论文阅读笔记—CVPR2022—Point-NeRF
论文链接:https://arxiv.org/abs/2201.08845
主要内容:将传统的MVS方法和NeRF进行结合,提出了基于点云的NeRF,该方法利用点云信息,可以避免在“empty space”上浪费大量时间,从而提高效率,与NeRF相比有几十倍的提速。
创新点:①将点云与NeRF结合 ②具有一定的泛化性(与MVSNeRF相似)
阅读本篇博客,你需要:①了解NeRF模型 ②了解MVSNet
颜色标记:输入输出 重点信息 留了个坑
一、基本框架
 图1 Point-NeRF基本框架
图1 Point-NeRF基本框架
如图所示,与传统NeRF模型不同,Point-NeRF并非直接利用图像输入,而是先利用点云生成模块生成点云数据,再以点云作为NeRF模型的输入。
1.1 基于点云的体渲染模块
 图2 体渲染模块
图2 体渲染模块
由于Point-NeRF的输入输出关系较复杂,因此先假设体渲染部分的输入(如图3)已知,其获取将在1.2进行讲解。
 图3 体渲染模块的输入
图3 体渲染模块的输入
如上图,P为若干个点云, 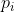 代表其空间位置,
代表其空间位置,  为特征向量,其编码了 局部场景信息,
为特征向量,其编码了 局部场景信息, ![]() 为置信度,取值范围为 [0,1] ,表示这个点位于surface上的可能性。
为置信度,取值范围为 [0,1] ,表示这个点位于surface上的可能性。
传统的NeRF模型直接利用MLP对光线上的采样点查询其辐射值 (radiance)和体密度
(radiance)和体密度 (volume density),而Point-NeRF对每个采样点,查询其在给定半径R(论文中未提及如何取值)中的K个点云,如公式1所示,以采样点位置x,光线方向d以及K个点云作为输入,输出其辐射值和体密度。这样做的好处是不用计算没有点云的空间,即empty space,从而极大地提高了体渲染的效率。
(volume density),而Point-NeRF对每个采样点,查询其在给定半径R(论文中未提及如何取值)中的K个点云,如公式1所示,以采样点位置x,光线方向d以及K个点云作为输入,输出其辐射值和体密度。这样做的好处是不用计算没有点云的空间,即empty space,从而极大地提高了体渲染的效率。
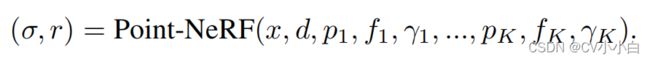 公式1
公式1
公式1可继续细化为三个公式。
首先是公式1.1,该公式是用于计算点云 对于采样点 x 的特征向量。其中 是点云特征向量, x 是采样点位置,![]() 代表点云 到采样点 x 的相对位置(利用相对位置,实现在点云平移的情况下网络的输出不变性),将特征向量和采样点位置输入MLP
代表点云 到采样点 x 的相对位置(利用相对位置,实现在点云平移的情况下网络的输出不变性),将特征向量和采样点位置输入MLP  ,输出点云 对于采样点位置 x 的特征向量
,输出点云 对于采样点位置 x 的特征向量![]() (注意区分 和
(注意区分 和 ![]() ,前者只与点云有关,后者还与采样点位置有关)。
,前者只与点云有关,后者还与采样点位置有关)。
 公式1.1
公式1.1
接着是公式1.2和公式1.3。公式1.2是计算采样点 x 对应的向量特征,其以每个点云的置信度![]() 以及点云到采样点 x 的距离
以及点云到采样点 x 的距离![]() 作为权重,对每个点云 在采样点 x的特征向量
作为权重,对每个点云 在采样点 x的特征向量 ![]() 进行加权求和,得到采样点 x 对应的向量特征
进行加权求和,得到采样点 x 对应的向量特征 。公式1.3
。公式1.3 ![]() 是将和光线方向d输入MLP
是将和光线方向d输入MLP  ,输出其辐射值。
,输出其辐射值。
 公式1.2
公式1.2
最后是体密度的计算,与辐射值的计算不同,体密度的计算先通过MLP  获得每个点云的密度,如公式1.4
获得每个点云的密度,如公式1.4 ![]() 所示,再对点云密度进行加权求和,其中权重是每个点云的置信度
所示,再对点云密度进行加权求和,其中权重是每个点云的置信度![]() 以及点云到采样点 x 的距离
以及点云到采样点 x 的距离![]() ,如公式1.5所示,最终输出采样点的体密度。
,如公式1.5所示,最终输出采样点的体密度。
 公式1.5
公式1.5
至此,我们已经获得了每个采样点的辐射值和体密度,利用传统的体渲染公式,如公式2,便可计算光线对应的像素点颜色。
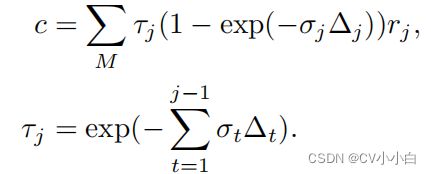 公式2
公式2
1.2 点云生成模块(Neural Point Generation)
输入:图像及其相机参数
输出:点云以及与点云对应的图像特征
 图3 点云生成模块
图3 点云生成模块
将图像分别输入![]() 和
和![]() ,其中
,其中![]() 为3D CNN模块,其首先利用plane-sweep在reference image上构建cost volume,从而得到深度图和每个点相对应的深度概率(在2.1有详细说明),将深度图进行反投影(unproject)便可获得点云数据;
为3D CNN模块,其首先利用plane-sweep在reference image上构建cost volume,从而得到深度图和每个点相对应的深度概率(在2.1有详细说明),将深度图进行反投影(unproject)便可获得点云数据;![]() 为2D CNN模块,其直接对图像进行卷积,获得不同尺度下的图像特征。
为2D CNN模块,其直接对图像进行卷积,获得不同尺度下的图像特征。
将点云投影到reference image的特征图上,将投影点对应的特征向量(不同尺度下特征的聚合)作为点云的特征向量,至此,我们获得了每幅图像的点云位置 以及每个点云对应的特征向量 。最后在深度概率空间上进行三线性采样,获得每个点云的置信度 ![]() (这一块我还没完全弄懂,暂且留个坑)。
(这一块我还没完全弄懂,暂且留个坑)。
除了使用MVSNet的方法获取深度图和点云,Point-NeRF也提出了他们自己的点云修剪和补全模块,该模块可以处理其他方法或模型(比如COLMAP)生成的点云,减小低分辨率区域点云密度,提高高分辨率区域点云密度,从而提高体渲染质量,其具体内容在2.2讲述。
二、部分模块的详细内容
2.1使用plane-sweep建立cost volume
在MVSNet中并非直接利用平面扫描法(plane-sweep)处理图像,而是先用2D CNN提取特征图像,再用特征图建立cost volume,下文介绍的是传统的平面扫描法,内容主要来自于(3条消息) 三维重建之平面扫描算法(Plane-sweeping)_小玄玄的博客-CSDN博客_plane sweep
 图4 平面扫描法基本原理
图4 平面扫描法基本原理
核心思想:平面扫描法认为,如果一个点在物体表面上,则其在不同相机上投影点的颜色应该一致,颜色差异越大,代表其离表面越远,即该点在表面上的概率越低。
基本步骤:如图4所示,三个相机的位置已知,camx对应的是reference image的相机,在camx的视锥体上划分若干平面 ,将平面上的3D点 P 投影到cam1和cam2的图像上,获得 p1 和 p2 两个投影点,这两个点的颜色差异就是深度概率。从前往后对每个平面上的所有3D点进行上述的处理,建立cost volume,即可获得视锥体上每个点对应的深度和其深度概率。camx中每个像素点可对应若干个(由平面数量决定)3D点,以每个点对应的深度概率作为权重,对其深度进行加权求和,最终结果就是像素点对应的深度,利用该深度进行反投影便可生成点云。
,将平面上的3D点 P 投影到cam1和cam2的图像上,获得 p1 和 p2 两个投影点,这两个点的颜色差异就是深度概率。从前往后对每个平面上的所有3D点进行上述的处理,建立cost volume,即可获得视锥体上每个点对应的深度和其深度概率。camx中每个像素点可对应若干个(由平面数量决定)3D点,以每个点对应的深度概率作为权重,对其深度进行加权求和,最终结果就是像素点对应的深度,利用该深度进行反投影便可生成点云。
2.2点云修剪和补全
Point-NeRF可以直接利用点云数据进行体渲染,但是为了提高渲染图像的质量,需要对点云数据进行处理,减小低分辨率的区域的点云密度,提高高分辨率区域的点云密度。
点云修剪:每隔10K次迭代,剔除置信度![]() <0.1的点云。
<0.1的点云。
点云补全:对于每根光线,查询不透明度最大的采样点,如公式3所示,如果该点满足![]() 以及
以及![]() ,表明该点接近物体表面且远离现有的点云,则生成该点(暂时还没有看懂前面的不等式中的符号, 论文中似乎没有提及)。
,表明该点接近物体表面且远离现有的点云,则生成该点(暂时还没有看懂前面的不等式中的符号, 论文中似乎没有提及)。
 公式3
公式3
三、实施细节
3.1训练方法
Point-NeRF使用与MVSNet类似的方法对点云生成模块进行预训练,其训练需要真值深度图作为监督。预训练完成后,对整个Point-NeRF模型进行端到端的训练。对点云生成模块的预训练使得Point-NeRF具有一定的泛化性,因为该模块可以使用在不同场景下,无需针对新的场景进行重新训练。
3.2损失函数
除了NeRF模型通用的图像重建损失,Point-NeRF还引入了对于置信度![]() 的损失,如公式4所示,该损失迫使置信度趋于0或者1。
的损失,如公式4所示,该损失迫使置信度趋于0或者1。
 公式4
公式4