ConnerNet-Lite:基于关键点的高效率目标检测 论文解读
摘要:基于关键点的方法是一种相对较新的对象检测范式,它消除了对anchor boxes的需求,并提供了一个简化的检测框架。基于关键点的ConnerNet在总多one-stage目标检测算法中取得了最好的成绩,但是取得这个精度需要高额的运算开销,本文解决了这个基于关键点目标检测的问题并介绍了ConnerNet-Lite。ConnerNet-Lite是结合了两种高效的ConnerNet的变体:ConnerNet-Saccade:该方法使用注意机制来消除对图像所有像素进行彻底处理的需要;CornerNet-Squeeze是一种新型的紧凑的backbone结构。这两个变体一起解决了高效对象检测中的两个关键用例:在不牺牲精度的情况下提高效率,以及保证实时效率下提高精度。ConnerNet-Saccade是非常适用于离线处理,在COCO数据集上ConnerNet的检测效率提高6.0x,准确度提高了1.0%。CornerNet-Squeeze是非常适用于实时检测,同时提高了精度和效率并超过了流行的Yolov3(34.4% AP at 34ms for CornerNet-Squeeze compared to 33.0% AP at 39ms for YOLOv3 on COCO)。这些贡献首次揭示了基于关键点的检测对于需要处理效率的应用的潜在价值。
1. 介绍:
基于关键点的目标检测是一种通过检测和组合关键点生成边界框的方法。CornerNet主要是通过检测和组合边界框的左上角和右下角的脚点,他是通过堆叠hourglass网络来预测corners的heatmap并关联embbeddings去给他们分组。CornerNet 简化了目标检测网络的设计,没有使用anchor-boxes,并且在COCO数据集上取得了one-stage检测算法中最好的结果。
然而CornerNet最大的缺点就是其速度,在coco数据集平均精度能达到42.2%,但是推理一张图时间约为1.147s,这对于视频应用来说速度太慢了。尽管可以通过减少处理像素数量,处理的尺度或者图像分辨率,但是这会大大降低精度。例如,单尺寸处理结合降低输入分辨率可以加速推理达到42ms一张图,但是速度和处理精度都会比Yolov3低。
本篇文章旨在提高ConnerNet的推理效率。任何目标检测算法都可以通过减少处理像素数量和减少每个像素的处理流程去提高检测效率。我们探索这两个方向并介绍两种高效的ConnerNet变体:ConnerNet-Saccade和CornerNet-Squeeze,我们统称为CornerNet-Lite.
ConnerNet-Saccade是通过减少处理像素数量来提高推理速度。这是通过一种类似于人类视觉的注意力机制。它缩小原图并生成一个attention map,然后放大再有模型进一步处理。这与最初的ConnerNet的不同之处在于,它是在多个尺度上完全卷积地应用的。通过在高分辨率下选择剪切子集去做测试,ConnerNet-Saccade提高速度,同时提高准确性。实验表明在COCO数据集上ConnerNet-Saccade能达到43.2%的准确度和190ms每张图的处理速度。完胜原始的ConnerNet.
CornerNet-Squeeze通过减少像素的处理流程来提高速度。它结合了SqueezeNet和MobileNets两种模型,介绍了一种新的紧凑的hourglass backbone,这个hourglass backbone使用了很多1x1的卷积,bottleneck layer和深度可分离卷积。在COCO数据集上能达到34.4%的准确率和30ms的处理速度,在速度和准确率上都超过了Yolov3。
2. 相关工作
ConnerNet-Saccade目标检测。人类视觉中的Saccade是指一系列快速的眼球运动来确定不同的图像区域。在对象检测算法的上下文中,我们广泛地使用这个术语来表示在推理过程中有选择地裁剪和处理图像区域(顺序地或并行地,像素或特征)。
Saccade在ConnerNet-Saccade是用单一的裁剪处理类型且每个裁剪能产生多个目标,而不需要额外的裁剪。这意味着ConnerNet-Saccade的裁剪处理数量远远目标数量,而对于R-CNN变体和自动对焦,裁剪的数量大于目标数量。这样就提高处理速度。
3. ConnerNet-Saccade
ConnerNet-Saccade检测图像类可能存在目标的小区域。他利用降采样的图去预测attentions map 和粗糙的边界框,两个都能暗示目标可能存在的位置。然后connerNet-Saccade 通过检验以高分辨率位置为中心区域来检测目标。它还可以通过控制每幅图像中要处理的目标位置的最大数量来换取精度和效率。大致的pipline可以看图二。在本节,我会详细介绍每一步的细节。

3.1评估对象位置
CornerNet-Saccade第一步是获取图像中目标的可能位置。我们用降采样的全图预测包含了目标位置和粗糙尺寸的attention map。给定一张图片,我们调整图像尺寸,长边到255和192像素。大小192的图像填充0到255,以便并行处理。我们是用这么低分辨率的图像有两个原因,1.这一步的的推理时间不能成为瓶颈;2.网络能够利用图像的上下文信息预测attention map。
对于降采样图片,CornerNet-Saccade用来预测3个attention map,一个用于小目标,一个用于中等目标,一个用于大目标。如果一个对象的边框长小于32像素,则认为该对象是小的;如果边框长在32到96像素之间,则认为该对象是中等的;如果边框长大于96像素,则认为该对象是大的。分别预测不同对象大小的位置可以让我们更好地控制每个位置的CornerNet-Saccade应该放大多少。我们可以在小对象位置放大更多,而在中等对象位置缩小。
我们使用不同尺度的特征图来预测注意图,特征图由CornerNet-Saccade中的骨干网得到,该骨干网是一种hourglass network。网络中的每个hourglass模块都应用几个卷积和下采样层来缩小输入特征图的大小。然后通过多个卷积和上采样层对特征映射回原始输入分辨率进行上采样。小尺度的特征映射用于较小的对象,粗尺度的特征映射用于较大的对象。我们用后面接了一个1x1的Conv-Sigmoid模块的3x3的Conv-ReLU模块来预测每个特征图的attention map。在测试过程中,我们只处理分数高于阈值t的位置,并在实验中设置t = 0.3。当CornerNet-Saccade处理缩小后的图像时,它可能会检测到图像中的一些对象,并为它们生成边界框。从缩小后的图像中得到的边界框可能不准确。因此,我们还研究了高分辨率区域,以获得更好的边界框。
在训练中,我们设置相应attention map的边界框中心位置是正样本,其他设为负样本。然后我们设置focal loss 参数α=2. 预测注意图的卷积层的偏差是根据这边文章(T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar. Focalloss for dense object detection. In Proceedings of the IEEE
international conference on computer vision, pages 2980–2988, 2017.)
3.2 Detecting Object
CornerNet-Saccade使用从缩小后的图像中获得的位置来确定处理的位置。如果我们直接从缩小的图像中裁剪区域,一些对象可能会变得太小而无法准确地检测。因此,我们应该根据第一步获得的比例尺信息,以更高的分辨率来研究区域。对于从注意图中获得的位置,我们可以根据不同的对象大小确定不同的缩放比例。Ss是小目标,Sm是中等目标,Sl是大目标。一般来说,Ss > Sm > Sl,因为我们应该对较小的对象放大,所以我们设置Ss = 4, Sm = 2, Sl = 1。在每个可能的位置(x,y);,我们将缩小后的图像放大si,其中i属于(s,m,l)并取决于物体的粗略尺寸。然后我们将CornerNet-Saccade应用到以该位置为中心的255 x255窗口。
从边界预测中获得的位置提供了关于对象大小的更多信息。我们可以使用边界框的大小来确定缩放比例。缩放比例是这样确定的,对于一个小对象,缩放后的边界框的较长边为24,中等物体是64,大物体是192。
有一些重要的实现细节可以提高处理效率。首先,我们批量处理区域,以更好地利用GPU。其次,我们将原始图像保存在GPU内存中,并对GPU执行大小调整和裁剪,以减少CPU和GPU之间传输图像数据的开销。在检测到可能的目标位置后,我们通过应用soft- nms来合并边界框和删除冗余的边界框。我们裁剪的时候,可能会遇到有目标的某一部分位于裁剪边界处,例如图3.检测器可能为这些目标生成边界框并且这些边界框并不会被Soft-Nms移除,原因是他们和完整对象的边界框具有较小的重叠区域。因此我们删除了接触边裁剪边界的边界框。在训练过程中,采用了和ConnerNet训练网络预测conner heatmap,embedding和offsets相同的损失函数。

3.3. Trading Accuracy with Efficiency
我们可以通过控制每幅图像中要处理的目标位置的最大数量来用效率换取准确性。为了达到良好的准确性和效率的平衡,我们优先考虑更可能包含对象的位置。因此,在获得对象位置之后,我们根据它们的得分对它们进行排序且优先考虑从边界框中获得的对象。
3.4. Suppressing Redundant Object Locations
当物体相互靠近时,我们可能会产生高度重叠的区域,如图4所示。处理这两个区域是不可取的,因为处理其中任何一个区域都可能检测到另一个区域中的对象。
我们采用类似于NMS的过程来删除冗余位置。首先,我们对对象位置进行排序,将来自包围框的位置优先于来自注意力地图的位置。然后,我们保留最佳对象位置,并删除靠近最佳位置的位置。我们重复这个过程,直到没有对象位置剩下为止。

3.5. Backbone Network
我们设计了一个hourglass骨干网网络,并在CornerNet-Saccade取得了很好的效果。新的hourglass网络由3个hourglass模块组成,深度为54层,而CornerNet中的hourglass-104由2个hourglass 模块组成,深度为104层。我们把这种新的骨干称为hourglass-54。hourglass-54中的每个hourglass模块具有更少的参数,并且比hourglass-104中的模块更浅。按照hourglass -104中的缩减策略,我们通过stride 2缩小了特征图的大小。我们在每个下采样层和每个跳过连接之后都应用残差模块。每个hourglass 模块将输入特性缩小3倍,并在此过程中增加通道的数量(384、384、512)。在模型中间有一个512通道的残差块,并且在每个上采样层后也会有一个残差块。在hourglass 模块之前,我们还将图像缩小了两次。按照hourglass 网络训练的一般实践,我们还在训练过程中添加了中间监督。在测试期间,我们只使用网络中最后一个hourglass 模块的预测。
3.6. Training Details
:我们使用Adam来优化注意力地图和目标检测的损失,并使用与在CornerNet中发现的相同的训练超参数。网络的输入大小为255x255,这也是推理期间的输入分辨率。:我们在四个1080Ti gpu上训练批处理大小为48的网络。为了避免过拟合,我们采用了CornerNet的数据增强技术网。当我们随机裁剪一个物体周围的一个区域时,这个物体要么是随机放置的,要么是在中心有一些随机偏移量。这确保了训练和测试是一致的,因为网络检测对象集中在裁剪的目标位置中心。
4. CornerNet-Squeeze
4.1. Overview
与CornerNet-Saccadee专注于像素的子集以减少处理量的不同,CornerNet-Squeeze探索了一种减少每个像素处理量的替代方法。在CornerNet大部分计算资源都花在了Hourglass- 104。Hourglass- 104由残差块构成,每个残差快由两个3x3个卷积层和一个跳过连接组成。虽然Hourglass-104实现了具有竞争力的性能,但它在参数数量和推理时间方面都很费时。为了减小Hourglass- 104的复杂度,我们结合了SqueezeNet和MobileNets的想法来设计一个轻量级的Hourglass架构。
4.2. Ideas from SqueezeNet and MobileNets
SqueezeNet提出了三种降低网络复杂度的策略:1.用1x1的卷积核代替3x3的卷积核;2.减少输入通道;3. Downsampling late.。SqueezeNet的构造模块-fire module模块,封装了前两个概念。fire模块首先通过由1x1个卷积核组成的挤压层减少输入通道的数量。然后,它通过一个由1x1和3x3个卷积核混合组成的扩展层提供结果。
基于SqueezeNet所提供的见解,我们CornerNet-Squeeze中使用了fire模块来代替残差块。此外,受MobileNets成功的启发,我们将第二层的3x3个标准卷积替换为3x3个深度可分离卷积,进一步提高了推理时间。表1给出了CornerNet中残差块与CornerNet-Squeeze中新的fire模块的详细比较。我们没有探索SqueezeNet中第三种思想。:由于hourglass网络具有对称结构,delayed downsampling使得上采样时的特征图分辨率更高。在高分辨率特征图上进行卷积运算计算量大,不利于实现实时检测。

除了替换剩余的块,我们还做了一些修改. 我们通过在hourglass模块之前再添加一个下采样层来降低hourglass模块的最大feature map分辨率,并在每个hourglass模块中删除一个下采样层.在hourglass模块之前,CornerNet-Squeeze相应地将图像缩小三次,而CornerNet将图像缩小两次。在CornerNet的预测模块中,我们用1x1个过滤器替换了3x3个过滤器。最后,我们用转置卷积替换hourglass网络中最近邻上采样。
4.3. Training Details
我们使用和CornerNet相同的训练损失和超参数训练CornerNet-Squeeze,只修改了batch size。在使用hourglass模块之前再一次缩小图像的大小,在相同的图像分辨率下,在corner - squeeze中可以减少4倍的内存使用。我们可以训练网络的批处理大小为55对4
1080Ti GPU(主GPU上有13张图像,其余GPU上每个GPU有14张图像)。
5. Experiments
5.1. Implementation Details
CornerNet-Lite在PyTorch[40]中实现。我们使用利用COCOCornerNet-Lite进行了评价,并与其他探测器进行了比较。在COCO中,有80个对象类别,训练115k张,验证5k张,测试20k张。为了测量推理时间,对于每个检测器,我们在计时器读取完图像时启动它,在计时器获得最终的边界框时停止它。硬件配置可能会影响推理时间。为了在不同检测器之间提供公平的比较,我们用1080Ti GPU和英特尔酷睿i7-7700k CPU。
5.2. Accuracy and Efficiency Tradeoffs
我们比较了精度和效率的权衡拥有三个最先进的物体探测器,包括YOLOv3,RetinaNet和Corner-Net,在验证集上。精度和效率的权衡曲线如图6所示。
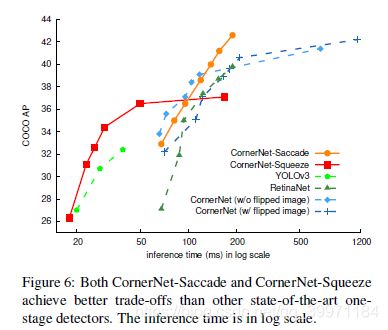
5.3. CornerNet Saccade Results
CornerNet Saccade不仅提高了测试的效率,而且提高了训练的效率. 我们只能在4个1080Ti GPU上训练angular - saccade,总共有44GB的GPU内存,而CornerNet需要10个Titan X (PASCAL) GPU,总共有120GB的GPU内存。我们减少了超过60%的内存使用。CornerNet和CornerNet-Saccade都不使用mixed precision training。
Attention map对CornerNet-Saccade。如果Attention map不准确,CornerNet-Saccade会漏掉图像中的目标。为了更好的理解attention map的特性,我们将预测的attention map替换为地面真实图。这提高了CornerNet-Saccade的AP 在验证集上有42.6%到50.3%,说明attention map有足够的改进空间。
5.4. CornerNet Squeeze Results
表5看出CornerNet Squeeze比用c写的Yolov3具有更高的精度和更快的速度,简直就是碾压。

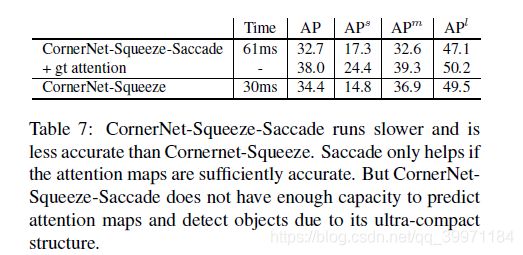
5.5. CornerNet Squeeze Saccade Results
为了进一步提高效率,我们尝试将CornerNet Squeeze和saccades结合起来。但是结果并没有比CornerNet Squeeze更好。在验证集上,CornerNet Squeeze达到34.4%的AP,而CornerNet-Squeeze-Saccade在kmax = 30到32.7%。如果我们将预测的attention map替换为ground-truth attention map,我们将CornerNet-Squeeze-Saccade的AP提高到38.0%,性能比CornerNet-Squeeze更好。
结果表明,只有当attention map足够准确时,saccade才有帮助。由于其超紧结构,CornerNet-Squeeze-Saccade没有足够的能力同时检测目标和预测注意图。此外, CornerNet-
Squeeze只在单一尺度的图像上操作,这就大大减少了CornerNet-Squeeze-Saccade保存的空间。CornerNet-Squeeze-Saccade比CornerNet-Squeeze,可以处理更多的像素,从而降低了推理时间。
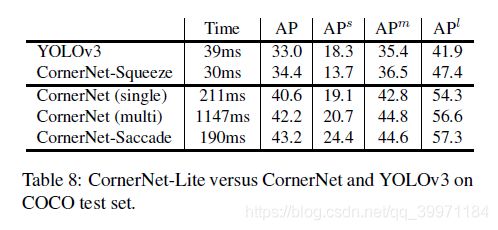
5.6. COCO Test AP
我们还比较了CornerNet-Lite和CornerNet以及YOLOv3对COCO的测试集在表8中。CornerNet-Squeeze比YOLOv3更快更准确。CornerNet Saccade在多尺度下比CornerNet更准确,速度是CornerNet的6倍。
6.本文探索出了两种cornet变体,ConnerNet-Saccade:该方法使用注意机制来消除对图像所有像素进行彻底处理的需要;CornerNet-Squeeze是一种新型的紧凑的backbone结构。ConnerNet-Saccade是非常适用于离线处理,在COCO数据集上ConnerNet的检测效率提高6.0x,准确度提高了1.0%。CornerNet-Squeeze是非常适用于实时检测,同时提高了精度和效率并超过了流行的Yolov3(34.4% AP at 34ms for CornerNet-Squeeze compared to 33.0% AP at 39ms for YOLOv3 on COCO)