MMDetection理解
MMDetection理解
- 1. Model整体构建流程和思想
-
- 1.1 训练核心组件
-
- 1.1.1 Backbone
- 1.1.2 Neck
- 1.1.3 Head
- 1.1.4 Enhance
- 1.1.5 BBox Assigner
- 1.1.6 BBox Sampler
- 1.1.7 BBox Encoder
- 1.1.8 Loss
- 1.1.9 Training tricks
- 2 整体抽象
-
- 2.1 流程抽象
-
- 2.1.1 Pipeline
- 2.2.2 DataParallel
- 2.2.3 Runner和Hooks
- 2.2 代码抽象
-
- 2.2.1 训练和测试整体代码抽象流程
- 2.2.2 Runner 训练和验证代码抽象
- 2.2.3 Model 训练和测试代码抽象
- 2.2.4 测试流程
- 3. Head 流程
-
- 3.1 Head 模块整体概述
-
- 3.1.1 Anchor-based与Anchor-free的本质区别 (分类方法)
-
- 3.1.1.1 本质区别 (分类方法 IoU v.s. SSC)
- 3.1.1.2 Anchor-based
- 3.1.1.3 Anchor-free
- 3.1.1.4 本质区别分析
-
- 3.1.1.4.1 分类子任务 (确定正负样本)
- 3.1.1.4.2 回归子任务 (回归目标的位置)
- 3.1.1.4.3 RetinaNet与FCOS的分类回归比较
- 3.1.2 dense_heads
- 3.1.3 roi_heads
- 3.1.4 Head内部模块
- 3.2 Head 模块构建流程
-
- 3.2.1 训练和测试中的Header函数
- 3.2.2 dense_heads 模块训练和测试流程
-
- 3.2.2.1 训练流程
-
- 3.2.2.1.1 BaseDenseHead
- 3.2.2.1.2 AnchorHead
- 3.2.2.1.3 AnchorFreeHead
- 3.2.2.2 测试流程
- 3.2.3 roi_heads 模块训练和测试流程
-
- 3.2.3.1 训练流程
- 3.2.3.2 测试流程
- 4. Backbone
-
- 4.1 ResNet
-
- 4.1.1 基本网络结构
- 4.1.2 ResNet-50-vd网络结构 (1 Stem + 4 Stages)
- 5. 常用算法
-
- 5.1 Faster R-CNN (Anchor+两阶段)
-
- 5.1.1 Faster R-CNN模型整体流程
- 5.1.2 Backbone
- 5.1.3 Neck (输入:4个特征图+输出:5个特征图)
- 5.1.4 RPN Head
- 5.1.5 BBox Assigner
-
- 5.1.5.1 AnchorGenerator
- 5.1.5.2 BBox Assigner
- 5.1.6 BBox Sampler
- 5.1.7 BBox Encoder Decoder
- 5.1.8 Loss
- 5.1.9 RPN Test
- 5.1.10 RoI Head
-
- 5.1.10.1 公共部分
- 5.1.10.2 训练逻辑
- 5.1.10.3 测试逻辑
- 5.1.10.4 RoIPool
- 5.1.10.5 RoIAlign
- 5.1.11 NMS
- 5.2 FCOS (Anchor-Free)
-
- 5.2.1 Backbone
- 5.2.2 Neck
- 5.2.3 Head
- 5.2.4 Bbox Assigner
- 5.2.5 BBox Encoder Decoder
- 5.2.6 Loss
-
- 5.2.6.1 分类分支
- 5.2.6.2 Bbox 回归分支
- 5.2.6.3 CenterNess 分支
- 5.2.7 总结
- 5.3 ATSS
-
- 5.3.1 RetinaNet 和 FCOS 深入对比分析
- 5.3.2 Backbone、Neck 和 Head
- 5.3.3 Bbox Assigner
- 5.3.4 Loss
- 5.3.5 总结
1. Model整体构建流程和思想

1.1 训练核心组件
1.1.1 Backbone
- 功能:特征提取
- 常用的Backbone:ResNet 系列、ResNetV1d 系列和 Res2Net 系列
- 典型用法
# 骨架的预训练权重路径
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet', # 骨架类名,后面的参数都是该类的初始化参数
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
- 支持的Backbones
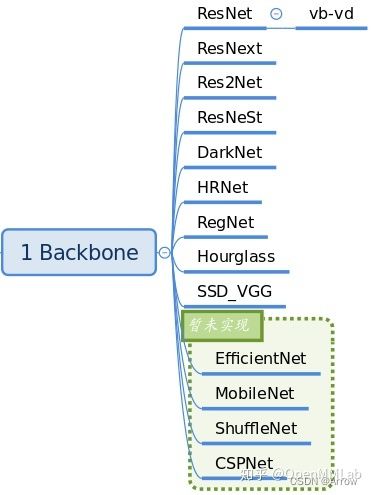
1.1.2 Neck
- 功能:
- 是 backbone 和 head 的连接层
- 主要负责对 backbone 的特征进行高效融合和增强,能够对输入的单尺度或者多尺度特征进行融合、增强输出等
- 常用的Neck:FPN
- 典型用法
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048], # 骨架多尺度特征图输出通道
out_channels=256, # 增强后通道输出
num_outs=5), # 输出num_outs个多尺度特征图
- 支持的Necks
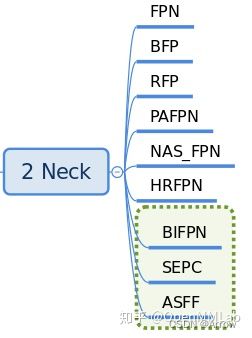
1.1.3 Head
- 功能:
- 负责分类、框和点的回归
- 在网络构建方面,理解目标检测算法主要是要理解 head 模块
- 常用的Head:每个算法都包括一个独立的 head
- 常用的Heads
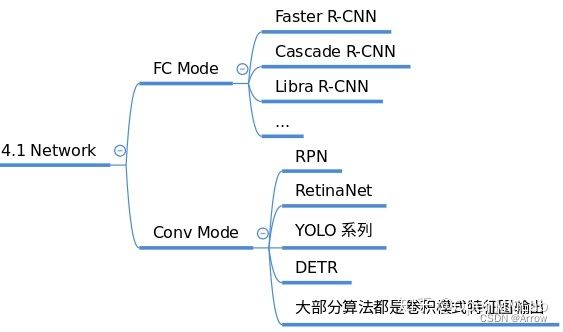
1.1.4 Enhance
- 功能:
- enhance 是即插即用、能够对特征进行增强的模块
- 其具体代码可以通过 dict 形式注册到 backbone、neck 和 head 中,非常方便
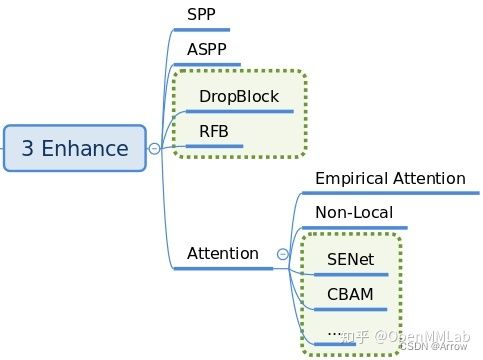
- 常用的enhance模块: SPP、ASPP、RFB、Dropout、Dropblock、DCN 和各种注意力模块 SeNet、Non_Local、CBA 等
- 支持的Enhances
1.1.5 BBox Assigner
- 功能:
- 正负样本属性分配模块作用是进行正负样本定义或者正负样本分配(可能也包括忽略样本定义),正样本就是常说的前景样本(可以是任何类别),负样本就是背景样本。
- 因为目标检测是一个同时进行分类和回归的问题,对于分类场景必然需要确定正负样本,否则无法训练。
- 该模块至关重要,不同的正负样本分配策略会带来显著的性能差异,目前大部分目标检测算法都会对这个部分进行改进。
- 支持的BBox Assigner
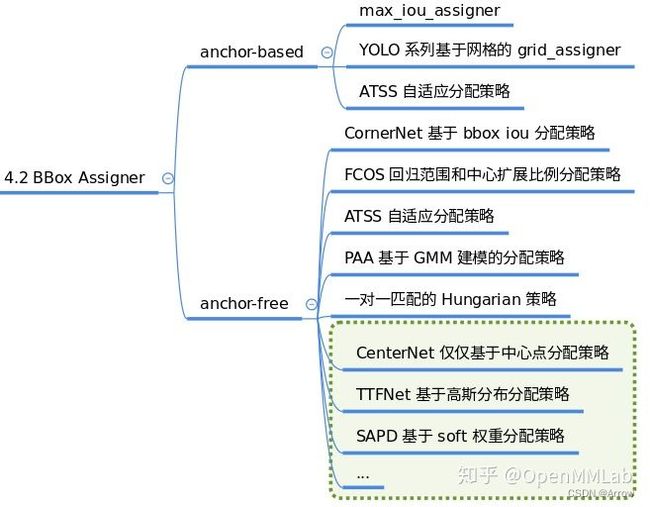
1.1.6 BBox Sampler
- 功能:
- 在确定每个样本的正负属性后,可能还需要进行样本平衡操作。
- 本模块作用是对前面定义的正负样本不平衡进行采样,力争克服该问题。
- 一般在目标检测中 gt bbox 都是非常少的,所以正负样本比是远远小于 1 的。
- 而基于机器学习观点:在数据极度不平衡情况下进行分类会出现预测倾向于样本多的类别,出现过拟合,为了克服该问题,适当的正负样本采样策略是非常必要的,一些典型采样策略如下:

1.1.7 BBox Encoder
- 功能:
- 为了更好的收敛和平衡多个 loss,具体解决办法非常多,而 bbox 编解码策略也算其中一个,bbox 编码阶段对应的是对正样本的 gt bbox 采用某种编码变换(反操作就是 bbox 解码)
- 最简单的编码是对 gt bbox 除以图片宽高进行归一化以平衡分类和回归分支,一些典型的编解码策略如下:
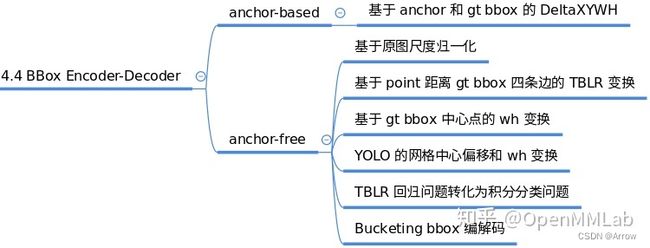
1.1.8 Loss
- 功能:
- Loss 通常都分为分类和回归 loss,其对网络 head 输出的预测值和 bbox encoder 得到的 targets 进行梯度下降迭代训练。
- loss 的设计也是各大算法重点改进对象,常用的 loss 如下:

1.1.9 Training tricks
- 训练技巧非常多,常说的调参很大一部分工作都是在设置这部分超参。这部分内容比较杂乱,很难做到完全统一,目前主流的 tricks 如下所示:
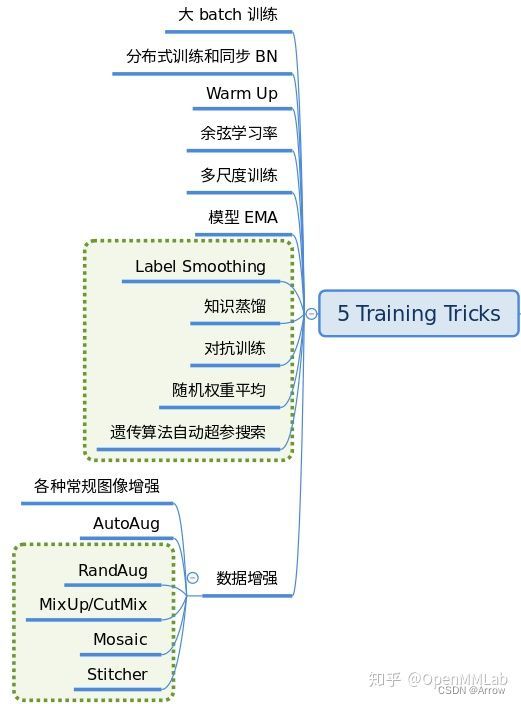
2 整体抽象
2.1 流程抽象
- 整体训练和测试抽象流程图:
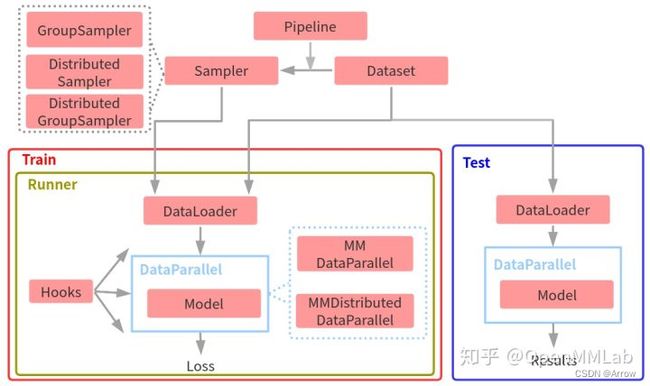
2.1.1 Pipeline
- Pipeline 实际上由一系列按照插入顺序运行的数据处理模块组成,每个模块完成某个特定功能,例如 Resize,因为其流式顺序运行特性,故叫做 Pipeline。
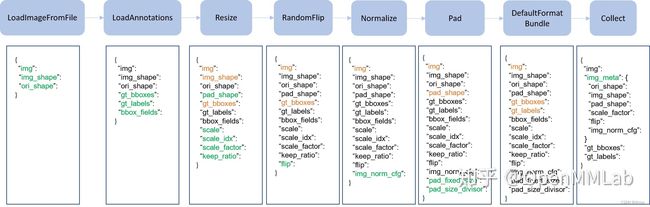
- 上图是一个非常典型的训练流程 Pipeline,每个类都接收字典输入,输出也是字典,顺序执行,其中绿色表示该类运行后新增字段,橙色表示对该字段可能会进行修改。如果进一步细分的话,不同算法的 Pipeline 都可以划分为如下部分:
- 图片和标签加载,通常用的类是 LoadImageFromFile 和 LoadAnnotations
- 数据前处理,例如统一 Resize
- 数据增强,典型的例如各种图片几何变换等,这部分是训练流程特有,测试阶段一般不采用(多尺度测试采用其他实现方式)
- 数据收集,例如 Collect
2.2.2 DataParallel
- 在 MMDetection 中 DataLoader 输出的内容不是 pytorch 能处理的标准格式,还包括了 DataContainer 对象,该对象的作用是包装不同类型的对象使之能按需组成 batch。
- 在目标检测中,每张图片 gt bbox 个数是不一样的,如果想组成 batch tensor,要么你设置最大长度,要么你自己想办法组成 batch。而考虑到内存和效率,MMDetection 通过引入 DataContainer 模块来解决上述问题,但是随之带来的问题是 pytorch 无法解析 DataContainer 对象,故需要在 MMDetection 中自行处理。
- MMDetection 选择了一种比较优雅的实现方式:MMDataParallel 和 MMDistributedDataParallel。具体来说,这两个类相比 PyTorch 自带的 DataParallel 和 DistributedDataParallel 区别是:
- 可以处理 DataContainer 对象
- 额外实现了 train_step() 和 val_step() 两个函数,可以被 Runner 调用
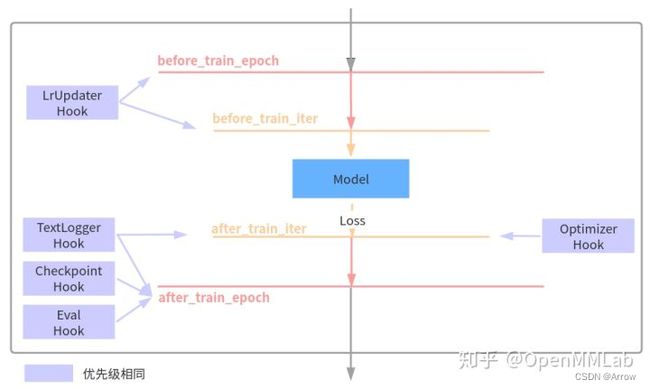
2.2.3 Runner和Hooks
- 对于任何一个目标检测算法,都需要包括优化器、学习率设置、权重保存等等组件才能构成完整训练流程,而这些组件是通用的。为了方便 OpenMMLab 体系下的所有框架复用,在 MMCV 框架中引入了 Runner 类来统一管理训练和验证流程,并且通过 Hooks 机制以一种非常灵活、解耦的方式来实现丰富扩展功能。
- Runner 封装了 OpenMMLab 体系下各个框架的训练和验证详细流程,其负责管理训练和验证过程中的整个生命周期,通过预定义回调函数,用户可以插入定制化 Hook ,从而实现各种各样的需求。下面列出了在 MMDetection 几个非常重要的 hook 以及其作用的生命周期:
2.2 代码抽象
2.2.1 训练和测试整体代码抽象流程

- 训练代码
#=================== mmdet/apis/train.py ==================
# 1.初始化 data_loaders ,内部会初始化 GroupSampler
data_loader = DataLoader(dataset,...)
# 2.基于是否使用分布式训练,初始化对应的 DataParallel
if distributed:
model = MMDistributedDataParallel(...)
else:
model = MMDataParallel(...)
# 3.初始化 runner
runner = EpochBasedRunner(...)
# 4.注册必备 hook
runner.register_training_hooks(cfg.lr_config, optimizer_config,
cfg.checkpoint_config, cfg.log_config,
cfg.get('momentum_config', None))
# 5.如果需要 val,则还需要注册 EvalHook
runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
# 6.注册用户自定义 hook
runner.register_hook(hook, priority=priority)
# 7.权重恢复和加载
if cfg.resume_from:
runner.resume(cfg.resume_from)
elif cfg.load_from:
runner.load_checkpoint(cfg.load_from)
# 8.运行,开始训练
runner.run(data_loaders, cfg.workflow, cfg.total_epochs)
2.2.2 Runner 训练和验证代码抽象
- runner 对象内部的 run 方式是一个通用方法,可以运行任何 workflow,目前常用的主要是 train 和 val。
- 当配置为:workflow = [(‘train’, 1)],表示仅仅进行 train workflow,也就是迭代训练
- 当配置为:workflow = [(‘train’, n),(‘val’, 1)],表示先进行 n 个 epoch 的训练,然后再进行1个 epoch 的验证,然后循环往复,如果写成 [(‘val’, 1),(‘train’, n)] 表示先进行验证,然后才开始训练
- 当进入对应的 workflow,则会调用 runner 里面的 train() 或者 val(),表示进行一次 epoch 迭代。其代码也非常简单,如下所示:
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self.call_hook('before_train_epoch')
for i, data_batch in enumerate(self.data_loader):
self.call_hook('before_train_iter')
self.run_iter(data_batch, train_mode=True)
self.call_hook('after_train_iter')
self.call_hook('after_train_epoch')
def val(self, data_loader, **kwargs):
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
self.call_hook('before_val_epoch')
for i, data_batch in enumerate(self.data_loader):
self.call_hook('before_val_iter')
with torch.no_grad():
self.run_iter(data_batch, train_mode=False)
self.call_hook('after_val_iter')
self.call_hook('after_val_epoch') # will call all the registered hooks
- 核心函数实际上是 self.run_iter(),如下:
def run_iter(self, data_batch, train_mode, **kwargs):
if train_mode:
# 对于每次迭代,最终是调用如下函数
outputs = self.model.train_step(data_batch,...)
else:
# 对于每次迭代,最终是调用如下函数
outputs = self.model.val_step(data_batch,...)
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'],...)
self.outputs = outputs
- 上述 self.call_hook() 表示在不同生命周期调用所有已经注册进去的 hook,而字符串参数表示对应的生命周期。以 OptimizerHook 为例,其执行反向传播、梯度裁剪和参数更新等核心训练功能:
@HOOKS.register_module()
class OptimizerHook(Hook):
def __init__(self, grad_clip=None):
self.grad_clip = grad_clip
def after_train_iter(self, runner):
runner.optimizer.zero_grad()
runner.outputs['loss'].backward()
if self.grad_clip is not None:
grad_norm = self.clip_grads(runner.model.parameters())
runner.optimizer.step()
- 可以发现 OptimizerHook 注册到的生命周期是 after_train_iter,故在每次 train() 里面运行到 self.call_hook(‘after_train_iter’) 时候就会被调用,其他 hook 也是同样运行逻辑。
2.2.3 Model 训练和测试代码抽象
- 训练和验证的时候实际上调用了 model 内部的 train_step 和 val_step 函数,理解了两个函数调用流程就理解了 MMDetection 训练和测试流程。
- 由于 model 对象会被 DataParallel 类包裹,故实际上上此时的 model,是指的 MMDataParallel 或者 MMDistributedDataParallel。以非分布式 train_step 流程为例,其内部完成调用流程图示如下:

- 调用 model 中的 train_step
#=================== mmdet/models/detectors/base.py/BaseDetector ==================
def train_step(self, data, optimizer):
# 调用本类自身的 forward 方法
losses = self(**data)
# 解析 loss
loss, log_vars = self._parse_losses(losses)
# 返回字典对象
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
def forward(self, img, img_metas, return_loss=True, **kwargs):
if return_loss:
# 训练模式
return self.forward_train(img, img_metas, **kwargs) # 在各种算法子类中实现
else:
# 测试模式
return self.forward_test(img, img_metas, **kwargs) # 在各种算法子类中实现
- forward_train 和 forward_test 需要在不同的算法子类中实现,输出是 Loss 或者 预测结果。
- 目前提供了两个具体子类,TwoStageDetector 和 SingleStageDetector ,用于实现 two-stage 和 single-stage 算法。
- 对于 TwoStageDetector 而言,其核心逻辑是:
#============= mmdet/models/detectors/two_stage.py/TwoStageDetector ============
def forward_train(...):
# 先进行 backbone+neck 的特征提取
x = self.extract_feat(img)
losses = dict()
# RPN forward and loss
if self.with_rpn:
# 训练 RPN
proposal_cfg = self.train_cfg.get('rpn_proposal',
self.test_cfg.rpn)
# 主要是调用 rpn_head 内部的 forward_train 方法
rpn_losses, proposal_list = self.rpn_head.forward_train(x,...)
losses.update(rpn_losses)
else:
proposal_list = proposals
# 第二阶段,主要是调用 roi_head 内部的 forward_train 方法
roi_losses = self.roi_head.forward_train(x, ...)
losses.update(roi_losses)
return losses
- 对于 SingleStageDetector 而言,其核心逻辑是:
#============= mmdet/models/detectors/single_stage.py/SingleStageDetector ============
def forward_train(...):
super(SingleStageDetector, self).forward_train(img, img_metas)
# 先进行 backbone+neck 的特征提取
x = self.extract_feat(img)
# 主要是调用 bbox_head 内部的 forward_train 方法
losses = self.bbox_head.forward_train(x, ...)
return losses
2.2.4 测试流程
- 由于没有 runner 对象,测试流程简单很多,下面简要概述:
- 调用 MMDataParallel 或 MMDistributedDataParallel 中的 forward 方法
- 调用 base.py 中的 forward 方法
- 调用 base.py 中的 self.forward_test 方法
- 如果是单尺度测试,则会调用 TwoStageDetector 或 SingleStageDetector 中的 simple_test 方法,如果是多尺度测试,则调用 aug_test 方法
- 最终调用的是每个具体算法 Head 模块的 simple_test 或者 aug_test 方法
3. Head 流程
3.1 Head 模块整体概述
 - 目前 MMDetection 中 Head 模块主要是按照 stage 来划分,主要包括两个 package: dense_heads 和 roi_heads , 分别对应 two-stage 算法中的第一和第二个 stage 模块,如果是 one-stage 算法则仅仅有 dense_heads 而已。
- 目前 MMDetection 中 Head 模块主要是按照 stage 来划分,主要包括两个 package: dense_heads 和 roi_heads , 分别对应 two-stage 算法中的第一和第二个 stage 模块,如果是 one-stage 算法则仅仅有 dense_heads 而已。
3.1.1 Anchor-based与Anchor-free的本质区别 (分类方法)
3.1.1.1 本质区别 (分类方法 IoU v.s. SSC)
- Anchor-based和Anchor-free方法的本质区别:如何定义正负训练样本, 参考论文《Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection》
- IoU: Intersection over Union
- SSC:Spatial and Scale Constraint
3.1.1.2 Anchor-based
- 代表算法:Faster R-CNN、SSD、RetinaNet、YoloV2/V3等
- 方法分类:
- two-stage:
- Faster R-CNN:由一个单独的区域建议网络(RPN: region proposal network)和一个区域预测网络(R-CNN: region proposal network)组成
- one-stage:2
- SSD:single shot multibox detector
- two-stage:
- Anchor是什么?
- 就是事先通过手工或聚类方法设定好的具有不同尺寸、宽高比的方框。这些方框覆盖了整张图像,目的是为了防止漏检。
- 在模型训练过程中,根据anchor与ground truth的IoU(交并比)损失对anchor的长宽以及位置进行回归,使其越来越接近ground truth,在回归的同时预测anchor的类别,最终输出这些回归分类好的anchors。
- two-stage方法要筛选和优化的anchors数量要远超one-stage方法,筛选步骤较为严谨,所以耗费时间要久一些,但是精度要高一些。在常用的检测基准上,SOTA的方法一般都是anchor-based的。
3.1.1.3 Anchor-free
- 代表算法:CornerNet、ExtremeNet、CenterNet、FCOS, YoloV1等
- 方法分类:
- keypoint-based
- center-based
3.1.1.4 本质区别分析
- 区别1:分类子任务,即定义(或选取)正负样本的方法
- 区别2:回归子任务,即从锚定箱(anchor box)或锚定点(anchor point)开始的回归
3.1.1.4.1 分类子任务 (确定正负样本)

- 上图中1为正,0为负
- 蓝色框: 真实值( ground-truth)
- 红色框:anchor box (锚框)
- 红色点:anchor point (锚点)
- RetinaNet:使用IoU同时在spatial and scale dimension选择正样本(1)
- 选择与groundTruth的IoU>=0.5(positive threshold)的初设anchor为正样本1,IOU<(negative threshold)的为负样本0,其他忽略,其中的两个threshold都是我们人为拟定的,对训练样本中所有的检测目标都适用,如图(a)所示。
- IoU来定义正负样本的方式会导致小尺寸物体的正样本数量相对大尺寸物体正样本数量偏少,进而对小样本检测性能不高。
- 模型对这种人为拟定的超参(positive/negative threshold)敏感。
- FCOS:首先在spatial dimension发现候选正样本(?),然后在scale dimension选择最后的正样本(1)
- FCOS没有默认anchor box,而是默认anchor point,如图(b)所示。
- FCOS有两步骤,首先是Spatial Constraint,如果默认point在目标内即预设为?,在目标外预设为0;然后是Scale Constarint(这部分细节这就不提了,可在FCOS论文中找到),大意是如果在这层feature map里需要regress的值 minumun value<(regress value)
3.1.1.4.2 回归子任务 (回归目标的位置)
- 在分类任务中,正负样本已经确定,在本任务中,从正样本处回归目标的位置
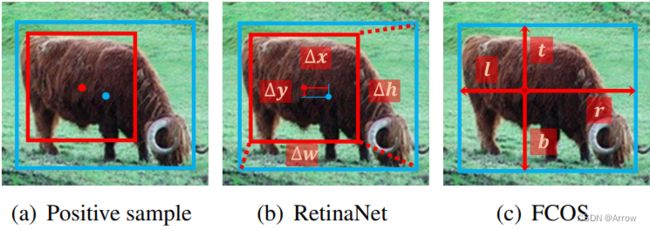
- 蓝色点: 目标的中心,真实值( ground-truth)
- 蓝色框: 目标的边界,真实值( ground-truth)
- 红色框:anchor box的边界
- 红色点:anchor box的中心(anchor point)
- RetinaNet回归:从anchor box回归,输出anchor box与object box间的四个偏移量 (offsets: Δ x , Δ y , Δ w , Δ h \Delta x, \Delta y, \Delta w, \Delta h Δx,Δy,Δw,Δh)
- FCOS回归:从anchor point 回归,输出anchor point到object边界框的四个距离值 (distances: l e f t , r i g h t , t o p , b o t t o m left, right, top, bottom left,right,top,bottom)
3.1.1.4.3 RetinaNet与FCOS的分类回归比较
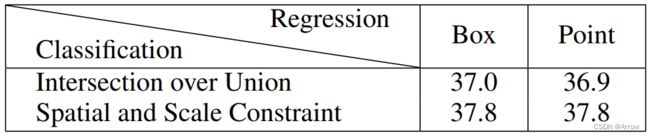
- RetinaNet:分类采用Intersection over Union(IoU),回归采用Bounding Box (BOX)
- FCOS:分类采用Spatial and scale Constraint,回归采用Point方式收敛
- 比较目的:由于分类和回归方式都不同,上表想证明到底是分类方式还是回归方式导致检测模型的性能不同。
- 分类方法相同:Table中显示当分类方式一样(横向对比),比如,IoU时,使用Box回归(mAP:37.0)与使用Point回归(mAP:36.9)时性能差别不大;同时,分类使用Spatial and Scale Constraint时,使用Box回归(mAP:37.8)与使用Point回归(mAP:37.8)时性能也差别不大。
- 回归方法相同:Table中显示当回归方式一样(纵向对比),比如,Box时,使用IoU分类(mAP:37.0)比使用Spatial and Scale Constraint分类(mAP:37.8)时性能低;同时,回归使用Point时,使用IoU分类(mAP:36.9)比使用Spatial and Scale Constraint分类(mAP:37.8)性能低。
- 结论: 由于模型的性能差异与Classification的方式有关(相关性大),与选择使用box或者Point来进行回归无关(相关性不大)。
3.1.2 dense_heads
- dense_heads 部分主要是按照 anchor-based 和 anchor-free 来划分,对应的类是 AnchorHead 和 AnchorFreeHead, 这两个类主要区别是 AnchorHead 会额外需要 anchor_generator 配置,用于生成默认 anchor。
- 同时可以看到有些类并没有直接继承这两个基类,例如 YOLOV3Head。原因是在该类中大部分函数处理逻辑都需要复写,为了简单就直接继承了 BaseDenseHead,而对于 SABLRetinaHead 而言,由于 SABL 是类似 anchor-based 和 anchor-free 混合的算法,故直接继承 BaseDenseHead 是最合适的做法。用户如果要进行扩展开发,可以依据开发便捷度自由选择最合适的基类进行继承。
3.1.3 roi_heads
- roi_heads 部分主要是按照第二阶段内部的 stage 个数来划分,经典的 Faster R-CNN 采用的是 StandardRoIHead,表示进行一次回归即可,而对于 Cascade R-CNN,其第二阶段内部也包括多个 stage 回归阶段,实现了 CascadeRoIHead,即可以构建任意次数的分类回归结果。
3.1.4 Head内部模块
- RoI 特征提取器 roi_extractor (必备)
- 共享模块 shared_heads
- bbox 分类回归模块 bbox_heads (必备)
- mask 预测模块 mask_heads
3.2 Head 模块构建流程
3.2.1 训练和测试中的Header函数
- 训练流程,two-stage Head核心函数:
- self.rpn_head.forward_train
- self.roi_head.forward_train
- 训练流程,one-stage Head核心函数:
- self.bbox_head.forward_train
- 测试流程:
- 单尺度:调用了 Head 模块自身的 simple_test方法
- 多尺度:调用了 Head 模块自身的 aug_test 方法
3.2.2 dense_heads 模块训练和测试流程
3.2.2.1 训练流程
- dense_heads 训练流程最外层函数是 forward_train, 其实现是在 mmdet/models/dense_heads/base_dense_head.py/BaseDenseHead 中,如下所示:
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
# 调用各个子类实现的 forward 方法
outs = self(x)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
# 调用各个子类实现的 loss 计算方法
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:
return losses
else:
# two-stage 算法还需要返回 proposal
proposal_list = self.get_bboxes(*outs, img_metas, cfg=proposal_cfg)
return losses, proposal_list
- 每个算法的 Head 子类一般不会重写上述方法,但是每个 Head 子类都会重写 forward 和 loss 方法,其中 forward 方法用于运行 head 网络部分输出分类回归分支的特征图,而 loss 方法接收 forward 输出,并且结合 label 计算 loss
3.2.2.1.1 BaseDenseHead
- BaseDenseHead 基类过于简单,对于 anchor-based 和 anchor-free 算法又进一步进行了继承,得到 AnchorHead 或者 AnchorFreeHead 类。
- 在目前的各类算法实现中,绝大部分子类都是继承自 AnchorHead 或者 AnchorFreeHead,其提供了一些相关的默认操作,如果直接继承 BaseDenseHead 则子类需要重写大部分算法逻辑。
3.2.2.1.2 AnchorHead
- 主要是封装了 anchor 生成过程。下面对 forward 和 loss 函数进行分析:
# BBoxTestMixin 是多尺度测试时候调用
class AnchorHead(BaseDenseHead, BBoxTestMixin):
# feats 是 backbone+neck 输出的多个尺度图
def forward(self, feats):
# 对每张特征图单独计算预测输出
return multi_apply(self.forward_single, feats)
# head 模块分类回归分支输出
def forward_single(self, x):
cls_score = self.conv_cls(x)
bbox_pred = self.conv_reg(x)
return cls_score, bbox_pred
- forward 函数比较简单,就是对多尺度特征图中每个特征图分别计算分类和回归输出即可,主要复杂度在 loss 函数中,其运行流程图如下所示:
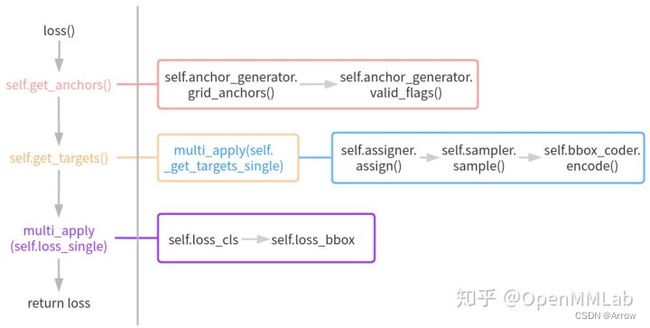
- 在 loss 函数中首先会调用 get_anchors 函数得到默认 anchor 列表。而 get_anchors 函数内部会先计算多尺度特征图上每个特征点位置的 anchor,然后再计算有效 anchor 标志(因为在组织 batch 时候有些图片会进行左上角 padding,这部分像素人为加的,不需要考虑 anchor)
- 然后基于 anchor、gt bbox 以及其他必备信息调用 get_targets 函数计算每个预测分支对应的 target。get_targets 函数内部会调用 multi_apply(_get_targets_single) 函数对每张图片单独计算 target,而 _get_targets_single 函数实现的功能比较多,包括:bbox assigner、bbox sampler 和 bbox encoder 三个关键环节
- 在得到 targets 后,调用 loss_single 函数计算每个输出尺度的 loss 值,最终返回各个分支的 loss
3.2.2.1.3 AnchorFreeHead
- AnchorFreeHead 逻辑比 AnchorHead 简单很多,主要是因为 anchor-free 类算法比 anchor-based 算法更加灵活多变,而且少了复杂的 anchor 生成过程,其 forward 方法实现和 AnchorHead 完全相同,而 loss 方法没有实现,其子类必须实现。
3.2.2.2 测试流程
- 最终会调用 Head 模块的 simple_test 或 aug_test 方法分别进行单尺度和多尺度测试,涉及到具体代码层面,one-stage 和 two-stage 调用函数有区别,但是最终调用的依然是 Head 模块的 get_bboxes 方法。
3.2.3 roi_heads 模块训练和测试流程
- 以最常用的 StandardRoIHead 为例进行分析。
3.2.3.1 训练流程
- 训练流程最外层依然是调用 forward_train, 其核心代码如下所示:
def forward_train(self,
x,
img_metas,
proposal_list,
gt_bboxes,
gt_labels,
...):
if self.with_bbox or self.with_mask:
num_imgs = len(img_metas)
sampling_results = []
for i in range(num_imgs):
# 对每张图片进行 bbox 正负样本属性分配
assign_result = self.bbox_assigner.assign(
proposal_list[i], ...)
# 然后进行正负样本采样
sampling_result = self.bbox_sampler.sample(
assign_result,
proposal_list[i],
...)
sampling_results.append(sampling_result)
losses = dict()
if self.with_bbox:
# bbox 分支 forward,返回 loss
bbox_results = self._bbox_forward_train(...)
losses.update(bbox_results['loss_bbox'])
if self.with_mask:
# mask 分支 forward,返回 loss
return losses
def _bbox_forward_train(self, x, sampling_results, gt_bboxes, gt_labels,
img_metas):
rois = bbox2roi([res.bboxes for res in sampling_results])
# forward
bbox_results = self._bbox_forward(x, rois)
# 计算 target
bbox_targets = self.bbox_head.get_targets(...)
# 计算 loss
loss_bbox = self.bbox_head.loss(...)
return ...
def _bbox_forward(self, x, rois):
# roi 提取
bbox_feats = self.bbox_roi_extractor(
x[:self.bbox_roi_extractor.num_inputs], rois)
# bbox head 网络前向
cls_score, bbox_pred = self.bbox_head(bbox_feats)
return ...
-
从上述逻辑可以看出,StandardRoIHead 中 forward_train 函数仅仅是对内部的 bbox_head 相关函数进行调用,例如 get_targets 和 loss,本身 StandardRoIHead 类不做具体算法逻辑计算。
-
可以参考 Faster R-CNN 配置文件理解 StandardRoIHead 和 bbox_head 的关系:
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))))
- StandardRoIHead 类包装了 bbox_roi_extractor 和 bbox_head 的实例,前者用于 RoI 特征提取,后者才是真正计算分类和回归的逻辑。在 bbox_head 中除了网络模型有些变换外,loss计算过程是非常类似的,其 get_targets 和 loss 计算过程都是封装在基类 mmdet/models/roi_heads/bbox_heads/bbox_head.py 中。
3.2.3.2 测试流程
- 测试流程是调用 Head 模块的 simple_test 和 aug_test 函数,单尺度测试 bbox 相关实现代码在 mmdet/models/roi_heads/test_mixins.py/BBoxTestMixin 的 simple_test_bboxes 函数中。
def simple_test_bboxes(self,
x,
...):
rois = bbox2roi(proposals)
# roi 提取+ forward,输出预测结果
bbox_results = self._bbox_forward(x, rois)
cls_score = bbox_results['cls_score']
bbox_pred = bbox_results['bbox_pred']
det_bboxes = []
det_labels = []
for i in range(len(proposals)):
# 对预测结果进行解码输出 bbox 和对应 label
det_bbox, det_label = self.bbox_head.get_bboxes(...)
det_bboxes.append(det_bbox)
det_labels.append(det_label)
return det_bboxes, det_labels
- 实际上依然是调用了 Head 模块内部的 get_bboxes 函数,处理逻辑和 dense_head 差不多( 解码+还原尺度+ nms)。
4. Backbone
4.1 ResNet
4.1.1 基本网络结构
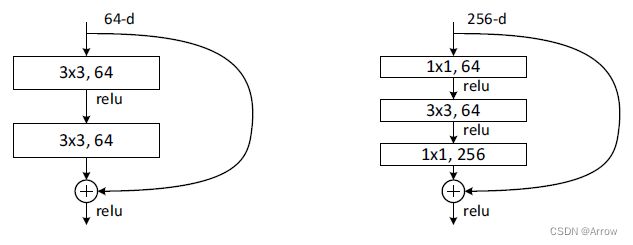
Basic Block BottleNeck

4.1.2 ResNet-50-vd网络结构 (1 Stem + 4 Stages)
- (a):Stem Block
- 输入卷积+MaxPool
- 输入Stem可以为:
- 3个3x3的卷积块 (如下图)
- 1个7x7的卷积块(见ResNet原论文)
- (b):Stage1-Block1
- ©:Stage1-Block2
- (d):FC-block

5. 常用算法
5.1 Faster R-CNN (Anchor+两阶段)
- Faster R-CNN (Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks) 是目标检测领域最为经典的方法之一,通过 RPN(Region Proposal Networks) 区域提取网络和 R-CNN 网络联合训练实现高效目标检测。其简要发展历程为:
- R-CNN。首先通过传统的 selective search 算法在图片上预取 2000 个左右 Region Proposal;接着将这些 Region Proposal 通过前处理统一尺寸输入到 CNN 中进行特征提取;然后把所提取的特征输入到 SVM 支持向量机中进行分类;最后对分类后的 Region Proposal 进行 bbox 回归。此时算法的整个过程较为繁琐,速度也较慢。
- Fast R-CNN。首先通过传统的 selective search 算法在图片上预取 2000 个左右 Region Proposal;接着对整张图片进行特征提取;然后利用 Region Proposal 坐标在 CNN 的最后一个特征图上进去 RoI 特征图提取;最后将所有 RoI 特征输入到分类和回归模块中。此时算法的整个过程相比 R-CNN 得到极大的简化,但依然无法联合训练。
- Faster R-CNN。首先通过可学习的 RPN 网络进行 Region Proposal 的预取;接着利用 Region Proposal 坐标在 CNN 的特征图上进行 RoI 特征图提取;然后利用 RoI Pooling 层进行空间池化使其所有特征图输出尺寸相同;最后将所有特征图输入到后续的 FC 层进行分类和回归。此时算法的整个过程一气呵成,实现了端到端训练。
- Faster R-CNN 的出现改变了整个目标检测算法的发展历程。之所以叫做 two-stage 检测器,原因是其包括一个区域提取网络 RPN 和 RoI Refine 网络 R-CNN,同时为了将 RPN 提取的不同大小的 RoI 特征图组成 batch 输入到后面的 R-CNN 中,在两者中间还插入了一个 RoI Pooling 层,可以保证任意大小特征图输入都可以变成指定大小输出。简要结构图如下所示:

5.1.1 Faster R-CNN模型整体流程

- 图片输入到 ResNet 中进行特征提取,输出 4 个特征图,按照特征图从大到小排列,分别是 C2 C3 C4 C5,stride = 4,8,16,32
- 4 个特征图输入到 FPN 模块中进行特征融合,输出 5 个通道数相同的特征图,分别是 p2 ~ p6,stride = 4,8,16,32,64
- FPN 输出的 5 个特征图,输入到同一个 RPN 或者说 5 个相同的 RPN 中,每个分支都进行前后景分类和 bbox 回归,然后就可以和 label 计算 loss
- 在 5 个 RPN 分支输出的基础上,采用 RPN test 模块输出指定个数的 Region Proposal,将 Region Proposal 按照重映射规则,在对应的 p2 ~ p5 特征图上进行特征提取,注意并没有使用 p6 层特征图,从而得到指定个数例如 2k 个 Region Proposal 特征图
- 将 2k 个不同大小的 RoI 区域特征图输入到 RoIAlign 或者 RoIPool 层中进行统一采样,得到指定输出 shape 的 2k 个特征图
组成 batch 输入到两层 FC 中进行多类别的分类和回归,其 loss 和 RPN 层 loss 相加进行联合训练
5.1.2 Backbone
- 以 ResNet50 为例
# 使用 pytorch 提供的在 imagenet 上面训练过的权重作为预训练权重
pretrained='torchvision://resnet50',
backbone=dict(
# 骨架网络类名
type='ResNet',
# 表示使用 ResNet50
depth=50,
# ResNet 系列包括 stem+ 4个 stage 输出
num_stages=4,
# 表示本模块输出的特征图索引,(0, 1, 2, 3),表示4个 stage 输出都需要,
# 其 stride 为 (4,8,16,32),channel 为 (256, 512, 1024, 2048)
out_indices=(0, 1, 2, 3),
# 表示固定 stem 加上第一个 stage 的权重,不进行训练
frozen_stages=1,
# 所有的 BN 层的可学习参数都不需要梯度,也就不会进行参数更新
norm_cfg=dict(type='BN', requires_grad=True),
# backbone 所有的 BN 层的均值和方差都直接采用全局预训练值,不进行更新
norm_eval=True,
# 默认采用 pytorch 模式
style='pytorch'),
- out_indices
- ResNet 提出了骨架网络设计范式即 stem+n stage+ cls head,对于 ResNet 而言,其实际 forward 流程是 stem -> 4 个 stage -> 分类 head
- stem 的输出 stride 是 4,而 4 个 stage 的输出 stride 是 4,8,16,32,这 4 个输出就对应 out_indices 索引。
- 如果你想要输出 stride=4 的特征图,那么你可以设置 out_indices=(0,),如果你想要输出 stride=4 和 8 的特征图,那么你可以设置 out_indices=(0, 1)。
- frozen_stages
- 该参数表示你想冻结前几个 stages 的权重,ResNet 结构包括 stem+4 stages
- frozen_stages=-1,表示全部可学习
- frozen_stage=0,表示stem权重固定
- frozen_stages=1,表示 stem 和第一个 stage 权重固定
- frozen_stages=2,表示 stem 和前两个 stage 权重固定
- norm_cfg 和 norm_eval
- norm_cfg 表示所采用的归一化算子,一般是 BN 或者 GN,而 requires_grad 表示该算子是否需要梯度,也就是是否进行参数更新,而布尔参数 norm_eval 是用于控制整个骨架网络的归一化算子是否需要变成 eval 模式。
- norm_cfg=dict(type=‘BN’, requires_grad=True),表示通过 Registry 模式实例化 BN 类,并且设置为参数可学习。在 MMDetection 中会常看到通过字典配置方式来实例化某个类的做法, 底层是采用了装饰器模式进行构建,最大好处是扩展性极强,类和类之间的耦合度降低。
- style
- style=‘caffe’ 和 style=‘pytorch’ 的差别就在 Bottleneck 模块中
- Bottleneck 是标准的 1x1-3x3-1x1 结构,考虑 stride=2 下采样的场景,caffe 模式下,stride 参数放置在第一个 1x1 卷积上,而 Pyorch 模式下,stride 放在第二个 3x3 卷积上
5.1.3 Neck (输入:4个特征图+输出:5个特征图)
neck=dict(
type='FPN',
# ResNet 模块输出的4个尺度特征图通道数
in_channels=[256, 512, 1024, 2048],
# FPN 输出的每个尺度输出特征图通道
out_channels=256,
# FPN 输出特征图个数
num_outs=5),
- ResNet输出的 4 个特征图(c2 c3 c4 c5)都会被利用。其详细流程是:
- 将(c2 c3 c4 c5) 4 个特征图全部经过各自 1x1 卷积进行通道变换变成 m2~m5,输出通道统一为 256
- 从 m5 开始,先进行 2 倍最近邻上采样,然后和 m4 进行 add 操作,得到新的 m4
- 将新 m4 进行 2 倍最近邻上采样,然后和 m3 进行 add 操作,得到新的 m3
- 将新 m3 进行 2 倍最近邻上采样,然后和 m2 进行 add 操作,得到新的 m2
- 对 m5 和新的融合后的 m4 ~ m2,都进行各自的 3x3 卷积,得到 4 个尺度的最终输出 p5 ~ p2
- 将 c5 进行 3x3 且 stride=2 的卷积操作,得到 p6,目的是提供一个感受野非常大的特征图,有利于检测超大物体
- 故 FPN 模块实现了c2 ~ c5 4 个特征图输入,p2 ~ p6 5个特征图输出,其 strides = (4,8,16,32,64)。
5.1.4 RPN Head
- RPN:Region Proposal Network(区域候选网络)
- RPN网络替代了之前RCNN版本的Selective Search,用于生成候选框。这里任务有两部分,一个是分类:判断所有预设anchor是属于positive还是negative(即anchor内是否有目标,二分类);还有一个bounding box regression:修正anchors得到较为准确的proposals。因此,RPN网络相当于提前做了一部分检测,即判断是否有目标(具体什么类别这里不判断),以及修正anchor使框的更准一些。
- Anchor:
- Anchor:特征图上的每个像素点就是一个Anchor
- Anchor Box:以每个anchor为中心点,人为设置不同的尺度(scale)和高宽比(aspect ratio),即可得到基于anchor的多个anchor box
- 在一幅图像中,要检测的目标可能出现在图像的任意位置,并且目标可能是任意的大小和任意形状,方法为:
- 使用CNN提取的Feature Map的点,来定位目标的位置(即Anchor Box的中心)
- 使用Anchor box的Scale来表示目标的大小
- 使用Anchor box的Aspect Ratio(高宽比)来表示目标的形状
- Anchor Box的中心:Anchor Box的生成是以CNN网络最后生成的Feature Map上的点为中心的(映射回原图的坐标)
- 举例说明:使用ResNet网络对输入的图像下采样了16倍,也就是Feature Map上的一个点对应于输入图像上的一个( 16 × 16 16 \times 16 16×16) 的正方形区域(感受野)。根据预定义的Anchor,以Feature Map上的一点为中心 就可以在原图上生成9种不同形状不同大小的边框,如下图所示:
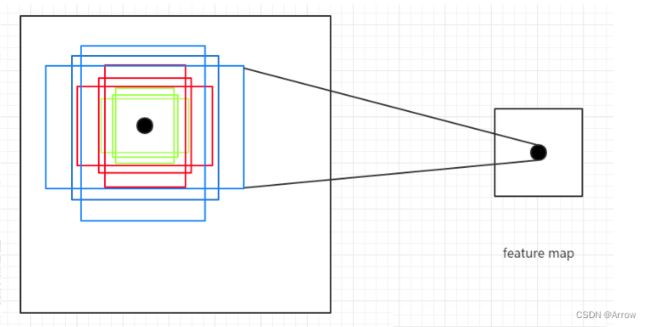
- 根据CNN的感受野,一个Feature Map上的点对应于原图的( 16 × 16 16 \times 16 16×16)的正方形区域,仅仅利用该区域的边框进行目标定位,其精度无疑会很差,甚至根本“框”不到目标。 而加入了Anchor后,一个Feature Map上的点可以生成9中不同形状不同大小的框,这样“框”住目标的概率就会很大,就大大的提高了检查的召回率;再通过后续的网络对这些边框进行调整,其精度也能大大的提高。
- 生成Anchors - 完整配置
rpn_head=dict(
type='RPNHead',
# FPN 层输出特征图通道数
in_channels=256,
# 中间特征图通道数
feat_channels=256,
# 后面分析
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
# 后面分析
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
# 后面分析
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
- RPN Head 网络比较简单,就一个卷积进行特征通道变换,加上两个输出分支即可,如下所示:
def _init_layers(self):
"""Initialize layers of the head."""
# 特征通道变换
self.rpn_conv = nn.Conv2d(
self.in_channels, self.feat_channels, 3, padding=1)
# 分类分支,类别固定是2,表示前/背景分类
# 并且由于 cls loss 是 bce,故实际上 self.cls_out_channels=1
self.rpn_cls = nn.Conv2d(self.feat_channels,
self.num_anchors * self.cls_out_channels, 1)
# 回归分支,固定输出4个数值,表示基于 anchor 的变换值
self.rpn_reg = nn.Conv2d(self.feat_channels, self.num_anchors * 4, 1)
- 5 个 RPN Head 共享所有分类或者回归分支的卷积权重,经过 Head 模块的前向流程输出一共是 5*2 个特征图
5.1.5 BBox Assigner
5.1.5.1 AnchorGenerator
- Faster R-CNN属于 Anchor-based 算法,在运行 bbox 属性分配前,需要得到每个输出特征图位置的 anchor 列表,故在分析 BBox Assigner 前,需要先详细说明下 anchor 生成过程,其对应配置如下所示:
anchor_generator=dict(
type='AnchorGenerator',
# 相当于 octave_base_scale,表示每个特征图的 base scales
scales=[8],
# 每个特征图有 3 个高宽比例
ratios=[0.5, 1.0, 2.0],
# 特征图对应的 stride,必须和特征图 stride 一致,不可以随意更改
strides=[4, 8, 16, 32, 64]),
- 可以看出一共 5 个输出层,每个输出层包括 3 个高宽比例和 1 种尺度,也就是说每一层的每个特征图像素坐标处都包括 3 个 anchor,一共 15 个 anchor

- 相同颜色表示在该特征图中基本尺度是相同的,只是宽高比不一样而已。
5.1.5.2 BBox Assigner
assigner=dict(
# 最大 IoU 原则分配器
type='MaxIoUAssigner',
# 正样本阈值
pos_iou_thr=0.7,
# 负样本阈值
neg_iou_thr=0.3,
# 正样本阈值下限
min_pos_iou=0.3,
# 忽略 bboxes 的阈值,-1 表示不忽略
ignore_iof_thr=-1),
- 如果 anchor 和所有 gt bbox 的最大 iou 值小于 0.3,那么该 anchor 就是背景样本
- 如果 anchor 和所有 gt bbox 的最大 iou 值大于等于 0.7,那么该 anchor 就是高质量正样本,该阈值比较高,这个阈值设置需要和后续的 R-CNN 模块匹配
- 如果 gt bbox 和所有 anchor 的最大 iou 值大于等于 0.3(可以看出可能有某些 gt bbox 没有和任意 anchor 匹配),那么该 gt bbox 所对应的 anchor 也是正样本
- 其余样本全部为忽略样本,但是由于 neg_iou_thr 和 min_pos_iou 相等,故不存在忽略样本
5.1.6 BBox Sampler
- Faster R-CNN 是通过正负样本采样模块来克服正负样本不平衡问题
sampler=dict(
# 随机采样
type='RandomSampler',
# 采样后每张图片的训练样本总数,不包括忽略样本
num=256,
# 正样本比例
pos_fraction=0.5,
# 正负样本比例,用于确定负样本采样个数上界
neg_pos_ub=-1,
# 是否加入 gt 作为 proposals 以增加高质量正样本数
add_gt_as_proposals=False)
- num = 256 表示采样后每张图片的样本总数,pos_fraction 表示其中的正样本比例,具体是正样本采样 128 个,那么理论上负样本采样也是 128 个
- neg_pos_ub 表示负和正样本比例上限,用于确定负样本采样个数上界,例如打算采样 1000 个样本,正样本打算采样 500 个,但是可能正样本才 200 个,那么正样本实际上只能采样 200 个,如果设置 neg_pos_ub=-1 那么就会对负样本采样 800 个,用于凑足 1000 个,但是如果设置了 neg_pos_ub 比例,例如 1.5,那么负样本最多采样 200x1.5=300 个,最终返回的样本实际上不够 1000 个,默认情况 neg_pos_ub=-1
- add_gt_as_proposals=True 是防止高质量正样本太少而加入的,可以保证前期收敛更快、更稳定,属于训练技巧,在 RPN 模块设置为 False,主要用于 R-CNN,因为前期 RPN 提供的正样本不够,可能会导致训练不稳定或者前期收敛慢的问题。
- 经过随机采样函数后,可以有效控制 RPN 网络计算 loss 时正负样本平衡问题。
5.1.7 BBox Encoder Decoder
- 在 anchor-based 算法中,为了利用 anchor 信息进行更快更好的收敛,一般会对 head 输出的 bbox 分支 4 个值进行编解码操作,作用有两个:
- 更好的平衡分类和回归分支 loss,以及平衡 bbox 四个预测值的 loss
- 训练过程中引入 anchor 信息,加快收敛
- Faster R-CNN采用的编解码函数是主流的 DeltaXYWHBBoxCoder,其配置如下:
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
-
target_means 和 target_stds 相当于对 bbox 回归的 4 个参数 ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx,ty,tw,th) 进行变换。
-
在不考虑 target_means 和 target_stds 情况下,其编码公式如下:
t x ∗ = ( x ∗ − x a ) / w a t y ∗ = ( y ∗ − y a ) / h a t w ∗ = l o g ( w ∗ / w a ) t h ∗ = l o g ( h ∗ / h a ) t_x^* = (x^* - x_a)/w_a \\ t_y^* = (y^* - y_a)/h_a \\ t_w^* = log(w^*/w_a) \\ t_h^* = log(h^*/h_a) tx∗=(x∗−xa)/waty∗=(y∗−ya)/hatw∗=log(w∗/wa)th∗=log(h∗/ha)- x ∗ , y ∗ x^*, y^* x∗,y∗:是 gt bbox 的中心 xy 坐标
- w ∗ , h ∗ w^*, h^* w∗,h∗:是 gt bbox 的wh值
- x a , y a x_a, y_a xa,ya:是 anchor 的中心 xy 坐标
- w a , h a w_a, h_a wa,ha:是 anchor 的wh值
- t x ∗ , t y ∗ t_x^*, t_y^* tx∗,ty∗:表示 gt bbox 中心相对于 anchor 中心点的偏移,并且通过除以 anchor 的 wh 进行归一化
- t w ∗ , t h ∗ t_w^*, t_h^* tw∗,th∗:表示 gt bbox 的 wh 除以 anchor 的 wh,然后取 log 非线性变换即可。
-
考虑编码过程 target_means 和 target_stds 情况下,核心代码如下:
dx = (gx - px) / pw
dy = (gy - py) / ph
dw = torch.log(gw / pw)
dh = torch.log(gh / ph)
deltas = torch.stack([dx, dy, dw, dh], dim=-1)
# 最后减掉均值,除以标准差
means = deltas.new_tensor(means).unsqueeze(0)
stds = deltas.new_tensor(stds).unsqueeze(0)
deltas = deltas.sub_(means).div_(stds)
- 解码过程是编码过程的反向,比较容易理解,其核心代码如下:
# 先乘上 stds,加上 means
means = deltas.new_tensor(means).view(1, -1).repeat(1, deltas.size(1) // 4)
stds = deltas.new_tensor(stds).view(1, -1).repeat(1, deltas.size(1) // 4)
denorm_deltas = deltas * stds + means
dx = denorm_deltas[:, 0::4] # 0, 4, 8 ...
dy = denorm_deltas[:, 1::4] # 1, 5, 9 ...
dw = denorm_deltas[:, 2::4] # 2, 6, 10 ...
dh = denorm_deltas[:, 3::4] # 3, 7, 11 ...
# wh 解码
gw = pw * dw.exp()
gh = ph * dh.exp()
# 中心点 xy 解码
gx = px + pw * dx
gy = py + ph * dy
# 得到 x1y1x2y2 的 gt bbox 预测坐标
x1 = gx - gw * 0.5
y1 = gy - gh * 0.5
x2 = gx + gw * 0.5
y2 = gy + gh * 0.5
5.1.8 Loss
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
- RPN 采用的 loss 是常用的 BCE (Binary Cross Entropy) Loss 和 L1 Loss,不需要详细描述。
5.1.9 RPN Test
- 到目前为止, RPN 的整个训练流程就分析完后,但是实际上 RPN 是作为一个 RoI 提取模块,真正核心的是 R-CNN 部分,为了实现联合训练,RPN 不仅仅要自己进行训练,还要同时输出 RoI,然后利用这些 RoI 在 FPN 输出的特征图上进行截取,最后输入给 R-CNN 进行分类和回归。
- 一个核心的问题是如何得到这些 RoI,实际上是调用了 RPN 的 test 过程。由于 RPN 也是和 RetinaNet 一样的 one-stage 算法,其大概过程和 RetinaNet 基本一致:
rpn=dict(
# 是否跨层进行 NMS 操作
nms_across_levels=False,
# nms 前每个输出层最多保留 1000 个预测框
nms_pre=1000,
# nms 后每张图片最多保留 1000 个预测框
nms_post=1000,
# 每张图片最终输出检测结果最多保留 1000 个,RPN 层没有使用这个参数
max_num=1000,
# nms 阈值
nms_thr=0.7,
# 过滤掉的最小 bbox 尺寸
min_bbox_size=0),
-
- 对 batch 输入图片经过 Backbone+FPN+RPN Head 后输出 5 个特征图,每个图包括两个分支 rpn_cls_score,rpn_bbox_pred,首先遍历每张图,然后遍历每张图片中的每个输出层进行后续处理
-
- 对每层的分类 rpn_cls_score 进行 sigmoid 操作得到概率值
-
- 按照分类预测分值排序,保留前 nms_pre 个预测结果
if cfg.nms_pre > 0 and scores.shape[0] > cfg.nms_pre:
# sort is faster than topk
# _, topk_inds = scores.topk(cfg.nms_pre)
ranked_scores, rank_inds = scores.sort(descending=True)
topk_inds = rank_inds[:cfg.nms_pre]
scores = ranked_scores[:cfg.nms_pre]
rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]
anchors = anchors[topk_inds, :]
-
- 对每张图片的 5 个输出层都运行 2 ~ 3 步骤,将预测结果全部收集,然后进行解码
scores = torch.cat(mlvl_scores)
anchors = torch.cat(mlvl_valid_anchors)
rpn_bbox_pred = torch.cat(mlvl_bbox_preds)
proposals = self.bbox_coder.decode(
anchors, rpn_bbox_pred, max_shape=img_shape)
-
- 进行统一的 NMS 操作,每张图片最终保留 cfg.nms_post 个预测框
nms_cfg = dict(type='nms', iou_threshold=cfg.nms_thr)
dets, keep = batched_nms(proposals, scores, ids, nms_cfg)
return dets[:cfg.nms_post]
- 经过 RPN test 计算后每张图片可以提供最多 nms_post 个候选框,一般该值为 2000。
5.1.10 RoI Head
- R-CNN 模块接收 RPN 输出的每张图片共 nms_post 个候选框,然后对这些候选框进一步 refine,输出包括区分具体类别和 bbox 回归。
- 该模块网络构建方面虽然简单,但是也包括了 RPN 中涉及到的组件,例如 BBox Assigner、BBox Sampler、BBox Encoder Decoder、Loss 等等,除此之外,还包括一个额外的 RPN 到 R-CNN 数据转换模块:RoIAlign 或者 RoIPool, 下面详细描述。
roi_head=dict(
# 一次 refine head,另外对应的是级联结构
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
# 2 个共享 FC 模块
type='Shared2FCBBoxHead',
# 输入通道数,相等于 FPN 输出通道
in_channels=256,
# 中间 FC 层节点个数
fc_out_channels=1024,
# RoIAlign 或 RoIPool 输出的特征图大小
roi_feat_size=7,
# 类别个数
num_classes=80,
# bbox 编解码策略,除了参数外和 RPN 相同,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
# 影响 bbox 分支的通道数,True 表示 4 通道输出,False 表示 4×num_classes 通道输出
reg_class_agnostic=False,
# CE Loss
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
# L1 Loss
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
- 从配置可以看出,和 RPN 相比,除了额外的 SingleRoIExtractor 外,基本都是相同的。其训练和测试流程简要概况如下:
5.1.10.1 公共部分
-
- RPN 层输出每张图片最多 nms_post 个候选框,故 R-CNN 输入 shape 为 (batch, nms_post, 4),4 表示 RoI 坐标
-
- 利用 RoI 重映射规则,将 nms_post 个候选框映射到 FPN 输出的不同特征图上,提取对应的特征图,然后利用插值思想将其变成指定的固定大小输出,输出 shape 为 (batch, nms_post, 256, roi_feat_size, roi_feat_size),其中 256 是 FPN层输出特征图通道大小,roi_feat_size 一般取 7。上述步骤即为 RoIAlign 或者 RoIPool 计算过程
-
- 将 (batch, nms_post, 256, roi_feat_size, roi_feat_size) 数据拉伸为 (batch*nms_post, 256*roi_feat_size*roi_feat_size),转化为 FC 可以支持的格式, 然后应用两次共享卷积,输出 shape 为 (batch*nms_post, 1024)
-
- 将 (batch*nms_post, 1024) 分成分类和回归分支,分类分支输出 (batch*nms_post, num_classes+1), 回归分支输出 (batch*nms_post, 4*num_class)
-
第2步的映射规则是在 FPN 论文中提出。假设某个 proposal 是由第 4 个 特征图层检测出来的,为啥该 proposal 不是直接去对应特征图层切割就行,还需要重新映射?原因是这些 proposal 是 RPN 测试阶段检测出来的,大部分 proposal 可能符合前面设定,但是也有很多不符合的,也就是说测试阶段上述一致性不一定满足,需要重新映射,公式如下:
k = ⌊ k 0 + l o g 2 ( w h / 224 ) ⌋ k=\lfloor k_0 + log_2(\sqrt{wh}/224)\rfloor k=⌊k0+log2(wh/224)⌋- 上述公式中 k 0 = 4 k_0=4 k0=4,通过公式可以算出 k,具体是:
- wh>=448x448,则分配给 p5
- wh<448x448 并且 wh>=224x224,则分配给 p4
- wh<224x224 并且 wh>=112x112,则分配给 p3
- 其余分配给 p2
- 在 R-CNN 部分没有采用感受野最大的 p6 层。
def map_roi_levels(self, rois, num_levels):
"""Map rois to corresponding feature levels by scales.
- scale < finest_scale * 2: level 0
- finest_scale * 2 <= scale < finest_scale * 4: level 1
- finest_scale * 4 <= scale < finest_scale * 8: level 2
- scale >= finest_scale * 8: level 3
"""
scale = torch.sqrt(
(rois[:, 3] - rois[:, 1]) * (rois[:, 4] - rois[:, 2]))
target_lvls = torch.floor(torch.log2(scale / self.finest_scale + 1e-6))
target_lvls = target_lvls.clamp(min=0, max=num_levels - 1).long()
return target_lvls
- 其中 finest_scale=56,num_level=5。
- 在基于候选框提取出对应的特征图后,再利用 RoIAlign 或者 RoIPool 进行统一输出大小,其计算过程在 Mask R-CNN 部分分析。
- 经过 RoIAlign 或者 RoIPool 后,所有候选框特征图的 shape 为 (batch, nms_post, 256, roi_feat_size, roi_feat_size),将其拉伸后输入到 R-CNN 的 Head 模块中,具体来说主要是包括两层分类和回归共享全连接层 FC,最后是各自的输出头,其 forward 逻辑如下:
if self.num_shared_fcs > 0:
x = x.flatten(1)
# 两层共享 FC
for fc in self.shared_fcs:
x = self.relu(fc(x))
x_cls = x
x_reg = x
# 不共享的分类和回归分支输出
cls_score = self.fc_cls(x_cls) if self.with_cls else None
bbox_pred = self.fc_reg(x_reg) if self.with_reg else None
return cls_score, bbox_pred
- 最终输出分类和回归预测结果。相比于目前主流的全卷积模型,Faster R-CNN 的 R-CNN 模块依然采用的是全连接模式。
5.1.10.2 训练逻辑
rcnn=dict(
assigner=dict(
# 和 RPN 一样,正负样本定义参数不同
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
# 和 RPN 一样,随机采样参数不同
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
# True,RPN 中为 False
add_gt_as_proposals=True)
- 理论上,BBox Assigner 和 BBox Sampler 逻辑可以放置在公共部分的前面,因为其任务是输入每张图片的 nms_post 个候选框以及标注的 gt bbox 信息,然后计算每个候选框样本的正负样本属性,最后再进行随机采样尽量保证样本平衡。
- R-CNN的候选框对应了 RPN 阶段的 anchor,只不过 RPN 中的 anchor 是预设密集的,而 R-CNN 面对的 anchor 是动态稀疏的,RPN 阶段基于 anchor 进行分类回归对应于 R-CNN 阶段基于候选框进行分类回归,思想是完全一致的,故 Faster R-CNN 类算法叫做 two-stage,因此可以简化为 one-stage + RoI 区域特征提取 + one-stage。
- 实际上为了方便理解,BBox Assigner 和 BBox Sampler 逻辑是在 公共部分的步骤 1后运行的。需要特别注意的是配置参数和 RPN 不同:
- match_low_quality=False。为了避免出现低质量匹配情况(因为 two-stage 算法性能核心在于 R-CNN,RPN 主要保证高召回率,R-CNN 保证高精度),R-CNN 阶段禁用了允许低质量匹配设置
- 3 个 iou_thr 设置都是 0.5,不存在忽略样本,这个参数在 Cascade R-CNN 论文中有详细说明,影响较大
- add_gt_as_proposals=True。主要是克服刚开始 R-CNN 训练不稳定情况
- R-CNN 整体训练逻辑如下:
if self.with_bbox or self.with_mask:
num_imgs = len(img_metas)
sampling_results = []
# 遍历每张图片,单独计算 BBox Assigner 和 BBox Sampler
for i in range(num_imgs):
# proposal_list 是 RPN test 输出的候选框
assign_result = self.bbox_assigner.assign(
proposal_list[i], gt_bboxes[i], gt_bboxes_ignore[i],
gt_labels[i])
# 随机采样
sampling_result = self.bbox_sampler.sample(
assign_result,
proposal_list[i],
gt_bboxes[i],
gt_labels[i],
feats=[lvl_feat[i][None] for lvl_feat in x])
sampling_results.append(sampling_result)
# 特征重映射+ RoI 区域特征提取+ 网络 forward + Loss 计算
losses = dict()
# bbox head forward and loss
if self.with_bbox:
bbox_results = self._bbox_forward_train(x, sampling_results,
gt_bboxes, gt_labels,
img_metas)
losses.update(bbox_results['loss_bbox'])
# mask head forward and loss
if self.with_mask:
mask_results = self._mask_forward_train(x, sampling_results,
bbox_results['bbox_feats'],
gt_masks, img_metas)
losses.update(mask_results['loss_mask'])
return losses
- _bbox_forward_train 逻辑和 RPN 非常类似,只不过多了额外的 RoI 区域特征提取步骤:
def _bbox_forward_train(self, x, sampling_results, gt_bboxes, gt_labels,
img_metas):
rois = bbox2roi([res.bboxes for res in sampling_results])
# 特征重映射+ RoI 特征提取+ 网络 forward
bbox_results = self._bbox_forward(x, rois)
# 计算每个样本对应的 target, bbox encoder 在内部进行
bbox_targets = self.bbox_head.get_targets(sampling_results, gt_bboxes,
gt_labels, self.train_cfg)
# 计算 loss
loss_bbox = self.bbox_head.loss(bbox_results['cls_score'],
bbox_results['bbox_pred'], rois,
*bbox_targets)
bbox_results.update(loss_bbox=loss_bbox)
return bbox_results
- _bbox_forward 逻辑是 R-CNN 的重点:
def _bbox_forward(self, x, rois):
# 特征重映射+ RoI 区域特征提取,仅仅考虑前 num_inputs 个特征图
bbox_feats = self.bbox_roi_extractor(
x[:self.bbox_roi_extractor.num_inputs], rois)
# 共享模块
if self.with_shared_head:
bbox_feats = self.shared_head(bbox_feats)
# 独立分类和回归 head
cls_score, bbox_pred = self.bbox_head(bbox_feats)
bbox_results = dict(
cls_score=cls_score, bbox_pred=bbox_pred, bbox_feats=bbox_feats)
return bbox_results
5.1.10.3 测试逻辑
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)
- 测试逻辑核心逻辑如下:
- 公共逻辑部分输出 batch * nms_post 个候选框的分类和回归预测结果
将所有预测结果按照 batch 维度进行切分,然后依据单张图片进行后处理,后处理逻辑为:先解码并还原为原图尺度;然后利用 score_thr 去除低分值预测;然后进行 NMS;最后保留最多 max_per_img 个结果
5.1.10.4 RoIPool
- RoIPool作用: 将任意大小的特征图都池化为指定输出大小。示意图如下:

- 假设左上图为输入特征图,bbox 分支预测的坐标可能是浮点数,设置 RoIPool 输出 size 是 (2,2)
- 首先将 bbox 预测值转化为整数,得到右上蓝框
- 将蓝框内 5x7 的特征图均匀切割为 2x2 的块,但是由于取整操作,实际上第一个块是 wh=(7//2,5//2),第二个块是 wh=(7-7//2,5-5//2), 后面类似,从而得到左下图示
- 然后在每个小块内采用 MaxPool 提取最大值,从而得到右下角的 2x2 输出
- 可以发现 RoIPool 存在两次取整操作,第一次是将 proposal 值变成整数,第二次是均匀切割时候。对于小物体的特征图而言,两次取整操作特征图会产生比较大的偏差,从而对 分割和定位精度有比较大的影响,在论文里作者把它总结为“未对齐问题”(mis-alignment)。
5.1.10.5 RoIAlign
- RoIAlign作用: 将任意大小的特征图都池化为指定输出大小
- 为了解决RoIPool的mis-alignment问题,RoIAlign 取消两次整数化操作,保留了小数,每个小数位置都采用双线性插值方法获得坐标为浮点数的特征图上数值, 其可视化如下所示:
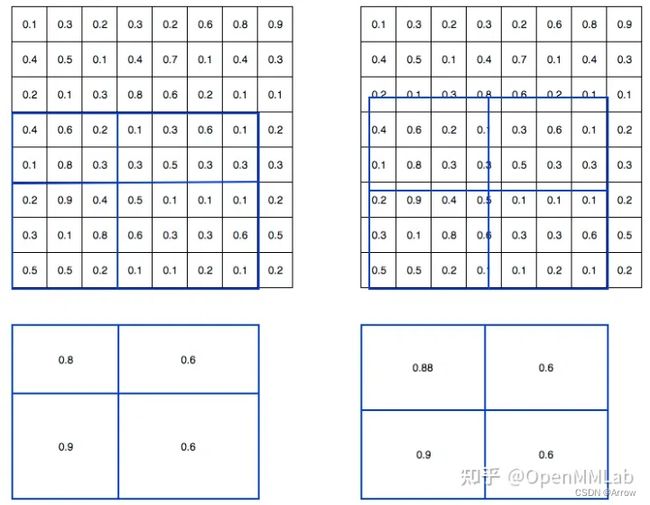
- 其对应的论文图示如下:

- 假设黑色大框是要切割的 bbox,打算输出 size 为 2x2 输出,则先把黑色大 bbox 均匀切割为 4 个小 bbox,然后在每个小 bbox 内部均匀采样 4 个点(相当于每个小 bbox 内部再次均匀切割为 2x2 共 4 个小块,取每个小块的中心点即可),首先对每个采样点利用双线性插值函数得到该浮点值处的值(插值的 4 个整数点是上下左右最近的 4 个点),然后对 4 个采样点采样值取 max 操作得到该小 bbox 的最终值。采样个数 4 是超参,实验发现设置为 4 的时候速度和精度都是最合适的。
5.1.11 NMS
-
NMS:Non-Maximum Suppression (非极大值抑制)
-
思想:搜素局部最大值,抑制非极大值。
-
用途:消除多余的框,找到最佳的物体检测位置。
- NMS算法在不同应用中的具体实现不太一样,但思想是一样的。非极大值抑制,在计算机视觉任务中得到了广泛的应用,例如边缘检测、人脸检测、目标检测(DPM,YOLO,SSD,Faster R-CNN)等。
- 目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。

-
左图是人脸检测的候选框结果,每个边界框有一个置信度得分(confidence score),如果不使用非极大值抑制,就会有多个候选框出现。右图是使用非极大值抑制之后的结果,符合我们人脸检测的预期结果。
-
NMS输入
- 目标边界框列表及其对应的置信度得分列表,设定阈值,阈值用来删除重叠较大的边界框。
- IoU:Intersection-Over-Union,即两个边界框的交集部分除以它们的并集。
-
NMS工作流程
- 根据置信度得分进行排序
- 选择置信度最高的边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空
5.2 FCOS (Anchor-Free)
- FCOS: Fully Convolutional One-Stage Object Detection
- FCOS 成为Anchor-Free典型代表的原因
- 沿用了主流网络结构 RetinaNet,使其具备公平对比的特性,在几乎没有修改情况下,性能可以超越 RetinaNet
- 性能优异,在增加额外 trick 后性能有大幅提升,这些 trick 也启发了后面很多算法
- 足够简单,训练和测试 pipeline 非常清晰,容易理解
- 原理:FCOS为全卷积网络,对输出特征图上的每一个点都进行分类和回归预测,等价于 anchor 个数为 1 且形状为正方形 anchor-based 类算法
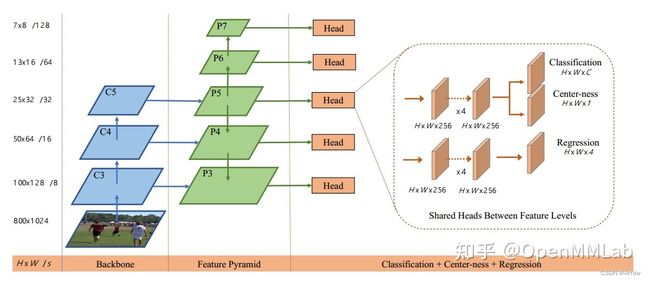
5.2.1 Backbone
- 所有配置文件中字段含义:
- r50、r101 表示 ResNet 网络,x101 表示 ResNeXt 网络
- gn-head 表示头部卷积采用的是 GN,而不是 BN
- 4x4 表示训练时候每个 GPU 的 batch 为 4,并且 num_worker 为 4
- 640-800 是多尺度训练时图片短边的范围
- mstrain 表示多尺度训练
- 1x 和 2x 分别代表 12 和 24 个 epoch
- Caffe 和 PyTorch 是指 Bottleneck 模块的区别,省略情况下表示是 PyTorch
- D 是可变形卷积
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='caffe'),
- FCOS 采用 Caffe 模式 RetinaNet 默认是 PyTorch 模式。至于 Caffe 和 PyTorch 具体区别见 RetinaNet 解读文章。需要特别注意:当切换 style=‘caffe’ 时,图片均值和方差也改变了
# pytorch
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True
# caffe
mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False
- 骨架训练策略有区别 一般在 Caffe 模式下,requires_grad=False,也就是说 ResNet 的所有 BN 层参数都不更新并且全局均值和方差也不再改变,而在 PyTorch 模式下,除了 frozen_stages 的 BN 参数不更新外,其余层 BN 参数还是会更新的。
5.2.2 Neck
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs=True,
extra_convs_on_inputs=False, # use P5
num_outs=5,
relu_before_extra_convs=True),
- 和 RetinaNet 相比,FCOS 的 FPN 层抽取层是不一样的,RetinaNet 采用 C5 层特征图进行下采样得到 P6 和 P7,而 FCOS 是从 P5 抽取得到, 并且 relu_before_extra_convs=True,也就是 P6 和 P7 进行卷积前,还会经过 ReLu 操作,RetinaNet 的 C5 后不需要经过 ReLu 是因为 ResNet 输出最后是 ReLu层。
5.2.3 Head
- 相比 RetinaNet 头部网络结构,主要有两个区别:
- 额外多了 centerness 分支,后面再分析该分支作用
- 4 个卷积层不是采用 BN,而是 GN,实验表明在 FCOS 中,GN 效果远远好于 BN
- 注意:FCOS 作者开源了好几个版本,其中后续版本通过各种实验验证了一些 trick,主要是:
- norm_on_bbox 即 bbox 分支输出值是否经过 relu 处理
- centerness_on_reg 即 centerness 分支是否和 reg 分支共享权重,图一示意图为 centerness_on_reg=False
- center_sampling 即是否开启中心采样策略
加入 trick 后性能有大幅提升,但是不会对推理有任何速度影响,故本文解读的都是加入 trick 的版本。
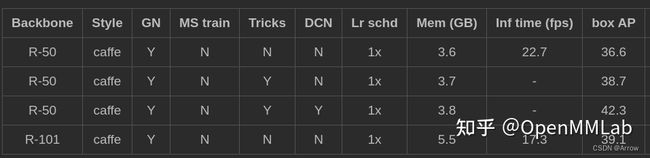
- FCOS Head 模块单个输出层 forward 流程如下:
# 4 层卷积 forward
cls_score, bbox_pred, cls_feat, reg_feat = super().forward_single(x)
if self.centerness_on_reg: # trick
# 将 centerness 分支放到 bbox 分支上
centerness = self.conv_centerness(reg_feat)
else:
centerness = self.conv_centerness(cls_feat)
# scale the bbox_pred of different level
# float to avoid overflow when enabling FP16
# 可学习 scale
bbox_pred = scale(bbox_pred).float()
if self.norm_on_bbox: # trick
# 因为输出值一定是正数,故直接用 relu 进行截取
bbox_pred = F.relu(bbox_pred)
if not self.training:
bbox_pred *= stride # bbox 输出解码过程
else:
# 早期做法
bbox_pred = bbox_pred.exp()
return cls_score, bbox_pred, centerness
- conv_centerness 分支输出通道是 1,分类分支输出通道是 num_class,检测分支输出通道是 4。
5.2.4 Bbox Assigner
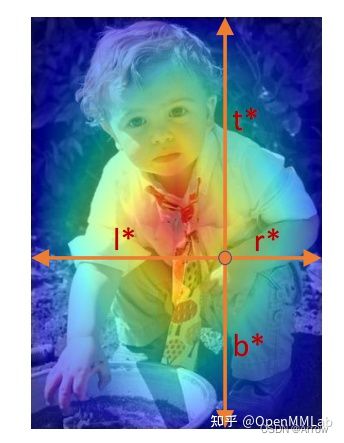
- 为了说明 Bbox Assigner,需要先说明 FCOS 网络输出格式。

- 其输出格式是:对于特征图位置上任何一点都回归其距离 Bbox 4 条边的距离,如上图所示
l = ( x − x 0 ) / s t = ( y − y 0 ) / s r = ( x 1 − x ) / s b = ( y 1 − y ) / s l = (x-x_0)/s \\ t = (y-y_0)/s \\ r = (x_1 - x)/s \\ b = (y_1 - y)/s \\ l=(x−x0)/st=(y−y0)/sr=(x1−x)/sb=(y1−y)/s - 假设 ( x , y ) (x,y) (x,y) 是原图上某点坐标, ( x 0 , y 0 , x 1 . y 1 ) (x_0, y_0, x_1. y_1) (x0,y0,x1.y1)是某个 gt bbox 在原图上的坐标, s s s 是总下采样倍数 stride,那么 ( x , y ) (x,y) (x,y) 点距离 4 条边的边界公式如上所示。为了平衡分类和回归 loss,网络输出输出形式和上述公式之间存在一个映射关系即 BBox Encoder Decoder 过程,在后面小节会描述。
- FCOS 的 BBox Assigner 过程是通过 regress_ranges 和 center_sample_radius 两个参数控制。和大部分算法的 BBox Assigner 类似,由于带有多尺度预测,故需要解决两个问题:
-
- 按照 scale 将不同大小的 gt bbox 分配给不同的 FPN 层进行预测,FCOS 是通过 regress_ranges 控制(用于选择用哪一层特征图)
-
- 在某个特定预测层,哪些位置负责预测该 gt bbox,FCOS 是通过 center_sample_radius 控制 (用于计算正样本区域)
-
- 默认值 regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),(512, INF),center_sample_radius=1.5
- 简单来说其分配过程如下所示:
- 对于任何一个gt bbox,首先映射到每一个输出层,利用 center_sampling_ratio 值计算出该 gt bbox 在每一层的正样本区域以及对应的 left/top/right/bottom 的 target
- 对于每个输出层的正样本区域,遍历每个 point 位置,计算其 max(left/top/right/bottom 的 target) 值是否在指定范围内,不在范围内的认为是背景样本
- 计算过程:
-
- 计算 5 个输出层特征图所对应原图尺度上每个点的坐标。具体来说是先在特征图尺度计算所有坐标点,然后通过 stride 转化为原图尺度
-
- 所有坐标组成矩阵,然后遍历每张图片,对单张图片单独计算正负样本。
- 3. 计算原图上坐标点和当前图片所有 gt bbox 4 条边的距离
- 假设一共 5 个输出特征图,经过第二步一共有 10000 个坐标点,当前图片一共有 8 个 gt bbox,那么本步骤是将这 10000 个坐标点分别和 8 个 gt bbox 计算距离其 4 条边的距离,可以得到距离矩阵 shape 为 (10000,8,4)。
-
- 基于 center_sampling 确定 gt bbox 自身所对应的内部有效区域
- 暂时不考虑 regress_ranges 参数。如果不开启中心采样,那么 gt bbox 内部的所有点都属于正样本,一旦开启了中心采样,则需要依据采样半径计算出每个 gt bbox 内部哪些点属于正样本。
-
- 基于 regress_ranges 确定最终正样本
- 第 4 步没有考虑 FPN 的按照 scale 分配样本的特性,而是将所有 gt bbox 都广播到每个输出层,然后每个层单独基于中心采样策略计算潜在的正样本点,而本步骤通过 regree_ranges 进一步按照 scale 原则进行区分。
- 可以发现,regress_ranges 核心限制规则是点距 gt bbox 4 条边的最大值处于预算范围内才算正样本。这种规则会导致某些 gt bbox 会在多个输出层上都进行预测,而不是强制某个 gt bbox 必须只能在某个层预测,会产生更多高质量的正样本。
-
5.2.5 BBox Encoder Decoder
- 编码:FCOS 的输出编解码规则非常简单,在训练时候输出的 4 个值代表距 4 条边的距离 ( l , t , r , b ) (l, t, r, b) (l,t,r,b),注意其值不是原图范围值,而是除以 stride 后的值。
- 解码:相应的解码过程只需要乘上各自输出层的 stride 即可。
5.2.6 Loss
- FCOS 一共有 5 个输出层,每个输出层 3 个分支,分别是分类分支、Bbox 回归分支和 centerness 预测分支。
5.2.6.1 分类分支
- 分类分支采用的是 FocalLoss
num_pos = torch.tensor(
len(pos_inds), dtype=torch.float, device=bbox_preds[0].device)
num_pos = max(reduce_mean(num_pos), 1.0)
loss_cls = self.loss_cls(
flatten_cls_scores, flatten_labels, avg_factor=num_pos)
- 相比于常规 FocalLoss,其 avg_factor 不是所有样本数,而是每张卡上正样本个数的平均值,个人猜测是为了和其余分支 loss 进行平衡。
5.2.6.2 Bbox 回归分支
- Bbox 回归分支仅仅需要考虑正样本,其采用 IoULoss 或者 GIoULoss
centerness_denorm = max(
reduce_mean(pos_centerness_targets.sum().detach()), 1e-6)
loss_bbox = self.loss_bbox(
pos_decoded_bbox_preds,
pos_decoded_target_preds,
weight=pos_centerness_targets,
avg_factor=centerness_denorm)
- 为了加强和 centerness 分支的输出一致性即越可能是正样本,其权重越大,作者将每个样本权重设置为 centerness 分支的 target,并且 avg_factor 设置为 centerness 正样本 target 的总和。
5.2.6.3 CenterNess 分支
- 在不引入 centerness 分支情况下,作者发现推理时候在 gt bbox 附近会预测出一些低质量的 bbox,原因是训练时候对于回归分支,正样本区域的权重是一样的,导致那些虽然是正样本但是离 gt bbox 中心比较远的点对最终 loss 产生了比较大的影响,这看起来不太合理。 作者解决办法是引入额外的 centerness 分类分支,该分支的 target 是离 gt Bbox 中心点越近,该值越大,范围是 0-1。虽然这是一个回归问题,但是作者采用的依然是 bce loss,并且 centerness 分支也仅仅对正样本点进行训练。
- 其 target 生成公式为:
c e n t e r n e s s ∗ = m i n ( l ∗ , r ∗ ) m a x ( l ∗ , r ∗ ) × m i n ( t ∗ , b ∗ ) m a x ( t ∗ , b ∗ ) centerness^* = \sqrt {\frac{min(l^*, r^*)}{max(l^*, r^*)} \times \frac{min(t^*, b^*)}{max(t^*, b^*)}} centerness∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗) - 效果如下所示:
- 越靠近 gt bbox 中心点,其 target 越接近 1,对应代码为:
def centerness_target(self, pos_bbox_targets):
# only calculate pos centerness targets, otherwise there may be nan
left_right = pos_bbox_targets[:, [0, 2]]
top_bottom = pos_bbox_targets[:, [1, 3]]
centerness_targets = (
left_right.min(dim=-1)[0] / left_right.max(dim=-1)[0]) * (
top_bottom.min(dim=-1)[0] / top_bottom.max(dim=-1)[0])
return torch.sqrt(centerness_targets)
# loss 计算
loss_centerness = self.loss_centerness(
pos_centerness, pos_centerness_targets, avg_factor=num_pos)
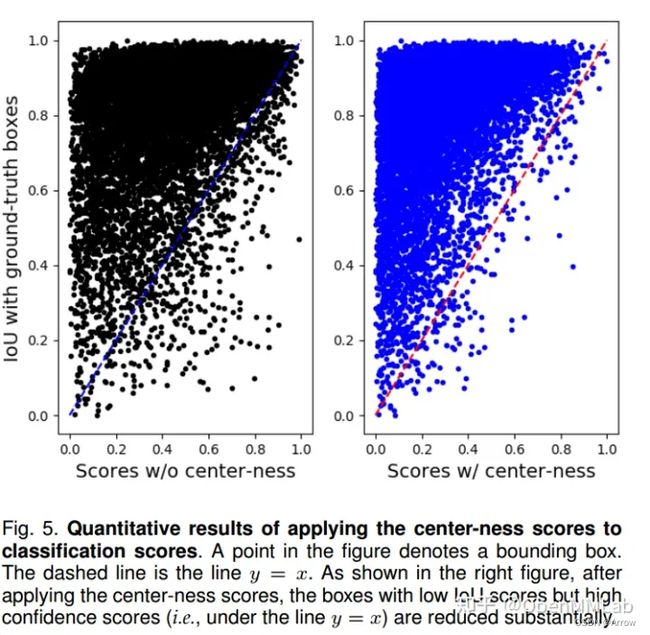
- 从上图可以看出,将该预测值和分类分支结果相乘得到横坐标分支图,纵坐标是 Bbox 和 gt Bbox 的 IoU,在引入 centerness 分支后,可以明显发现两者的一致性得到了提高,对最终性能有很大影响。后续很多 anchor-free 方向的算法改进对于 centerness 分支的作用和改进有比较深入的研究,同时大家也逐渐意识到分类预测值和 Bbox 预测质量之间的不一致性是影响性能很大的一个重要因素。
5.2.7 总结
- FCOS 是一个优异且应用广泛的 anchor-free 算法,其最大优点是不需要基于数据集重新设置 anchor 参数,并且整个算法 pipeline 简单而清晰,容易理解。但其也存在不足,例如有两个需要结合数据集而设置的重要超参 regress_ranges 和 center_sampling,在 ATSS 算法中有对应的改进,在后续分析中会详细说明。
5.3 ATSS
- ATSS目的:FCOS 一文中详细说明了主流的 anchor-free 算法 FCOS,文章最后也提到了其存在两个需要结合数据集定制的超参,特别是 regress_range,而 ATSS 算法基于 FCOS 对其 Bbox Assigner 规则进行改进,提出了自适应分配机制,正样本分配机制更加灵活,虽然依然存在一个超参 topk,但是论文中通过实验验证了该超参的鲁棒性。
- ATSS 算法来自 Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection 论文,总的来说有两个创新点:
- 深入对比分析了 anchor-based 和 anchor-free 性能差异根本原因
- 提出了自适应 Bbox Assigner 算法,该规则可以适用于 anchor-based 和 anchor-free 算法,超参鲁棒,效果蛮好
5.3.1 RetinaNet 和 FCOS 深入对比分析
-
为了引出后续自适应正负样本分配策略的重要性,作者首先对两大主流算法进行深入公平对比分析,希望能找到性能差异的根本原因。
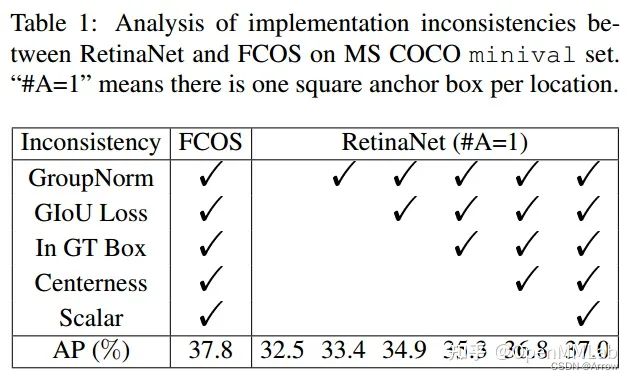
-
因为 FCOS 算法性能优于 RetinaNet,并且其额外引入了许多 trick,为了公平对比,将 FCOS 所提 trick 也迁移到 RetinaNet 中,并且设置 RetinaNet 的 anchor 个数为 1,结果如上所示。可以看出即使所有 trick 都加上 RetinaNet 依然差了 0.8 mAP,说明上面这些 trick 不是根本原因。
-
排除上述 trick 因素后,两个算法的区别是:
- Bbox Assigner
- Bbox Encoder Decoder。FCOS 回归编码规则是预测每个点距 4 条边的距离 (Point 模式 ( l , t , r , b ) (l, t, r, b) (l,t,r,b)),而 RetinaNet 是基于预设 anchor 进行变换回归 (Bbox 模式 ( Δ x , Δ y , Δ w , Δ h ) (\Delta x, \Delta y, \Delta w, \Delta h) (Δx,Δy,Δw,Δh))
-
下图可以清晰看出差别:

-
实验结果如下所示:

- 行方向看,不管是采用 Point 还是 Box 模式,mAP 都是非常接近的,说明Bbox Encoder Decoder 影响很小
- 列方向看,Bbox Assigner 不同会带来极大的性能差异,其中 IoU 是指 RetinaNet 中分配规则,Spatial and Scale Constraint 是 FCOS 中分配规则
-
从上述对比可以看出:anchor-based 和 anchor-free 的性能差异根本在于正负样本定义(即Bbox Assigner)。具体区别可从下图看出:

-
对于 PL1 和 PL2 两个输出层,RetinaNet 直接采用全局统一的 IoU 阈值进行分配,可以确定上图蓝色 1 位置是正样本,而 FCOS 会分成两个步骤进行分配,第一步通过中心采样阈值计算后续正样本,第二步通过回归 scale 范围计算最终正样本,可以确定上图有两个蓝色 1 位置都是正样本,也就是说相比 RetinaNet 算法会产生更多的正样本。
-
基于上述结论可以知道 FCOS 这种分配机制还是不错的,但是其依然存在超参难以设置问题,故 ATSS 算法的核心就在于提出一个自适应的 Bbox Assigner 算法。为了条理清晰,我们依然按照前面 Backbone、Neck 和 Head 等顺序进行解读。
5.3.2 Backbone、Neck 和 Head
- 前面说过相比 RetinaNet 或者 FCOS,除去 trick,核心的是分配机制,故 ATSS 算法虽然在 Backbone、Neck 和 Head 设置方面和前两个算法有些区别,但是不要紧。
# backbone 部分和 RetinaNet 完全相同
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
# neck 部分,add_extra_convs 参数不同,其余完全相同
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_output',
num_outs=5),
# head 部分和 FCOS 相同,也是加入了额外的 centerness 分支
bbox_head=dict(
type='ATSSHead',
num_classes=80,
in_channels=256,
stacked_convs=4,
feat_channels=256),
- 结合代码,和 RetinaNet 对比,其不同在于:
- neck 部分采用 P5 生成 stride 更大的特征图,而 RetinaNet 采用 C5
- 参考 FCOS,额外加入了 centerness 分支,同时 Head 部分也是采用 GN,而不是 BN
5.3.3 Bbox Assigner
-
这部分是 ATSS 核心:其基本思路是通过某种手段给输出特征图上每个点计算其适应度值,值越大表示越适合作为正样本;然后计算所有适应度值的统计值得到全局阈值(这就是要找的自适应阈值);最后高于阈值才是正样本,其余都是负样本,从而实现自适应分配的目的。
-
其简要流程为:(根据L2距离找topk个anchor点,根据IoU的均值和标准差计算自适应阈值)
- 计算每个 gt bbox 和多尺度输出层的所有 anchor 之间的 IoU
- 计算每个 gt bbox 中心坐标和多尺度输出层的所有 anchor 中心坐标的 L2 距离
- 遍历每个输出层,遍历每个 gt bbox,找出当前层中 topk (超参,默认是 9 )个最小 L2 距离的 anchor 。假设一共有 l 个输出层,那么对于任何一个 gt bbox,都会挑选出 topk×l 个候选位置
- 对于每个 gt bbox,计算所有候选位置 IoU 的均值和标准差,两者相加得到该 gt bbox 的自适应阈值
- 遍历每个 gt bbox,选择出候选位置中 IoU 大于阈值的位置,该位置认为是正样本,负责预测该 gt bbox
- 如果 topk 参数设置过大,可能会导致某些正样本位置不在 gt bbox 内部,故需要过滤掉这部分正样本,设置为背景样本
-
某种手段是指计算每个 gt bbox 和所有 anchor 之间的 IoU topk 操作;每个 gt bbox 和 anchor 计算得到的 IoU 值即为适应度值,值越大越可能是正样本;计算 gt bbox 和候选 anchor 的 IoU 均值和标准差即为对适应度值计算统计值得到全局阈值;然后采用每个 gt bbox 各自的全局预测进行切分即可得到正样本。
-
举个例子简要概述:假设当前图片中,一共 2 个 gt bbox,一共 5 个输出层,每层都是 100 个 anchor
- 遍历每个 gt bbox,和 500 个 anchor 都计算 IoU 和中心坐标的 L2 距离值
- 遍历 5 个输出层,对于每个 gt bbox,都选择 topk=9 个 L2 距离最小的 anchor,此步骤完成后每个 gt bbox,一共挑选出 9x5=45 个候选 anchor
- 遍历每个 gt bbox,将挑选出来的 45 个 anchor 所对应的 IoU 计算均值和标准差,然后相加,此时 2 个 gt bbox,都可以得到各自的全局预测
- 最后遍历每个 gt bbox,在候选 anchor 中将 IoU 值低于阈值的 anchor 设置为负样本,其余为正样本
-
其能够实现自适应的原因是:
- 均值:代表了 anchor 对 gt bbox 的正样本概率适应度值,其值越高,代表候选样本质量普遍越高
- 标准差:代表哪些输出层适合预测该 gt bbox,标准差越大越能区分层和层之间的 anchor 质量差异。
- 均值和标准差相加:就能够很好的反应出哪些层的哪些 anchor 适合作为正样本。一个好的 anchor 设计,应该是满足高均值、高标准差的设定。
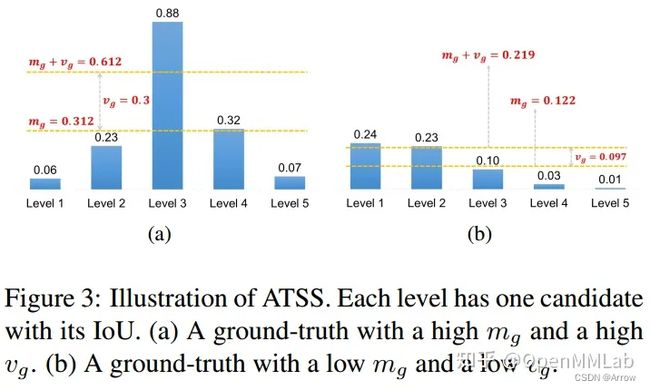
- 如上图所示,(a) 的阈值计算出来是 0.612,采用该阈值就可以得到 level3 上才有正样本,是高均值高方差的。同样的如果预设 anchor 设置和 gt bbox 不太匹配,(b) 计算出来的阈值为 0.219,依然可以选择出合适的正样本区域,虽然其属于低均值、低方差的。
-
需要特别强调:ATSS 自定义分配策略可以用于 anchor-free,也可以用于 anchor-based,当用于 anchor-free 后,其 anchor 设置仅仅用于计算特征图上面点的正负样本属性,不会参与后续任何计算,而且由于其自适应策略,anchor 的设置不当影响没有 anchor-based 类算法大。其 anchor 设置为:
anchor_generator=dict(
type='AnchorGenerator',
ratios=[1.0],
octave_base_scale=8,
scales_per_octave=1,
strides=[8, 16, 32, 64, 128]),
- 自适应分配策略配置如下:
train_cfg=dict(
assigner=dict(type='ATSSAssigner', topk=9),
allowed_border=-1,
pos_weight=-1,
debug=False),
5.3.4 Loss
- 前面说过,ATSS 算法可以用于 anchor-based 类算法例如 RetinaNet,也可以用于 anchor-free 类算法例如 FCOS,在 MMDetection 复现中是基于 anchor-based 中 RetinaNet 为例的。既然是 RetinaNet,那么其 Bbox Encoder Decoder 则是以 anchor 为基准,输出是 gt bbox 和 anchor 的变换值。其完整配置如下:
bbox_head=dict(
type='ATSSHead',
num_classes=80,
in_channels=256,
stacked_convs=4,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
ratios=[1.0],
octave_base_scale=8,
scales_per_octave=1,
strides=[8, 16, 32, 64, 128]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=2.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
- 其 Loss 计算过程和 FCOS 完全相同。
5.3.5 总结
- 本文重点分析了 ATSS 算法(理解本文请联合 FCOS 算法解读一起阅读),其最大贡献是提出一个可适用于 anchor-based 和 anchor-free 的自适应 Bbox 正负样本分配算法,将超参变成了只有一个 topk,且实验表明该参数非常鲁棒。
参考:
- https://mmdetection.readthedocs.io/zh_CN/stable/article.html
- https://zhuanlan.zhihu.com/p/349807581