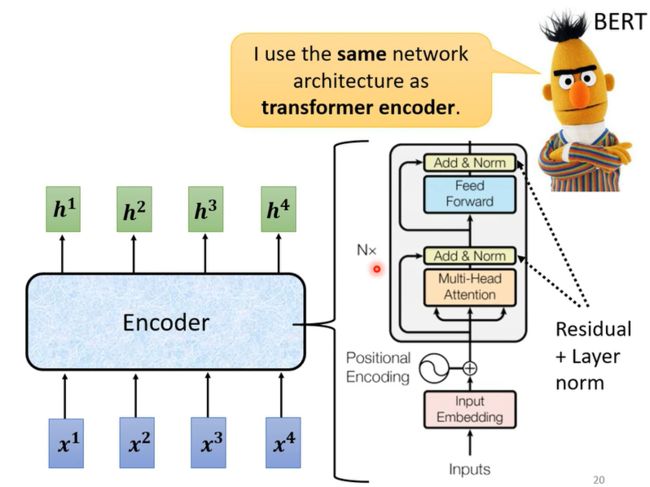
所以上述讲述了Transformer模型Encoder部分重要的一些结构,BERT模型也是使用相同的结构;
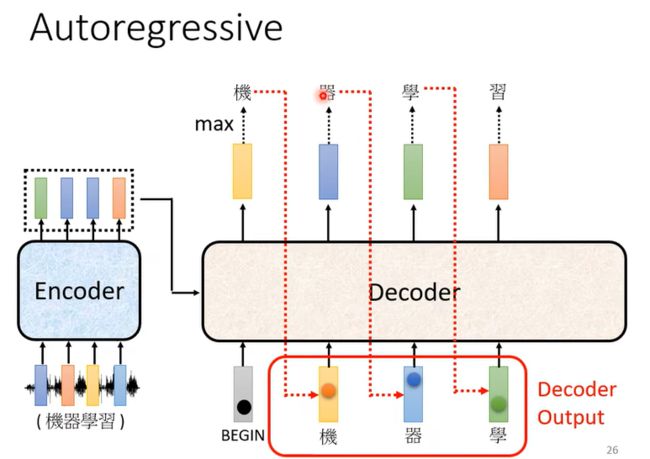
Seq2Seq model Decoder:
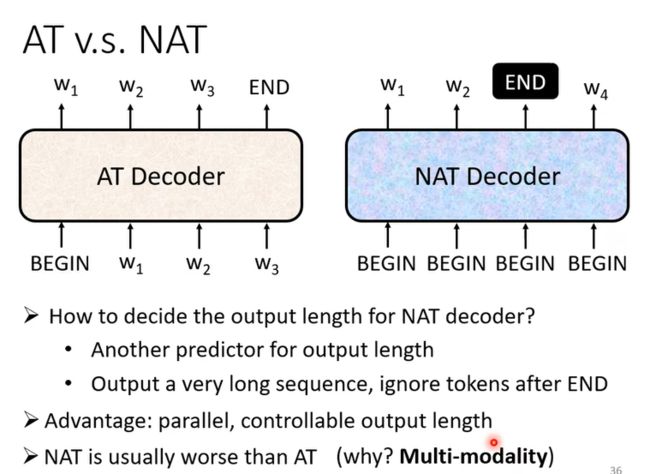
Decoder有两种,常见的 Autoregressive(AT) Decoder,和Non-autoregressive (NAT) Decoder;
AT:
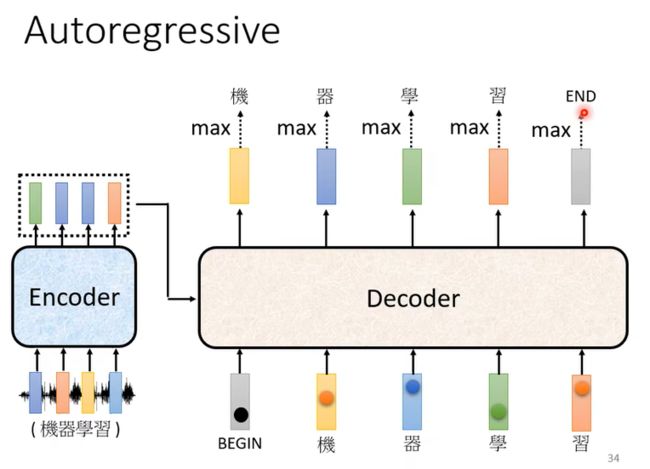
起初会有 一个BEGIN信号,随后Decoder 把自己的输出,当做接下来的输入,然后持续这个process;
Decoder内部结构:通过对比其实发现encoder和decoder内部结构除了中间一块十分类似,结尾加上Linear和Softmax做预测分析;
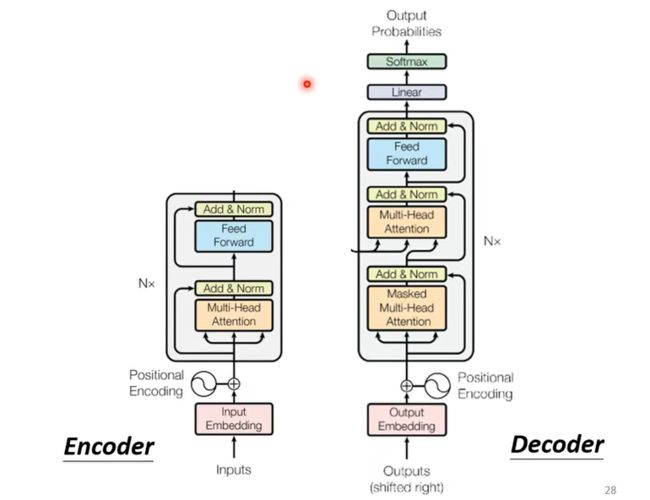
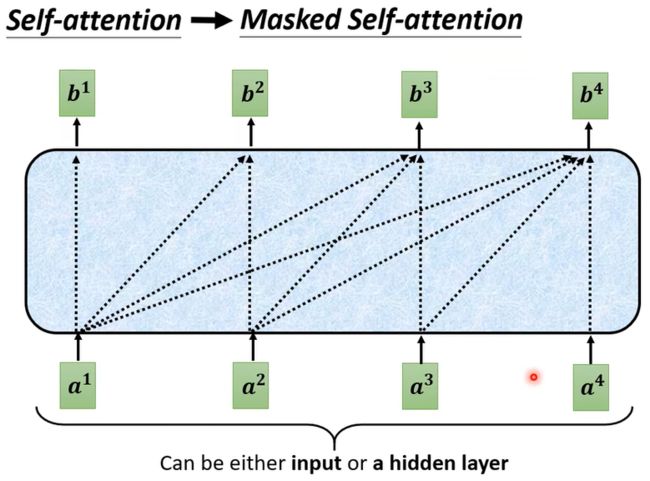
需要注意到decoder使用的是Masked Multi-Head Attention而encoder就是使用Multi-Head Attention, 这是因为decoder在产生输出时候,只能借鉴前半部分的信息,而后半部分的信息还等待这被产生,所以他被称作Masked,如下图;
还有一个问题关于什么时候停止输出,因此我们需要一个END信号,当产生向量END,就是断的信号,那么整个 Decoder 产生 Sequence 的过程就结束了;
NAT:
NAT 的 Decoder一次输入所有BEGIN Token,就把一排 BEGIN 的 Token输入,让它一次产生所有输出就结束了,而这个BEGIN Token的数量可以有以下几种方式获得,一个做法是,你另外学习一个 Classifier,输入 Encoder 的 Input,然后输出是一个数字,这个数字代表 Decoder 应该要输出的长度;或者给很多BEGIN,然后等到输出 END,输出 END之后的就当不存在; 好处在于并行化,比较容易控制其长度,但是总的来说它往往不如AT;
Cross attention:
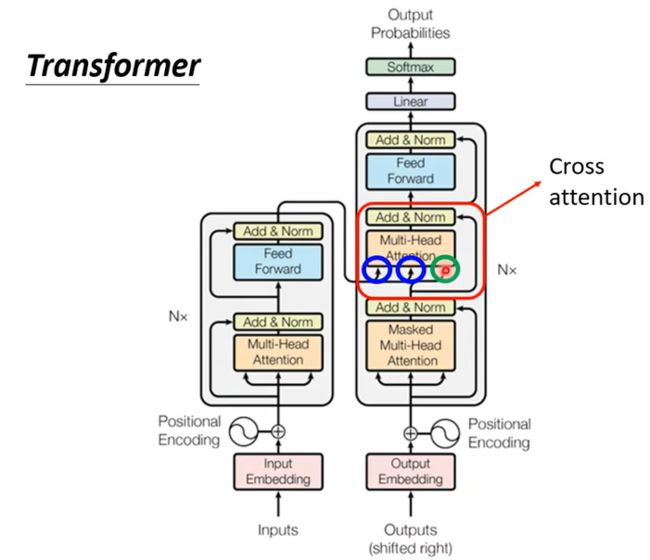
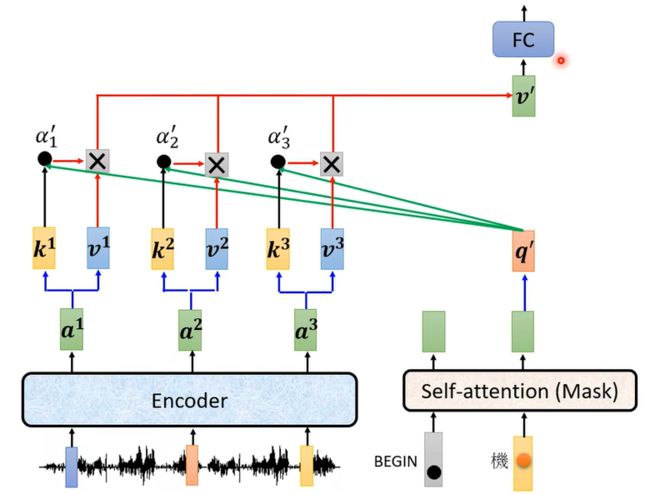
这块叫做 Cross Attention,它是连接 Encoder 跟 Decoder 之间的桥樑,这里会发现有两个输入来自Encoder, Encoder 提供两个箭头,然后 Decoder 提供了一个箭头;更细节化来说如下图,当然他不是完全固定的;
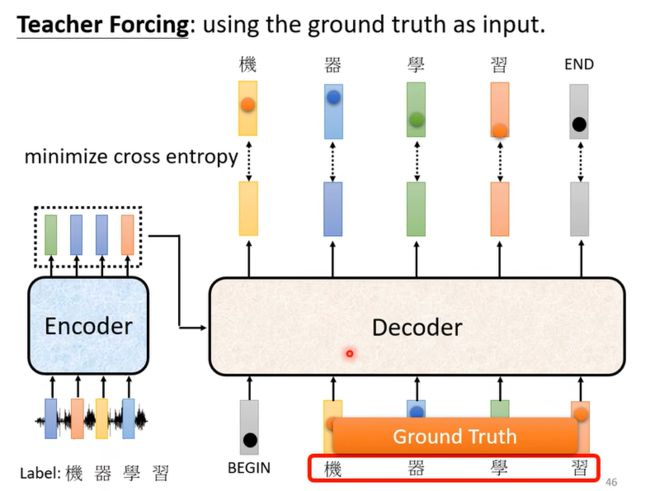
Training:
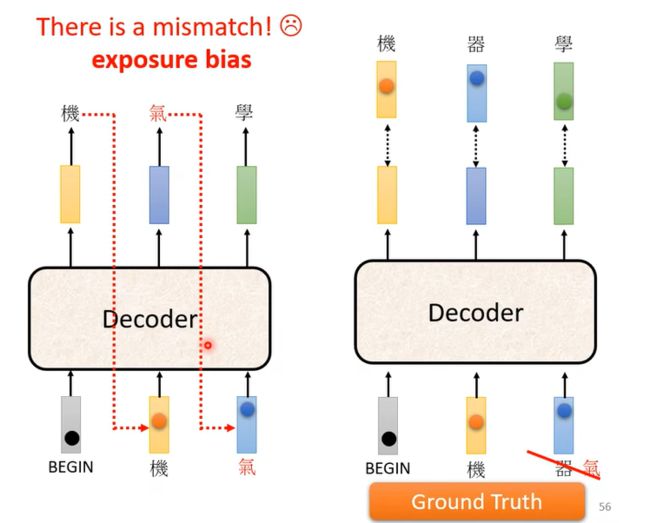
注意在训练时,我们会把正确答案给decoder当作输入,然后最小化cross entropy来进行训练,当然这里会存在mismatch的现象,因为在实际操作时不会有正确答案;
解决方法就是Scheduled Sampling:
给 Decoder 的输入的加入一些错误的东西,不要给 Decoder 都是正确的答案,偶尔给它一些错的东西,它会学得更好;
TIPS for optimization:
1Copy Mechanism, 例如chat-bot,因为有部分信息没有实际意义,直接copy会省力很多;最早有从输入复製东西的能力的模型,叫做 Pointer Network;

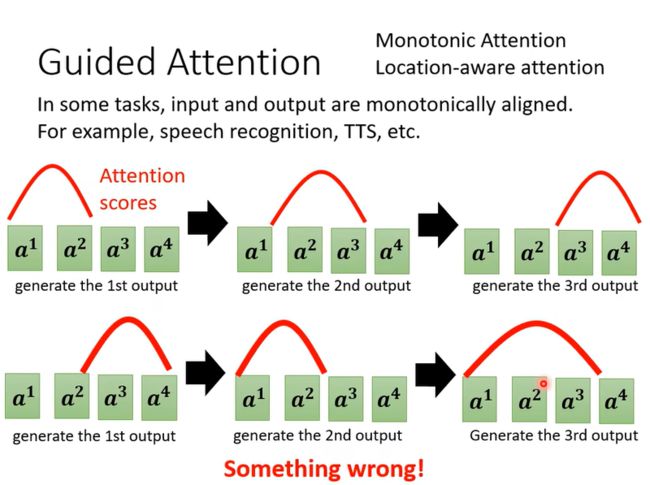
2Guided Attention,要做的事情就是,要求机器它在做 Attention 的时候,是有固定的方式的(guide)
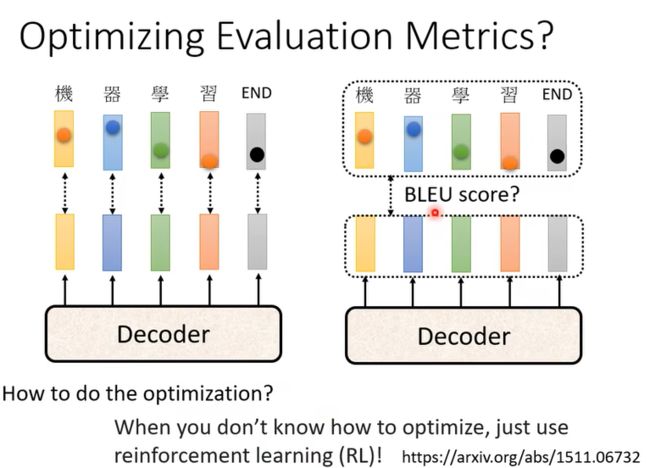
Optimizing Evaluation Metrics:
我们在训练时候用到了cross entropy,而使用BLEU score来表示我们最后的精准度;实际来说cross entropy并不能得到最好的BLEU score,而我们也不能用BLEU 来做训练,因为这个非常复杂而且不好计算微分;所以我们在做Validation Set的时候应该考虑用 BLEU Score;而且当我们遇到optimization困难的时候使用RL或许会有意想不到的结果;