正则化总结
一 .正则化的目的:
1. 过拟合现象:
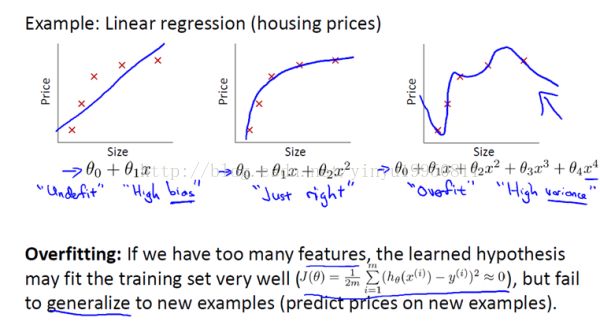
如图,在线性回归中。图一中,使用一条直线进行数据的拟合,但是这个模型并没有很好的拟合数据,产生很大的偏差。这种现象称为欠拟合。
图二中,使用一个二次函数进行拟合,得到很好的拟合结果。
图三中,使用更高阶的多项式进行拟合,这个模型通过了所有的训练数据,使代价函数 约等于0甚至等于0。但是这是一条极度不规律扭曲的曲线,它并不是一个好的模型。
过拟合现象:如果我们使用高阶多项式,变量(特征)过多,那么这个函数能够很好的拟合训练集,但是却会无法泛化到新的数据样本中(泛化:一个假设模型能够应用到新样本的能力)。
当存在较多的变量,较少的训练数据,使得没有足够的训练集来约束这个变量过多的模型,就会导致过拟合的现象。
1. 解决过拟合问题:
1)减少变量的个数:舍弃一些变量,保留更为重要的变量。但是,如果每个特征变量都对预测产生影响。当舍弃一部分变量时,也就舍弃了一些信息。所以,希望保留所有的变量。
2)正则化:保留所有的变量,将一些不重要的特征的权值置为0或权值变小使得特征的参数矩阵变得稀疏,使每一个变量都对预测产生一点影响。
二. 正则化的思路:
如果参数对应一个较小的值,那么会得到形式更加简单的假设。惩罚高阶参数,使它们趋近于0,这样就会得到较为简单的假设,也就是得到简单的函数,这样就不易发生过拟合。但是在实际问题中,并不知道哪些是高阶多项式的项,所以在代价函数中增加一个惩罚项/正则化项,将代价函数中所有参数值都最小化,收缩每一个参数。

参数值越小模型越简单(预防过拟合)的原因:

因为越复杂的模型,越是会尝试拟合所有的训练数据,包括一些异常样本,这就容易造成在较小的区间内预测值产生较大的波动,这种大的波动反映了在某些小的区间里导数值很大。而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
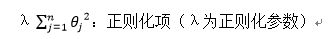
正则化参数要做的就是控制两个目标之间的平衡关系:在最小化训练误差的同时正则化参数使模型简单。
1.最小化误差是为了更好的拟合训练数据。
2.正则化参数是为了防止模型过分拟合训练数据。
所以正则化参数要保证模型简单的基础上使模型具有很好的泛化性能。
三. 正则化方法
L_0范数
L_0范数是指向量中非零元素的个数(设0^0=0)

若用L_0范数来规则化参数矩阵,就是希望参数矩阵大部分元素都为0,使特征矩阵稀疏。但是很难优化求解。
L_1范数
L_1范数是指向量中各个绝对值元素之和

因为参数的大小与模型的复杂度成正比,所以模型越复杂,范数就越大。使用范数也可以实现特征稀疏。正则化是正则化的最优凸近似,相对范数的优点是容易求解,因此通常都是用范数进行正则化,而不是范数。
L_2范数
L_2范数是各参数的平方和再求平方根

让L_2范数的正则化项‖W‖_2最小,可以使W的每个元素都很小,都接近于零。但是与范数L_1不同,它不使每个元素都为0,而是接近于零。越小的参数模型越简单,越简单的模型越不容易产生过拟合现象。
L_2范数的好处:
L_2范数不仅可以防止过拟合,而且还使优化求解变得稳定与迅速。
1. L_2范数解决在用正规方程进行最小化代价函数时矩阵可能会不可逆的问题:
使用正规方程进行最小化代价函数minJ(θ)

但是如果样本的数目m比特征参数n要小的时候,也就是方程组的个数小于未知数的个数,那么X^T X将会是不满秩的,也就是X^T X不可逆,那么就无法求出最优解。
在加上正则项后: 
就会保证 是可逆的。
是可逆的。
2. 正则化可以加快收敛的速度
线性回归的代价函数叫做凸函数(只有一个全局最优解)。而加入规则项后,就是将代价函数变为λ-strongly convex(λ强凸)。
普通的convex函数的定义,函数在x的地方做一阶泰勒近似:
f(y)≥f(x)+〈∇f(x),y-x〉+o(‖y-x‖)
而加入正则项优化后将函数变为λ强凸:
f(y)≥f(x)+〈∇f(x),y-x〉+λ/2 ‖y-x‖^2(λ>0)


Convex性质是指函数曲线位于该点的切线之上,保证函数在任意一点都处于它的一阶泰勒函数之上,而strongly convex 进一步要求位于该处的一个二次函数之上,也就是要求函数不要太平坦,有向上弯曲的趋势。
如图,当代价函数如左图时,代价函数相对较平坦,当wt点距离最优解点w*较远时,近似梯度值就已经很小了,而距离w*点较近的点的梯度值就会更小,所以迭代速度会很慢,在有限的迭代次数中,可能会无法保证收敛到全局最优解。
但是在右图中,w*附近的点存在着较大的梯度值,这样收敛速度快,就可以保证以较少的迭代次数到达w*点。
正则化与正则化的比较
对于和规则化的代价函数来说,我们可以写成以下形式:
考虑二维的情况,在(w1,w2)平面上可以画出代价函数的等高线,圆心就是样本值,半径就是误差,而约束条件则就是红色边界。等高线与约束条件相交的地方就是最优解。

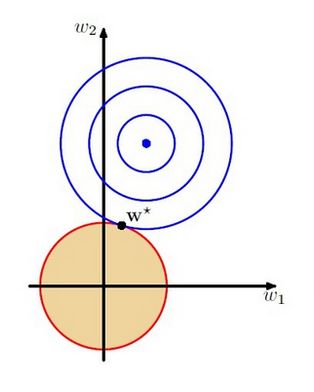
左图为L_1正则化的约束项,右图为L_2正则化的约束项。通过可视化可以发现,使用L_1正则化在取得最优解的时候w1的值为0,相当于去掉了一个特征,而使用L_2正则化在取得最优解的时候特征参数都有其值。
结论:
L_1会趋向于产生少量的特征,而其他的特征都为0,而L_2会选择更多的特征,特征值都趋近于0.Lasso在选择特征时非常有用,而Ridge就只是规则化而已。所以在所有特征中只有少数特征起重要作用的情况下,选择Lasso进行特征选择。而所有特征中大部分特征都能起作用,而且作用很平均,那么使用Ridge会更合适。