目录
- 前言
- 题目一:
- 使用正则表达式和文件操作爬取并保存“百度贴吧”某帖子全部内容(该帖不少于5页)
- 题目二:
- 实现多线程爬虫爬取某小说部分章节内容并以数据库存储(不少于10个章节)
本次的7个python爬虫小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习。
前言
关于Python7个爬虫小案例的文章分为三篇,本篇为上篇,共两题,其余两篇内容请关注!
题目一:
使用正则表达式和文件操作爬取并保存“百度贴吧”某帖子全部内容(该帖不少于5页)
本次选取的是百度贴吧中的NBA吧中的一篇帖子,帖子标题是“克莱和哈登,谁历史地位更高”。爬取的目标是帖子里面的回复内容。
源程序和关键结果截图:
import csv
import requests
import re
import time
def main(page):
url = f'https://tieba.baidu.com/p/7882177660?pn={page}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
resp = requests.get(url,headers=headers)
html = resp.text
# 评论内容
comments = re.findall('style="display:;"> (.*?) ',html)
# 评论用户
users = re.findall('class="p_author_name j_user_card" href=".*?" rel="external nofollow" target="_blank">(.*?)',html)
# 评论时间
comment_times = re.findall('楼
(.*?)50:
continue
csvwriter.writerow((u,t,c))
print(u,t,c)
print(f'第{page}页爬取完毕')
if __name__ == '__main__':
with open('01.csv','a',encoding='utf-8')as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('评论用户','评论时间','评论内容'))
for page in range(1,8): # 爬取前7页的内容
main(page)
time.sleep(2)

题目二:
实现多线程爬虫爬取某小说部分章节内容并以数据库存储(不少于10个章节)
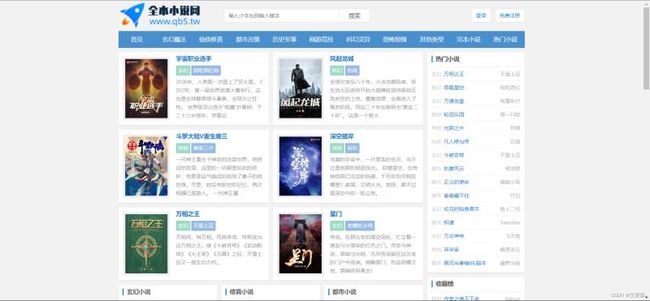
本次选取的小说网址是全本小说网https://www.qb5.tw/,这里我们选取第一篇小说进行爬取
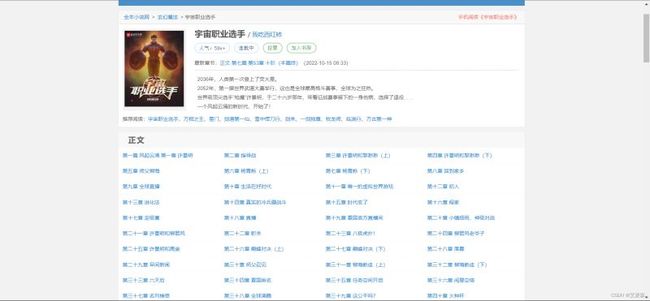
然后通过分析网页源代码分析每章小说的链接

找到链接的位置后,我们使用Xpath来进行链接和每一章标题的提取

在这里,因为涉及到多次使用requests发送请求,所以这里我们把它封装成一个函数,便于后面的使用

每一章的链接获取后,我们开始进入小说章节内容页面进行分析

通过网页分析,小说内容都在网页源代码中,属于静态数据

这里我们选用re正则表达式进行数据提取,并对最后的结果进行清洗

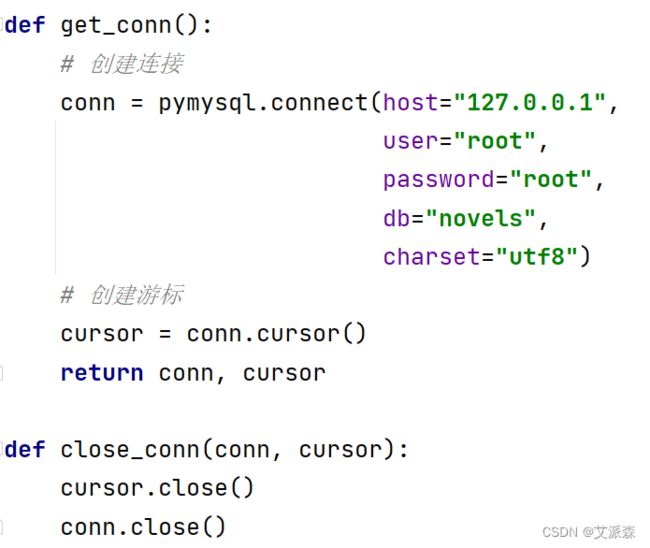
然后我们需要将数据保存到数据库中,这里我将爬取的数据存储到mysql数据库中,先封住一下数据库的操作
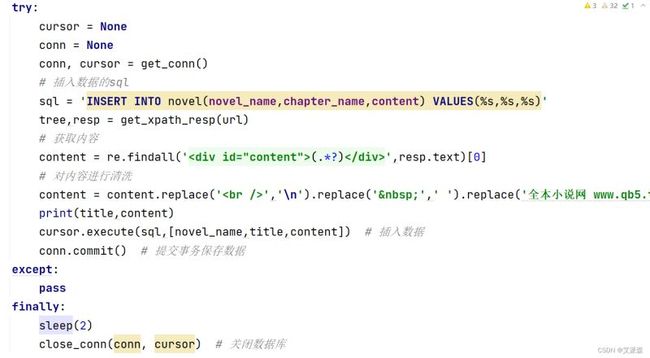
接着将爬取到是数据进行保存
最后一步就是使用多线程来提高爬虫效率,这里我们创建了5个线程的线程池

源代码及结果截图:
import requests
from lxml import etree
import re
import pymysql
from time import sleep
from concurrent.futures import ThreadPoolExecutor
def get_conn():
# 创建连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="root",
db="novels",
charset="utf8")
# 创建游标
cursor = conn.cursor()
return conn, cursor
def close_conn(conn, cursor):
cursor.close()
conn.close()
def get_xpath_resp(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
resp = requests.get(url, headers=headers)
tree = etree.HTML(resp.text) # 用etree解析html
return tree,resp
def get_chapters(url):
tree,_ = get_xpath_resp(url)
# 获取小说名字
novel_name = tree.xpath('//*[@id="info"]/h1/text()')[0]
# 获取小说数据节点
dds = tree.xpath('/html/body/div[4]/dl/dd')
title_list = []
link_list = []
for d in dds[:15]:
title = d.xpath('./a/text()')[0] # 章节标题
title_list.append(title)
link = d.xpath('./a/@href')[0] # 章节链接
chapter_url = url +link # 构造完整链接
link_list.append(chapter_url)
return title_list,link_list,novel_name
def get_content(novel_name,title,url):
try:
cursor = None
conn = None
conn, cursor = get_conn()
# 插入数据的sql
sql = 'INSERT INTO novel(novel_name,chapter_name,content) VALUES(%s,%s,%s)'
tree,resp = get_xpath_resp(url)
# 获取内容
content = re.findall('(.*?)
',resp.text)[0]
# 对内容进行清洗
content = content.replace('
','\n').replace(' ',' ').replace('全本小说网 www.qb5.tw,最快更新宇宙职业选手最新章节!
','')
print(title,content)
cursor.execute(sql,[novel_name,title,content]) # 插入数据
conn.commit() # 提交事务保存数据
except:
pass
finally:
sleep(2)
close_conn(conn, cursor) # 关闭数据库
if __name__ == '__main__':
# 获取小说名字,标题链接,章节名称
title_list, link_list, novel_name = get_chapters('https://www.qb5.tw/book_116659/')
with ThreadPoolExecutor(5) as t: # 创建5个线程
for title,link in zip(title_list,link_list):
t.submit(get_content, novel_name,title,link) # 启动线程


到此这篇关于Python7个爬虫小案例详解(附源码)上篇的文章就介绍到这了,其他两个部分的内容(中、下篇)请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!