共轭梯度法(Conjugate Gradients)(3)
最近在看ATOM,作者在线训练了一个分类器,用的方法是高斯牛顿法和共轭梯度法。看不懂,于是恶补了一波。学习这些东西并不难,只是难找到学习资料。简单地搜索了一下,许多文章都是一堆公式,这谁看得懂啊。
后来找到一篇《An Introduction to the Conjugate Gradient Method Without the Agonizing Pain》,解惑了。
为什么中文没有这么良心的资料呢?英文看着费劲,于是翻译过来搬到自己的博客,以便回顾。
由于原文比较长,一共 66 66 66 页的PDF,所以这里分成几个部分来写。
目录
共轭梯度法(Conjugate Gradients)(1)
共轭梯度法(Conjugate Gradients)(2)
共轭梯度法(Conjugate Gradients)(3)
共轭梯度法(Conjugate Gradients)(4)
共轭梯度法(Conjugate Gradients)(5)
8. The Method of Conjugate Gradients(共轭梯度法)
好的,你可能很奇怪,这篇关于 CG(Conjugate Gradients,共轭梯度)的文章为什么到现在还没有开始讲 CG。不过,现在所有材料已经就绪了。
实际上,简单来说 CG 就是共轭方向(Conjugate Directions),只不过它的搜索方向是由残差的共轭(conjugation of the residuals)来构建的。(即,通过令 u i = r ( i ) u_i = r_{(i)} ui=r(i))。
这个选择是有意义的,原因有很多。首先,残差(residuals)适用于最陡下降(Steepest Descent),所以为啥不能用于共轭方向(Conjugate Directions)呢?第二,残差有非常好的特性,它与前面所有的搜索方向都正交(垂直),见 公式(39),所以它能保证总是能产生一个新的、线性无关的搜索方向。除非残差为 0 0 0,而这种情况下问题已经求解完毕了。我们将看到,还有更好的理由来选择残差。
让我们来考虑一下这种选择的含义。由于搜索向量(search vectors)是从残差(residuals)构建来的,所以子空间(subspace span) { r ( 0 ) , r ( 1 ) , … , r ( i − 1 ) } \{r_{(0)}, r_{(1)},\dots,r_{(i-1)} \} {r(0),r(1),…,r(i−1)} 等价于 D i \mathcal{D}_i Di。由于每个残差都和前面的搜索方向正交,那么它也和前面的残差正交。(见 图(29))。
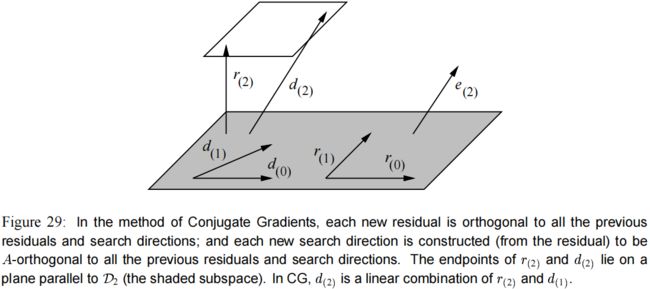
式子(41)变成: r ( i ) T r ( j ) = 0 , i ≠ j (44) r_{(i)}^T r_{(j)} = 0, \qquad i\neq j \tag{44} r(i)Tr(j)=0,i=j(44)
有趣的是,式子(43) 表明每个新的残差 r ( i ) r_{(i)} r(i) 就是先前的残差与 A d ( i − 1 ) Ad_{(i-1)} Ad(i−1) 的线性组合。
回想 d ( i − 1 ) ∈ D i d_{(i-1)}\in \mathcal{D}_i d(i−1)∈Di,这意味着每个新的子空间 D i + 1 \mathcal{D}_{i+1} Di+1 是由前一个子空间 D i \mathcal{D}_i Di 和子空间 A D i AD_i ADi 的并集构成的。
因此,
D i = span { d ( 0 ) , A d ( 0 ) , A 2 d ( 0 ) , … , A i − 1 d ( 0 ) } = span { r ( 0 ) , A r ( 0 ) , A 2 r ( 0 ) , … , A i − 1 r ( 0 ) } \begin{aligned} \mathcal{D}_i &= \text{span} \{ d_{(0)} , Ad_{(0)}, A^2d_{(0)}, \dots , A^{i-1}d_{(0)} \} \\ &= \text{span} \{ r_{(0)} , Ar_{(0)}, A^2r_{(0)}, \dots , A^{i-1}r_{(0)} \} \end{aligned} Di=span{d(0),Ad(0),A2d(0),…,Ai−1d(0)}=span{r(0),Ar(0),A2r(0),…,Ai−1r(0)}
这个子空间被称为克雷洛夫子空间(Krylov subspace),它是一种通过重复地用一个矩阵乘以一个向量而产生的子空间。他有一个让人高兴的特性:由于 A D i A\mathcal{D}_i ADi 被包含在 D i + 1 \mathcal{D}_{i+1} Di+1 里,下一个残差 r ( i + 1 ) r_{(i+1)} r(i+1) 与 D ( i + 1 ) \mathcal{D}_{(i+1)} D(i+1) 正交(式子(39))这一事实表明 r ( i + 1 ) r_{(i+1)} r(i+1) 与 D i \mathcal{D}_i Di 是 A A A-共轭的。格拉姆-施密特共轭(Gram-Schmidt conjugation)变得很容易,因为除了 d ( i ) d_{(i)} d(i) 以外, r ( i + 1 ) r_{(i+1)} r(i+1) 已经和前面所有的搜索向量都 A A A-共轭。
回顾 式子(37),格拉姆-施密特的常量为 β i j = − r i T A d ( j ) d ( j ) T A d ( j ) \beta_{ij} = - \dfrac{r_i^T A d_{(j)}}{ d_{(j)}^T A d_{(j)} } βij=−d(j)TAd(j)riTAd(j),我们来简化一下这个式子。
由 r ( i ) r_{(i)} r(i) 的内积和 式子(43),有:
r ( i ) T r ( j + 1 ) = r ( i ) T r ( j ) − α ( j ) r ( i ) T A d ( j ) α ( j ) r ( i ) T A d ( j ) = r ( i ) T r ( j ) − r ( i ) T r ( j + 1 ) r ( i ) T A d ( j ) = { 1 α ( i ) r ( i ) T r ( i ) , i = j , − 1 α ( i − 1 ) r ( i ) T r ( i ) , i = j + 1 , ( By Equation 44. ) 0 , otherwise. ∴ β i j = { 1 α ( i − 1 ) r ( i ) T r ( i ) d ( i − 1 ) T A d ( i − 1 ) , i = j + 1 , ( By Equation 37. ) 0 , i > j + 1. \begin{aligned} r_{(i)}^T r_{(j+1)} &= r_{(i)}^T r_{(j)} - \alpha_{(j)} r_{(i)}^T A d_{(j)} \\[0.5em] \alpha_{(j)} r_{(i)}^T A d_{(j)} &= r_{(i)}^T r_{(j)} - r_{(i)}^T r_{(j+1)} \\[0.5em] r_{(i)}^T A d_{(j)} &= \left\{ \begin{array}{ll} \dfrac{1}{\alpha_{(i)}} r_{(i)}^T r_{(i)}, & i=j, \\[1em] -\dfrac{1}{\alpha_{(i-1)}} r_{(i)}^T r_{(i)}, & i=j+1, \qquad (\text{By Equation 44.})\\[1em] 0, & \text{otherwise.} \end{array} \right. \\[1em] \therefore \beta_{ij} &= \left\{ \begin{array}{ll} \dfrac{1}{\alpha_{(i-1)}} \dfrac{r_{(i)}^T r_{(i)} }{ d_{(i-1)}^T A d_{(i-1)} }, & i=j+1, \qquad (\text{By Equation 37.})\\[1em] 0, & i > j+1 . \end{array} \right. \end{aligned} r(i)Tr(j+1)α(j)r(i)TAd(j)r(i)TAd(j)∴βij=r(i)Tr(j)−α(j)r(i)TAd(j)=r(i)Tr(j)−r(i)Tr(j+1)=⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧α(i)1r(i)Tr(i),−α(i−1)1r(i)Tr(i),0,i=j,i=j+1,(By Equation 44.)otherwise.=⎩⎪⎨⎪⎧α(i−1)1d(i−1)TAd(i−1)r(i)Tr(i),0,i=j+1,(By Equation 37.)i>j+1.
就像是用了魔法一样,大部分的 β i j \beta_{ij} βij 都消失了。 不再需要存储旧的搜索向量来确保和新的搜索向量 A A A-正交。这一重大进步使得 CG 成为一个如此重要的算法,因为每次迭代的空间复杂度和时间复杂度都从 O ( n 2 ) \mathcal{O}(n^2) O(n2) 下降到了 O ( m ) \mathcal{O}(m) O(m), 其中 m m m 是 A A A 的非零项的个数(where m m m is the number of nonzero entries of A A A)。后面就用缩写: β ( i ) = β i , i − 1 \beta_{(i)} = \beta_{i,i-1} β(i)=βi,i−1。
进一步简化: β ( i ) = r ( i ) T r ( i ) d ( i − 1 ) T r ( i − 1 ) ( by Equation 32 ) = r ( i ) T r ( i ) r ( i − 1 ) T r ( i − 1 ) ( by Equation 42 ) \begin{aligned} \beta_{(i)} &= \frac{ r_{(i)}^T r_{(i)} }{ d_{(i-1)}^T r_{(i-1)} } \qquad (\text{by Equation 32}) \\[1em] &= \frac{ r_{(i)}^T r_{(i)} }{ r_{(i-1)}^T r_{(i-1)} } \qquad (\text{by Equation 42}) \end{aligned} β(i)=d(i−1)Tr(i−1)r(i)Tr(i)(by Equation 32)=r(i−1)Tr(i−1)r(i)Tr(i)(by Equation 42)
拼到一起,共轭梯度法(Conjugate Gradients)就是:
d ( 0 ) = r ( 0 ) = b − A x ( 0 ) , (45) d_{(0)} = r_{(0)} = b- Ax_{(0)}, \tag{45} d(0)=r(0)=b−Ax(0),(45) α ( i ) = r ( i ) T r ( i ) d ( i ) T A d ( i ) by Equation 32 and 42 (46) \alpha_{(i)} = \dfrac{r_{(i)}^T r_{(i)} }{ d_{(i)}^T A d_{(i)} } \qquad \text{by Equation 32 and 42} \tag{46} α(i)=d(i)TAd(i)r(i)Tr(i)by Equation 32 and 42(46) x ( i + 1 ) = x ( i ) + α ( i ) d ( i ) , x_{(i+1)} = x_{(i)} + \alpha_{(i)} d_{(i)}, x(i+1)=x(i)+α(i)d(i), r ( i + 1 ) = r ( i ) − α ( i ) A d ( i ) , (47) r_{(i+1)} = r_{(i)} - \alpha_{(i)} A d_{(i)} , \tag{47} r(i+1)=r(i)−α(i)Ad(i),(47) β ( i + 1 ) = r ( i + 1 ) T r ( i + 1 ) r ( i ) T r ( i ) , (48) \beta_{(i+1)} = \dfrac{ r_{(i+1)}^T r_{(i+1)} }{ r_{(i)}^T r_{(i)} } , \tag{48} β(i+1)=r(i)Tr(i)r(i+1)Tr(i+1),(48) d ( i + 1 ) = r ( i + 1 ) + β ( i + 1 ) d ( i ) . (49) d_{(i+1)} = r_{(i+1)} + \beta_{(i+1)} d_{(i)}. \tag{49} d(i+1)=r(i+1)+β(i+1)d(i).(49)
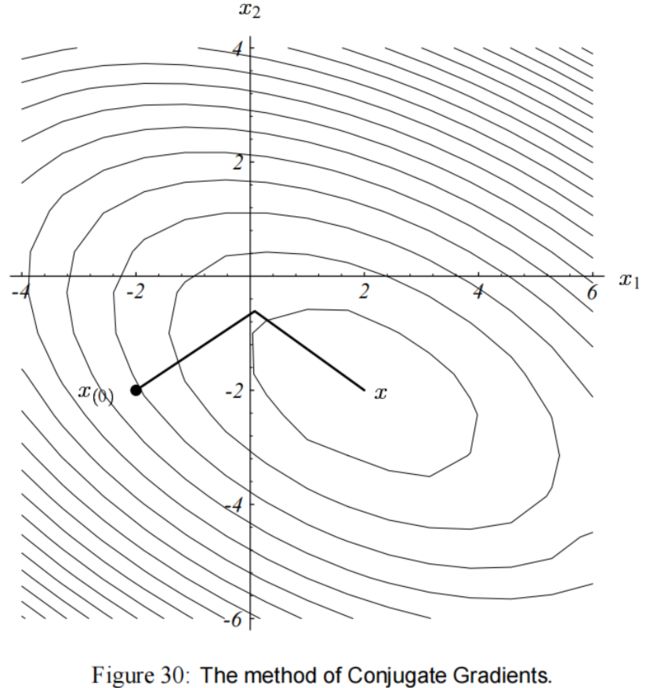
在我们的用例中,CG 的性能如 图(30) 所示。
关于共轭梯度这个命名:
“共轭梯度(Conjugate Gradients)” 这个名字多少有点不太恰当,因为那些梯度(gradients)都不是共轭(conjugate)的,而且那些共轭方向(Conjugate directions) 也不全为梯度(gradients)。
用 “Conjugated Gradients” 会更精确一些。
9. Convergence Analysis of Conjugate Gradients(共轭梯度的收敛性分析)
CG 在 n n n 次迭代后完成计算,为什么我们要关心它的收敛性呢?
① 在实践中,累计的浮点数舍入误差 ( floating point roundoff error )会导致残差 ( residual )的准确度逐渐降低,
② 而式子里没有用上误差,又会导致搜索向量失去 A A A-正交性。
前①个问题可以像之前在最陡下降的做法那样处理。
但第②个问题就不那么好解决了。由于这么做失去了共轭,数学界在 20 20 20 世纪 60 60 60 年代抛弃了 CG。后来有相关的研究发表了证据,提出了当它作为迭代过程的有效性,人们才重新产生了兴趣。
时代变了,我们的前景也变了。今天,收敛性分析很重要,因为 CG 通常用于很大的问题,甚至运行 n n n 次迭代都不行。收敛性分析很少被看做是用来预防浮点数误差的,更多的是用于证明用于某种问题(这类问题无法用精确的算法式子表达)。
共轭梯度(CG )的第 1 1 1 次迭代和最陡下降的第 1 1 1 次迭代是一样的。因此在没有改变的情况下,第6.1节描述了 CG 在第 1 1 1 次迭代上收敛的情况。
9.1 Picking Perfect Polynomials(选择完美的多项式)
我们已经看到,在 CG 的每一步中, e ( i ) e_{(i)} e(i) 的值都是从空间 e ( 0 ) + D i e_{(0)} + \mathcal{D}_i e(0)+Di 中选择的,其中 D i = span { r ( 0 ) , A r ( 0 ) , A 2 r ( 0 ) , … , A i − 1 r ( 0 ) } = span { A e ( 0 ) , A 2 e ( 0 ) , A 3 e ( 0 ) , … , A i e ( 0 ) } \begin{aligned} \mathcal{D}_i &= \text{span} \{ r_{(0)} , Ar_{(0)}, A^2r_{(0)}, \dots , A^{i-1}r_{(0)} \} \\ &= \text{span} \{ Ae_{(0)}, A^2e_{(0)}, A^3e_{(0)}, \dots , A^{i}e_{(0)} \} \end{aligned} Di=span{r(0),Ar(0),A2r(0),…,Ai−1r(0)}=span{Ae(0),A2e(0),A3e(0),…,Aie(0)}
像这样的克雷洛夫子空间(Krylov subspace)有另外一种友好的特性。对于固定的 i i i,误差项具有以下形式: e ( i ) = ( I + ∑ j = 1 i ψ j A j ) e ( 0 ) e_{(i)} = \left( I + \sum^{i}_{j=1} \psi_j A^j \right) e_{(0)} e(i)=(I+j=1∑iψjAj)e(0)
系数 ψ j \psi_j ψj 与 α ( i ) \alpha_{(i)} α(i) 和 β ( i ) \beta_{(i)} β(i) 的值相关,但确切的关系在这里并不重要。
重要的是在 7.3 节里的这个证明: CG 中采用的系数 ψ j \psi_j ψj 能最小化 ∥ e ( i ) ∥ A \| e_{(i)} \|_A ∥e(i)∥A。
上面括号中的表达式可以表示为一个多项式。
令 P i ( λ ) P_i(\lambda) Pi(λ) 为 i i i 次的多项式, P i P_i Pi 可以用一个标量或者一个矩阵作为它的参数,以同样的形式写出式子。
举个例子,如果 P 2 ( λ ) = 2 λ 2 + 1 P_2(\lambda) = 2\lambda^2 +1 P2(λ)=2λ2+1,则 P 2 ( A ) = 2 A 2 + I P_2(A) = 2A^2 + I P2(A)=2A2+I.
这种灵活的表示法对于特征向量很有用,你脑海里应该要有这个东西: P i ( A ) v = P i ( λ ) v P_i(A)v = P_i(\lambda)v Pi(A)v=Pi(λ)v。
(注意 A v = λ v , A 2 v = λ 2 v Av=\lambda v,A^2v = \lambda^2 v Av=λv,A2v=λ2v,以此类推)
于是我们可以把误差项写成 e ( i ) = P i ( A ) e ( 0 ) e_{(i)} = P_i (A) e_{(0)} e(i)=Pi(A)e(0)
如果我们要求 P i ( 0 ) = 1 P_i(0)=1 Pi(0)=1。 CG 在选择系数 ψ j \psi_j ψj 的时候就选择了这个多项式。
让我们来研究一下对 e ( 0 ) e_{(0)} e(0) 应用这个多项式的效果。
像之前在最陡下降里的分析一样,把 e ( 0 ) e_{(0)} e(0) 表示为正交的单位长度的特征向量的线性组合: e ( 0 ) = ∑ j = 1 n ξ j v j e_{(0)} = \sum_{j=1}^n \xi_j v_j e(0)=j=1∑nξjvj
然后我们有 e ( i ) = ∑ j ξ j P i ( λ j ) v j A e ( i ) = ∑ j ξ j P i ( λ j ) λ j v j ∥ e ( i ) ∥ A 2 = ∑ j ξ j 2 [ P i ( λ j ) ] 2 λ j \begin{aligned} e_{(i)} &= \sum_j \xi_j P_i (\lambda_j) v_j \\ A e_{(i)} &= \sum_j \xi_j P_i (\lambda_j) \lambda_j v_j \\ \|e_{(i)} \|_A^2 &= \sum_j \xi_j^2 [P_i (\lambda_j)]^2 \lambda_j \end{aligned} e(i)Ae(i)∥e(i)∥A2=j∑ξjPi(λj)vj=j∑ξjPi(λj)λjvj=j∑ξj2[Pi(λj)]2λj
CG 会找到多项式,使这个表达式最小化,但是它的收敛性不如最差的特征向量(the worst eigenvector)的收敛性。
令 Λ ( A ) \Lambda(A) Λ(A) 为 A A A 的特征向量的集,我们有: ∥ e ( i ) ∥ A 2 ≤ min P i max λ ∈ Λ ( A ) [ P i ( λ ) ] 2 ∑ j ξ j 2 λ j = min P i max λ ∈ Λ ( A ) [ P i ( λ ) ] 2 ∥ e ( 0 ) ∥ A 2 (50) \begin{aligned} \|e_{(i)} \|_A^2 &\leq \min_{P_i} \max_{\lambda \in \Lambda(A)} [P_i(\lambda)]^2 \sum_j \xi_j^2 \lambda_{j} \\ &= \min_{P_i} \max_{\lambda \in \Lambda(A)} [P_i(\lambda)]^2 \|e_{(0)} \|_A^2 \end{aligned} \tag{50} ∥e(i)∥A2≤Piminλ∈Λ(A)max[Pi(λ)]2j∑ξj2λj=Piminλ∈Λ(A)max[Pi(λ)]2∥e(0)∥A2(50)

图(31) 表明,对于一些 i i i 的值,对于我们的例题, P i P_i Pi 在特征值为 2 2 2 和 7 7 7 的情况下能最小化这个表达式(式子(50))。只有 1 1 1 个 零次多项式满足 P 0 ( 0 ) = 1 P_{0}(0)=1 P0(0)=1,那个就是 P 0 ( λ ) = 1 P_{0}(\lambda)=1 P0(λ)=1,如 图(31)a 所示。
注意到 P 1 ( 2 ) = 5 9 P_1(2) = \dfrac{5}{9} P1(2)=95, P 1 ( 7 ) = − 5 9 P_1(7)=-\dfrac{5}{9} P1(7)=−95,所以经过一次 CG 迭代之后,误差项的能量范数不会大于初始值的 5 9 \dfrac{5}{9} 95。
图(31)c 表明,经过两次迭代后, 式子(50) 算出来为零,这是因为二次的多项式可以拟合这三个点( P 2 ( 0 ) = 1 P_2(0)=1 P2(0)=1, P 2 ( 2 ) = 0 P_2(2)=0 P2(2)=0, P 2 ( 7 ) = 0 P_2(7)=0 P2(7)=0)
总的来说,一个 n n n 次的多项式可以拟合 n + 1 n+1 n+1 个点,从而可以容许 n n n 个单独的特征值。
上面的讨论强化了我们的理解:CG 在 n n n 次迭代后产生精确结果。
并且进一步证明,如果特征值有重复,CG 会更快。
如果浮点数的精度无限,那迭代的次数最多不超过特征值的个数(线性无关的特征值)。
(还有一种提前结束迭代的可能: x ( 0 ) x_{(0)} x(0) 可能和一些 A A A 的特征向量 A A A-正交。如果一些特征向量不在 x ( 0 ) x_{(0)} x(0) 的展开式中,那在 式子(50)中可以考虑省去它们的特征值。但是,要提前警告你的是,由于浮点数舍入误差(floating point roundoff error),这些特征向量可能会被重新引入。)
我们还发现,当特征值聚集(clustered)在一起时,CG 收敛得更快(与它们在 λ m i n \lambda_{min} λmin 和 λ m a x \lambda_{max} λmax 之间不规则分布时相比)。这是因为 CG 更容易选择一个多项式,使 式子(50) 最小化。
如果我们已经知道 A A A 的特征值的一些性质,那有可能能提出一个多项式,得到一个快速收敛的证明。然而,在本分析的其余部分中,我将假设是最一般的情况:特征值均匀分布在 λ m i n \lambda_{min} λmin 和 λ m a x \lambda_{max} λmax 之间,特征值的数量非常多,还有浮点数舍入误差。
9.2 Chebyshev Polynomials(切比雪夫多项式)
一个有用的方法是,在区间 [ λ m i n , λ m a x ] [\lambda_{min}, \lambda_{max}] [λmin,λmax] 之间最小化 式子(50),而不是在有限数量的点上。
实现这方法的多项式是基于切比雪夫多项式(Chebyshev Polynomials)的。
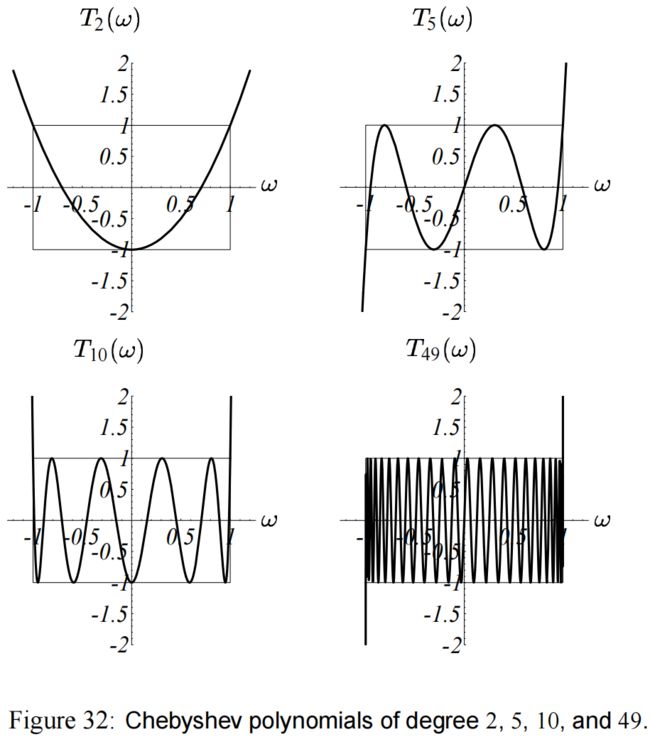
i i i 次的切比雪夫多项式为: T i ( ω ) = 1 2 [ ( ω + ω 2 − 1 ) i + ω − ω 2 − 1 ) i ] T_i(\omega) = \dfrac{1}{2} \left[ (\omega + \sqrt{\omega^2 - 1})^i + \omega - \sqrt{\omega^2 - 1})^i \right] Ti(ω)=21[(ω+ω2−1)i+ω−ω2−1)i]
(如果你觉得这个式子看起来不像多项式,试着算一下 i i i 为 1 1 1 或者 2 2 2 的情况)
图(32) 展示了几个切比雪夫多项式。
切比雪夫多项式有这样的性质:
在域 ω ∈ [ − 1 , 1 ] \omega \in [-1,1] ω∈[−1,1] 之间有 ∣ T i ( ω ) ∣ ≤ 1 | T_i(\omega) | \leq 1 ∣Ti(ω)∣≤1。(实际上是在 1 1 1 和 − 1 -1 −1 之间震荡)
进一步地,对于所有这些多项式, ω \omega ω 不在 [ − 1 , 1 ] [-1,1] [−1,1] 的时候 ∣ T i ( ω ) ∣ | T_i(\omega) | ∣Ti(ω)∣ 是最大的。
总的来说,在每张示意图的的矩形区域以外, ∣ T i ( ω ) ∣ | T_i(\omega) | ∣Ti(ω)∣ 增大的速度有多快就多快。
附录(C3) 说明了采用下面的值时, 式子(50) 可以最小化。
P i ( λ ) = T i ( λ m a x + λ m i n − 2 λ λ m a x − λ m i n ) T i ( λ m a x + λ m i n λ m a x − λ m i n ) P_i(\lambda) = \dfrac { T_i \left( \dfrac{\lambda_{max} + \lambda_{min} - 2 \lambda}{ \lambda_{max} -\lambda_{min} } \right) } {T_i \left( \dfrac{\lambda_{max} + \lambda_{min} }{ \lambda_{max} -\lambda_{min} } \right) } Pi(λ)=Ti(λmax−λminλmax+λmin)Ti(λmax−λminλmax+λmin−2λ)
在区间 λ m i n ≤ λ ≤ λ m a x \lambda_{min} \leq \lambda \leq \lambda_{max} λmin≤λ≤λmax 上,该多项式具有 切比雪夫多项式 的震荡性。它的分母能满足我们的要求,即 P i ( 0 ) = 1 P_i(0)=1 Pi(0)=1。分子在 λ m i n \lambda_{min} λmin 和 λ m a x \lambda_{max} λmax 之间的最大值是 1 1 1,所以由 式子(50) 有:
∥ e ( i ) ∥ A ≤ T i ( λ m a x + λ m i n λ m a x − λ m i n ) 1 ∥ e ( 0 ) ∥ A = T i ( κ + 1 κ − 1 ) − 1 ∥ e ( 0 ) ∥ A = 2 [ ( κ + 1 κ − 1 ) i + ( κ − 1 κ + 1 ) i ] − 1 ∥ e ( 0 ) ∥ A (51) \begin{aligned} \| e_{(i)} \|_A & \leq T_i \left( \dfrac{ \lambda_{max} +\lambda_{min} }{ \lambda_{max} -\lambda_{min} } \right)^1 \| e_{(0)} \|_A \\ &= T_i \left( \dfrac{ \kappa +1 }{ \kappa -1 } \right)^{-1} \| e_{(0)} \|_A \\ &= 2 \left[ \left( \dfrac{ \sqrt{\kappa} +1 }{ \sqrt{\kappa} -1 } \right)^{i} + \left( \dfrac{ \sqrt{\kappa} -1 }{ \sqrt{\kappa} + 1 } \right)^{i} \right]^{-1} \| e_{(0)} \|_A \end{aligned} \tag{51} ∥e(i)∥A≤Ti(λmax−λminλmax+λmin)1∥e(0)∥A=Ti(κ−1κ+1)−1∥e(0)∥A=2[(κ−1κ+1)i+(κ+1κ−1)i]−1∥e(0)∥A(51)
随着 i i i 的增加,方括号内的第二个加数收敛于零,因此,通常用较弱的不等式来表示 CG 的收敛性:
∥ e ( i ) ∥ A ≤ 2 ( κ − 1 κ + 1 i ) ∥ e ( 0 ) ∥ A (52) \| e_{(i)}\|_A \leq 2 \left( \dfrac{\sqrt{\kappa}-1}{ \sqrt{\kappa} +1 }^i \right) \| e_{(0)} \|_A \tag{52} ∥e(i)∥A≤2(κ+1κ−1i)∥e(0)∥A(52)
CG 的第一步相当于最陡下降的第一步。令 式子(51) 中的 i = 1 i=1 i=1,我们得到 式子(28),即最陡下降的收敛结果。也就是 图(31)b 中的线性多项式的情况。
图(34) 画出了 CG 每一次迭代的收敛情况,忽略损失因子 “ 2 ” “\, 2 \,” “2”。实际中,CG 的收敛速度通常比 式子(52) 的建议速度要快,如果你有较好的特征值分布,或者较好的起点。比较 式子(52) 和 式子(28) ,容易发现 CG 的收敛速度比最陡下降快得多(见图(35)).。然而,不是 CG 的每一次迭代都能具有更快的收敛速度,例如,它的第 1 1 1 次迭代其实是一个最陡下降。 式子(52) 的因子为 2 2 2,使得 CG 在这一些比较差的迭代上有些松弛。
10 Complexity(复杂性)
在每一次最陡下降或者共轭梯度的迭代中,主要的操作是矩阵-向量的乘法。一般来说,矩阵-向量乘法需要 O ( m ) \mathcal{O}(m) O(m) 的操作,其中 m m m 为矩阵中非零项的个数。对于许多问题,包括本文介绍的一些, A A A 都是稀疏的(sparse), m ∈ O ( n ) m \in \mathcal{O}(n) m∈O(n)。
假设我们想要执行足够的迭代,把误差项的范数减少到 ε \varepsilon ε 倍,即 ∥ e ( i ) ∥ ≤ ε ∥ e ( 0 ) ∥ \|e_{(i)} \| \leq \varepsilon \| e_{(0)}\| ∥e(i)∥≤ε∥e(0)∥。可以用 式子(28) 来表明,使用最陡下降来实现这个边界,所需的最大迭代次数是 i ≤ ⌈ 1 2 κ ln ( 1 ϵ ) ⌉ i \leq \left\lceil \dfrac{1}{2} \kappa \ln \left(\dfrac{1}{\epsilon} \right) \right\rceil i≤⌈21κln(ϵ1)⌉
而 式子(52) 表明,CG 所需要的最大迭代次数为 i ≤ ⌈ 1 2 κ ln ( 2 ϵ ) ⌉ i \leq \left\lceil \dfrac{1}{2} \sqrt{\kappa} \ln \left(\dfrac{2}{\epsilon} \right) \right\rceil i≤⌈21κln(ϵ2)⌉
我的总结是,最陡下降的时间复杂性是 O ( m κ ) \mathcal{O}(m\kappa) O(mκ),而 CG 的时间复杂性是 O ( m κ ) \mathcal{O}(m \sqrt{\kappa}) O(mκ)。两个算法的空间复杂性都是 O ( m ) \mathcal{O}(m) O(m)。
在 d 维域( d d d - dimensional domains)上的二阶椭圆边值问题( second-order elliptic boundary value problems)的有限差分(Finite difference)和有限元逼近(finite element approximations)通常有 κ ∈ O ( n 2 / d ) \kappa \in \mathcal{O}(n^{2/d}) κ∈O(n2/d)。
因此,在 2 2 2 维问题上,最陡下降的时间复杂度是 O ( n 2 ) \mathcal{O}(n^2) O(n2),相比于 CG 的 O ( n 3 / 2 ) \mathcal{O}(n^{3/2}) O(n3/2)。
对于 3 3 3 维问题,最陡下降的时间复杂度是 O ( n 5 / 3 ) \mathcal{O}(n^{5/3}) O(n5/3), CG 是 O ( n 4 / 3 ) \mathcal{O}(n^{4/3}) O(n4/3)。
11 Starting and Stopping(起始和结束)
在前面的最陡下降和共轭梯度算法中,忽略了一些细节;特别是如何选择起点,以及何时停止。
11.1 Starting(开始)
这没什么多说的。
如果你有一个 x x x 的粗略估计,就把它作为起始值 x ( 0 ) x_{(0)} x(0)。如果没有,就设 x ( 0 ) = 0 x_{(0)} = 0 x(0)=0。
对线性系统求解时,最陡下降 和 共轭梯度 都会收敛。
而非线性最小化会比较棘手,尽管如此,但因为可能有几个局部最小值,起始点的选择将会决定收敛到哪个最小值,或者能否真的收敛。
11.2 Stopping(停止)
当最陡下降或共轭梯度达到最小点时,残差变为零。如果在一次迭代后计算 式子(11) 或者 式子(48),就会发生除以零的情况。这看起来当残差为 0 0 0 时必须立刻停止。然而,更复杂的是,在残差的递归公式(式子(47))中累积的舍入误差可能会产生一个错误的零残差,这个问题可以通过重新计算 式子(45) 来解决。
通常来说,人们希望在完全收敛之前就停止。由于误差项不可用,通常当残差的范数低于指定阈值时,就停止。这个值通常是初始残差的一个分数( ∥ r ( i ) ∥ < ε ∥ r ( 0 ) ∥ \| r_{(i)}\| < \varepsilon \| r_{(0)}\| ∥r(i)∥<ε∥r(0)∥)。见 目录B。