知识图谱之命名实体识别
本片博文我将讲解两个部分,第一部分讲命名实体识别的发展史,这中间会涉及到整个技术的成熟历程,第二部分讲主流的命名实体识别技术的实现细节。
概述
命名实体识别是自然语言处理中的基础任务之一,其目标是提取文本中特定的实体并对其进行分类,最常见的实体比如:人名、地名、组织机构名,在推荐、搜索、信息检索、智能问答等领域有着广泛的应用。命名实体识别在识别实体的时候需要找出实体的具体位置,这就需要对实体进行标注,常见的标注体系有:IO、BIO、BMEWO等,以BIO为例:
- B:Beginning of NE( tag;
- I:Inside of NE(I-) tag;
- O:Outside of NE(O-) tag;
训练数据的输入有两种形式,第一种是标注结果直接给在词的后面(词1/tag1,词2/tag2),第二种是将语料和标注结果分开,放在不同的文件夹。
NER的技术发展趋势
今年来,ner的技术发展趋势如下图所示,早期主要是基于规则和构建词典的方式构建NER系统,2000年之后CRF等概率图模型等到了广泛的应用,在之后,深度学习的兴起,BI-LSTM+CRF一度成为了研究的热点。
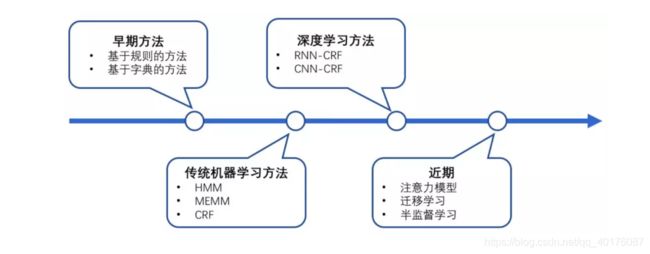
在此之后,很多的研究方法都是在BI-LSTM+CRF的基础上进行修改,LSTM和CRF都需要合并上下文中的序列信息,注意力机制Attention计算上下文中不同对象的权重,这成为了很有用的技巧。但是深度学习一般需要大量标注的学习语料,才能学习出比较好的效果。在工业生产中往往会出现标记数据过少的情况,迁移学习和远程监督学习在一定程度能解决这个问题。总结起来如下:
1.基于规则和字典:
- 基本流程;
- 词典和规则的构建;
- 规则的自动生成和维护;;
2.基于机器学习方法:
- 无监督:自动生成规则和关键词,学习模式;
- 有监督:CRF和BI-LSTM-CRF为代表,需要大量标注语料;
- 半监督:预训练+BI-LSTM-CRF+特征融合;
深度学习NER模型都处于BI-LSTM-CRF的框架之下,不同之处在于编码的学习,词编码、字符编码、句子编码等,然后就是模型设计上的技巧和规律被发现和解释。下面详细讲解BI-LSTM-CRF技术细节。
BI-LSTM-CRF框架
BI-LSTM-CRF在命名实体识别中发挥着不可替代的作用,下面就专门讲解其中的细节,好,正式开始一本正经的胡说八道。
数据
现在我们有一个数据集,为了简单起见,这个数据集假设只涉及到两类实体,分别是人名和地名,并且采用BIO的数据标记模式,那么这样一来,标签类别就有只有以下五种:
- B-Person:人名的开始部分;
- I-Person:人名的中间部分;
- B-Location:地名的开始部分;
- I-Location:地名的中间部分;
- O:非实体部分;
假设现在我们有一句话,这句话只有5个单词的长度,记为:(w1,w2,w3,w4,w5),其中,【w1,w2】是人名,【w4,w5】是地名,其他都是“O”。
模型
BI-LSTM-CRF模型的结构如下图所示, 首先是NLP中老生常谈的步骤,Embedding过程,这里的词向量过程在不同的业务场景中有不同的方法,可以是词向量、字符向量、句子向量,或者其他的特征向量融合,这里不再展开。词向量可以是预训练的,比如word2vec、Elmo等,也可以开始随机初始化,然后在训练过程fine_tuning。图中输入到BI-LSTM层的每一个 w i w_i wi,都是一个经过Embedding之后的指定维度的向量。
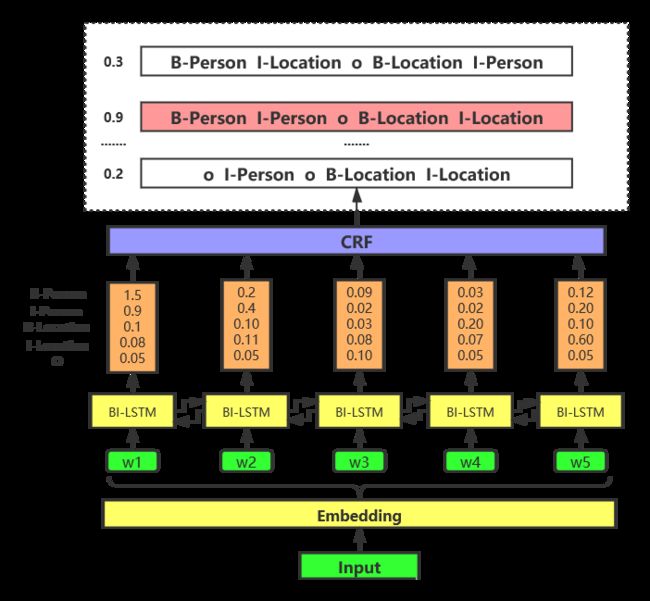
每一个词向量输入到BI-LSTM层,经过前向后向的计算之后,每个BI-LSTM单元都会输出一个分数列表,这个分数列表的长度等于标签的种类数。这个分数列表表示该位置对应的单词属于不同类标签的概率大小,分数值越大,说明该位置对应的单词越有可能属于这个标签类别。
然后,每一个BI-LSTM层的输出作为CRF层的输入,经过CRF层的计算,最终会输出一个标记序列的列表,每一个标记序列都会对应一个概率值,概率值最大的标记序列即为该模型最终预测的结果。
为啥要加CRF层,没有CRF层会怎么样?
如果没有CRF层,那问题真的变成了纯粹的单词分类问题了,如下图所示,直接从BI-LSTM层的输出分数列表中取出分数值最大对应的标签类别即可,非得整什么幺蛾子(CRF层)。

如上图所示,去掉CRF层,直接从BI-LSTM的输出中取分数值最高对应的标签类别,作为预测结果,貌似也能得出正确的结果,那是否就可以断定,这个CRF层是多余的了呢。不急,这只是个例,再看下面结果。
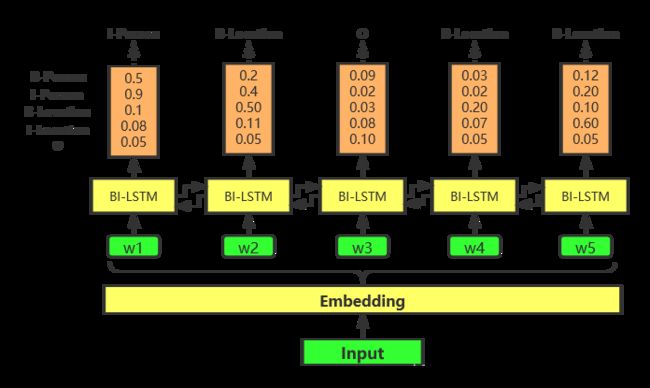
上图中的结果就明显不对,所以不加CRF层,少数情况下能得到正确的预测结果,但是我们也不能心存侥幸啊。加上CRF层主要目的在于加入一些约束条件,来保证最终的预测结果是有效的,这些约束可以在训练数据时被CRF层自动学习得到。在我们这个场景下,可以学习到的约束条件有:
- 句子开头要么是O,要么是B-,其他的肯定不对;
- “B-label1 I-label2 I-label3…”这种模型的序列,label1、label2、label3一定是同一种实体,否则就不对;
- 实体的开头一定是B-,或者O;
有了这些有用的约束,错误的预测序列将会大大减少。那么CRF层是怎么学习到这些的限制条件的呢?其实这涉及到一个状态转移矩阵,可以这么理解:可以把这个状态转移矩阵看成是BI-LSTM-CRF的一个参数矩阵,在模型训练之前,类似于词向量一样,可以随机初始化这个状态转移矩阵的值,然后这些值会随着模型的训练而不断更新和优化,是一个不断学习的过程,它能自己学习到这些约束条件。
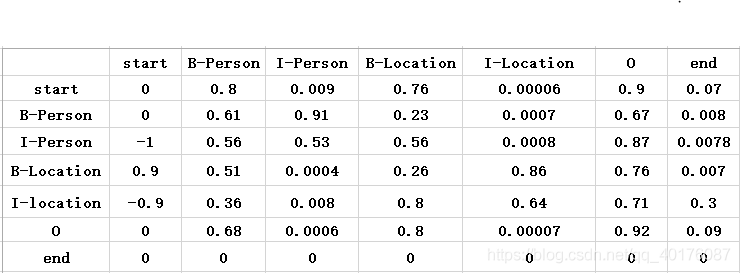
start和end分别表示序列的开始和结束的位置,从上图中可以看出,这个训练之后得到的状态转移矩阵已经学习到一些有用的约束条件了:
- 句子的开头是B或者O,start->B-,start->O的得分较高,其他的比较低;
- “O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”;
BI-LSTM-CRF参数(包括状态转移矩阵参数)如何更新的?
上文说到,CRF层的状态转移矩阵开始是随机初始化的,随着训练过程不断优化更新,最终能够学习到一些标记序列的约束条件,那么这个状态转移矩阵参数具体是如何更新的呢?下面详细讲解。
假设一个句子经过Embedding之后,每个字符向量为 ( x 1 , x 2 , . . . , x n ) (\boldsymbol x_{1},\boldsymbol x_{2},...,\boldsymbol x_{n}) (x1,x2,...,xn), 作为双向LSTM各个时间步的输入,再将正向LSTM输出的隐状态序列 ( h 1 ⟶ , h 2 ⟶ , . . . , h n ⟶ ) (\overset{\longrightarrow}{\boldsymbol h_1},\overset{\longrightarrow}{\boldsymbol h_2},...,\overset{\longrightarrow}{\boldsymbol h_n}) (h1⟶,h2⟶,...,hn⟶)与反向LSTM输出的隐状态序列 ( h 1 ⟵ , h 2 ⟵ , . . . , h n ⟵ ) (\overset{\longleftarrow}{\boldsymbol h_1},\overset{\longleftarrow}{\boldsymbol h_2},...,\overset{\longleftarrow}{\boldsymbol h_n}) (h1⟵,h2⟵,...,hn⟵)按照对应字符位置进行拼接 h t = [ h t ⟶ ; h t ⟵ ] ∈ R m \boldsymbol h_{t}=[\overset{\longrightarrow}{\boldsymbol h_t};\overset{\longleftarrow}{\boldsymbol h_t}]\in\mathbb R^{m} ht=[ht⟶;ht⟵]∈Rm,从而得到完整的隐状态序列:
( h 1 , h 2 , . . . , h n ) ∈ R n × m ({\boldsymbol h_1},{\boldsymbol h_2},...,{\boldsymbol h_n})\in\mathbb R^{n\times m} (h1,h2,...,hn)∈Rn×m
在设置dropout后,接入一个线性层,将隐状态向量从 m m m维映射到 k k k维, k k k是标注集的标签数,从而得到自动提取的句子特征,记作矩阵 P = ( p 1 , p 2 , . . . , p n ) ∈ R n × k P=({\boldsymbol p_1},{\boldsymbol p_2},...,{\boldsymbol p_n})\in\mathbb R^{n\times k} P=(p1,p2,...,pn)∈Rn×k,可以把 p i ∈ R k \boldsymbol p_i\in\mathbb R^{k} pi∈Rk的每一维 p i j p_{ij} pij都视为将字 x i x_i xi分类到第 j j j个标签的打分值,如果再对 P P P进行Softmax的话,就相当于对各个位置独立进行 k k k分类,但是这样对各个位置进行标注时无法利用已经标注过的信息,所以接下来将接入一个CRF层来进行标注。
CRF层的参数是一个 ( k + 2 ) × ( k + 2 ) (k+2)\times (k+2) (k+2)×(k+2)矩阵 A A A, A i j A_{ij} Aij表示的是从 i i i个标签转移到第 j j j个标签的转移得分,进而在为一个位置进行标注的时候可以利用此前已经标注过的标签,之所以要加2是因为要为句子首部添加一个起始状态以及为句子尾部添加一个终止状态。如果记一个长度等于句子长度的标签序列 y = ( y 1 , y 2 , . . . , y n ) y=(y_1,y_2,...,y_n) y=(y1,y2,...,yn),那么这个模型对于句子x的标签等于y的打分为:
s c o r e ( x , y ) = ∑ i = 1 n P i , y i + ∑ i = 1 n + 1 A y i − 1 , y i score(x,y)=\sum_{i=1}^{n}P_{i,y_{i}}+\sum_{i=1}^{n+1}A_{y_{i-1},y_{i}} score(x,y)=i=1∑nPi,yi+i=1∑n+1Ayi−1,yi
可以看出整个序列的打分等于各个位置的打分之和,而每个位置的打分由两部分得到,一部分是由LSTM输出的 p i \boldsymbol p_i pi决定的,另一部分则由CRF的转移矩阵 A A A决定。进而可以利用Softmax得到归一化后的概率:
P ( y ∣ x ) = exp ( s c o r e ( x , y ) ) ∑ y ′ exp ( s c o r e ( x , y ′ ) ) P(y|x)=\frac{\exp(score(x,y))}{\sum_{y'}\exp(score(x,y'))} P(y∣x)=∑y′exp(score(x,y′))exp(score(x,y))
上面的这个 P ( y ∣ x ) P(y|x) P(y∣x)概率值在某种程度上就是真实路径的分数指数值/总路径的分数指数值,真实路径的分数值肯定是所有路径中分数最高的,那么就可以构造损失函数,使得在训练过程中,BiLSTM-CRF模型的参数值将随着训练过程的迭代不断更新,使得真实路径所占的比值越来越大。那么有一个问题来了,怎么计算所有路径的得分?难道要把所有可能的路径都列出来,挨个计算每条路径的得分,再相加么?当然不是了,有更为高效的方式,类似于 前向后向算法,这是一种基于动态规划的算法,假设一个序列长度为n,i表示序列索引,那么长度为i时的序列其所有路劲总得分score(i)=score(i-1)+emission(i)+trans(i-1,i),这是一个递推式,emission(i)表示索引i位置的发射得分,trans(i-1,i)表示从i-1到i的转移得分,根据这个递推式,就可以算出最终的路径总得分,核心思想是这个,具体细节可以参考链接。
接着刚才说的,对 P ( y ∣ x ) P(y|x) P(y∣x)取负对数,模型在训练的时候通过最小化负对数似然函数,下式给出了对一个训练样本 ( x , y x ) (x,y^{x}) (x,yx)的对数似然:
log P ( y x ∣ x ) = s c o r e ( x , y x ) − log ( ∑ y ′ exp ( s c o r e ( x , y ′ ) ) ) \log P(y^{x}|x)=score(x,y^{x})-\log(\sum_{y'}\exp(score(x,y'))) logP(yx∣x)=score(x,yx)−log(y′∑exp(score(x,y′)))
利用诸如梯度下降法来求解优化损失函数,使得模型在训练过程中不断更新优化参数,逼近最优解。
以上所述,描述的是BI-LSTM-CRF 模型训练时参数更新的过程,那么如果模型训练好了,如何对一个新的句子进行预测呢?其实预测过程又叫解码过程,可以用Viterbi算法,这是一种基于动态规划的算法,这里不做展开,后续会详解。
到这里,本文就结束了,下一篇将以比赛为例,实战讲解命名实体识别。