Pytorch-Lightning基本使用步骤
发现了一个神器,减少代码量,界面优美。
于是乎,开撸
Pytorch Lightning
导入下列包:
import os
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader, random_split
import pytorch_lightning as pl
Step 1: 定义Lightning模型
class LitAutoEncoder(pl.LightningModule):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 64),
nn.ReLU(),
nn.Linear(64, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 28*28)
)
def forward(self, x):
# in lightning, forward defines the prediction(预测)/inference(推理) actions
embedding = self.encoder(x)
return embedding
def training_step(self, batch, batch_idx):
# training_step defined the train loop.
# It is independent of forward
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = F.mse_loss(x_hat, x)
# Logging to TensorBoard by default
self.log('train_loss', loss)
#self.log('my_loss', loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer
SYSTEM VS MODEL
LightningModule 定义了一个系统而不是一个模型。
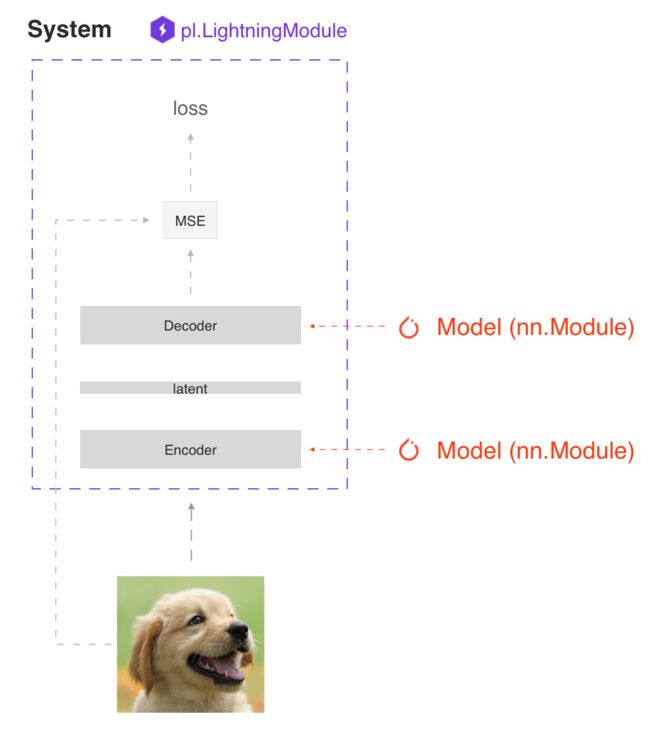
FORWARD vs TRAINING_STEP
在Lightning中,将训练步骤和推理分离,训练步骤定义了完整的训练过程。
例如,我们可以定义autoencoder去实现一个编码提取器。
def forward(self, x):
embeddings = self.encoder(x)
return embeddings
当然,没有什么可以阻止你在forward中使用训练步骤。
def training_step(self, batch, batch_idx):
...
z = self(x)
这取决与你的应用,但是,我们建议你把这两种分开
- 使用forward去推理(预测)
- 使用训练步骤去训练
Step 2: Fit with Lightning Trainer
首先,按照你想要的方式来定义数据,Lightning只需要一个DataLoader对与训练集/交叉验证集/测试集分割
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
train_loader = DataLoader(dataset)
接下来,初始化LightningModule和 Pytorch Lightning Trainer,然后开始训练。
# init model
autoencoder = LitAutoEncoder()
# most basic trainer, uses good defaults (auto-tensorboard, checkpoints, logs, and more)
# trainer = pl.Trainer(gpus=8) (if you have GPUs)
trainer = pl.Trainer()
trainer.fit(autoencoder, train_loader)
The Trainer automates:
- Epoch and batch iteration
- Calling of optimizer.step(), backward, zero_grad()
- Calling of .eval(), enabling/disabling grads
- Saving and loading weights
- Tensorboard (see Loggers options)
- Multi-GPU training support
- TPU support
- 16-bit training support
Predict or Deploy
当结束训练后,有3个选项去使用你训练好的LightningModule
Option 1: Sub-models
使用系统内任何模型去预测
# ----------------------------------
# to use as embedding extractor
# ----------------------------------
autoencoder = LitAutoEncoder.load_from_checkpoint('path/to/checkpoint_file.ckpt')
encoder_model = autoencoder.encoder
encoder_model.eval()
# ----------------------------------
# to use as image generator
# ----------------------------------
decoder_model = autoencoder.decoder
decoder_model.eval()
Option 2: Forward
# ----------------------------------
# using the AE to extract embeddings
# ----------------------------------
class LitAutoEncoder(pl.LightningModule):
def forward(self, x):
embedding = self.encoder(x)
return embedding
autoencoder = LitAutoencoder()
autoencoder = autoencoder(torch.rand(1, 28 * 28))
# ----------------------------------
# or using the AE to generate images
# ----------------------------------
class LitAutoEncoder(pl.LightningModule):
def forward(self):
z = torch.rand(1, 3)
image = self.decoder(z)
image = image.view(1, 1, 28, 28)
return image
autoencoder = LitAutoencoder()
image_sample = autoencoder()
Option 3: Production
确保已经添加了forward mathod , 或者仅仅需要跟踪子模块
# ----------------------------------
# torchscript
# ----------------------------------
autoencoder = LitAutoEncoder()
torch.jit.save(autoencoder.to_torchscript(), "model.pt")
os.path.isfile("model.pt")
# ----------------------------------
# onnx
# ----------------------------------
with tempfile.NamedTemporaryFile(suffix='.onnx', delete=False) as tmpfile:
autoencoder = LitAutoEncoder()
input_sample = torch.randn((1, 28 * 28))
autoencoder.to_onnx(tmpfile.name, input_sample, export_params=True)
os.path.isfile(tmpfile.name)
Using CPUs/GPUs/TPUs
在Lightning中使用cpu、gpu或tpu是很简单的,无需改变代码,只需要改变训练选项。
# train on CPU
trainer = pl.Trainer()
# train on 8 CPUs
trainer = pl.Trainer(num_processes=8)
# train on 1024 CPUs across 128 machines
trainer = pl.Trainer(
num_processes=8,
num_nodes=128
)
# train on 1 GPU
trainer = pl.Trainer(gpus=1
# train on multiple GPUs across nodes (32 gpus here)
trainer = pl.Trainer(
gpus=4,
num_nodes=8
)
# train on gpu 1, 3, 5 (3 gpus total)
trainer = pl.Trainer(gpus=[1, 3, 5])
# Multi GPU with mixed precision
trainer = pl.Trainer(gpus=2, precision=16)
# Train on TPUs
trainer = pl.Trainer(tpu_cores=8)
无需修改代码中的任意一行,就可以使用上面的代码执行以下操作。
# train on TPUs using 16 bit precision
# using only half the training data and checking validation every quarter of a training epoch
trainer = pl.Trainer(
tpu_cores=8,
precision=16,
limit_train_batches=0.5,
val_check_interval=0.25
)
Checkpoints
Lightning会自动保存你的模型,一旦你训练好了,你可以通过下面代码来加载检查点
model = LitModel.load_from_checkpoint(path)
上面的检查点包含了初始化模型和设置状态字典所需的所有参数
# load the ckpt
ckpt = torch.load('path/to/checkpoint.ckpt')
# 等效与上述代码
model = LitModel()
model.load_state_dict(ckpt['state_dict'])
Logging
要记录日志到Tensorboard或进度条,可以在LighningModule中的任何地方调用use()方法。
def training_step(self, batch, batch_idx):
self.log('my_metric', x)
The log() 有一些选项。
- on_step (在训练的那个步骤记录metric)
- on_epoch (在epoch结束时,自动积累并且记录)
- prog_bar (记录到进度条中)
- logger (记录到tensorboard中)
Setting on_epoch=True will accumulate your logged values over the full training epoch.
def training_step(self, batch, batch_idx):
self.log('my_loss', loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
进度条中显示的损失值在最后的值上被平滑处理,因此不同于在训练/验证步骤中返回的实际损失。
你也可以直接使用记录器的任意方法
def training_step(self, batch, batch_idx):
tensorboard = self.logger.experiment
tensorboard.any_summary_writer_method_you_want())
一旦你的训练开始,你就可以通过使用你最喜欢的记录器启动Tensorboard查看日志。
!tensorboard --logdir ./lightning_logs #在命令行中查看
From: https://pytorch-lightning.readthedocs.io/en/latest/new-project.html#
def training_step(self, batch, batch_idx):
tensorboard = self.logger.experiment
tensorboard.any_summary_writer_method_you_want())
一旦你的训练开始,你就可以通过使用你最喜欢的记录器启动Tensorboard查看日志。
!tensorboard --logdir ./lightning_logs #在命令行中查看
From: https://pytorch-lightning.readthedocs.io/en/latest/new-project.html#