超参数调优框架optuna(可配合pytorch)
目录
- 前言
- 一、optuna的使用流程
- 二、结果可视化
- 三、pytorch代码使用optuna
前言
在深度学习快速发展的今天,对于不同深度学习模型的超参数优化(hyperparameter optimization),始终是一个比较头痛的问题。在超参较少的情况下,grid search是比较常见的方式,但是随着超参数量的不断增多,特别是对于神经网络而言,训练过程的超参和NN本身的超参组成的参数空间是巨大的,grid search方法会消耗巨大的资源,而且效果很差,因此寻找一个“机器炼丹”的框架十分必要。
optuna 是一个十分常用的超参数调优框架,具有操作简单,嵌入式强和动态调整参数空间等优点。另外还有其他框架也可以进行超参优化,如李沐老师提到的automl等。
一、optuna的使用流程
首先需要在命令行 pip install optuna 载入这个第三方库,载入之后import即可。
optuna中需要注意几个关键的名词:
trail::一次实验
study::一次学习过程(包括多次实验)
import optuna
def obj(trail):
x = trail.suggest_float('x',1,5)
return (x-3)*(x-3)
stu = optuna.creat_study(study_name = 'test', direction = 'minimize')
stu.optimize(obj, n_trials = 50)
print(study.best_params)
print(study.best_trial)
print(study.best_trial.value)
该段实例代码中,函数obj定义一个含参数的需要优化的模块,带调整的超参数为 ‘x’ ,返回值为该模块的 objective value。超参x的类型为float,可调整空间为 [1,5] 左右都闭区间,常用的还有suggest_int表示整型,suggest_categorical表示字符串集合。
trail.suggest_int('name', 10, 50)
trail.suggest_categorical('active', ['relu', 'sigmoid', 'tanh'])
study表示一个学习过程,direction参数为“minimize”表示对函数obj 的返回值(同时也是每次trial的objective value)向最小的方向优化。
二、结果可视化
optuna.visualization中包含了丰富的可视化工具。比较推荐使用的是以下三个:
optuna.visualization.plot_param_importances(stu).show()
optuna.visualization.plot_optimization_history(stu).show()
optuna.visualization.plot_slice(stu).show()
plot_param_importances 展示各个超参数对结果影响的重要性
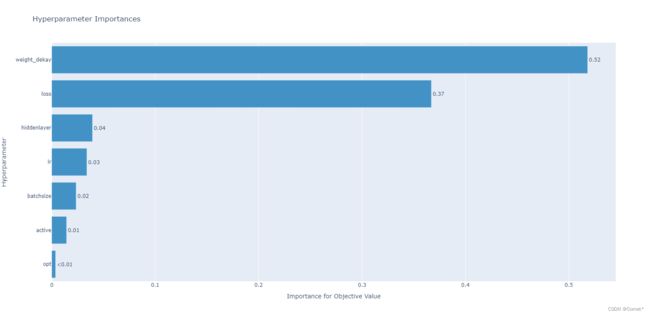
plot_optimization_history 展示在n_trail 个trail中每次的objective value和当前的最优解
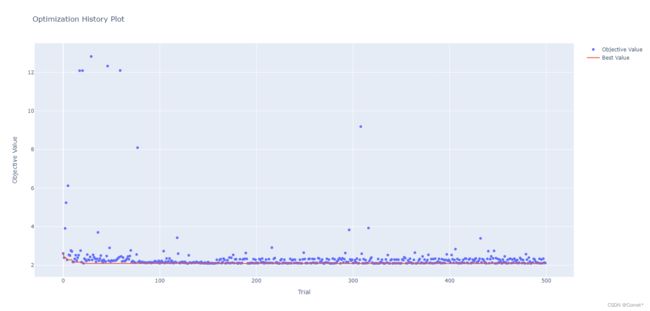
plot_slice 展示每个超参数在所有trail中取值的分布,以散点图的形式
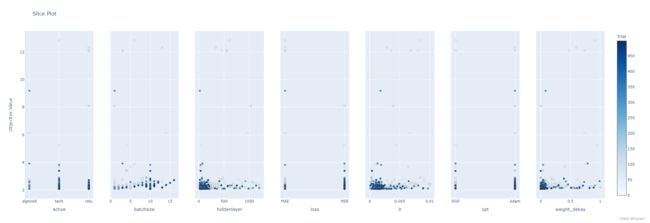
三、pytorch代码使用optuna
在pytorch构建的MLP中进行使用,可以看到该调参框架是十分灵活的,可以设置训练参数,如batchsize,learning rate,也可也设置NN的参数,如隐藏层数目,激活函数类型等。
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torch.autograd import Variable # 获取变量
import optuna
def train(batch_size, learning_rate, lossfunc, opt, hidden_layer, activefunc, weightdk,momentum): # 选出一些超参数
trainset_num = 800
testset_num = 50
train_dataset = myDataset(trainset_num)
test_dataset = myDataset(testset_num)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
# 创建CNN模型, 并设置损失函数及优化器
model = MLP(hidden_layer, activefunc).cuda()
# print(model)
if lossfunc == 'MSE':
criterion = nn.MSELoss().cuda()
elif lossfunc == 'MAE':
criterion = nn.L1Loss()
# optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weightdk)
optimizer =optim.RMSprop(model.parameters(),lr=learning_rate,weight_decay=weightdk, momentum=momentum)
# 训练过程
for epoch in range(num_epoches):
# 训练模式
model.train()
for i, data in enumerate(train_loader):
inputs, labels, _ = data
inputs = Variable(inputs).float().cuda()
labels = Variable(labels).float().cuda()
# 前向传播
out = model(inputs)
# 可以考虑加正则项
train_loss = criterion(out, labels)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
model.eval()
testloss = test() #返回测试集合上的MAE
print('Test MAE = ', resloss)
return resloss
def objective(trail):
batchsize = trail.suggest_int('batchsize', 1, 16)
lr = trail.suggest_float('lr', 1e-4, 1e-2,step=0.0001)
lossfunc = trail.suggest_categorical('loss', ['MSE', 'MAE'])
opt = trail.suggest_categorical('opt', ['Adam', 'SGD'])
hidden_layer = trail.suggest_int('hiddenlayer', 20, 1200)
activefunc = trail.suggest_categorical('active', ['relu', 'sigmoid', 'tanh'])
weightdekey = trail.suggest_float('weight_dekay', 0, 1,step=0.01)
momentum= trail.suggest_float('momentum',0,1,step=0.01)
loss = train(batchsize, lr, lossfunc, opt, hidden_layer, activefunc, weightdekey,momentum)
return loss
if __name__ == '__main__':
st=time.time()
study = optuna.create_study(study_name='test', direction='minimize')
study.optimize(objective, n_trials=500)
print(study.best_params)
print(study.best_trial)
print(study.best_trial.value)
print(time.time()-st)
optuna.visualization.plot_param_importances(study).show()
optuna.visualization.plot_optimization_history(study).show()
optuna.visualization.plot_slice(study).show()