可分离卷积(Separable convolution)详解
可分离卷积
可分离卷积包括空间可分离卷积(Spatially Separable Convolutions)和深度可分离卷积(depthwise separable convolution)。
假设feature的size为[channel, height , width]
- 空间也就是指:[height, width]这两维度组成的。
- 深度也就是指:channel这一维度。
空间可分离卷积
具有如下特点
- 乘法次数减少
- 计算复杂度降低
- 网络速度更快
空间可分离卷积就是在空间维度将标准卷积运算拆分成多个小卷积核。例如我们可以将卷积核拆分成两个(或多个)向量的外积。
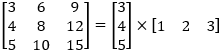
可分离卷积的第一个版本主要处理图像和内核的空间尺寸-高度和宽度。 它将一个内核分为两个较小的内核,其中最常见的是将一个3x3内核分为一个3x1和1x3内核。 因此,代替进行一次具有9个乘法的卷积,而是执行两次分别具有3个乘法两个卷积组合起来共需要6次乘法,以实现相同的效果
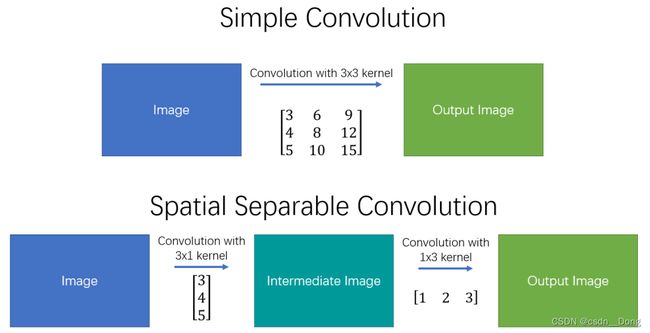
可以在空间上分离的最著名的内核之一是Sobel(用于边缘检测)
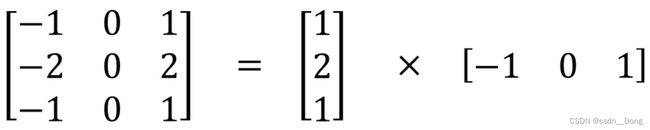
与标准卷积相比,空间可分离卷积中的矩阵乘法更少
一般的,空间可分离卷积就是将nxn的卷积分成1xn和nx1两步计算
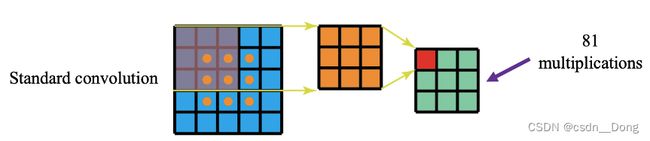
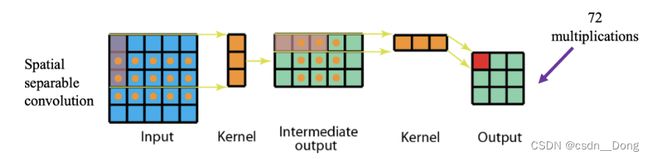
- 普通的3x3卷积在一个5x5的feature map上的计算方式如下图,每个位置需要9次乘法,一共9个位置,整个操作要81次做乘法
- 同样的状况在空间可分离卷积中的计算方式如下图,第一步先使用3x1的filter,所需计算量为:15x3=45;第二步使用1x3的filter,所需计算量为:9x3=27;总共需要72次乘法就可以得到最终结果,要小于普通卷积的81次乘法
深度可分离卷积
Separable Convolution在Google的Xception以及MobileNet论文中均有描述。它的核心思想是将一个完整的卷积运算分解为两步进行,分别为Depthwise Convolution与Pointwise Convolution。
常规卷积
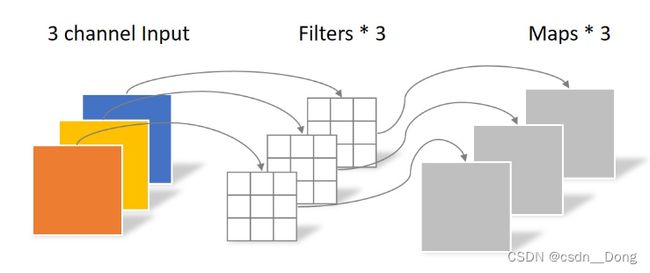
假设输入层为一个大小为64×64像素、三通道彩色图片。经过一个包含4个Filter的卷积层,最终输出4个Feature Map,且尺寸与输入层相同。整个过程可以用下图来概括。 4x3x3x3=108,参考下图:

此时,卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:N_std = 4 × 3 × 3 × 3 = 108
Depthwise Convolution(逐深度卷积(滤波))
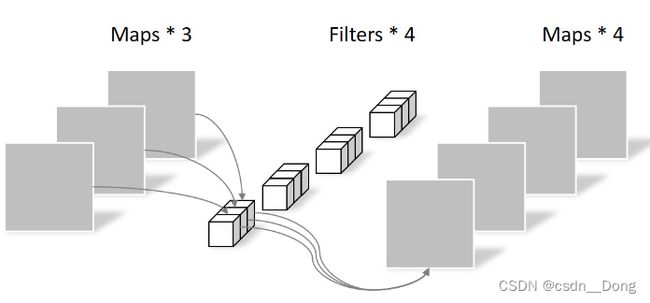
同样是上述例子,一个大小为64×64像素、三通道彩色图片首先经过第一次卷积运算,不同之处在于此次的卷积完全是在二维平面内进行,且Filter的数量与上一层的Depth相同。所以一个三通道的图像经过运算后生成了3个Feature map,如下图所示。
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的depth相同,但是这种运算对输入层的每个channel独立进行卷积运算后就结束了,没有有效的利用不同map在相同空间位置上的信息。因此需要增加另外一步操作来将这些map进行组合生成新的Feature map,即接下来的Pointwise Convolution。
Pointwise Convolution(逐点卷积(组合))
Pointwise Convolution的运算与常规卷积运算非常相似,不同之处在于卷积核的尺寸为 1×1×M,M为上一层的depth。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个Filter就有几个Feature map。如下图所示。
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:N_pointwise = 1 × 1 × 3 × 4 = 12
参数对比
参数量计算
参考<<卷积参数量计算(标准卷积,分组卷积,深度可分类)>>
简单来说就是需要多少个可以学习的参数, 这里理解的思路为因为与input fmap进行卷积, 卷积核上的每一点weight都要进行学习, 所以需要学习的量为K平方, 注意这只是单个通道的卷积核需要学习的参数量, 还要依照进来的多少个通道的input, 卷积核在扩展成一样的通道数, 接着input的每个通道都与卷积核进行卷积之后, 在依照输出的通道数,就会产生几组的卷积核组, 于是进行相乘。
- 输入尺寸为 H ∗ W ∗ C1
- 卷积核为 k∗k∗C1
- 输出特征图 通道数C2
- 标准卷积参数量计算为k * k * c1 * c2
常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
深度可分类卷积主要是由
- depthwise conv : 负责滤波 尺寸为 D k ∗ D k ∗ 1 Dk * Dk * 1Dk∗Dk∗1, 共M个, (Dk 就是 Depthwise kernel size), 作用在输入的每个通道上, 所以1表示单个通道, M就是依照输入特征的通道数分成M组
- pointwise conv : 负责转换通道, 尺寸为 1 ∗ 1 ∗ M 1 * 1 * M1∗1∗M, 共N个, 因为是做1x1的卷积, 并且要增加通道数为M, 一共有N个卷积核

Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
PyToch 实现可分离卷积

输入为(N,C_in,H,W),输出为(N,C_out,H_out,W_out).
dilation来控制卷积膨胀间隔;
groups分组卷积来控制输入和输出的连接方式,in_channels和out_channels都要被groups整除。当groups设置不同时,可以区分出分组卷积或深度可分离卷积:
- 当groups=1时,表示普通卷积层
- 当groups
- 例如 在group=2时,该操作变得等效于并排有两个卷流层,每个卷流层看到一半的输入通道并产生一半的输出通道,并且两者随后都连接起来。
示例代码
import torch.nn as nn
import torch
from torchsummary import summary
class Conv_test(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size, padding, groups):
super(Conv_test, self).__init__()
self.conv = nn.Conv2d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=kernel_size,
stride=1,
padding=padding,
groups=groups,
bias=False
)
def forward(self, input):
out = self.conv(input)
return out
标准卷积
#标准的卷积层,输入的是3x64x64,目标输出4个feature map
# 参数:4x3x3x3 = 108
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(3, 4, 3, 1, 1).to(device)
print(summary(conv, input_size=(3, 64, 64)))

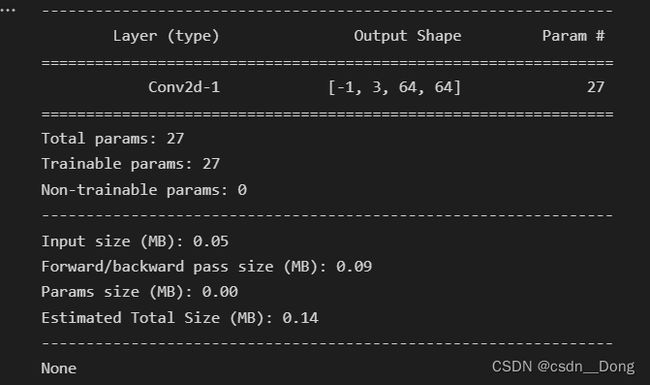
逐深度卷积
# 逐深度卷积层,输入同上
# 参数:有3个通道的3x3x1 也就是27
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(3, 3, 3, padding=1, groups=3).to(device)
print(summary(conv, input_size=(3, 64, 64)))
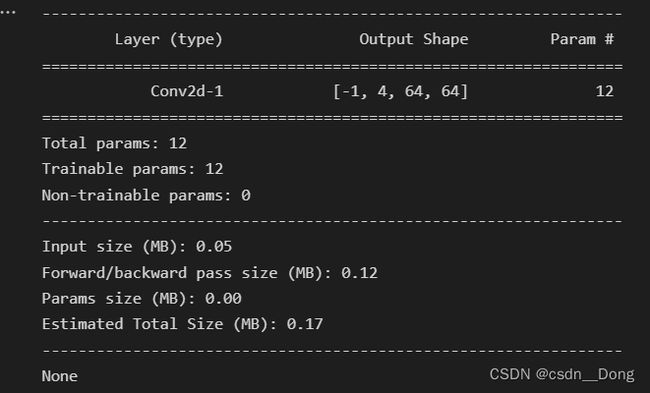
逐点卷积
# 逐点卷积,输入即逐深度卷积的输出大小,目标输出也是4个feature map
# 参数 1x1x3x4 = 12
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(3, 4, kernel_size=1, padding=0, groups=1).to(device)
print(summary(conv, input_size=(3, 64, 64)))
分组卷积
# 分组卷积层,输入的是4x64x64,目标输出4个feature map
# 参数数量 2x3x3x6
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(4, 6, 3, padding=1, groups=2).to(device)
print(summary(conv, input_size=(4, 64, 64)))

参考文档
https://blog.csdn.net/qq_40406731/article/details/107398593
https://icode.best/i/06017834795045
https://blog.csdn.net/weixin_44638957/article/details/105177543
更多深度学习文章请关注
