Paddle进阶实战系列(一):保险文本视觉认知问答
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
保险文本视觉认知问答
1.项目介绍
1.1背景
随着人工智能技术的逐渐成熟,计算机视觉、语音、自然语言处理等技术在金融行业的应用从广度和深度上都在加速,这不仅降低了金融机构的运营和风险成本,而且有助于提升客户的满意度,比如利用NLP 技术实现智能问答解决方案,帮助用户即使没有复杂的金融背景知识也能快速找到自己需要的信息,而在寿险、产险、健康险等保险的理赔流程和客户服务环节中,存在大量扫描文档,例如医疗票据、费用清单、病例等。对这些扫描文档进行文字检测与识别,并且提取出结构化信息,可以用于极速理赔、个人健康管理等业务场景。

在保险领域,用户常见的问题占了60%~70%,这部分重复性工作费时费力,需要更有效率的处理方式。智能问答能够准确理解用户的意图,并直接给出精确的答案,极大节省了用户及工作人员的时间。
1.2.项目任务分析
本次任务需要将提供面向保险场景的扫描图片数据集,利用OCR技术自动识别影像资料后,再通过AI智能判断所识别文字的内在逻辑,回答关于图片的自然语言问题。问题的答案是可以从图片中提取的任何文本/标记。
输入: 保险场景的扫描文档(例如:医疗票据)+ 自然语言提问(例如:病人服用的药品清单有什么?)
输出: 对应自然语言提问的事实性答案.
-
分析: 根据不同文档图片数据集进行OCR识别,对问题和回答进行建模,保证一定准确率,技术涉及到OCR+NLP。
-
难点: 照片拍摄角度不同,字体混合手写,一张图片可能由多张票据混合,背景噪声影响识别效果,考虑使用多种模型对比。
项目链接:见文末!
项目框架:使用paddle框架将OCR与NLP技术相结合
PaddleOCR流程

1.3 参考资料:
基于Paddle实现baseline项目参考:AIWN保险文本视觉认知问答
优秀方案参考:DocVQA冠军方案分享
PaddleOCR官方资料库
PaddleNLP官方资料库
2.数据集
2.1数据简介
- 本次大赛提供的数据集使用的扫描文件类型包括票据、说明、报告等20 多种。混合了印刷、打字和手写的内容。
- 训练集有5000余张左右原始扫描文件及对应的 4万余个自然语言问答标注。提供的数据均已做了标注及脱敏。
2.1.1 训练集
-
训练集数据包括:
- image:包含所有原始扫描文件图像
- train.csv:问答训练库,包含序号(index)、问题 ID(quesiton_id)、图片名称(filename)、问题(question_text)、答案(answer_text),共 5 列
- readme:数据说明文档
字段说明:
-
训练集用于模型训练,数据字段包括以下内容:
1、index:序号
2、question_id:问题的唯一id标识
3、filename:问题对应的唯一图片名称
4、question_text:问题描述
5、answer_text:问题对应的唯一答案
2.1.2 测试集
-
测试集数据规模为1000张左右原始扫描文件及对应的7000个自然语言问题,数据内容样例同训练集。
-
测试集包含以下3个文件:
- image:包含所有原始扫描文件图像
- test1.csv:问答测试库,包含序号(index)、问题 ID(quesiton_id)、图片路径(filename)、问题(question_text),共 4 列
- readme:数据说明文档
-
测试集用于模型验证,需提交问题对应答案结果,数据字段包括以下内容:
1、index:序号
2、question_id:问题的唯一id标识
3、filename:问题对应的唯一图片名称
4、question_text:问题描述
2.2数据展示
-
样例一:
- 提问: 西药费的金额是多少? 回答: 140.16
提问: 140.16元购买了什么药品? 回答: {甲}缘沙坦胶囊{基}
- 提问: 西药费的金额是多少? 回答: 140.16
-
样例二:
- 提问: 这是一份关于什么药品的说明? 回答: 十三味疏肝胶囊
提问: 药品的有效期是多久? 回答: 1.5年
- 提问: 这是一份关于什么药品的说明? 回答: 十三味疏肝胶囊
3.项目代码
使用PaddleOCR+PaddleNLP实现代码
参考项目原地址: https://github.com/datawhalechina/competition-baseline/tree/master/competition/AIWIN2021
3.1安装环境依赖包
# 安装paddleocr和paddlenlp
!pip install --user paddleocr==2.0.4 paddlenlp==2.0.0rc18!pip list!pip install pandas pillow matplotlib Ipython#解压数据集
!tar -xf data/data83016/dataset.tar -C dataimport pandas as pd
from PIL import Image
import codecs
import os
import matplotlib.pyplot as plt
# from IPython.display import set_matplotlib_formats
# %matplotlib inline
# set_matplotlib_formats('svg') # 输出为svg
df = pd.read_csv('data/train-utf8.csv')
df['filename'] = 'data/image/' + df['filename'] # 改为本地路径3.2 OCR阶段
ocr阶段生成位置及内容:
注:Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换参数依次为ch, en, french, german, korean, japan。
from paddleocr import PaddleOCR
import pandas as pd
from PIL import Image
import codecs
import os
import matplotlib.pyplot as plt
ocr = PaddleOCR(use_angle_cls=True, lang="ch", enable_mkldnn=True) # need to run only once to download and load model into memory
df = pd.read_csv('data/train-utf8.csv')
df['filename'] = 'data/image/' + df['filename'] # 改为本地路径
for path in df['filename'].unique():
print(path)
if os.path.exists('result/' + os.path.basename(path)[:-4] + '.txt'):
continue
result = ocr.ocr(path, cls=True)
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
for box, txt in zip(boxes, txts):
with codecs.open('result/' + os.path.basename(path)[:-4] + '.txt', 'a') as up:
up.write('{0}\t{1}\n'.format(box, txt))
In [ ]
#创建结果路径
!mkdir resultIn [ ]
#运行上述脚本,时间比较长,耐心等待即可
!python ocr.py输出结果展示:
[[394.0, 51.0], [459.0, 51.0], [459.0, 75.0], [394.0, 75.0]] 橘红丸
[[34.0, 125.0], [343.0, 125.0], [343.0, 137.0], [34.0, 137.0]] 说明书来源:广东宏兴集团股份有限公司宏兴制药厂
[[77.0, 169.0], [150.0, 169.0], [150.0, 186.0], [77.0, 186.0]] 【药品名称】
[[178.0, 169.0], [249.0, 169.0], [249.0, 186.0], [178.0, 186.0]] 【通用名称】
[[300.0, 169.0], [343.0, 169.0], [343.0, 186.0], [300.0, 186.0]] 橘红丸
[[178.0, 210.0], [248.0, 210.0], [248.0, 223.0], [178.0, 223.0]] 【汉语拼音】
[[300.0, 210.0], [379.0, 210.0], [379.0, 223.0], [300.0, 223.0]] JuhongWan
结果分析示例:
In [ ]
df.head(10) index question_id filename \
0 1 Q00001 data/image/c850b0d7018d127989d1b20d0f7118d66f5...
1 2 Q00002 data/image/c850b0d7018d127989d1b20d0f7118d66f5...
2 3 Q00003 data/image/c850b0d7018d127989d1b20d0f7118d66f5...
3 4 Q00004 data/image/c850b0d7018d127989d1b20d0f7118d66f5...
4 5 Q00005 data/image/c850b0d7018d127989d1b20d0f7118d66f5...
5 6 Q00006 data/image/c850b0d7018d127989d1b20d0f7118d66f5...
6 7 Q00007 data/image/c850b0d7018d127989d1b20d0f7118d66f5...
7 8 Q00008 data/image/c850b0d7018d127989d1b20d0f7118d66f5...
8 9 Q00009 data/image/c850b0d7018d127989d1b20d0f7118d66f5...
9 10 Q00010 data/image/AHEFGLB18921EAAA75R7_20210301111254...
question_text answer_text
0 这是什么药品? 茶碱缓释片
1 本说明书来源于哪里? 黑龙江鼎恒升药业有限公司
2 本品可通过什么屏障? 胎盘
3 说明书上方正中是什么字? 茶碱缓释片
4 左上角是什么字? 说明书来源:黑龙江鼎恒升药业有限公司
5 老年用药是下一项是什么? 药物相互作用
6 Theophylline Sustainde-release Tablets是药品的什么? 英文名
7 茶碱是指什么? 主要成份
8 198.18是指什么数? 分子量
9 太平洋产险全国统一保险消费投诉电话是哪个号码? 95500-3-4
In [ ]
Image.open(df['filename'].iloc[0])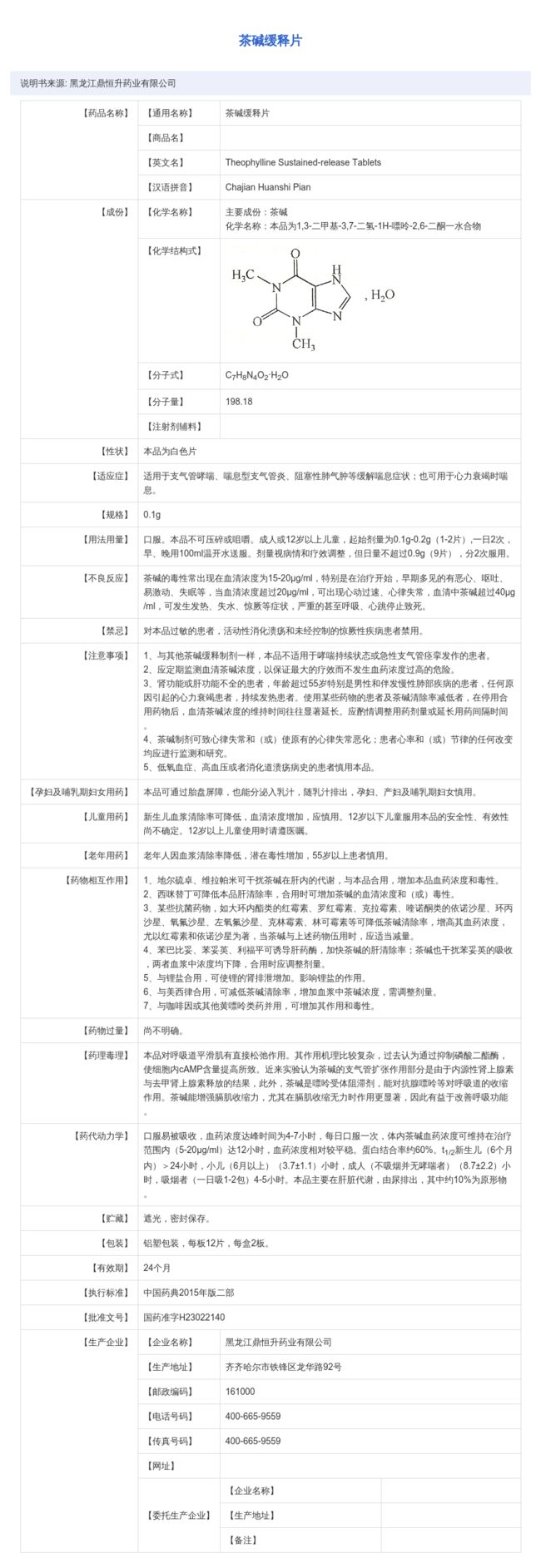
In [ ]
codecs.open('result/' + os.path.basename(df['filename'].iloc[0])[:-4] + '.txt').readlines()[:10]['[[374.0, 51.0], [476.0, 51.0], [476.0, 74.0], [374.0, 74.0]]\t茶碱缓释片\n', '[[33.0, 124.0], [274.0, 124.0], [274.0, 137.0], [33.0, 137.0]]\t说明书来源:黑龙江鼎恒升药业有限公司\n', '[[231.0, 167.0], [304.0, 170.0], [303.0, 187.0], [231.0, 184.0]]\t【通用名称】\n', '[[133.0, 170.0], [202.0, 170.0], [202.0, 185.0], [133.0, 185.0]]\t【药品名称】\n', '[[354.0, 169.0], [424.0, 169.0], [424.0, 187.0], [354.0, 187.0]]\t茶碱缓释片\n', '[[232.0, 209.0], [292.0, 209.0], [292.0, 226.0], [232.0, 226.0]]\t【商品名】\n', '[[231.0, 245.0], [291.0, 248.0], [290.0, 266.0], [231.0, 264.0]]\t【英文名】\n', '[[355.0, 248.0], [600.0, 248.0], [600.0, 264.0], [355.0, 264.0]]\tTheophylline Sustained-release Tablets\n', '[[233.0, 286.0], [304.0, 286.0], [304.0, 303.0], [233.0, 303.0]]\t【汉语拼音】\n', '[[356.0, 288.0], [488.0, 288.0], [488.0, 301.0], [356.0, 301.0]]\tChajian HuanshiPian\n']
3.3 自然语言处理
3.3.1 模型1:规则匹配
In [ ]
codecs.open('result/' + os.path.basename(df['filename'].iloc[80])[:-4] + '.txt').readlines()[:15]['[[150.0, 57.0], [470.0, 57.0], [470.0, 83.0], [150.0, 83.0]]\tPERSDNAL\n', '[[456.0, 57.0], [694.0, 57.0], [694.0, 83.0], [456.0, 83.0]]\tRESUME\n', '[[205.0, 276.0], [293.0, 276.0], [293.0, 304.0], [205.0, 304.0]]\t五百丁\n', '[[576.0, 276.0], [696.0, 276.0], [696.0, 307.0], [576.0, 307.0]]\t基本信息\n', '[[212.0, 328.0], [519.0, 328.0], [519.0, 341.0], [212.0, 341.0]]\t一句话介绍自己,告诉HR为什么选择你而不是别人\n', '[[575.0, 332.0], [633.0, 332.0], [633.0, 355.0], [575.0, 355.0]]\t画24岁\n', '[[576.0, 367.0], [629.0, 367.0], [629.0, 389.0], [576.0, 389.0]]\t国汉族\n', '[[577.0, 402.0], [657.0, 402.0], [657.0, 422.0], [577.0, 422.0]]\t广东广州\n', '[[35.0, 416.0], [154.0, 416.0], [154.0, 443.0], [35.0, 443.0]]\t(国)求职意向\n', '[[574.0, 436.0], [699.0, 430.0], [700.0, 453.0], [575.0, 459.0]]\tC13800138000\n', '[[36.0, 474.0], [132.0, 474.0], [132.0, 494.0], [36.0, 494.0]]\t幼儿园老师\n', '[[574.0, 471.0], [694.0, 466.0], [695.0, 486.0], [575.0, 490.0]]\t区[email protected]\n', '[[575.0, 533.0], [695.0, 533.0], [695.0, 562.0], [575.0, 562.0]]\t()技能特长\n', '[[34.0, 561.0], [155.0, 561.0], [155.0, 591.0], [34.0, 591.0]]\t()教育背景\n', '[[35.0, 619.0], [122.0, 619.0], [122.0, 633.0], [35.0, 633.0]]\t2013.9-至今\n']
In [ ]
df[df['question_text'].apply(lambda x: '邮箱是多少' in x)]
# 1、ocr识别图片
# 2、问题的意图
# 3、问题和ocr的结果进行匹配 index question_id filename \
96 97 Q00097 data/image/e506b03f95cfc0b0649e4edcdb2076300a9...
376 377 Q00377 data/image/a11b4e53ee1b706c0a01c626d4b53ee7712...
1954 1955 Q01955 data/image/e09b52455b9e351cf62b8537f4d06208a9c...
2088 2089 Q02089 data/image/word_1145.png
2812 2813 Q02813 data/image/03d0ce91ee87f4939e64470c700d69a9058...
2850 2851 Q02851 data/image/d326457bd0d87670c10e232ceef5a0ffecc...
2919 2920 Q02920 data/image/03d0ce91ee87f4939e64470c700d69a9058...
3153 3154 Q03154 data/image/fa964e762d3d2ab7595931c1d9bdd628475...
3169 3170 Q03170 data/image/e8c8044dd0ba4c1b7665be4005b6835f314...
3283 3284 Q03284 data/image/ecd226c3b1db5dec169dad321465287ffad...
5002 5003 Q05003 data/image/054260010acde733be26cd74ad7fff4b77b...
7032 7033 Q07033 data/image/c4b40cc2dc55ad0ce1909db20ab1d29fa36...
7471 7472 Q07472 data/image/ba12ed9453422ec07f2866a3e69d7701af5...
7538 7539 Q07539 data/image/cb3eb2eb4f42bdac18dd9634c08687422b8...
8862 8863 Q08863 data/image/word_1117.png
9725 9726 Q09726 data/image/d3dfd339afdfd79102cd5dc3508ef106dfc...
12592 12593 Q12593 data/image/d792e6f57fc699e729122b938777eee60b2...
13625 13626 Q13626 data/image/3266144112911b1370cbe9b0ebb78bce86c...
13767 13768 Q13768 data/image/f25e0d56fbe2f2cd7227bcadb30f3c5baca...
30950 30951 Q30951 data/image/AHEFBZ1Y2021M010251ATEMP_5249414_1.jpg
31092 31093 Q31093 data/image/11525741dee150c477b4cc598d934afa5d4...
31379 31380 Q31380 data/image/201907_71922e65-a8da-4b09-844d-8e55...
34193 34194 Q34194 data/image/4c42b2a394fea24bb8e41a2e6a0f35376bf...
34369 34370 Q34370 data/image/79dbb85c53a538fc9fe1d38dcc22d949920...
35070 35071 Q35071 data/image/201907_f0116bfd-948c-4b3b-8bb9-6f06...
35241 35242 Q35242 data/image/57cedc752dfc0f0037e2fc3771e51abe687...
35249 35250 Q35250 data/image/3dce2f8ef58180c531cbc8c9a271be4d30e...
35771 35772 Q35772 data/image/201907_f1d0da38-c6dc-426a-b4ee-a712...
40771 40772 Q40772 data/image/201907_f4b4c7c1-0c3e-41ed-afa3-1ddf...
question_text answer_text
96 邮箱是多少? [email protected]
376 五百丁邮箱是多少? [email protected]
1954 五百丁的邮箱是多少? [email protected]
2088 这张简历的邮箱是多少? [email protected]
2812 该证券中吴立的邮箱是多少? [email protected]
2850 五百丁的邮箱是多少? [email protected]
2919 图中杨烨辉的邮箱是多少? [email protected]
3153 五百丁的邮箱是多少? [email protected]
3169 五百丁的邮箱是多少? [email protected]
3283 五百丁的邮箱是多少? [email protected]
5002 研究助理:薛绍阳的邮箱是多少? [email protected]
7032 五百丁在简历上留的邮箱是多少? [email protected]
7471 五百丁的邮箱是多少? [email protected]
7538 五百丁邮箱是多少? [email protected]
8862 此人的邮箱是多少? [email protected]
9725 五百丁邮箱是多少? [email protected]
12592 五百丁的邮箱是多少? [email protected]
13625 五百丁的邮箱是多少? [email protected]
13767 五百丁的电子邮箱是多少? [email protected]
30950 投保人的电子邮箱是多少? 54564560134.com
31092 分析师金敏的邮箱是多少? [email protected]
31379 锤子的电子邮箱是多少? [email protected]
34193 五百丁的邮箱是多少? [email protected]
34369 五百丁的邮箱是多少? [email protected]
35070 这张简历的邮箱是多少? [email protected]
35241 五百丁的邮箱是多少? [email protected]
35249 五百丁的邮箱是多少? bd@500d,me
35771 邮箱是多少? [email protected]
40771 求职者锤子的邮箱是多少? docer @qq.com
In [ ]
import re
# 对于所有的数据集,迭代每一行
# 步骤1:判断OCR是否识别
for row in df.iloc[:].iterrows():
qs = row[1].question_text
# ocr是否识别成功
if not os.path.exists('ocr_result/'+os.path.basename(row[1]['filename'])[:-4] + '.txt'):
continue
# 读取ocr识别结果
ocrs = codecs.open('ocr_result/'+os.path.basename(row[1]['filename'])[:-4] + '.txt').readlines()[:]
# 文字
ocr_text = [x.split('\t')[1].strip() for x in ocrs]
# 文本框
ocr_box = [x.split('\t')[0].strip() for x in ocrs]
if re.findall('什么药品', qs):
# pass
print(row[1].answer_text, '\t', ocr_text[0])
elif re.findall('说明书来源于哪里', qs):
candicate_text = list(set([x for x in ocr_text if '说明书' in x]))
candicate_text = [x for x in candicate_text if '说明书' in x][0]
candicate_text = candicate_text.replace('说明书', '').replace('来源', '').replace(':', '')
print(row[1].answer_text, candicate_text)
pass
elif re.findall('什么大学什么专业', qs):
candicate_text = list(set([x for x in ocr_text if '大学' in x and '专业' in x]))
print(row[1].answer_text, candicate_text[0])
elif re.findall('什么大学', qs):
candicate_text = list(set([x for x in ocr_text if re.findall('大学', x)]))
if len(candicate_text) == 0:
continue
# print(row[1].answer_text, candicate_text[0])
elif re.findall('什么专业', qs):
candicate_text = list(set([x for x in ocr_text if re.findall('本科', x)]))
if len(candicate_text) == 0:
continue
# print(row[1].answer_text, candicate_text[0])
# elif re.findall('电话是多少', qs):
# continue
# # break
elif re.findall('邮箱', qs):
candicate_text = list(set([x for x in ocr_text if re.findall('@', x)]))
if len(candicate_text) == 0:
continue
print(row[1].answer_text, candicate_text[0])
# 没有匹配成功怎么办
# XX之后是什么?,最近的框里面的文本进行回答
# box信息,字的大小信息,字号
# ocr结果
# XX
# YY
# break
# break模型3.3.2 Bert
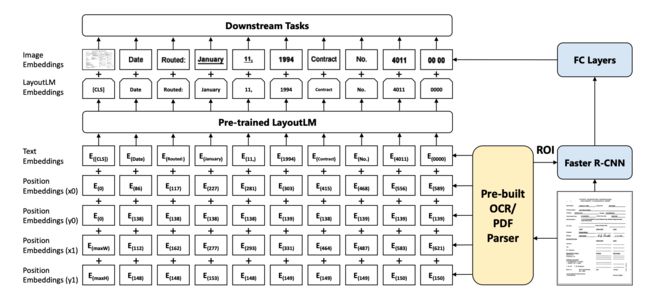
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
介绍:LayoutLM利用文本分布的板式信息和识别到的文字信息,基于bert进行大规模预训练,然后在SER和RE任务进行微调;LayoutLMv2在LayoutLM的基础上,将图像视觉信息引入预训练阶段,对多模态信息进行更好的融合;LayoutXLM将LayoutLMv2扩展到多语言。
适用场景:针对卡证、票据等场景的信息提取、关系抽取、文档视觉问答任务。
参考资料:
论文:https://arxiv.org/pdf/1912.13318.pdf
https://huggingface.co/transformers/model_doc/layoutlm.html


更多模型选择请参考:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/transformers.md
Bert模型训练
可以直接使用本项目中转换后的文本数据训练,也可先执行下面命令生成自己的数据,训练( 注意:生成数据时间较长,请耐心等待 )
In [ ]
# !python gen_dataset.pyimport paddle
import paddlenlp as ppnlp
from functools import partial
from paddlenlp.data import Stack, Dict, Pad
from utils import prepare_train_features, prepare_validation_features, evaluate
############参数配置###############
# 模型名称
MODEL_NAME = "bert-wwm-chinese"
# 根据官方文档可使用更多的模型,例如:BERT,ERNIE, RoBERTa等,之后可考虑集成的方法
# MODEL_NAME = "roberta-wwm-ext"
# 最大文本长度
max_seq_length = 512
# 文本滑动窗口步幅
doc_stride = 128
# 训练过程中的最大学习率
learning_rate = 2e-5
# 训练轮次
epochs = 12
# 数据批次大小
batch_size = 32 # 根据显存大小更改
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
#############模型################
# 加载模型
# 请根据模型名称查看官方文档文档更换接口
model = ppnlp.transformers.BertForQuestionAnswering.from_pretrained(MODEL_NAME)
# model = ppnlp.transformers.RobertaForQuestionAnswering.from_pretrained(MODEL_NAME)
# 加载 tokenizer
# 请根据文档更换接口
tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained(MODEL_NAME)
# tokenizer = ppnlp.transformers.RobertaTokenizer.from_pretrained(MODEL_NAME)
#############数据###############
# 加载数据集
# 如果是自己生成的数据请更换为自己数据的路径
train_ds = ppnlp.datasets.load_dataset('dureader_robust', data_files='data/data83268/train.json')
dev_ds = ppnlp.datasets.load_dataset('dureader_robust', data_files='data/data83268/dev.json')
# 数据滑窗处理
train_trans_func = partial(prepare_train_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
train_ds.map(train_trans_func, batched=True)
dev_trans_func = partial(prepare_validation_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
dev_ds.map(dev_trans_func, batched=True)
# 数据读取器配置
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=batch_size, shuffle=True)
train_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
"start_positions": Stack(dtype="int64"),
"end_positions": Stack(dtype="int64")
}): fn(samples)
train_data_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=train_batchify_fn,
return_list=True)
dev_batch_sampler = paddle.io.BatchSampler(
dev_ds, batch_size=batch_size, shuffle=False)
dev_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id)
}): fn(samples)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_sampler=dev_batch_sampler,
collate_fn=dev_batchify_fn,
return_list=True)
#############优化器配置#############
# 学习率策略
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = ppnlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# 设置优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
#############损失函数################
class CrossEntropyLossForSQuAD(paddle.nn.Layer):
def __init__(self):
super(CrossEntropyLossForSQuAD, self).__init__()
def forward(self, y, label):
start_logits, end_logits = y # both shape are [batch_size, seq_len]
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-1)
end_position = paddle.unsqueeze(end_position, axis=-1)
start_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=start_logits, label=start_position, soft_label=False)
start_loss = paddle.mean(start_loss)
end_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=end_logits, label=end_position, soft_label=False)
end_loss = paddle.mean(end_loss)
loss = (start_loss + end_loss) / 2
return loss
#############模型训练################
# 实例化 loss
criterion = CrossEntropyLossForSQuAD()
global_step = 0
# 训练
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
global_step += 1
input_ids, segment_ids, start_positions, end_positions = batch
logits = model(input_ids=input_ids, token_type_ids=segment_ids)
loss = criterion(logits, (start_positions, end_positions))
if global_step % 100 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f" % (global_step, epoch, step, loss))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model=model, data_loader=dev_data_loader)
# 保存
model.save_pretrained('/home/aistudio/checkpoint')
tokenizer.save_pretrained('/home/aistudio/checkpoint')
In [91]
#运行上训练述代码,可以用四卡跑,若内存溢出可以调低batchsize,训练时间较长可以提前终止。
!python train.pyOCR获得测试集文本数据
In [1]
#注意:如果使用aistudio平台这里需要自行去官网下载数据并上传
#!python gen_test.pyBert模型预测结果
import paddle
import paddlenlp as ppnlp
from functools import partial
from paddlenlp.data import Dict, Pad
from utils import prepare_validation_features, predict
############参数配置###############
# 模型名称
MODEL_NAME = "bert-wwm-chinese"
# 根据官方文档可使用更多的模型,例如:BERT,ERNIE, RoBERTa等,之后可考虑集成的方法
# MODEL_NAME = "roberta-wwm-ext"
# 最大文本长度
max_seq_length = 512
# 文本滑动窗口步幅
doc_stride = 128
# 训练过程中的最大学习率
learning_rate = 3e-5
# 训练轮次
epochs = 4
# 数据批次大小
batch_size = 32
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
#############模型################
# 加载模型
model = ppnlp.transformers.BertForQuestionAnswering.from_pretrained("训练得到的checkpoint文件夹")
# model = ppnlp.transformers.RobertaForQuestionAnswering.from_pretrained(MODEL_NAME)
# 更新参数
# state_dict = paddle.load('checkpoints/model_state.pdparams')
# model.state_dict(state_dict)
# 加载 tokenizer
# 请根据文档更换接口
tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained("训练得到的checkpoint文件夹")
# tokenizer = ppnlp.transformers.RobertaTokenizer.from_pretrained(MODEL_NAME)
#############数据###############
# 加载数据集
dev_ds = ppnlp.datasets.load_dataset('dureader_robust', data_files='ocr_result/test.json')
dev_trans_func = partial(prepare_validation_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
dev_ds.map(dev_trans_func, batched=True)
# 数据读取器配置
dev_batch_sampler = paddle.io.BatchSampler(
dev_ds, batch_size=batch_size, shuffle=False)
dev_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id)
}): fn(samples)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_sampler=dev_batch_sampler,
collate_fn=dev_batchify_fn,
return_list=True)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# 预测
predict(model=model, data_loader=dev_data_loader)
#运行上述推理预测代码
#
!python infer.py4.项目总结
针对保险文本视觉认知问答项目,本文使用paddle框架将OCR与NLP技术相结合,根据不同文档图片数据集进行OCR识别,对问题和回答进行建模 。本次学习收获主要是对语言处理有进一步了解,熟悉规则匹配和nlp的Bert语言模型,后面会在ENRIE、GPT-2等模型做对比实验,结合模型参数和训练策略,选择准确率最高的模型作为最终项目应用。
本项目链接:保险文本视觉认知问答 - 飞桨AI Studio
参考链接:保险文本视觉认知问答竞赛(Baseline) - 飞桨AI Studio