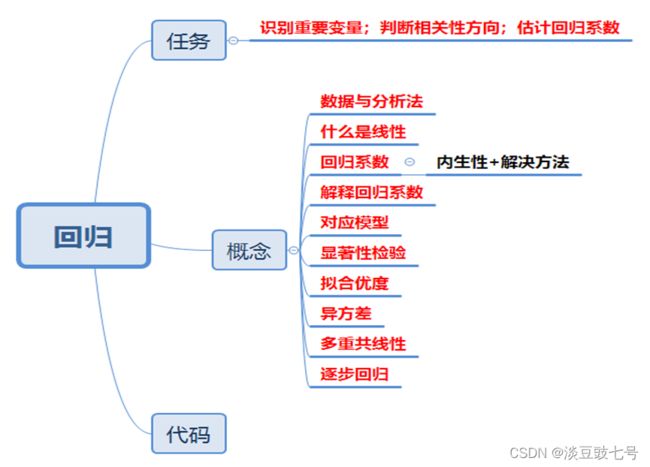
数学建模学习1.22——多元回归分析
清风老师课程
目录
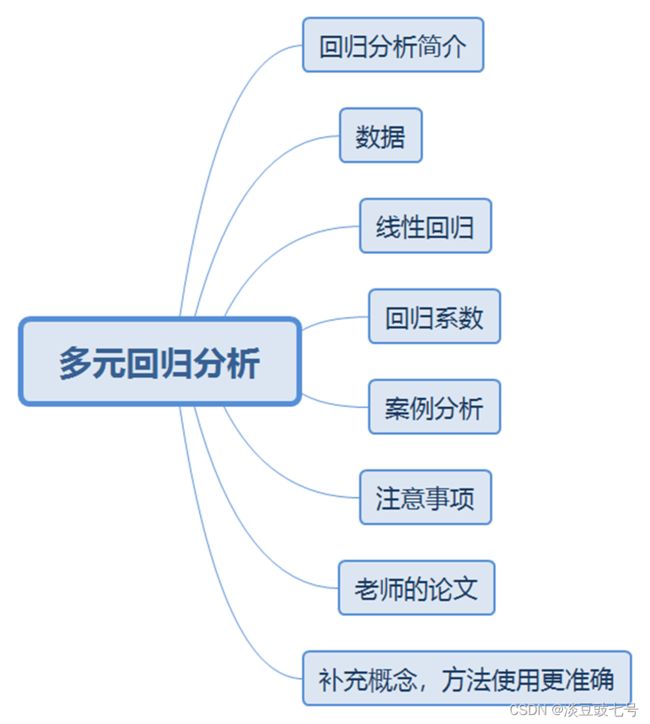
一、回归分析简介
二、数据分类与数据处理方法
三、线性回归
四、回归系数的解释与模型分类
五、回归实例
六、错误论文分析
七、清风老师的毕业论文讲解
八、异方差,多重共线性和逐步回归
一、回归分析简介






二、数据分类与数据处理方法
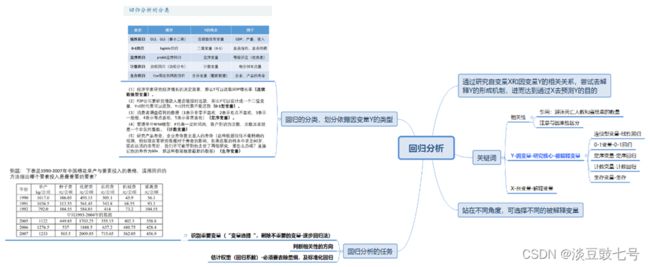
1.数据分类
(1)横截面数据(Cross Sectional Data)
在某一时点收集的不同对象的数据。

(2)时间序列数据(Time Series Data)
对同一对象在不同时间连续观察所取得的数据。

(3)面板数据(Panel Data)
(1)(2)综合起来——横截面数据与时间序列数据综合起来的一种数据资源
例如:2008-2018年,我国各省份GDP数据。
2.数据处理方法

注:
(1)时间序列数据——前四种建模方法最常用,时间序列数据用来预测居多。
(2)回归的建模方法用的较多
(3)学习计量经济学
(4)收集数据的网站 提供过的网站
微观数据:市面上很少,研究的单位很小,很少有研究机构研究
【简道云汇总】110+数据网站
http://link.jiansaoyun.com/f/5cc652cc2cf3b22fb7819189
虫部落数据搜集
http://data.chongbuluo.com/
【汇总】数据来源/大数据平台
大数据导航-大数据工具导航-199IT大数据导航-199IT大数据工具导航-Hao.199it.com
数据平台
大数据查询导航 - HiPPTER | PPT资源导航 | PPT模板下载

上面的数据多半都是宏观数据,微观数据市面上很少
大家可以在人大经济论坛搜索
https://bbs.pinggu.org/
也可以自己学习爬虫
Python等软件爬取(需要编程基础,实际学习起来不困难)
网易云课堂:零基础21天搞定Python分布法宠
傻瓜式软件爬取(八爪鱼)
学习网站:https://space.bilibili.com/186546950/video
(5)B题一般都会给出数据,需要自己进行数据清洗或数据预处理。自己搜集数据使论文非常饱满丰富。
三、线性回归
1.一元线性回归
(1)引入:一元线性函数拟合
找出k和b——看点到直线距离之和最近,需要求出绝对值,绝对值之和要最小,是优化类问题,不方便求解


注:没有强调自变量和因变量

残差平方和要最小
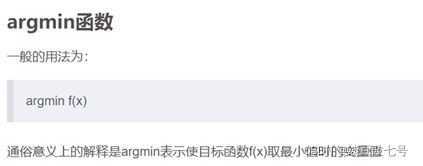
(3)线性的理解

线性假定并不要求初始模型都呈上述的严格线性关系,自变量和因变量可以通过变量变换而转化成线性模型。

使用线性回归模型进行建模前,需要对数据进行预处理。用Excel、Matlab、Stata软件等都可以进行数据清洗/数据处理。
注:
Excel操作
- 求自然对数的函数 =ln(xx);=log(xx,EXP(1))
- 下拉/鼠标放在表格右下方+后双击
- 求平方=xx^2
- 求乘积=x1*x2
(4)回归系数的解释

注意:
- 要加上“平均”二字,否则不够严密;
- 产品价格要纳入模型中,否则会遗漏变量;
- 站在样本个体的角度,y需要加下标i,
- 站在总体的角度,不需要加下标,写法均可;
- 自己写论文可以不考虑截距的含义,没有多少现实意义;
- 主要分析回归系数的意义;
- 引入新的变量后,回归系数变化很大——遗漏变量导致的内生性
- 内生性的理解

一定条件:外生性
内生性会导致回归系数不满足无偏性和一致性
无偏性:

一致性(大样本):理解-只要样本足够大,不论估计值是否满足无偏性,估计值都接近真实值

注:
a)误差项包括所有与y相关,但未添加到回归模型中的变量。

b)解决内生性的方法:找工具变量-新变量,更加复杂
c)内生性的危害:用蒙特卡罗模拟反映——
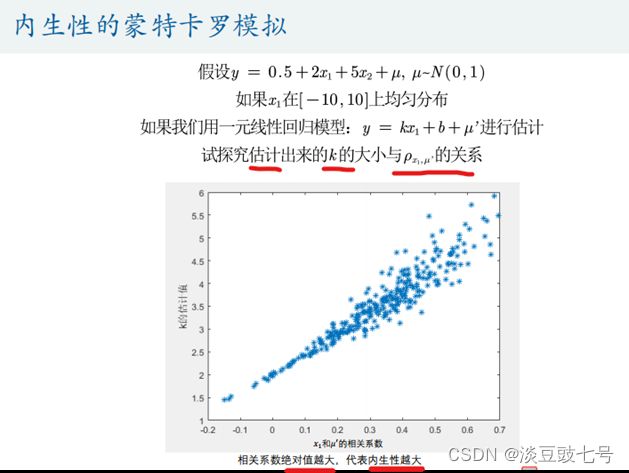
- 忽略价格x2,直接用x1模拟;比较估计出的k和x,u
 相关系数的关系;
相关系数的关系; - 相关系数(绝对值)越大,内生性越大。
- 相关系数为0时,即没有内生性时,k的估计值为2;
- 随着内生性严重,即相关系数增大,k的估计值与2相差越来越大,验证出内生性的危害——内生性使得回归系数估计不准确,不满足无偏性,回归系数有偏
d)构造内生性的环境:用matlab代码设置——代码如下
![]()
%% 蒙特卡洛模拟:内生性会造成回归系数的巨大误差
times = 300; % 蒙特卡洛的次数
R = zeros(times,1); % 用来储存扰动项u和x1的相关系数
K = zeros(times,1); % 用来储存遗漏了x2之后,只用y对x1回归得到的回归系数
for i = 1: times
n = 30/30000; % 样本数据量为n
x1 = -10+rand(n,1)*20; % x1在-10和10上均匀分布,大小为30*1
u1 = normrnd(0,5,n,1) - rand(n,1); % 随机生成一组随机数
x2 = 0.3*x1 + u1; % x2与x1的相关性不确定, 因为我们设定了x2要加上u1这个随机数
% 这里的系数0.3我随便给的,没特殊的意义,你也可以改成其他的测试。
u = normrnd(0,1,n,1); % 扰动项u服从标准正态分布
y = 0.5 + 2 * x1 + 5 * x2 + u ; % 构造y
k = (n*sum(x1.*y)-sum(x1)*sum(y))/(n*sum(x1.*x1)-sum(x1)*sum(x1)); % y = k*x1+b 回归估计出来的k
K(i) = k;
u = 5 * x2 + u; % 因为我们回归中忽略了5*x2,所以扰动项要加上5*x2
r = corrcoef(x1,u); % 2*2的相关系数矩阵
R(i) = r(2,1);
end
plot(R,K,'*')
xlabel("x_1和u'的相关系数")
ylabel("k的估计值")
![]()
总结:
- 取样本个数30-介于大样本和小样本之间。
- 样本个数取多少均可,可以调整样本量(大样本量与一致性有关),扰动项中包含x2。只需要相关系数矩阵中的一个值,就可得到相关系数。
- 将样本量改为30000,k还是不能达到2——内生性的危害:内生性使得回归系数估计不准确,不满足一致性。
e)要保证严格的外生性有很高的要求,怎么解决这个问题?
区分变量,保证和核心解释变量不相关

四、回归系数的解释与模型分类
复习——什么是假设检验









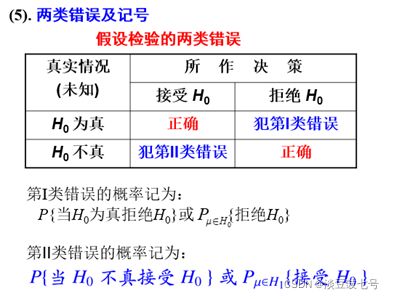


(一)预备知识
1.重点关注核心解释变量前的回归系数,该回归系数是否显著,需要用假设检验。

2.多元线性回归模型中的回归系数,被称为偏回归系数。

3.取对数——被解释变量对解释变量的弹性,百分比。
4.扰动项u需要满足的条件:无内生性;无异方差。

(二)模型分类(可以理解不了弹性含义,但是一定要会解释):
一元线性回归模型
双对数模型
半对数模型(解释变量/被解释变量)


(三)变量的转化
1.把定性变量转化为定量变量——引入虚拟变量X

2.假定扰动变量符合正态分布
3.δ0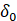 >0表示女性的平均工资大于男性的平均工资,反之。且.δ0
>0表示女性的平均工资大于男性的平均工资,反之。且.δ0![]() 显著地异于0才有意义。(显著异于看后面的解释)
显著地异于0才有意义。(显著异于看后面的解释)
虚拟变量的解释:

4.Success为二值变量,对照组设置(xx比xx),其余设置为虚拟变量,每次保证一个虚拟变量为1。之后用假设检验。
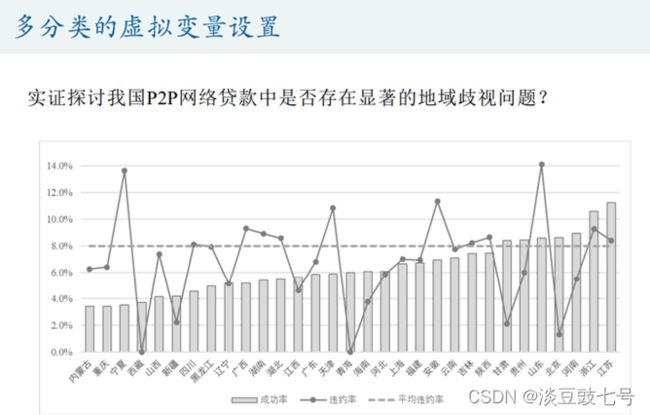
5.要计算出回归系数,需要避免完全多重共线性。为了避免完全多重共线性,引入虚拟变量数是分类数-1。

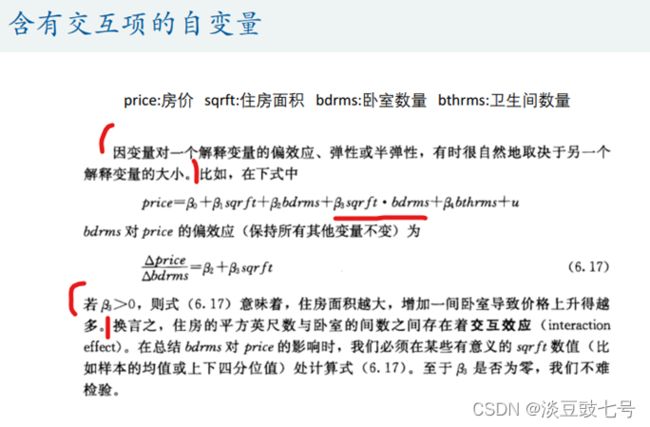
6.交互项——住房面积*卧室数量,引入交互项原因,四种模型——偏相关系数,即偏效应,同时考虑两个变量的影响。回归系数为正,交互效应为正向(系数要显著异于0)
 五、回归实例
五、回归实例

1.Excel的表格功能:数据全选点击插入-表格-包含标题,可以用下拉筛选
2.选用处理虚拟变量工具——Stata

(1)文件导入——Excel表格
(2)文件保存——创建.do文件
3.数据的描述性统计
(1)定量数据summarize 变量1 变量 2(简写:sum)
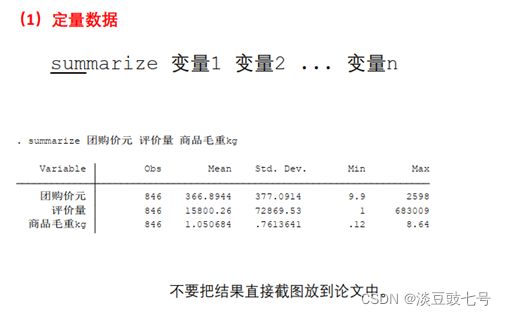
(2)把数据复制为表格放在Excel中制作成三线表再放到论文中
(3)写论文时养成好习惯不要直接截图粘贴
(4)pageup返回上一条命令,cls清屏
(5)定性数据tabulate 变量名,gen(A)
gen(A)可以创造虚拟变量。
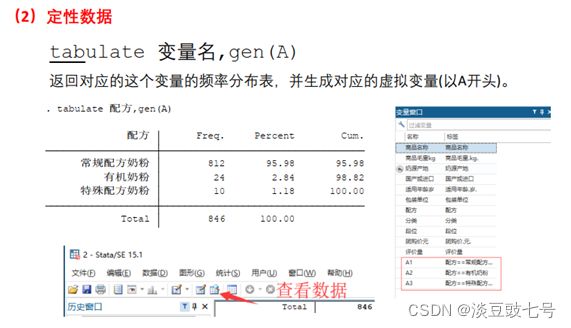
(6)使用stata能大大方便我们的运算。直接求出虚拟变量,数据编辑器(浏览)可以看虚拟变量,比用excel简单
(7)商品名称太多,数据描述性统计无意义。
以上部分对应的代码如下
![]()
// 按键盘上的PageUp可以使用上一次输入的代码(Matleb中是上箭头)
// 清除所有变量
clear
// 清屏 和 matlab的clc类似
cls
// 导入数据(其实是我们直接在界面上粘贴过来的,我们用鼠标点界面导入更方便 本条请删除后再复制到论文中,如果评委老师看到了就知道这不是你写的了)
// import excel "C:\Users\hc_lzp\Desktop\数学建模视频录制\第7讲.多元回归分析\代码和例题数据\课堂中讲解的奶粉数据.xlsx", sheet("Sheet1") firstrow
import excel "课堂中讲解的奶粉数据.xlsx", sheet("Sheet1") firstrow
// 定量变量的描述性统计
summarize 团购价元 评价量 商品毛重kg
// 定性变量的频数分布,并得到相应字母开头的虚拟变量
tabulate 配方,gen(A)
tabulate 奶源产地 ,gen(B)
tabulate 国产或进口 ,gen(C)
tabulate 适用年龄岁 ,gen(D)
tabulate 包装单位 ,gen(E)
tabulate 分类 ,gen(F)
tabulate 段位
![]()
(8)要把定性数据结果放在论文正文中,可以作图需要学好excel中的数据透视表功能。
数据透视表:添加字段;数据透视表分析工具作图;
绘制柱状图前对数据要排序,学会隐藏某些字段
(9)交叉项分析绘制数据透视图
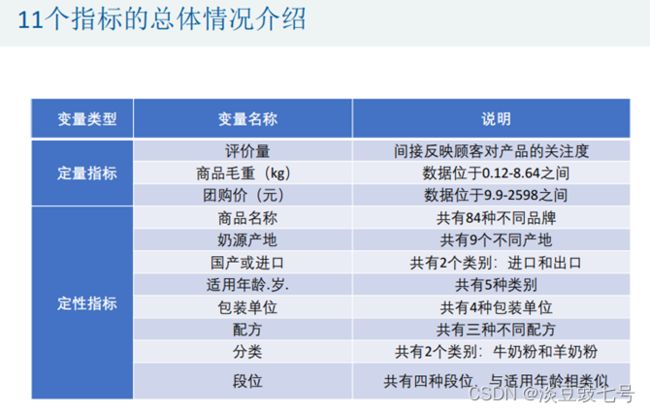
4.做一个指标汇总的表格一目了然(写作技巧)
5.Stata回归的语句
(1)regress y x1 x2 … xk (默认使用的OLS:普通最小二乘估计法)
GLS(广义最小二乘法,扰动项不符合条件时用此法)
方差分析表

(2)Model-SSR-回归平方和
Residual-SSE-误差平方和
Total-SST-总平方和
SS-对应的数值
![]() =
=![]()
df-自由度
MS-SS/df
一般只看SS和df对应的项


——《计量经济学-斯托克》RSS=SSE ESS=SSR
(4)联合显著性检验
关注:统计量是什么,原假设,p值<0.05。
回归出来系数都为0说明回归模型设置不合理。



(5)使用调整后的R2![]() 放到论文中,加上那句话。
放到论文中,加上那句话。

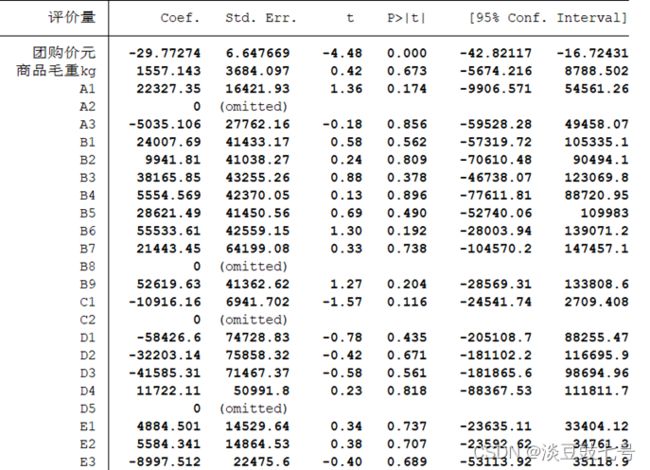
(6)检验回归系数用t统计量
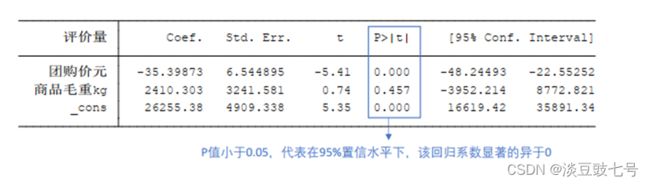
回归系数表
(7)cons——常数项β0![]()
(8)coef.——对应的回归系数β1β2![]() 使用点估计
使用点估计
(9)Std.Err——标准误差,用来计算t统计量的值
(10)原假设H0:β1=0![]() ,p<0.05拒绝原假设
,p<0.05拒绝原假设
(11)Conf.Intervall——置信区间
加入定性数据——段位回归
reg 评价量 G1 G2 G3 G4
note:G4 omitted because of collinearity(因为多重共线性的影响)

所以G4被看作为对照组,分析解读:
在其他变量不变的条件下,段位为1的评价量比段位为4的小7595.045
代码1:
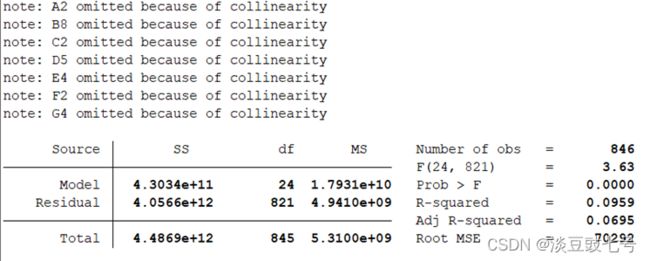
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2
> D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4
代码2:
// 下面进行回归
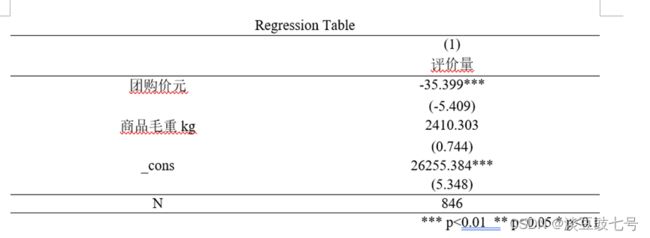
regress 评价量 团购价元 商品毛重kg
// 下面的语句可帮助我们把回归结果保存在Word文档中
// 在使用之前需要运行下面这个代码来安装下这个功能包(运行一次之后就可以注释掉了)
// ssc install reg2docx, all replace
// 如果安装出现connection timed out的错误,可以尝试换成手机热点联网,如果手机热点也不能下载,就不用这个命令吧,可以自己做一个回归结果表,如果觉得麻烦就直接把回归结果截图。
est store m1
reg2docx m1 using m1.docx, replace
// *** p<0.01 ** p<0.05 * p<0.1
// Stata会自动剔除多重共线性的变量
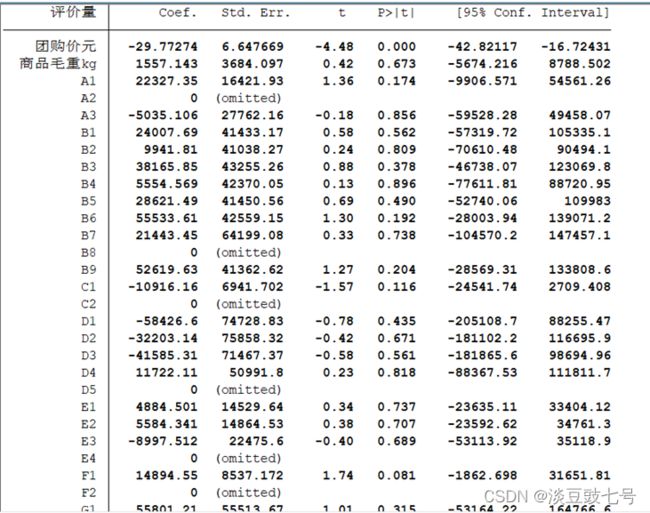
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4
est store m2
reg2docx m2 using m2.docx, replace
(12)在A1 A2 A3中随机选择一个作为对照组变量忽略掉,以避免多重共线性
(13)word文档要调整字体,两步走。
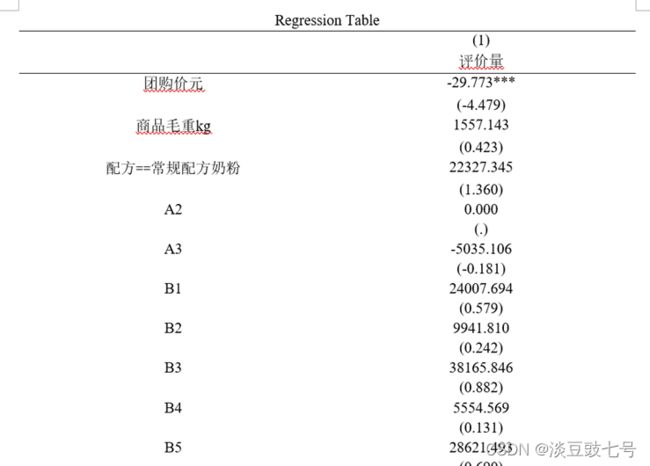
(14)()里面是检验值,即t检验值,这张表格可以放在论文中
(15)表格中文字替换后放到论文中
6.预测性回归可以看作是拟合,要求![]() 很大
很大
7.lny对lnx的回归——经济学上是弹性
8.预测性回归![]() 很小怎么办?调整模型,数据取对数或者平方——高维数据拟合
很小怎么办?调整模型,数据取对数或者平方——高维数据拟合
9.使用解释型回归较多,解释回归中![]() 很小,原因:数据中可能存在异常值或者数据分布极度不均匀
很小,原因:数据中可能存在异常值或者数据分布极度不均匀

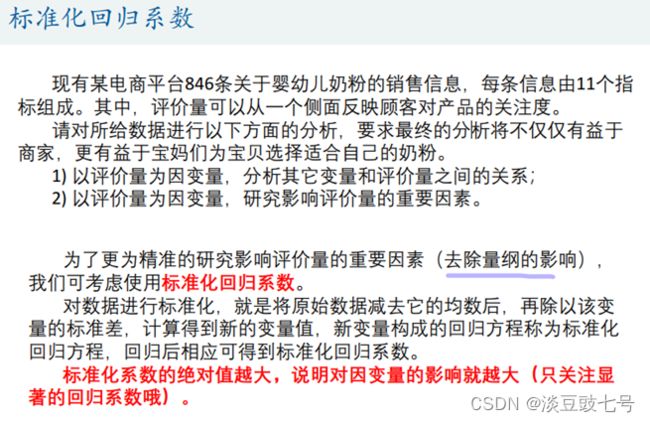
使用标准化回归

六、错误论文分析
1.对数据归一化处理存在很大问题——数据含义没法解释
2.存在问题:回归系数是什么?以及哪个回归系数是显著的?
3.先看是否通过联合显著性检验——通过证明模型没有问题
接着看回归系数与对应p值——找在一定置信区间下是显著的量,置信区间不要包含0
4.拟合优度R2不需要加入那么多变量,模型太复杂没法解释。
5.分析重要因素用标准化回归就行,不用那么复杂。
// 补充语法 (大家不需要具体的去学Stata软件,掌握我课堂上教给大家的一些命令应对数学建模比赛就可以啦)
// 事实上大家学好Excel,学好后应对90%的数据预处理问题都能解决
// (1) 用已知变量生成新的变量
generate lny = log(评价量)
generate price_square = 团购价元 ^2
generate interaction_term = 团购价元*商品毛重kg
七、清风老师的毕业论文讲解
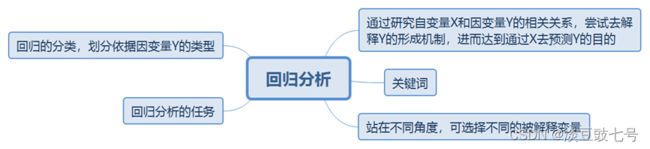
目的:通过论文加深对回归的理解;
对excel有更好的认识,如何分析大量的数据;
熟悉用excel统计图的制作。
P2P网络借贷中的地域歧视现象研究
——基于 “人人贷”平台的经验数据
1.选题的背景和意义——借款人具有信息优势,所以会提供借款人信息


2.文献综述
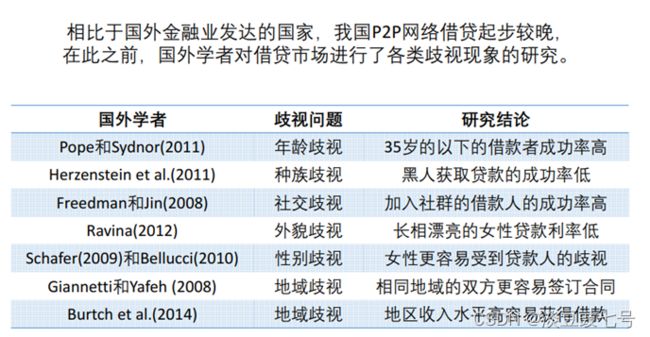
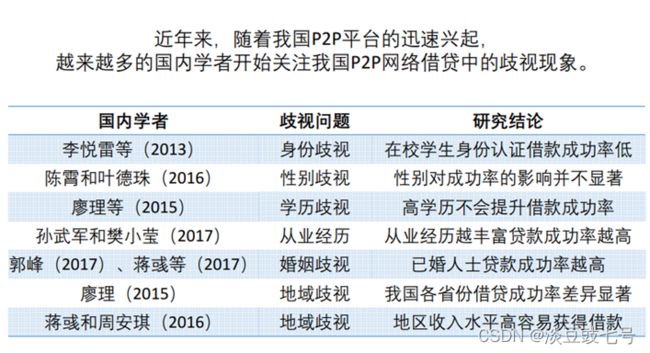
3.创新之处

异质性:百度百科
异质性(Heterogeneity)是指一些事物在某些特征上存在差异。在Meta分析中,异质性指纳入的不同研究之间存在的差异。当研究间存在异质性时,合并的结果可能是不可靠的,或合并本身就是不恰当的。因此在做Meta分析时,需要识别和测量异质性,并制定相应的策略探索异质性。
在系统评价中,研究间任何种类的变异被称为异质性。异质性主要包含三类:①临床异质性:所研究的受试者、干预措施和结局的变异;②方法学异质性:研究设计中的多样性和偏倚风险;③统计学异质性:在不同研究中所评估的干预效应中的多样性,其为临床异质性和方法学异质性的结果 [1] 。
如果个体研究结果的可信区间重叠较少,这通常表明存在统计学异质性。异质性检验是定量地评估异质性大小的方法,即通过统计学方法检验异质性。常用的检验异质性的方法有卡方检验Q统计量和I2统计量 [2] 。卡方检验评价了观测结果间的差异是否仅由机遇所致。但异质性检验方法存在一定的局限性,如当研究样本量小时,其检验效能较低,意味着有统计学意义的结果可能表明存在异质性问题;当Meta分析纳入很多研究时,有较高的检验效能可能检出无临床意义的少量异质性。
4.数据来源

港澳台数据太少
5.数据说明
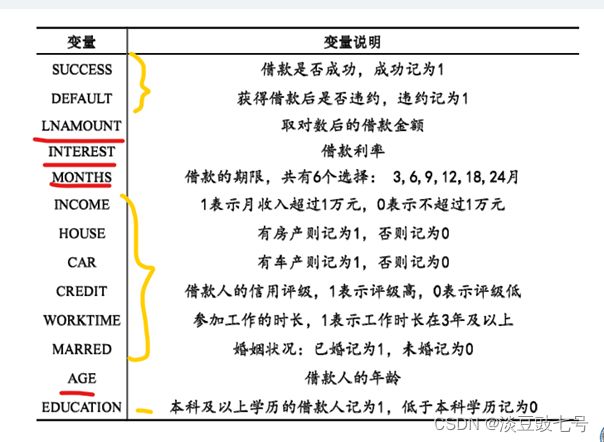
6.数据的描述性统计
stata:summarize
excel:打开数据分析,百度对应的版本操作方法

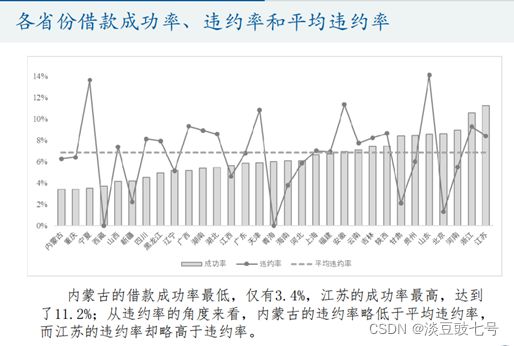
7.各个省份借贷样本数、成功率和违约率
主要掌握视频中的excel操作

8.检验地域歧视是否存在的模型(1)

(1)回归结果
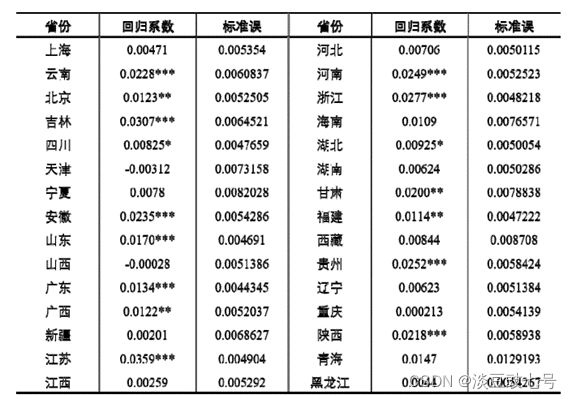
(2)回归结果的可视化

回归可以控制其他的变量
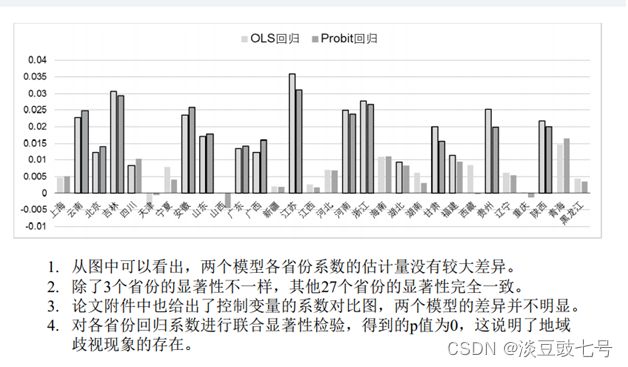
(3)各省份系数的回归结果
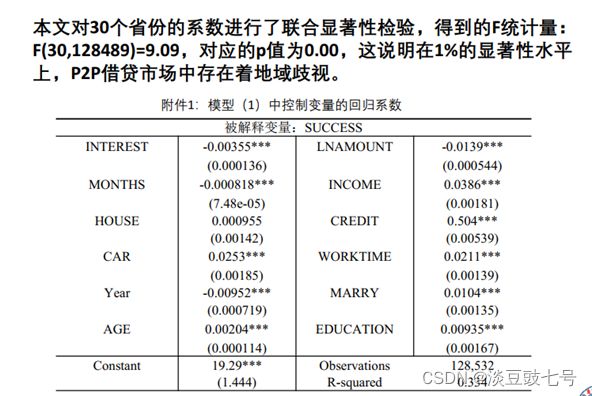
9.研究地域歧视的异质模型(2)

(1)地域歧视对学历的异质性
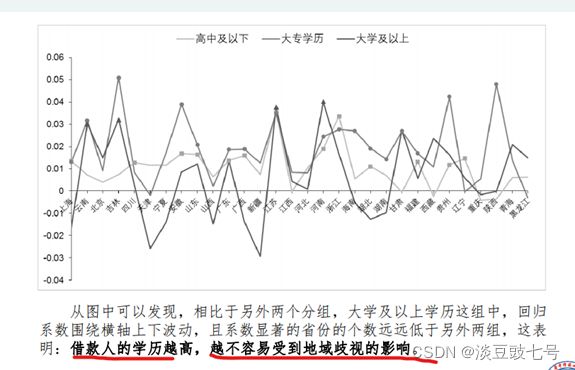
(2)借款人年龄的频数分布直方图
excel + ppt加工而成
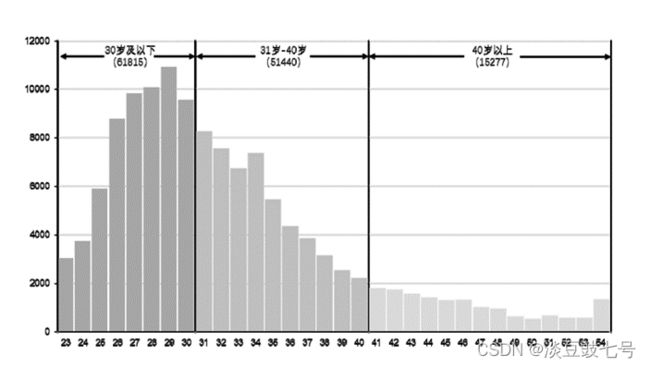 (3)地域歧视对年龄的异质性
(3)地域歧视对年龄的异质性
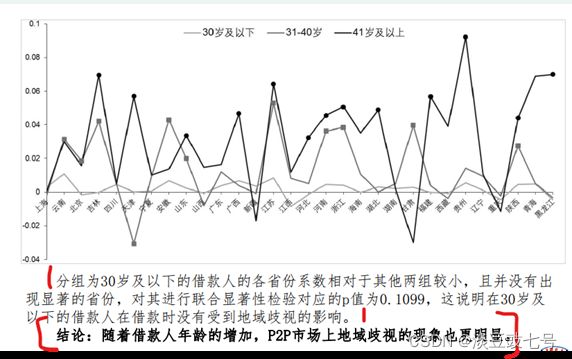
10.地域歧视是否理性的理论

11.判断地域歧视是否理性的模型(3)

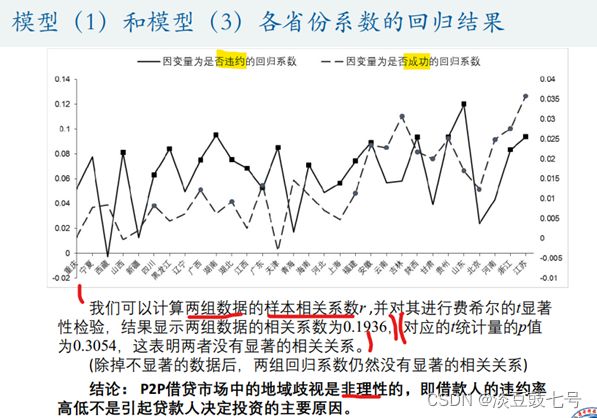
12.
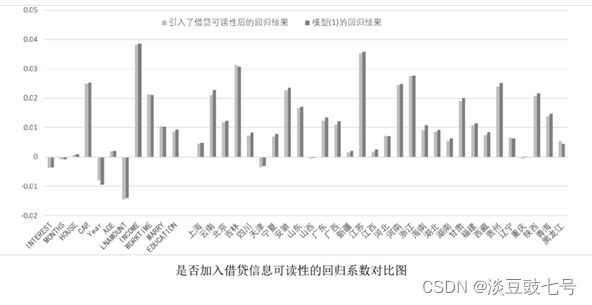
(1)稳健性检验:更改地域歧视的研究对象
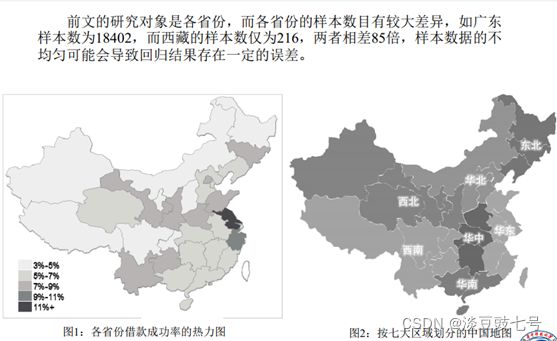
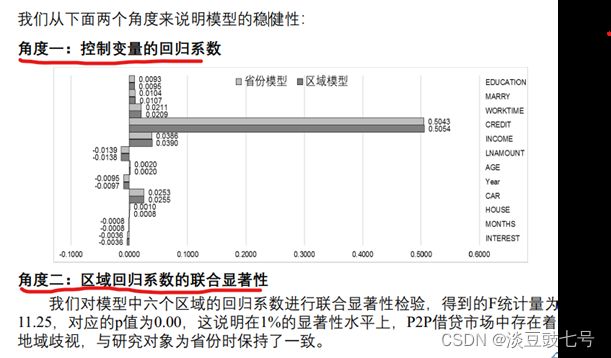
(2)稳健性检验:更改计量方法

(3)稳健性检验:加入其他控制变量

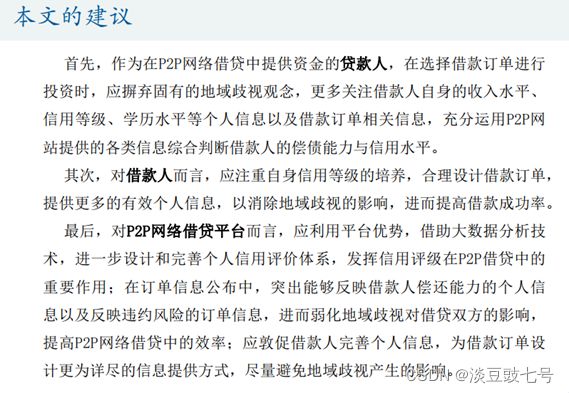
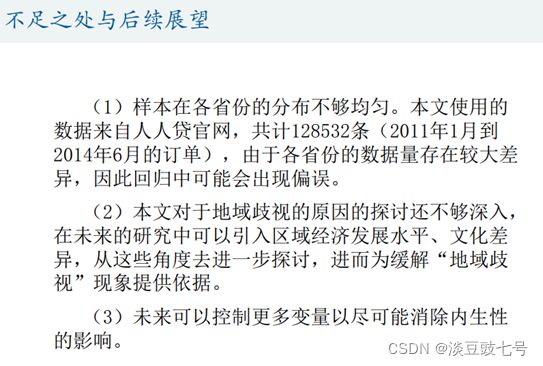
13.研究结论

二值变量——一般用logit回归或者probit回归
八、异方差,多重共线性和逐步回归
引入:扰动项要满足的条件
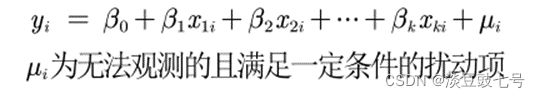

1.异方差
百度百科:
异方差性是相对于同方差而言的。所谓同方差,是为了保证回归参数估计量具有良好的统计性质,经典线性回归模型的一个重要假定:总体回归函数中的随机误差项满足同方差性,即它们都有相同的方差。如果这一假定不满足,即:随机误差项具有不同的方差,则称线性回归模型存在异方差性。
异方差性是计量经济学术语。指回归模型中扰动项的方差不全相等。假设线性回归模型y=Xβ+ε 中,扰动项 ε 的分量εi(i=1,2,…,n) 是均值为零,彼此独立的,但Varεi=σi2 不全相等,在这种情况下。OLS 估计虽然具有无偏性和一致性,却不是最优线性无偏估计。因此在预测Y时 波动较大。为此,在应用 OLS 方法之前要对模型的异方差性进行检验,并设法消除异方差性。
(1)影响:即使存在异方差,OLS估计出来的回归系数也是无偏一致的。
(2)产生问题:假设检验失效——回归系数的标准误SE失效—构造的统计量失效。
(3)OLS估计量不再是最优线性无偏估计量(BLUE)。
(4)解决异方差方法

(4)包含信息较多可以理解为信息较为重要,权重赋予更多

2.检验异方差
rvfplot (画残差与拟合值的散点图)
rvpplot x (画残差与自变量x的散点图)
(1)图形方法用stata绘图——拟合值较小时数据无波动,拟合值较大时数据波动较大,所以存在异方差。f——代表拟合值
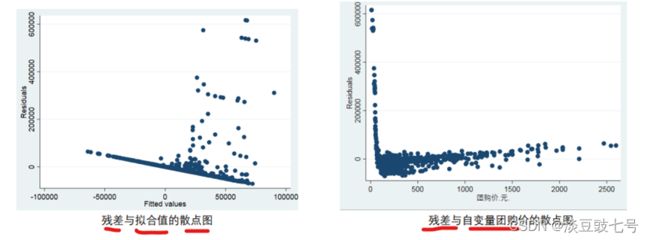
(2)评价量应该是整数但是出现了负数——评价量分布极度不均匀
(3)检验异方差的两种假设检验

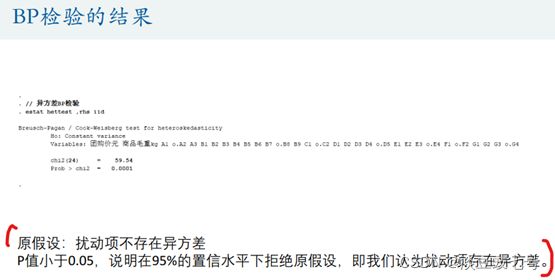
BP检验——怀特检验的特例——对应卡方分布
怀特检验——推荐使用
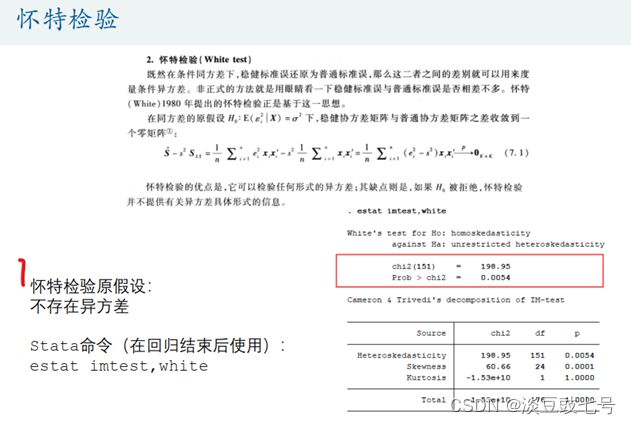
(4)检验异方差可以让思路更加严谨
3.异方差的处理方法
忽略异方差,只能得到两个显著的自变量;
处理后,可以得到更多显著的自变量,更容易解释
sem,(全称Standard Error of Mean)中文名标准误,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度。其公式为S=√(PxQ)/n。
英文:Standard Error of Mean
标准误,即样本均数的标准差,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度,反映的是样本均数之间的变异。标准误不是标准差,是多个样本平均数的标准差。
标准误用来衡量抽样误差。标准误越小,表明样本统计量与总体参数的值越接近,样本对总体越有代表性,用样本统计量推断总体参数的可靠度越大。因此,标准误是统计推断可靠性的指标。
(1)使用OLS+稳健的标准误
论文中加一句话:
(2)广义最小二乘法GLS


4.多重共线性
百度百科:
多重共线性是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。
一般来说,由于经济数据的限制使得模型设计不当,导致设计矩阵中解释变量间存在普遍的相关关系。完全共线性的情况并不多见,一般出现的是在一定程度上的共线性,即近似共线性。
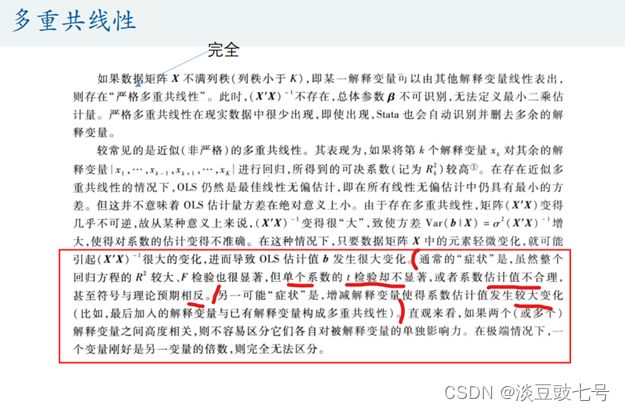
a.存在完全多重共线性时,总体参数b不可识别,stata可以帮助删除完全多重共线性,但是对于近似的多重共线性无效。
b.存在严重多重共线性会使系数估计变得不准确。
5.检验多重线性
使用的新概念:方差膨胀因子
方差膨胀系数(variance inflation factor,VIF)是衡量多元线性回归模型中复 (多重)共线性严重程度的一种度量。它表示回归系数估计量的方差与假设自变量间不线性相关时方差相比的比值。
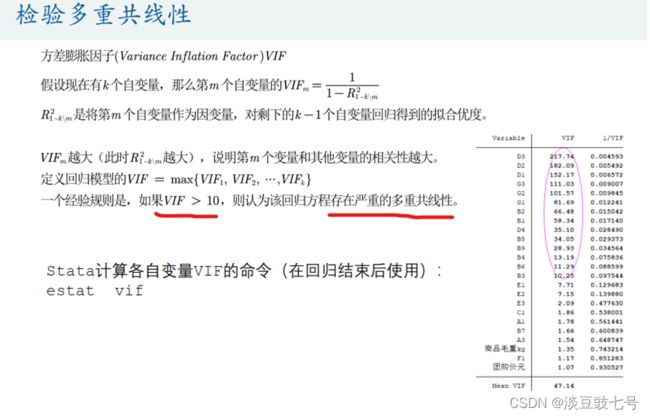
6.处理多重共线性
(1)预测解释变量——不用管
(2)关心具体回归系数——2种情况
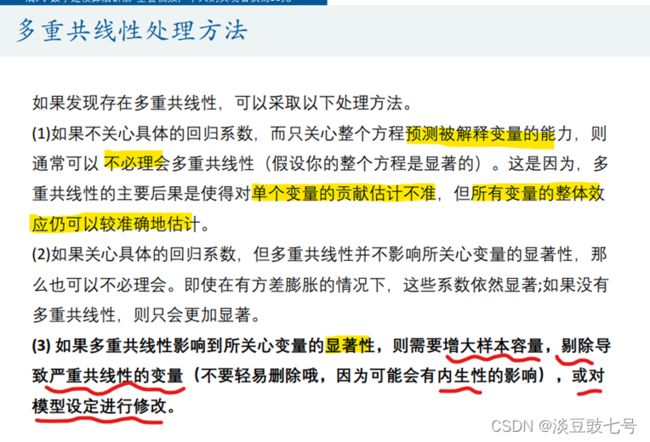
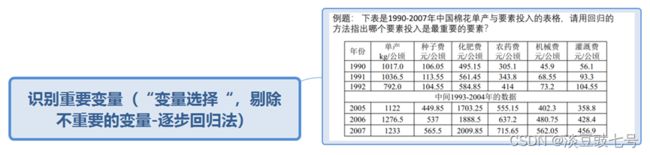
7.逐步回归
可以用来解决多重共线性的问题
(1)向前逐步回归Forward selection——自变量逐个引入模型,进行检验(使用t检验或F检验)

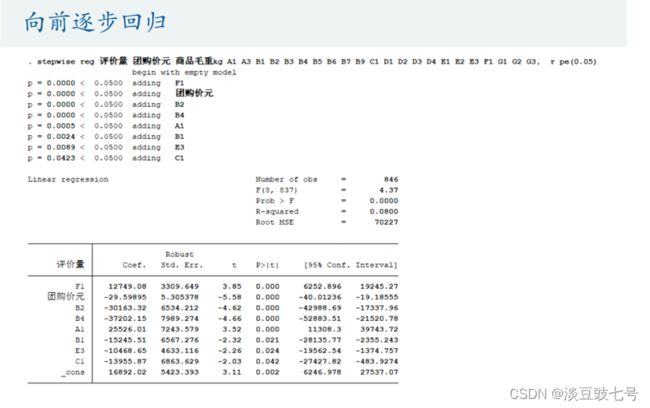
(2)向后逐步回归Backward elimination——逐个剔除不显著的自变量(更加推荐)
实现逐步回归

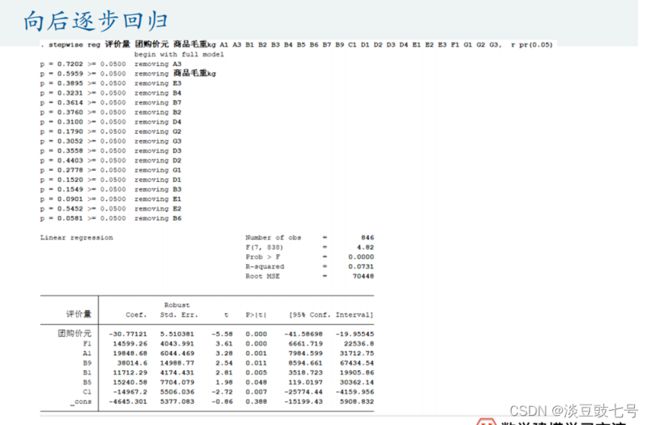


regress——可以直接说明多重共线性的自变量
stepwise——需要手动去除
(3)两种方法的说明
a.数学建模比赛比较短可以使用逐步回归,但是在写论文中需要认真考虑
b.全局筛选不现实
c.最后对留下的显著的自变量进行分析即可

参考代码
// 下面进行回归
regress 评价量 团购价元 商品毛重kg
// 下面的语句可帮助我们把回归结果保存在Word文档中
// 在使用之前需要运行下面这个代码来安装下这个功能包(运行一次之后就可以注释掉了)
// ssc install reg2docx, all replace
// 如果安装出现connection timed out的错误,可以尝试换成手机热点联网,如果手机热点也不能下载,就不用这个命令吧,可以自己做一个回归结果表,如果觉得麻烦就直接把回归结果截图。
est store m1
reg2docx m1 using m1.docx, replace
// *** p<0.01 ** p<0.05 * p<0.1
// Stata会自动剔除多重共线性的变量
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4
est store m2
reg2docx m2 using m2.docx, replace
// 得到标准化回归系数
regress 评价量 团购价元 商品毛重kg, b
// 画出残差图
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4
rvfplot
// 残差与拟合值的散点图
graph export a1.png ,replace
// 残差与自变量团购价的散点图
rvpplot 团购价元
graph export a2.png ,replace
// 为什么评价量的拟合值会出现负数?
// 描述性统计并给出分位数对应的数值
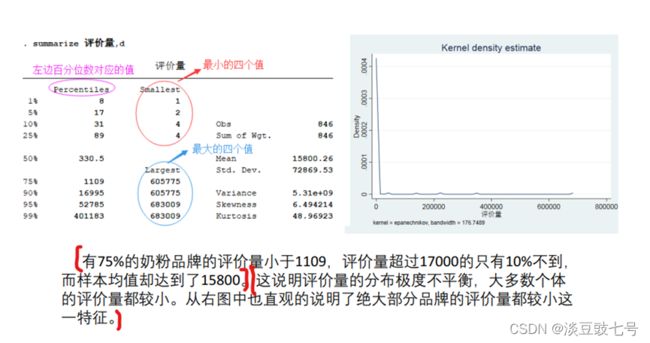
summarize 评价量,d
// 作评价量的概率密度估计图
kdensity 评价量
graph export a3.png ,replace
// 异方差BP检验
estat hettest ,rhs iid
// 异方差怀特检验
estat imtest,white
// 使用OLS + 稳健的标准误
regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4, r
est store m3
reg2docx m3 using m3.docx, replace
// 计算VIF
estat vif
// 逐步回归(一定要注意完全多重共线性的影响)
// 向前逐步回归(后面的r表示稳健的标准误)
stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r pe(0.05)
// 向后逐步回归(后面的r表示稳健的标准误)
stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r pr(0.05)
// 向后逐步回归的同时使用标准化回归系数(在r后面跟上一个b即可)
stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r b pr(0.05)
总结: