点云的密度 曝光时间_PointConv:基于3D点云的深度卷积网络
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达
3D视觉工坊的第70篇文章
本文出自知乎:
https://zhuanlan.zhihu.com/p/69597887?utm_source=wechat_session&utm_medium=social&utm_oi=1135649954939883520
原文:
PointConv: Deep Convolutional Networks on 3D Point Clouds
Wenxuan Wu, Zhongang Qi, Li Fuxin
CORIS Institute, Oregon State Universitywuwen, qiz,[email protected]
摘要
图像数据通常可以表示成密集的网格形式,而三维的点云数据通常是不规则的无序的。因此,在点云数据上使用卷积是困难的。本文将动态滤波器拓展为一种新的卷积操作——PointConv。PointConv可以应用于点云进而搭建深度卷积网络。我们把卷积核视作一个作用在局部三维点坐标系上的由权重和密度函数组成的非线性函数。给定一个点,权重函数可以通过多层感知网络习得,而密度函数可以通过核密度估计来得到。本文最重要的贡献是:提出了一种新颖的高效的计算权重函数的方法。这种方法允许我们动态的拓展网络并极大的提升模型能力。习得的卷积核可以用于计算三维空间任意给定的点集上的卷积,而这种卷积能保证语义不变和置换不变性。此外,PointConv还可以用作反卷积运算符,从而将子采样点云中的特征传播回其原始分辨率。在ModelNet40,ShapeNet和ScanNet数据集上的实验结果表明,基于PointConv的深度卷积网络在三维点云语义分割任务中具备一流的能力。此外,我们还将CIFAR-10数据集转成点云格式,并用PointConv搭建网络测试其性能。其结果与采用类似结构的二维图像网络相仿。
一、 介绍
近来在机器人、自动驾驶、虚拟现实等领域,能直接捕获三维数据的传感器发展迅猛。这其中包括室内传感器,比如激光扫描器,time-of-flight传感器,比如Kinect,RealSense 或者Google Tango,structural light传感器,比如iPhoneX,同样的有室外传感器比如LIDAR和MEMS传感器。在这些应用场景中,直接测量3D数据的能力是非常重要的,因为深度信息可以从2D图像中消除分割不确定性,并且表面法线信息为应用场景提供几何的重要线索。
在二维图像中,卷积神经网络(CNNs)从根本上改变了计算机视觉的版图,卷积神经网络几乎在所有的视觉任务中都极大的提升了现有的结果。CNNs的成功源于利用了翻译不变性(translation invariance),所以一组相同设置的卷积滤波器可以作用在同一图像的所有位置,这一做法可以降低参数量提升泛化性能。我们期望能够在3D数据的分析中延续这种成功。然而三维数据通常以点云的形式表示,也就是一组无序的三维点,也许每个点还包含额外的特征(比如颜色信息)。点云是无序的,不能像二维图像一样把每个点归于规则的网格。在无序的输入上运用传统的卷积网络是存在诸多困难。一种可选的方法是将三维空间视作一个体素化的网格,但是在实际操作中,空间网格通常是稀疏的并且在高分辨率场景中,CNNs需要面对相当棘手的计算开销。
本文中,我们提出了一种新颖的方法,用来在非均匀采样的3D点云数据集上执行卷积操作。我们注意到实际的卷积操作可以视作对连续的卷积的离散近似。在3D空间中,我们可以将该卷积算子的权重视为相对于参考3D点的局部3D点坐标的(Lipschitz)连续函数。连续函数可以通过多层感知机(MLP)来近似得到,就如同[33] 和 [16]中的做法类似。但是这些算法没有考虑非均匀采样带来的影响。我们提出使用一个反向密度估计(inverse density scale)的方法重新计算MLP习得的连续函数,这一过程对应连续函数中的蒙特卡罗近似。我们称这一操作为PointConv。PointConv综合考虑点云的位置分布,学习一个MLP来近似权重函数,并使用反向密度估计(inverse density scale)的方法对学习到的权重根据非均匀采样进行补偿。
原生的PointConv实现中输出特征的通道非常大,内存消耗多,效率低,因此模型训练困难。所以为了降低PointConv的内存开销,我们引入了一种改变总和顺序(summation order)的方法,可以极大的提升内存效率。新的结构可以用于在3D点云上搭建多层深度卷积网络,能达到在图像2D卷积类似的效果。与2D卷积网络类似,我们的方法同样可以达到相同的翻译不变性,并且根据输入点云序列保证序列不变性。
在分割任务中,从稀疏层到精细层的信息整合能力至关重要。因此,能够充分利用从粗糙层到更精细层的特征的反卷积操作[24]对于性能至关重要。大多数最先进的算法[26,28]无法执行反卷积操作,这限制了它们在分割任务中的性能。我们提出的PointConvis是卷积的完全近似,因此将PointConv扩展为PointDeconv是很自然的事情,它可以完全利用粗糙层中的信息并传播到更精细的层。通过使用PointConv 和PointDeconv,我们可以在语义分割任务上实现更高的性能。
我们的主要工作贡献是:
1)我们提出PointConv,一种密度函数重加权卷积,它能够在任何3D点集上完全逼近3D连续卷积。
2)我们设计了一种内存高效的方法来实现PointConv,使用求和顺序技术的变化提升性能,最重要的是,它允许模型能够扩展到现代CNNs的层数。
3)我们将PointConv扩展为反卷积(PointDeconv)版本以获得更好的分割结果。
实验表明和其它点云深度网络相比,我们基于Point-Conv搭建的深度网络模型具备相当的竞争力,并且在部件分割数据集[2]和室内场景语义分割数据集[5].上取得最先进的结果。为了证明我们提出的PointConv确实是一个真正的卷积运算,我们还通过将2D图像中的所有像素转换为:具有2D坐标以及GB特征的点云来评估CIFAR-10上的PointConv性能。在CIFAR-10上的实验表明,我们的PointConv的分类精度与具有类似结构的图像CNN相当,远远超过了点云网络先前获得的最佳结果。作为对3D数据的近似CNN方法,我们相信PointConv可能有许多潜在的应用。
二、 相关工作
3D CNN网络上的大多数工作都将3D点云转换为2D图像或3D体积网格。[36,27]提出将3D点云或形状投影到几个2D图像中,然后应用2D卷积网络进行分类的方法。虽然这些方法在形状分类和检索任务上已经取得了不错的结果,但将这些方法扩展到高分辨率场景分割任务仍然任重道远[5]。[43,43,27]代表另一种类型的方法,通过量化方法将点云体素化为体积网格,然后应用3D卷积网络。这种方法受到3D网格分辨率和3D卷积的计算成本的限制。[31]通过使用一组不平衡的八叉树显著地提高了分辨率,其中每个叶节点存储一个合并的特征表示。Kd-networks [18]在具有一定大小的Kd树上以前馈自下而上的方式计算表示点云特征。在Kd-networks中,点云中的输入点数在训练和测试期间需要相同,这不适用于许多任务。SSCN [7]利用基于体素网格的卷积,通过仅在CNN中考虑输入点位置的激活情况来讨论CNN输出,提升速度减少内存开销。然而,如果点云的采样稀疏,尤其是当采样率不均匀时,对于稀疏采样区域,可能无法在体积卷积滤波器内找到任何邻居点云,这可能导致无法正常计算卷积。
一些最新的方法[30,26,28,35,37,13,9,39]直接将原始点云作为输入,而不需要将点云转换为其他格式。[26,30]提出使用共享的多层感知器和最大池化层来获得点云的特征。由于最大池化层应用于点云中的所有点,因此很难捕获局部特征。PointNet ++ [28]通过添加层次结构改进了PointNet [26]中的网络。层次化结构类似于图像CNN中使用的分层结构,它从小的局部区域开始并逐渐扩展到更大的区域逐级提取特征。PointNet [26]和PointNet ++ [28]均使用最大池化结构来聚合来自不同点的特征。但是,最大池化层仅对局部或全局区域中的信号最强的体素进行激活,在分割任务中,这可能会丢失一些有用的细节信息。[35]提出了一种方法,将点云的输入特征投影到高维网格上,然后在高维网格上应用双向卷积来聚合特征,称为“SPLATNet”。SPLATNet [35]能够提供与PointNet ++ [28]相近的结果。切线卷积(tangent convolution)[37]在每个点周围的切平面上投影局部曲面几何,从而得到一组平面可卷积曲切线图像。逐点卷积[13]在运行中查询最近邻居并将点分成多个内核单元,然后在分块单元上进行内核权重估计从而在点云上进行卷积。Flex-convolution [9]引入了一种基于传统卷积层的推广方法以及其高效的GPU实现,该方法可以应用于具有数百万个点的点云。FeaStNet [39]提出可以通过添加软分配矩阵(soft-assignment matrix)将常规卷积层推广到3D点云。PointCNN [21]是从输入点学习χ变换,然后用它来同时对点相关的输入特征进行加权和置换。与我们提出的方法相比,PointCNN无法实现序列不变性,而这是分析点云时所需要的。
文献[33,16,41,12,40]和[44]提出学习连续滤波器来执行卷积操作。[16]提出2D卷积中的权重卷积核可以被视为连续函数,可以通过MLPs近似。[33]首先在3D图结构中引入这个想法。[40]将[33]中的方法扩展到分割任务并提出了一个效率更高的版本,但它们的版本只能近似深度卷积(depth-wise convolution)而不是真正的卷积。动态图CNN [41]提出了一种可以动态更新图结构的方法。[44]提出了一个特殊的过滤器族来近似权重函数,而不是使用MLP。[12]结合点云密度提出了3D卷积的蒙特卡罗近似。我们的工作在3个方面与上述工作不同。最重要的是,我们提出了真正有效的卷积。此外,我们利用点云密度的方式不同于[12],我们提出了一种基于PointConv的反卷积算子来执行语义分割任务。
三、 PointConv
我们提出了一种卷积运算,它将传统的图像卷积扩展到点云上,我们称其为Point-Conv。PointConv是3D连续卷积算子的一种蒙特卡罗近似扩展。对于每个卷积滤波器,它使用MLP来近似加权函数,然后应用密度标度(density scale)函数来重新估计权重函数的参数。Sec. 3.1介绍了PointConv层的结构。Sec. 3.2引入PointDeconv,使用PointConv层反卷积点云特征。
3.1. 3D 点云上的卷积
形式上,给定一个d维向量x,卷积可以定义为Eq.(1)。
图像可以用2D离散函数表示,其通常表示形式为网格形矩阵。在CNN中,每个滤波器被限制在一个小的局部区域内,例如3×3;5×5等。在每个局部区域内,不同像素之间的相对位置总是固定的,如图1(a)所示。并且我们可以容易地将滤波器离散化,成为具有局部区域内的每个位置的实值权重的总和。(译者注:即局部加权求和。)
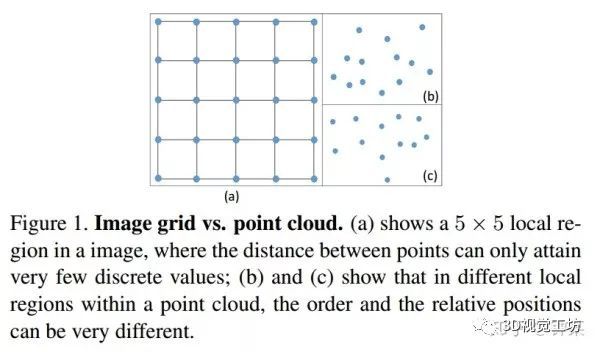
一组点云集合可以表示为一组3D点的集合,其中每个点包含一组位置向量或其它信息如颜色、表面切线等。不同于图像,点云的表示形式更灵活。在坐标系中,一个点的坐标不会限制在一个固定网格里,而是有可能取任意的连续值。因此,每个局部区域中不同点的相对位置是不同的。栅格化的图像上的传统离散卷积滤波器不能直接应用于点云。图1显示了图像中的局部区域和点云之间的差异。
为了使卷积能在点集兼容使用,我们提出了一种序列不变卷积运算,称为PointConv。我们的首先回忆3D卷积的连续版本:
其中是以点为中心的局部区域G中的点的特征。一组点云可以视为从一个连续空间进行非均匀采样的结果。在每个局部区域中,可能是局部区域的任何可能的位置。我们对PointConv进行如下定义:
其中是点处的反密度估计(inversedensity)。是必要的,因为点云往往存在非均匀采样。直观上看,局部区域中的点数在整个点云中变化,如图2(b)和(c)所示。

此外,在图2(b)和(c)中,点均相邻较近。所以每个点对全局特征的贡献较小。
我们的主要思想是通过多层感知机从三维坐标中近似权重函数并利用一个核密度估计[38]以及一个非线性变换(MLP实现)近似反密度函数。因为权重函数高度依赖于输入点云的分布,我们称整个卷积运算为PointConv。[16,33]考虑了权重函数的近似,但没有考虑对采样密度的近似,因此不是连续卷积算子的完全近似。我们对密度进行估计时采用的非线性变换也与[12]不同。
PointConv中的MLP的权重在所有点之间共享,以便保证序列不变性。为了计算反向密度尺度估计函数,我们首先使用核密度估计(KDE)离线估算点云中每个点周边的密度,然后将密度值输入到一个1D非线性变换的MLP中。使用非线性变换的原因是有必要让网络自适应地决定是否使用密度估计。
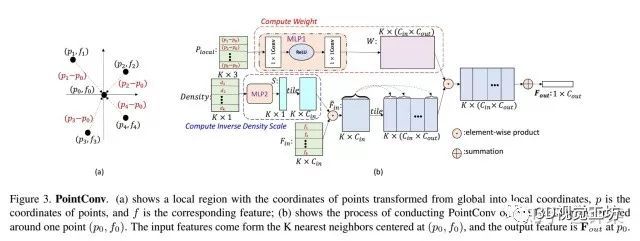
图3显示了在K邻域的局部区域内进行的PointConv操作。假设分别为特征的输入和输出通道数,分别指代k近邻,输入特征的第个通道,输出特征的第个通道。输入为3D局部位置坐标信息,记为,可以通过减去局部区域的质心的坐标或者局部的特征值来计算。本文使用1*1的卷积来实现MLP。权重函数的输出为。所以是一个向量。密度尺度范围为。经过卷积,输入特征从一个K近邻的局部区域被映射到了输出特征向量,如Eq.(4)所示。
PointConv学习一个网络用以近似卷积的连续权重。对于每个输入点,我们可以使用其相对坐标来计算MLP的权重。图2(a)展示了一个用于卷积的连续权重函数。不妨将点云输入视作对连续输入的离散化采样,一个离散卷积可以通过图2(b)所示的方式进行计算,用以提取局部特征,这对于不同的点云采样集合都有作用(可能具有不同的近似精度)(图2) (b-d)),其中的一个例子包括规则网格(图2(d))。注意,在栅格化图像中,局部区域中的相对位置是固定的。这时,PointConv(仅采用各点的相对位置作为权重函数的输入)将在整个图像上输出相同的权重和密度,此时它退化成为传统的离散化卷积。
为了聚合整个点集中的特征,我们使用层次化的结构,该结构能够整合细粒度的小区域特征进而组合成覆盖更大空间范围的抽象特征。我们使用的层次结构由几个特征编码模块组成,类似于PointNet ++ [28]中使用的模块。每个模块大致相当于卷积CNN中的一个层。每个特征编码模块中的关键层是采样层,分组层和PointConv。更多细节可以在补充材料中找到。
这种方法的缺点是每个滤波器需要由一个网络近似,因此效率非常低。在 Sec.4中,我们提出了一种实现PointConv的有效方法。
3.2. 使用反卷积的特征传播
对于语义分割任务,我们需要逐点预测。为了获得所有输入点的特征,需要一种将特征从二次采样点云传播到更密集的点的方法。PointNet ++ [28]提出使用基于距离的插值方法来传播特征,这是合理的,因为局部区域内的点具备局部相关性。然而,这并未充分利用反卷积操作来捕获来自粗粒度级别的局部相关信息。我们提出添加一个基于PointConv的PointDeconv层作为反卷积操作来解决这个问题。
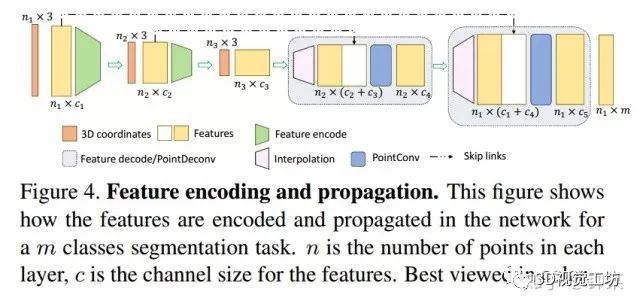
正如图4所示,PointDeconv由两部分组成:插值和PointConv。首先,我们使用插值来传播前一层的粗粒度特征。根据[28]的方法,我们通过从3个最近点来进行线性特征插值。然后,使用skip links将插值特征与来自卷积层的具有相同分辨率的特征连接起来。连接后,我们在连接的特征上应用PointConv以获得最终的反卷积输出,类似于图像反卷积层[24]。我们反复执行此过程,直到所有输入点的要素已传播回原始分辨率。
四、高效的 PointConv
原生的PointConv实现内存消耗巨大和比较低效。不同于[33],我们提出了一种新的重构方法,这种方法通过将PointConv减少到两个标准操作来实现PointConv:矩阵乘法和2d卷积。这种新颖的技巧不仅利用了GPU的并行计算,而且可以使用主流深度学习框架轻松实现。因为反密度估计函数不存在内存问题,所以下面的讨论主要集中在权重函数上。
特别的,将训练阶段的mini-batch size记为B,点云中的点的个数记N,每个点的邻域点集个数记为K,为输入点的通道数,为点的输出通道数。对一个点云而言,每部分局部区域都共享从MLP习得的相同的权重函数。但是对不同位置的不同点而言,运算得到的权重应当是不同的。由MLP生成的权重卷积核参数大小约为.假设,并且卷积核以单点精度进行存储。那么在这种情况下,单层网络的卷积核内存占用就达到了8GB。如此之高的内存占用情况使得网络几乎无法训练。[33]中使用了非常小的网络,卷积核个数非常少,这极大的降低了其性能。为了解决这个问题,我们提出了基于以下引理的内存高效版PointConv:
Lemma 1 PointConv等价于以下公式:
其中是用于计算权重函数的MLP中最后一层的输入,是同一MLP中最后一层的权重,是1*1的卷积。
证明:
通常,MLP的最后一层是线性层。在某一个局部区域中,假设,并且以1*1卷积的形式重写MLP,这时权重函数的输出为,假设k为局部点集中,点的序列号,分别指代输入,中间层,卷积核的输出。这时,为从函数W中得来的一个向量。而为从函数H中得来的一个向量。由公式(4)可知,PointConv可以写成如公式(5)中的形式。
让我们以更精细的方式观察公式(5),权重函数的输出可以表示为:
将公式(6)带入公式(5)。
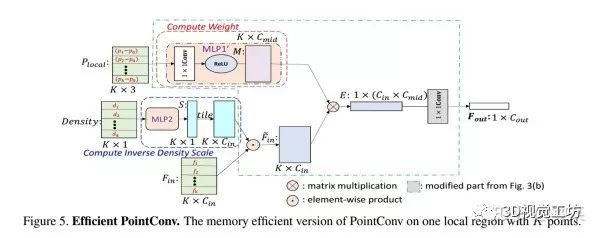
因此,原始PointConv可以等效地简化为矩阵乘法和1×1卷积。图5显示了PointConv的高效版本。
在这种方法中,我们不把生成的卷积核存储在内存中,而是将卷积核分为两部分:中间结果M和卷积核H。就如我们所见,和内存开销降低到原始方法的。取图三中相同的输入配置,取,内存开销为,约为原始PointConv的。
五、实验
为了评估我们提出的新PointConv网络性能,我们在几个广泛使用的数据集上进行了实验,ModelNet40 [43],ShapeNet [2]和ScanNet [5]。为了证明我们的PointConv能够完全逼近常规卷积,我们还测试了CIFAR-10数据集的结果[19]。在所有实验中,我们在GTX 1080Ti GPU上使用Tensorflow实现模型,实验中使用Adam优化器, 除最后一个完全连接的层之外,在每个层之后应用ReLU和batch normalization。
5.1 ModelNet40分类任务
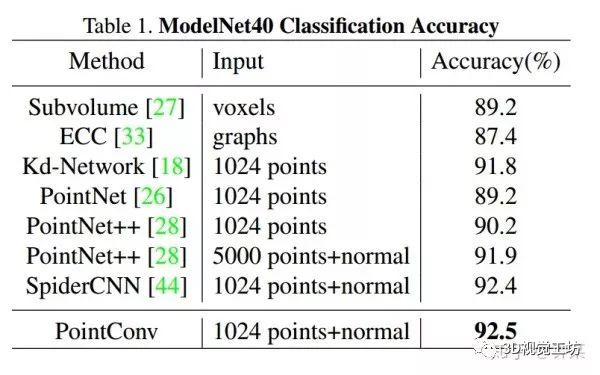
ModelNet40包含来自40个人造对象类别的12,311个CAD模型。我们使用官方提供的方案使用9843个形状用于训练,2468个用于测试。按照[26]中的配置,我们使用PointNet [26]中的源代码均匀采样1,024个点并从流型模型计算法向量。为了公平比较,我们采用与[26]相同的数据增强策略——沿z轴随机旋转点云并通过具有零均值和0.02标准偏差的高斯噪声来偏移每个点。在表1中,在基于3D输入的方法中,PointConv实现了最先进的性能。与我们的方法类似的 ECC [33],存在无法扩展到大型网络的缺点,性能受限。
5.2. ShapeNet 零件分割
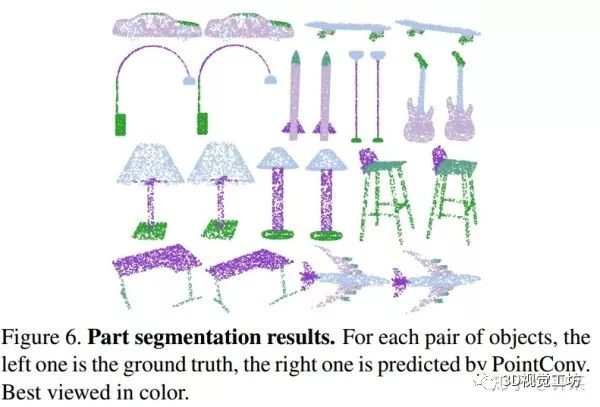
零件分割是一项具有挑战性的细粒度3D识别任务。ShapeNet数据集包含16个类的16881个形状,总共50个部分。任务的输入数据是由点云表示的形状数据,任务目标是为点云中的每个点分配零件类别标签。每个形状的类别标签已经给定。大多数相关工作中遵循类似的实验设置[28,35,44,18],我们同样如此。通常使用已知的输入3D对象类别,有助于缩小搜索范围。我们还将每个点上的法线方向作为输入要素,以更好地描述基本形状。图6显示了一些样本结果。
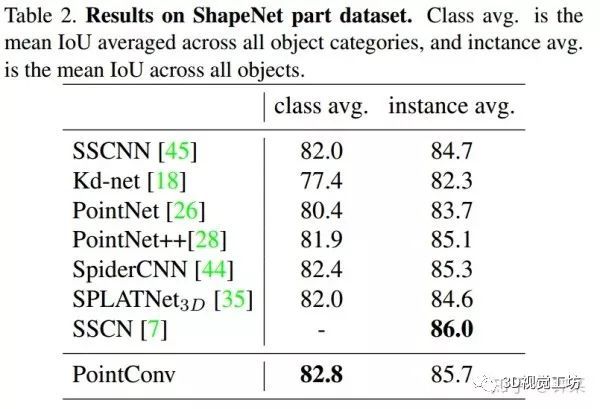
与PointNet ++ [28],SPLATNet [35]和其他一些部分分割算法[45,18,44,7]相同,我们使用point intersection-over-union(IoU)来评估我们的PointConv网络。结果显示在表2中。PointConv获得的类平均mIoU为82.8%,实例平均mIoU为85.7%,这与仅采用点云作为输入的最新算法相当。根据[35],SPLATNet2D-3D还将2D视图作为输入。由于我们的PointConv仅将3D点云作为输入,为了公平比较,我们仅将结果与[35]中的SPLATNet3D进行比较。
5.3. 场景语义标注
ModelNet40 [43]和ShapeNet [2]等数据集是人造合成数据集。正如我们在上一节中所看到的,大多数最先进的算法都能够在这些数据集上获得相对较好的结果。为了评估我们的方法处理包含大量噪声数据的真实点云的能力,我们使用ScanNet数据集来评估我们的PointConv语义场景分割性能。任务目标是在给定由点云表示的室内场景的每个3D点上指定语义对象标签。最新版本的ScanNet [5]包括所有1513 个ScanNet扫描结果和100个新的测试扫描数据集合,所有语义标签都是公开的,我们将结果提交给官方评估服务器以与其他方法进行比较。
我们将我们的算法与Tangent Convolutions [37],SPLAT Net [35],PointNet ++ [28]和ScanNet [5]进行比较。所有提到的算法都使用新的扫描数据集,算法的输入仅包括3D坐标数据和RGB。在我们的实验中,我们通过从室内房间随机抽取的立方体来生成训练样本,并在整个扫描中使用滑动窗口进行评估。
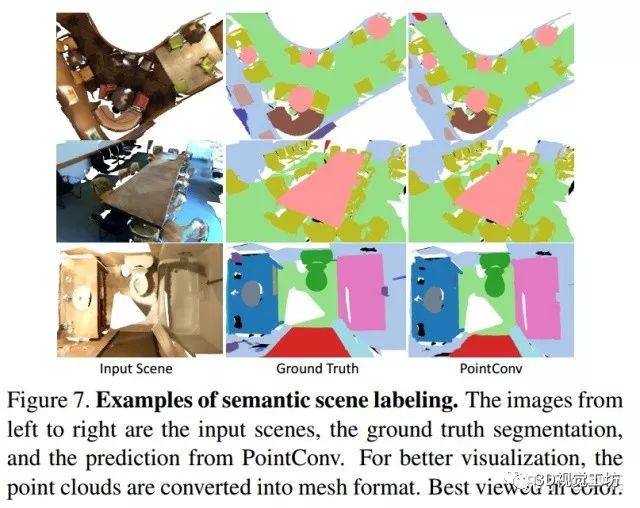
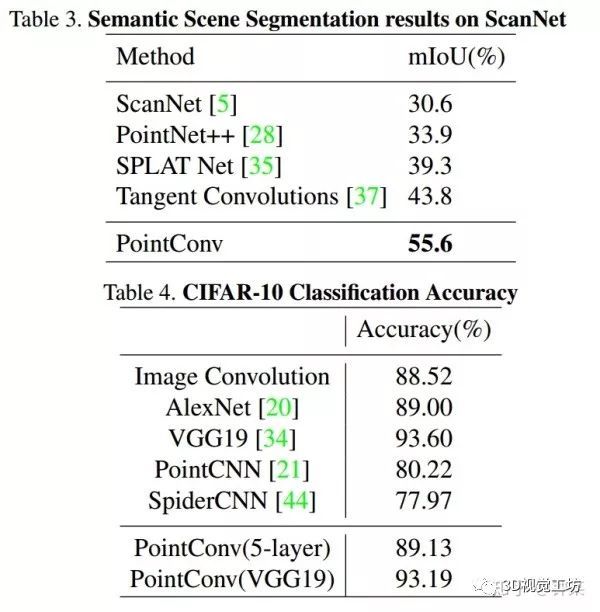
我们使用(IoU)作为评测标准。我们在图7中可视化一些语义分割结果。mIoU列于表3。mIoU是所有类别中IoU的平均值。我们的PointConv在很大程度上优于其他算法(表3)。在单块GTX1080Ti上进行测试,就ScanNet数据集而言,单轮训练时间约为170s,评估时对8*8192个点进行测试,用时约0.5s。
5.4. CIFAR-10分类结果
在Sec.3.1,我们认为PointConv可以与2D CNN等效。如果这是正确的,那么基于PointConv的网络的性能应该等同于应用于光栅图像CNN的性能。为了验证这一点,我们使用CIFAR-10数据集作为比较基准。我们将CIFAR-10中的每个像素转化成为具有xy坐标和RGB特征的2D点。在训练和测试之前,点云数据被缩放到单位球坐标上。
实验表明,CIFAR-10上的PointConv确实具有与2D CNN相同的学习能力。表4显示了图像卷积和PointConv的结果。从表中可以看出,CIFAR-10上PointCNN [21]的准确率仅为80.22%,远远低于图像CNN。对于5层网络模型,使用PointConv的网络能够达到89.13%的准确率,这与使用图像卷积的网络类似。而且,与VGG19 [34]结构相比,PointConv也可以实现与VGG19类似的精确度。
六、 剥离试验(Ablation Experiments)和可视化
在本节中,我们进行了额外的实验来评估PointConv各方面的有效性。除了对PointConv结构的消融研究外,我们还对ScanNet数据集上PointConv的性能进行了深入分析。最后,我们提供了一些可视化的卷积核。
6.1. MLP结构
在本节中,我们设计实验来评估PointConv中MLP参数的选择。为了快速评估,我们从ScanNet数据集生成一个子集作为分类任务的数据集。数据子集中的每个样例由原始场景扫描数据中随机采样的1024点构成。这样,ScanNet数据集取得20种不同的场景类型。我们根据经验在PointConv中选取不同的和不同数量的MLP层。每个实验进行3次随机试验。结果可以在补充材料中找到。从结果中,我们发现较大的不一定能提供更好的分类结果。MLP中不同的层数不会对分类结果带来太大差异。由于与每个PointConv层的内存消耗线性相关,因此结果表明我们可以选择相对小的以获得更高的内存效率。
6.2. 反密度尺度估计Inverse Density Scale
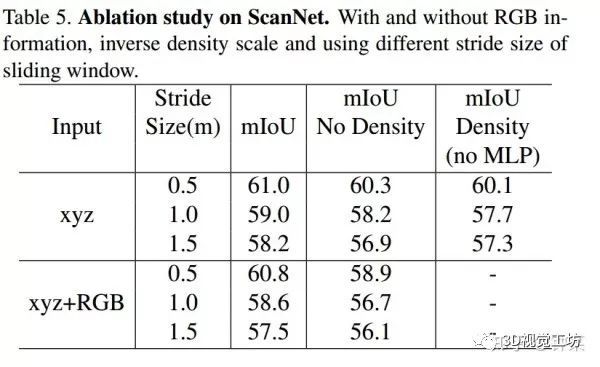
在本节中,我们研究了反密度尺度函数S的有效性。我们选择ScanNet作为评估任务的数据集,因为ScanNet中的点云是从真实的室内场景生成的,存在采样不均匀的情况。我们遵循作者提供的training/validation分组方案。如Sec. 3.1所述,我们分别使用和不使用反密度标度训练网络。表5显示了结果。正如我们所看到的,和不使用反密度尺度的PointConv相比,使用反密度尺度的PointConv提升了约1%的性能,这证明了反密度尺度函数的有效性。在我们的实验中,我们观察到反密度尺度在靠近输入的层中往往更有效。在深层,密度尺度对MLP的影响逐渐变小。一个可能的原因是,使用最远点采样算法作为我们的下采样算法时,更深层中的点云倾向于更均匀地分布。如表5所示,考虑密度带来的影响却不使用非线性变换评估密度时得到的结果比不考虑密度的结果更差,这表明非线性变换能够更好学习数据集中的反密度尺度。
6.3. Ablation Studies on ScanNet
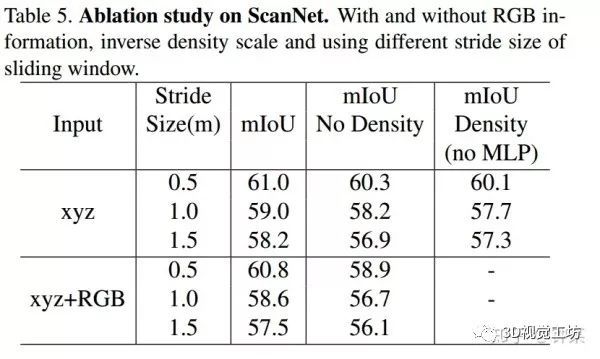
可以发现,我们的PointConv在很大程度上优于其他方法。由于我们只允许将我们算法的最终的一次结果提交给ScanNet的基准服务器,因此我们使用[5]提供的公共验证集对PointConv进行更多的消融研究。对于分割任务,我们从3m×1.5m×1.5m的空间随机采样的8192个点训练我们的PointConv,并在xy平面用不同步幅以滑动窗口方式选择3m×1.5m×1.5m立方体中的所有点分别来评估模型。为了保证稳健性,我们在所有实验中使用了5个窗口的多数投票的方法判定场景。从表5中,我们可以看到较小的步幅大小能够改善分割结果,而ScanNet上的RGB信息似乎不会显著改善分割结果。即使没有这些额外的改进,PointConv仍然大大超过基线测试成绩。
6.4. Visualization
图8显示了PointConv中学习到的卷积核。为了更好地可视化卷积核,我们在平面z = 0对学习函数进行采样。从图8中,我们可以看到学习到的连续卷积核中的一些模式。

七、结论
本文中,我们提出了一种新的方法来对3D点云进行卷积运算,称为PointConv。PointConv训练局部点坐标上的多层感知器,从而近似卷积核中的连续权重和密度函数,这种方法使得它自然地具备序列不变性和平移不变性。使用该卷积,我们可以直接在3D点云上构建深度卷积网络。我们提出了一种有效的实现方法,大大提高了它的可扩展性。我们展示了其在多个具有挑战性的基准测试中的强大性能以及在2D图像中足以媲美基于网格的卷积性能的能力。在未来的工作中,我们希望将PointConv运用于更多主流的图像卷积网络架构中,例如ResNet和DenseNet。代码请参见DylanWusee/pointconv。
参考文献
[1] Michael M Bronstein and Iasonas Kokkinos. Scale-invariant heat kernel signatures for non-rigid shape recognition. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pages 1704–1711. IEEE, 2010.
[2] Angel X Chang, Thomas Funkhouser, Leonidas Guibas,Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese,Manolis Savva, Shuran Song, Hao Su, et al. Shapenet:
An information-rich 3d model repository. arXiv preprint arXiv:1512.03012, 2015. 2, 6, 7
[3] Ding-Yun Chen, Xiao-Pei Tian, Yu-Te Shen, and Ming Ouhyoung. On visual similarity based 3d model retrieval. In Computer graphics forum, volume 22, pages 223–232. Wiley Online Library, 2003.
[4] Hang Chu, Wei-Chiu Ma3 Kaustav Kundu, Raquel Urtasun, and Sanja Fidler. Surfconv: Bridging 3d and 2d convolution for rgbd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3002–3011, 2018.
[5] Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), volume 1, 2017. 2, 6, 7, 8
[6] Yi Fang, Jin Xie, Guoxian Dai, Meng Wang, Fan Zhu, Tiantian Xu, and Edward Wong. 3d deep shape
http://descriptor.In
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2319–2328, 2015.
[7] Benjamin Graham and Laurens van der Maaten. Submanifold sparse convolutional networks. arXiv preprint arXiv:1706.01307, 2017. 2, 6, 7
[8] Adrien Gressin, Clement Mallet, J ´ er ´ ome Demantk ˆ e, and ´ Nicolas David. Towards 3d lidar point cloud registration improvement using optimal neighborhood knowledge. ISPRS journal of photogrammetry and remote sensing, 79:240–251,2013.
[9] Fabian Groh, Patrick Wieschollek, and Hendrik Lensch.Flex-convolution (deep learning beyond grid-worlds). arXiv preprint arXiv:1803.07289, 2018. 2
[10] Kan Guo, Dongqing Zou, and Xiaowu Chen. 3d mesh labeling via deep convolutional neural networks. ACM Transactions on Graphics (TOG), 35(1):3, 2015.
[11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[12] Pedro Hermosilla, Tobias Ritschel, Pere-Pau Vazquez, ´ Alvar ` Vinacua, and Timo Ropinski. Monte carlo convolution for learning on non-uniformly sampled point clouds. In SIGGRAPH Asia 2018 Technical Papers, page 235. ACM, 2018. 3, 4
[13] Binh-Son Hua, Minh-Khoi Tran, and Sai-Kit Yeung. Pointwise convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 984–993, 2018. 2
[14] Qiangui Huang, Weiyue Wang, and Ulrich Neumann. Recurrent slice networks for 3d segmentation of point
http://clouds.In
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2626–2635, 2018.
[15] Jorn-Henrik Jacobsen, Jan van Gemert, Zhongyou Lou, and ¨Arnold WM Smeulders. Structured receptive fields in
http://cnns.In
Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on, pages 2610–2619. IEEE, 2016.
[16] Xu Jia, Bert De Brabandere, Tinne Tuytelaars, and Luc V Gool. Dynamic filter networks. In Advances in Neural Information Processing Systems, pages 667–675, 2016. 1, 3,4
[17] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,2014.
[18] Roman Klokov and Victor Lempitsky. Escape from cells:Deep kd-networks for the recognition of 3d point cloud models. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 863–872. IEEE, 2017. 2, 6, 7
[19] Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, Citeseer, 2009. 6
[20] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton.Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012. 7
[21] Yangyan Li, Rui Bu, Mingchao Sun, and Baoquan Chen.Pointcnn. arXiv preprint arXiv:1801.07791, 2018. 2, 7
[22] Haibin Ling and David W Jacobs. Shape classification usingthe inner-distance. IEEE transactions on pattern analysis and machine intelligence, 29(2):286–299, 2007.
[23] Daniel Maturana and Sebastian Scherer. Voxnet: A 3d convolutional neural network for real-time object recognition. In Intelligent Robots and Systems (IROS), 2015 IEEE/RSJ International Conference on, pages 922–928. IEEE, 2015. 2
[24] Hyeonwoo Noh, Seunghoon Hong, and Bohyung Han. Learning deconvolution network for semantic
http://segmentation.In
Proceedings of the IEEE International Conference on Computer Vision, pages 1520–1528, 2015. 2, 4
[25] Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J Guibas. Frustum pointnets for 3d object detection from rgb-d data. arXiv preprint arXiv:1711.08488, 2017.
[26] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 1(2):4, 2017. 2, 6
[27] Charles R Qi, Hao Su, Matthias Nießner, Angela Dai, Mengyuan Yan, and Leonidas J Guibas. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5648–5656, 2016. 2, 6
[28] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems, pages 5105–5114, 2017. 2, 4, 6, 7
[29] Xiaojuan Qi, Renjie Liao, Jiaya Jia, Sanja Fidler, and Raquel Urtasun. 3d graph neural networks for rgbd semantic segmentation. In Proceedings of theqi IEEE Conference on Computer Vision and Pattern Recognition, pages 5199–5208, 2017.
[30] Siamak Ravanbakhsh, Jeff Schneider, and Barnabas Poczos. Deep learning with sets and point clouds. arXiv preprint arXiv:1611.04500, 2016. 2
[31] Gernot Riegler, Ali Osman Ulusoy, and Andreas Geiger. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, volume 3, 2017. 2
[32] Radu Bogdan Rusu, Nico Blodow, and Michael Beetz. Fast point feature histograms (fpfh) for 3d registration. In Robotics and Automation, 2009. ICRA’09. IEEE International Conference on, pages 3212–3217. IEEE, 2009.
[33] Martin Simonovsky and Nikos Komodakis. Dynamic edgeconditioned filters in convolutional neural networks on graphs. In Proc. CVPR, 2017. 1, 3, 4, 5, 6
[34] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 7
[35] Hang Su, Varun Jampani, Deqing Sun, Subhransu Maji, Evangelos Kalogerakis, Ming-Hsuan Yang, and Jan Kautz.Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2530–2539, 2018. 2, 6, 7
[36] Hang Su, Subhransu Maji, Evangelos Kalogerakis, and Erik Learned-Miller. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE international conference on computer vision, pages 945–953, 2015. 2
[37] Maxim Tatarchenko, Jaesik Park, Vladlen Koltun, and QianYi Zhou. Tangent convolutions for dense prediction in 3d. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3887–3896, 2018. 2, 7
[38] Berwin A Turlach. Bandwidth selection in kernel density estimation: A review. In CORE and Institut de Statistique. Citeseer, 1993. 4
[39] Nitika Verma, Edmond Boyer, and Jakob Verbeek. Feastnet: Feature-steered graph convolutions for 3d shape analysis. In CVPR 2018-IEEE Conference on Computer Vision & Pattern Recognition, 2018. 2
[40] Shenlong Wang, Simon Suo, Wei-Chiu Ma, Andrei Pokrovsky, and Raquel Urtasun. Deep parametric continuous convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2589–2597, 2018. 3
[41] Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma,Michael M Bronstein, and Justin M Solomon. Dynamic graph cnn for learning on point clouds. arXiv preprint arXiv:1801.07829, 2018. 3
[42] Zizhao Wu, Ruyang Shou, Yunhai Wang, and Xinguo Liu. Interactive shape co-segmentation via label propagation. Computers & Graphics, 38:248–254, 2014.
[43] Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1912–1920, 2015. 2, 6, 7
[44] Yifan Xu, Tianqi Fan, Mingye Xu, Long Zeng, and Yu Qiao.Spidercnn: Deep learning on point sets with parameterized convolutional filters. arXiv preprint arXiv:1803.11527,2018. 3, 6, 7
[45] Li Yi, Hao Su, Xingwen Guo, and Leonidas Guibas. Syncspeccnn: Synchronized spectral cnn for 3d shape segmentation. In Computer Vision and Pattern Recognition (CVPR),2017. 6, 7
[46] Tinghui Zhou, Matthew Brown, Noah Snavely, and David G Lowe. Unsupervised learning of depth and ego-motion from video. In CVPR, volume 2, page 7, 2017.
[47] Yin Zhou and Oncel Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. arXiv preprint arXiv:1711.06396, 2017.
上述内容,如有侵犯版权,请联系作者,会自行删文。欢迎加入我们公众号读者群一起和同行交流,目前有3D视觉、深度学习、激光SLAM、VSLAM、三维重建、点云后处理、图像处理、手眼标定、自动驾驶、位姿估计等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。

学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、可答疑解惑、助你高效解决问题