ATSS 论文阅读笔记以及核心代码解析
文章目录
- 1 论文题目
- 2 论文目的
- 3 论文实现
- 4 核心代码解读
1 论文题目
Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
本篇论文也是入选了2020年的CVPR,算是今年CVPR里目标检测方向为数不多的论文之一。
2 论文目的
首先,本文作者指出在目标检测的方法中,anchor-based的方法与anchor-free的方法之间主要的区别在于如何定义正负样本。如果两类方法采取相同的定义方式,那么这两类方法将会取得差不多的效果。
针对上述发现,作者提出了Adaptive Training Sample Selection (ATSS)的方法去自动的选取正负样本,这种方法弥补了anchor-based的方法与anchor-free方法之间的差距。
3 论文实现
作者分别选取了两类方法中具有代表性的方法:RetinaNet和FCOS,并以此详细的说明了ATSS方法。
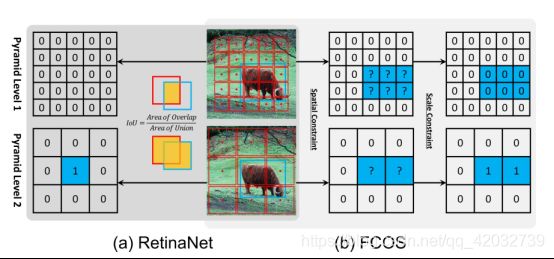
首先,在RetinaNet中,是采用IOU的方式区分正负样本,因此是在空间维度和尺度维度同时进行选择。而在FCOS中,首先是在空间维度上选定一些候选的正样本,并在此基础上在尺度维度上选择正样本,剩余的作为负样本。

上述实验结果说明:(按列分析)对于RetinaNet来说,定义正负样本的方式从IOU改为Spatial and Scale Constraint的话,map从37.0%提升到37.8%。而对于FCOS来说,定义正负样本的方式从Spatial and Scale Constraint改变为IOU,map从37.8%降低到36.9%。
所以,如何定义正负样本,是很重要的。
从另一个角度来分析上述表格(按行分析),即回归的方式,对于RetinaNet来说,从anchor box得到最后的bbox,改为从anchor point得到最后的bbox,对于map几乎没有影响。对于FCOS也一样。
所以回归的方式不是一个重要的因素。
下面将具体说明ATSS具体的步骤:
先给出伪算法框图:

输入: g: 输入图片所有ground truth
L: 金字塔网络的层数
: 第i层金字塔网络的先验框集合
A: 所有先验框
K: 对于每个ground truth 的中心,我们每层选取k个与之最近的先验框。
输出: P:正样本集合
N: 负样本集合
具体流程:
(1)确定一些正例的候选样本(根据L2距离,每层选取k个先验框),所以如果有l层的话,则共有k*l个先验框
(2)计算先验框与ground truth之间的IOU
(3)利用上面计算的IOU,分别计算均值和标准差
(4)利用 + ,来定义正负样本,即IOU得分大于等于,则被定义成正样本,否则就是负样本。
(5)在第(4)步选择正负样本的过程中,还有个判断条件就是该样本的中心必须在目标内,才能被定义成正样本。
关于ATSS算法的一些解释:
(1)作者认为,先验框的中心离ground truth越近,先验框的质量越好
(2)关于均值和标准差(从统计学的原理说明):
均值:某个目标的IOU均值能够说明:对于这个目标,相应的先验框设置的是否合理。
标准差:能够说明金字塔结构中的哪一层更加适合检测这个目标。
(3)保证先验框的中心在ground truth之内
4 核心代码解读
作者开源的代码是直接在FOCS代码上改进的,所以在此只分析关于ATSS的相关代码,如果想看FCOS的相关代码,可以看看这篇博客,写的很好。点击这里
下面言归正传,先给出ATSS核心代码的路径,其实刚开始我也没找到,还是特意问的作者. (小白一枚)
ATSS-master/atss_core/modeling/rpn/atss/loss.py
建议下面的代码结合上面的伪算法流程图一起看,更容易理解
elif self.cfg.MODEL.ATSS.POSITIVE_TYPE == 'ATSS':
num_anchors_per_loc = len(self.cfg.MODEL.ATSS.ASPECT_RATIOS) * self.cfg.MODEL.ATSS.SCALES_PER_OCTAVE
#每个level 的 anchor 数量
num_anchors_per_level = [len(anchors_per_level.bbox) for anchors_per_level in anchors[im_i]]
ious = boxlist_iou(anchors_per_im, targets_per_im)
gt_cx = (bboxes_per_im[:, 2] + bboxes_per_im[:, 0]) / 2.0
gt_cy = (bboxes_per_im[:, 3] + bboxes_per_im[:, 1]) / 2.0
gt_points = torch.stack((gt_cx, gt_cy), dim=1)
anchors_cx_per_im = (anchors_per_im.bbox[:, 2] + anchors_per_im.bbox[:, 0]) / 2.0
anchors_cy_per_im = (anchors_per_im.bbox[:, 3] + anchors_per_im.bbox[:, 1]) / 2.0
anchor_points = torch.stack((anchors_cx_per_im, anchors_cy_per_im), dim=1)
#计算 anchor 和 GT 之间的L2距离
distances = (anchor_points[:, None, :] - gt_points[None, :, :]).pow(2).sum(-1).sqrt()
# Selecting candidates based on the center distance between anchor box and object
candidate_idxs = []
star_idx = 0
#遍历每一张img 的 的每一个level 的 anchor 集合
for level, anchors_per_level in enumerate(anchors[im_i]):
end_idx = star_idx + num_anchors_per_level[level]
distances_per_level = distances[star_idx:end_idx, :]
topk = min(self.cfg.MODEL.ATSS.TOPK * num_anchors_per_loc, num_anchors_per_level[level])
# 根据L2 距离选择 前K个 anchor
_, topk_idxs_per_level = distances_per_level.topk(topk, dim=0, largest=False)
candidate_idxs.append(topk_idxs_per_level + star_idx)
#为了记录下一个level,不然的话,下一个level的candidate_idxs 会把上一个level的candidate_idxs 覆盖掉
star_idx = end_idx
candidate_idxs = torch.cat(candidate_idxs, dim=0)
# Using the sum of mean and standard deviation as the IoU threshold to select final positive samples
#计算 anchor 和 GT 之间的 IOU
candidate_ious = ious[candidate_idxs, torch.arange(num_gt)]
#计算均值
iou_mean_per_gt = candidate_ious.mean(0)
#计算标准差
iou_std_per_gt = candidate_ious.std(0)
#新的阈值 = 均值 + 标准差
iou_thresh_per_gt = iou_mean_per_gt + iou_std_per_gt
#选出candidate中 IOU 大于新的阈值的anchors
is_pos = candidate_ious >= iou_thresh_per_gt[None, :]
# 保证最后保留的anchor的中心 在ground truth中
# Limiting the final positive samples’ center to object
anchor_num = anchors_cx_per_im.shape[0]
for ng in range(num_gt):
candidate_idxs[:, ng] += ng * anchor_num
e_anchors_cx = anchors_cx_per_im.view(1, -1).expand(num_gt, anchor_num).contiguous().view(-1)
e_anchors_cy = anchors_cy_per_im.view(1, -1).expand(num_gt, anchor_num).contiguous().view(-1)
#view(-1) 是将变量转换成1维
#这块怎么判断center 在 GT 之内,有点没看懂
candidate_idxs = candidate_idxs.view(-1)
l = e_anchors_cx[candidate_idxs].view(-1, num_gt) - bboxes_per_im[:, 0]
t = e_anchors_cy[candidate_idxs].view(-1, num_gt) - bboxes_per_im[:, 1]
r = bboxes_per_im[:, 2] - e_anchors_cx[candidate_idxs].view(-1, num_gt)
b = bboxes_per_im[:, 3] - e_anchors_cy[candidate_idxs].view(-1, num_gt)
is_in_gts = torch.stack([l, t, r, b], dim=1).min(dim=1)[0] > 0.01
#is_pos --> is_postive 最后返回 true or false 表示该图片是否是正例
is_pos = is_pos & is_in_gts
# if an anchor box is assigned to multiple gts, the one with the highest IoU will be selected.
#创建一个 元素都为-INF的tensor,并展开成一维
ious_inf = torch.full_like(ious, -INF).t().contiguous().view(-1)
index = candidate_idxs.view(-1)[is_pos.view(-1)]
# 向ious_inf tensor中对应的位置(index)赋予iou的值
ious_inf[index] = ious.t().contiguous().view(-1)[index]
#将 ious_inf 转换成num_gt行,每行都对应着每个anchor 与这个GT 的IOU值
ious_inf = ious_inf.view(num_gt, -1).t()
#找出与每个GT IOU值最大的那个anchor 的 IOU值 以及 序号(index)
anchors_to_gt_values, anchors_to_gt_indexs = ious_inf.max(dim=1)
#找到这些anchor对应的label
cls_labels_per_im = labels_per_im[anchors_to_gt_indexs]
#将不具有最大IOU值的anchor 分类得分置为0
cls_labels_per_im[anchors_to_gt_values == -INF] = 0
#通过label保留最后的bbox
matched_gts = bboxes_per_im[anchors_to_gt_indexs]
想写的就这么多了,第一次写这种代码解析的博客,有什么错误请大家积极指出,我尽量改正,如果对于相关代码有什么好的理解,可以写在评论里。当然,大家有比较好的关于目标检测的论文可以写在评论里,也方便大家一起学习。
感谢大家。