深度学习调参大法-学习率动态调整
本文将介绍一下六种动态学习率的调整
optim.StepLR,
optim.MultiStepLR,
optim.LambdaLR,
optim.ExponentialLR,
optim.CosineAnnealingLR,
optim.ReduceLROnPlateau
导入工具包
from torch.optim.lr_scheduler import StepLR, MultiStepLR, LambdaLR, ExponentialLR, CosineAnnealingLR, ReduceLROnPlateau
import torch
import torch.nn as nn
LambdaLR,
- new_lr = k * initial_lr
- k是由epoch为自变量算出来的值
initial_lr = 0.1
optimzer_1 = torch.optim.Adam(Net.parameters(),lr = initial_lr)
scheduler_1 = LambdaLR(optimzer_1, lr_lambda=lambda epoch: 1/(epoch + 1)) #y = 1 /(epoch + 1)
print("初始化的学习率:",optimzer_1.defaults['lr'])
for epoch in range(1,11):
optimzer_1.zero_grad()
optimzer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimzer_1.param_groups[0]['lr']))
scheduler_1.step()

StepLR,
- 以epoch等间隔的更新学习率,每次更新-----学习率*gmma—
initial_lr = 0.1
optimzer_1 = torch.optim.Adam(Net.parameters(),lr = initial_lr)
scheduler_1 = StepLR(optimzer_1, step_size=2, gamma=0.1)
print("初始化的学习率:",optimzer_1.defaults['lr'])
for epoch in range(1,11):
optimzer_1.zero_grad()
optimzer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimzer_1.param_groups[0]['lr']))
scheduler_1.step()

MultiStepLR,
- 在指定的epoch上更新学习率
initial_lr = 0.1
optimzer_1 = torch.optim.Adam(Net.parameters(),lr = initial_lr)
scheduler_1 = MultiStepLR(optimzer_1, milestones=[2,6,8], gamma=0.5)
print("初始化的学习率:",optimzer_1.defaults['lr'])
for epoch in range(1,11):
optimzer_1.zero_grad()
optimzer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimzer_1.param_groups[0]['lr']))
scheduler_1.step()

ExponentialLR,
- 指数型的一种学习更新方式—initial * gmma^epoch
initial_lr = 0.1
optimzer_1 = torch.optim.Adam(Net.parameters(),lr = initial_lr)
scheduler_1 = ExponentialLR(optimzer_1, gamma=0.1)
print("初始化的学习率:",optimzer_1.defaults['lr'])
for epoch in range(1,11):
optimzer_1.zero_grad()
optimzer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimzer_1.param_groups[0]['lr']))
scheduler_1.step()

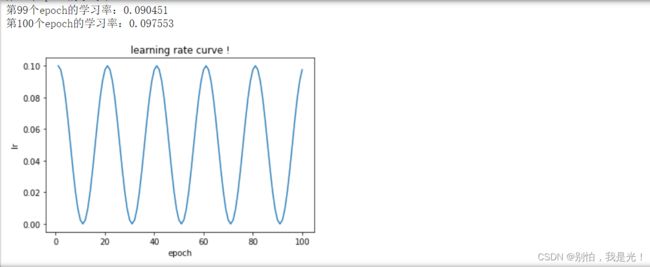
CosineAnnealingLR,
- 一种余弦的学习率调整方式, 变化为一个周期
- new_lr = eta_min + (initial - eta_min) * (1 + cos(epoch * π/T_max))
import matplotlib.pyplot as plt
initial_lr = 0.1
optimzer_1 = torch.optim.Adam(Net.parameters(),lr = initial_lr)
scheduler_1 = CosineAnnealingLR(optimzer_1, T_max=10)
print("初始化的学习率:",optimzer_1.defaults['lr'])
lr_list = []
for epoch in range(1,101):
optimzer_1.zero_grad()
optimzer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimzer_1.param_groups[0]['lr']))
lr_list.append(optimzer_1.param_groups[0]['lr'])
scheduler_1.step()
#画出epoch的变化图
plt.plot(list(range(1,101)),lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate curve !")
plt.show()
ReduceLROnPlateau
- 根据训练过程中的某些检测量调整学习率
initial_lr = 0.1
optimzer_1 = torch.optim.Adam(Net.parameters(),lr = initial_lr)
scheduler_1 = ReduceLROnPlateau(optimzer_1, mode='min',factor=0.1, patience=2) #容忍两次还没有更新,开始调整学习率
print("初始化的学习率:",optimzer_1.defaults['lr'])
lr_list = []
for epoch in range(1,15):
train_loss = 2
optimzer_1.zero_grad()
optimzer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimzer_1.param_groups[0]['lr']))
lr_list.append(optimzer_1.param_groups[0]['lr'])
scheduler_1.step(train_loss)
