深度稳定学习:因果学习的最新进展 | 清华大学团队 CVPR 研究
2021-05-02 13:44:18
作者 | 陈大鑫、张兴璇
这都2021年了,对 AI 而言,识别出猫猫狗狗肯定再简单不过了。
可是,可是,AI 真的有那么「丝滑」吗?

并没有——如上图所示,当训练分类器时,给定的数据集中狗大多在草地上、而猫大多在雪地上,这时为了最小化训练的风险损失,AI 就可能把草地当作判断狗的要素。所以当测试时看到草地上的猫,AI 就会“指猫为狗”。
那么为什么上述机器学习模型容易在数据分布变化时出现决策失误呢?
因为它可能学到了不具备泛化性能的关联性,相对I.I.D.假设下的模型学习,这种训练环境和测试环境的数据分布不同的问题称为Non-I.I.D.或者OOD(Out-of-Distribution)。
图灵奖得主 Yoshua Bengio 也一度认为OOD泛化是人工智能当然最为迫切需要解决的问题之一。
那么针对OOD泛化问题,近些年来都有哪些研究呢?
1 OOD泛化研究
领域泛化(DG)是其一,其实在视觉学习的领域,早在2011年MIT的研究者Antonio Torralba就在《Unbiased Look at Dataset Bias》一文中对于视觉任务中不同的标杆数据集之间存在偏差的现象作了初步的探索。该文提出已有视觉数据集的不断推出无非给视觉模型和算法一个单纯的”跑分“而已,对于深入理解视觉研究问题,“量变”似乎还无法引发“质变”。
为此,该论文提出了一种“跨数据集泛化性”(Cross-dataset generalization)指标,即用来自不同数据集的图像分别构成训练集和测试集,通过模型性能的下降幅度来评估数据集之间的偏差,这种评估策略也逐渐成为日后领域自适应学习 (Domain Adaptation)中用于评价模型泛化性能的核心指标。
而领域泛化问题的设定更为严苛,在训练过程中所有的测试数据及其标注均对当前模型不可见,所以要求模型有向任意未知领域泛化的能力。领域泛化的基本思想是将训练数据显式地划分为多个领域,使得不相关的特征在不同的域中变化,而相关的特征保持不变。这样划分出来的训练数据可以使得一个设计良好的模型能够学习跨领域的不变性表示,并抑制不相关特征的负面影响,从而在任何未知分布转移下具有更好的泛化能力。
沿袭这种思路,一些有效的方法需要明确而显著的异构性,即要求领域是人工划分和标记的。但是在实际应用中这些方法并不总是令人满意,因为大部分数据集都可以认为由来自不同的潜在未知领域的数据构成,而这些未知领域需要大量的额外人工标注,甚至可能在人类认知下的异质性不足以将数据划分到若干领域。
最近,也有研究人员提出一些方法来从数据中隐式地学习潜在领域,但是他们隐式地假设潜在域是平衡的,这意味着训练数据是由潜在领域的平衡采样形成的。然而,在实际应用中,由于潜在领域对模型是未知的,所以来自各个领域的采样数据量平衡的假设很脆弱,会导致这些方法的退化,效果将大打折扣。
总之目前已有的研究这个问题的思路都不是很合理。
当下的人工智能技术往往不能很好地泛化到未知的环境,这是因为这些模型通常只做到了知其「然」(即关联性)而不知其「所以然」(即因果性)。
而稳定学习的目标正是在于寻找目前的机器学习方法与因果推理之间的共同基础,从而推进这两个方向的融合。
2 稳定学习
而为了解决这些难题,自2016 年起,崔鹏老师的团队开始深入研究如何将因果推理与机器学习相结合,并最终形成了「稳定学习」(stable learning)的研究方向。从宏观的角度来看,稳定学习旨在寻找因果推理与机器学习之间的共同基础,从而应对一系列有待解决的问题。相比而言,稳定学习目标的设置更加合理且符合实际,解决了这个问题才算是解决了OOD泛化的问题。
而基于这一目标,崔鹏老师团队在先前提出了一系列关于稳定学习的研究[1-5]。
考虑到相关特征和不相关特征之间的统计相关性是分布转移下模型崩溃的主要原因,他们提出通过对相关特征和不相关特征进行去相关来实现分布外泛化。由于没有额外的监督来将相关特性与无关特性分离,所以保守的解决方案是消除所有特性的相关性。
近年来,这一概念已被证明有效地提高了线性模型的泛化能力。[6]提出了一种以输入变量去相关为目标的样本加权(sample weighting)方法,并从理论上证明了该样本加权方法能使线性模型在分布转移下产生稳定预测的原因。
但这些已有方法都是在线性框架的约束下发展起来的,处理更加复杂的数据类型及任务(如图像识别、检测等)时就要求我们在深度网络框架中实现稳定学习,也就是深度稳定学习(deep stable learning)。
而将这些思想扩展到深度模型会面临两个主要挑战:
1、特征之间复杂的非线性依赖关系比线性依赖关系更难度量和消除;
2、这些方法中的全局样本加权策略对深度模型的存储量和计算量要求都比较大,这在实际中是不可行的。
事实上,从OOD泛化问题即可看出当下人工智能存在的风险,即不可解释性和不稳定性,而关联统计是导致这些风险的重要原因。
而如果我们能够结合因果推断的机器学习,保证模型在不同环境下具有可靠的模型性能,并且能够优化性能波动的方差,也即基于因果推理中的「混淆变量平衡」的思想那么就可以来实现稳定学习值得一提的是,从因果角度出发,可解释性和稳定性之间存在一定的内在关系,即通过优化模型的稳定性亦可提升其可解释性。
3 深度稳定学习
就在今年,清华大学崔鹏团队研究的稳定学习在深度学习框架下有些突破,给出了比较通用有效的深度稳定学习方法,名为 StableNet,其论文《Deep Stable Learning for Out-Of-Distribution Generalization》已被CVPR2021接收。

论文地址:
https://arxiv.org/abs/2104.07876
针对上面说到的第一个挑战,本文提出了一种新的基于随机傅立叶特征的非线性特征去相关方法[7],这种方法具有线性计算复杂度。
对于上面说到的第二个挑战,本文提出了一种高效的优化机制,通过迭代保存和重新加载模型的特征和权重来感知和去除全局相关性。且该方法对这两个模块进行了联合优化。
此外,如图1所示,StableNet可以有效地分离不相关的特征(如水),并利用真正相关的特征进行预测,从而在wild非稳定环境中获得更稳定的性能。
并且已经有了成功的应用案例,大量的实验表明,与现有的SOTA方法相比,崔鹏团队提出的方法在多个分布泛化基准上都很有效。通过对PACS、VLCS、MNIST-M和NICO等分布泛化基准数据集上的大量实验,也都证明了该方法的有效性。
深度稳定学习的基本思路
深度稳定学习的基本思路是提取不同类别的本质特征,去除无关特征与虚假关联,并仅基于本质特征(与标签存在因果关联的特征)作出预测。
如下图所示,当训练数据的环境较为复杂且与样本标签存在强关联时,ResNet等传统卷积网络无法将本质特征与环境特征区分开来,所以同时利用所有特征进行预测,而StbleNet则可将本质特征与环境特征区分开来,并仅关注本质特征而忽略环境特征,从而无论环境(域)如何变化,StableNet均能做出稳定的预测。

图注:传统深度模型与深度稳定学习模型的saliency map,其中亮度越高的点对预测结果的贡献越大,可以看到两者特征的显著不同,StableNet更关注与物体本身而传统深度模型也会关注环境特征。
目前已有的稳定学习方法多针对线性模型,通过干扰变量平衡(Confounder Balancing)的方法来使得神经网络模型能够推测因果关系。具体而言,如果要推断变量A对变量B的因果关系(存在干扰变量C),以变量A是离散的二元变量(取值为0或1)为例,根据A的值将总体样本分为两组(A=0或A=1),并给每个样本赋予不同的权重,使得在A=0和A=1时干扰变量C的分布相同(即D(C|A=0) = D(C|A=1),其中D代表变量分布),此时判断D(B|A=0) 和D(B|A=1)是否相同可以得出A是否与B有因果关系。
而在计算机视觉相关的场景中,由于经卷积网络后的各维特征为连续值且存在复杂的非线性依赖关系,无法通过直接应用上述干扰变量平衡方法来消除特征间的相关性;另外由于用于深度学习的训练数据集通常尺寸较大,深度特征的维度也较大,所以无法直接计算出全局的样本权重。
本文要解决的问题,就是如何在深度学习网络中找到一组样本权重,使得所有变量之间都可以做到互相独立,即任意选取一个变量为目标变量,目标变量的分布不随其它变量的值的改变而改变。
基于随机傅立叶特征的深度特征去相关
去除特征间相关性的基本思路是干扰变量平衡,其基本原理如下图所示:

图4. 样本变量之间独立性函数(图左);样本权重更新公式(图右)
而深度网络的各维特征间存在复杂的依赖关系,仅去除变量间的线形相关性并不足以完全消除无关特征与标签之间的虚假关联,所以一个直接的想法就是通过kernel(核方法)将映射到高维空间,但是经过kernel映射后原始特征的特征图维度被扩大到无穷维,使得各维变量间的相关性无法计算。
鉴于随机傅立叶特征(Random Fourier Feature, RFF)在近似核函数以及衡量特征独立性方面的优良性质,本文采用RFF将原始特征映射到高维空间中(可以理解为在样本维度进行扩充),消除新特征间的线形相关性即可保证原始特征严格独立,如下图所示。
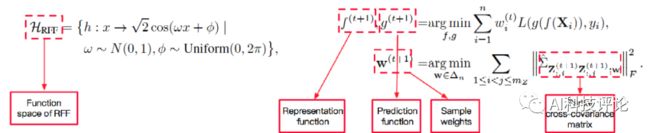
图注:用于独立性检测的随机傅立叶特征(图左);StableNet网络与样本权重更新(图右)
全局优化样本权重
上述公式要求在训练过程中为每个训练样本都学习一个特定的权重,但在实践中,尤其对于深度学习任务,要想利用全部样本全局地学习样本权重需要巨大的计算和存储开销。此外,使用SGD对网络进行优化时,每轮迭代中仅有部分样本对模型可见,因此无法获取全部样本的特征向量。
本文提出了一种存储、重加载样本特征与样本权重的方法,在每个训练迭代的结束融合并保存当前的样本特征与权重,在下一个训练迭代开始时重加载,作为训练数据的全局先验知识优化新一轮的样本权重,如下图所示。

图注:全局先验知识(图左);先验知识更新(图右)
StableNet的结构图如下图所示,输入图片经过卷积网络后提取得视觉特征,后经过两个分支。其中上方分支为样本权重学习子网络,下方分支为常规分类网络。最终训练损失为分类网络预测损失与样本权重的加权求和。其中LSWD为去相关样本权重学习模块(Learning Sample Weights for Decorrelation),利用RFF学习使特征各维独立的样本权重。
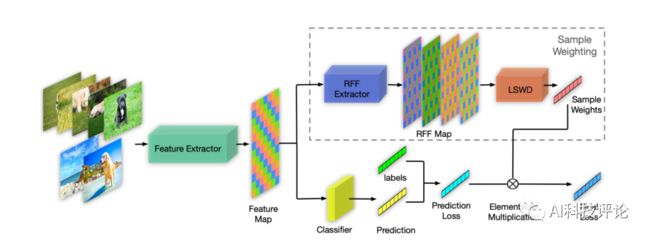
图注:StbelNet结构图
下面以识别狗的应用为例,如果训练样本中大部分的狗在草地上,少部分的狗在沙滩上,图片相应的视觉特征经样本重加权后各维独立,即狗对应的特征与草地、沙滩对应的特征在统计上不相关,所以分类器在预测狗是否存在时更容易关注与狗相关的特征(若关注草地、沙滩等特征会造成预测损失激增),所以测试时无论狗在草地上或沙滩上与否,StableNet均能依据本质特征给出较准确的预测,实现模型在OOD数据上的泛化。
下图展示了StbelNet训练流程:

含义更广泛的域泛化任务
在常规的域泛化(DG)任务中,训练集的不同源域容量相近且异质性清晰,然而在实际应用中,绝大部分数据集都是若干潜在源域的组合,当源域异质性不清晰或未被显式标注时,我们很难假定来自于各源域的数据数量大致相同。为了更加全面地验证StableNet的泛化性能,本文提出三种新的域泛化任务来仿真更加普适且挑战性更强的分布迁移泛化场景。
1)不均衡的域泛化
对于源域不明确的域泛化问题,假定源域容量相近过于理想化,一个更普适的假设为来自不同源域的数据量可能不同且可能差异巨大。在这种情况下,模型对于未知目标域的泛化能力更满足实际应用的需求。例如在识别狗的例子中,我们很难假定背景为草地、沙滩或水里的图片数量相同,实际情况下狗较多地出现在草地上而较少出现在水里。这就要求模型的预测不能被经常与狗一起出现的背景草地误导,所以本任务的普适性和难度显著高于均衡的域泛化。
使用ResNet18作为特征提取网络的实验结果如下表,StableNet在PACS和VLCS所有的目标领域及平均准确率上均取得了最优性能,且较基线方法提升较为明显。
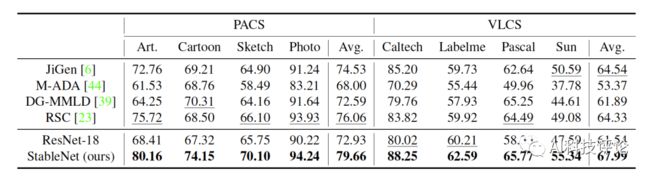
表1. 不均衡的域泛化实验结果
2)部分类别缺失的域泛化
我们考虑一种挑战性更大且在现实场景中经常存在的情况,某些源域中有部分类别的数据缺失,而在测试集中模型需要识别所有类别。例如,鸟经常出现在树上而几乎不会出现在水里,鱼经常出现鱼缸里而几乎不会出现在树上,所以并不是所有源域都一定包含全部类别。这种场景要求更高的模型泛化能力,由于每个源域中仅有部分类别,所以域相关的特征与标签间的虚假关联更强且更易误导分类器。
下表为实验结果,由于对域异质性及类别完整性的要求,很多现有域泛化方法无法显著优于ResNet,而StableNet在PCAS,VLCS及NICO上均取得了最优结果。
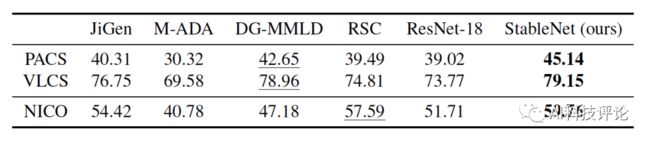
表2. 部分类别缺失的域泛化实验结果
3)存在对抗的域泛化
一种难度更大的场景是任一给定类别的主导源域与主导目标域不同。例如,训练数据中的狗大多在草地上而猫大多在室内,而测试数据中的狗大多在室内而猫大多在草地上,这就导致如果模型不能区分本质特征与域相关特征,就会被域信息所误导而做出错误预测。
下表为在MNIST-M数据集上的实验结果,StableNet仍显著优于其他方法,且可见随主导域比例升高,ResNet的表现显著下降,StableNet的优势也越发明显。
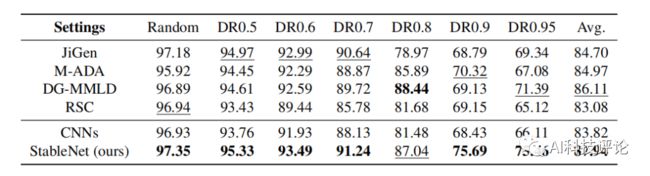
表3. 存在对抗的域泛化实验结果
StableNet小结
上文对这种基于样本重加权的深度网络框架StableNet做了详细介绍,它能将稳定学习拓展到深度学习领域,并在一系列更广泛的域泛化实验中取得了当前最优效果。
StableNet利用RFF及干扰变量平衡帮助网络动态地学习与类别相关联的本质特征,消除环境特征与样本标签间的虚假关联,已实现在不同未知目标环境中的稳定预测。
另外最重要的一点是StableNet并不依赖于特定backbone网络,是一个非常通用的方法。
而有了好的网络方法之后,接下来我们就要接着思考另外一个问题,那就是能不能更高效地来直接检验模型方法的Non-I.I.D.泛化性能,崔鹏团队发现Non-I.I.D.远比想象的更加常见,甚至可以在最有公信力的I.I.D.图像数据集ImageNet上找到Non-I.I.D.的影子。
并通过实现发现:
1、Non-I.I.D.普遍存在于各训练集的各种类别中;
2、不同训练集的组成会带来数据分布差异的不同。然而,ImageNet等数据集并非为Non-I.I.D.问题而设计,它们能造成的数据偏差都不明显,偏差程度也很难调控,不足以支持充分的研究。
3、数据分布的差异大小将直接影响模型学习的好坏。
这时就需要一个区别于I.I.D.下传统图像任务的定义,把“跨数据集泛化性”作为主要的评价标准的Non-I.I.D.数据集。
以基本的图像分类任务为例,Non-I.I.D.下的图像分类分为Targeted类和General类。两类任务的区别在于是否已知测试环境的信息,目标都是从训练环境中学习可以泛化到有数据分布偏差的测试环境的模型。
显然,随着不同类型、任务、规模的数据集不断提出,单单通过排列组合来考察“跨数据集泛化性”带来的边际效应越来越低,从实际研究的⻆度出发,整个研究社区亟需⼀个可以系统、定量地研究数据分布偏差与模型泛化性能的标杆数据集。
4 NICO数据集简介
就在去年,在《面向分独立同分布图像分类:数据集和基线模型》(Towards Non-IID Image Classification: A Dataset and Baseline) 一文中,崔鹏团队提出了一个带有“调节杆”的多分类图像数据集 (NICO),用于模拟训练和测试集分布不同条件下的图像分类任务场景,辅以定量刻画数据分布偏差的指标”Non-I.I.D. Index“ (NI)。

通过“调节杆”,我们可以手动调节不同档位的NI,从而模拟一连串不同难度的场景,从接近经典数据集下的“无偏”环境平滑过渡到加入对抗信息的“极偏”环境中。

图注:NICO数据集示例
区别于其它标准数据集,构建NICO数据集的核心思想是以(主体对象,上下文)的组合为单位收集数据。同一个类别(主体对象),有多个上下文与之对应,描述主体内的属性,如颜色、形状等,或主体外的背景,如草地、日落等。
为了实用性和适用性,我们从搜索引擎上与主体最密切的联想词中筛选出丰富多样的上下文,并保证不同主体的上下文有足够的重叠度。上下文实际上提供了围绕主体的有偏数据分布,通过在训练环境和测试环境组合不同的(主体对象,上下文),我们就能构建不同的Non-I.I.D.场景
可以构建的场景包括但不限于:
1、最小偏差:NICO可达到的近似“I.I.D.”,通过随机采样使训练和测试环境的所有(主体对象,上下文)单元的数据比例相同。
2、比例偏差:虽然训练和测试环境中出现(主体对象,上下文)的组合相同,但是不同单元之间的比例不同。
3、成份偏差:测试环境中存在训练环境中没出现过的(主体对象,上下文)单元,算作比例偏差的一个特例。
4、对抗偏差:通过精心组合训练集和测试集的主体对象/上下文,我们可以专门干扰模型对某个指定类别(正类)的预测。
虽然NI的区间变化很大,利用NICO就能很容易地创建这些经典的Non-I.I.D.场景,然后进行多样的科学研究。假设测试环境的信息已知,你可以做迁移学习、域适应性学习等研究;如果测试环境的信息不知,也可以进行稳定机器学习等方面的研究。

目前为止,NICO以树状结构组织了2个超类(交通工具类和动物类)、19个类(鸟、…、火车)、以及每个类别下的9或10种上下文,共累积了188种(主体对象,上下文)组合,收集了约25000张图像,其规模也正不断扩大。对于热火朝天的人工智能而言,Non-I.I.D.下机器学习的稳定性已成为新的战场。靶(数)子(据)?NICO提供了一个很好的选择。
更多关于NICO的细节请参见NICO的官方网站:
http://nico.thumedialab.com
或者相关的论文《Towards Non-IID Image Classification: A Dataset and Baseline》。
参考资料
1、Yue He, Zheyan Shen, and Peng Cui. Towards non-iid image classification: A dataset and baselines. Pattern Recognition, page 107383, 2020.
2、K. Kuang, R. Xiong, P. Cui, S. Athey, and B. Li. Stable prediction across unknown environments. Research Papers, 2018. 2
3、Kun Kuang, Ruoxuan Xiong, Peng Cui, Susan Athey, and Bo Li. Stable prediction with model misspecification and agnostic distribution shift. In AAAI, pages 4485–4492, 2020.
4、Z. Shen, P. Cui, K. Kuang, B. Li, and P. Chen. On image classifi
cation: Correlation v.s. causality. 2017.
5、Zheyan Shen, Peng Cui, Tong Zhang, and Kun Kuang. Stable learning via sample reweighting. In AAAI, pages 5692–5699, 2020.
6、Aditya Khosla, Tinghui Zhou, Tomasz Malisiewicz, Alexei A Efros, and Antonio Torralba. Undoing the damage of dataset bias. In European Conference on Computer Vision, pages 158–171. Springer, 2012.
7、Gary Marcus. Deep learning: A critical appraisal. arXiv preprint arXiv:1801.00631, 2018.