TensorRT学习笔记--官方示例sampleMNIST.cpp的理解与运行
目录
1--前言
2--编写CMakeLists.txt
3--代码注释
4--运行结果
1--前言
基于 TensorRT 8.2.5.1 和 Cuda11.3,在 Ubuntu 20.04 编写 CMakeLists.txt 进行编译,生成可执行文件;
2--编写CMakeLists.txt
提供一个 CMakeLists.txt 编写样例,需根据个人实际修改具体路径:
cmake_minimum_required(VERSION 3.13)
project(TensorRT_test)
set(CMAKE_CXX_STANDARD 11)
set(SAMPLES_COMMON_SOURCES "/home/liujinfu/Downloads/TensorRT-8.2.5.1/samples/common/logger.cpp")
add_executable(TensorRT_test sampleMNIST.cpp ${SAMPLES_COMMON_SOURCES})
# add TensorRT8
include_directories(/home/liujinfu/Downloads/TensorRT-8.2.5.1/include)
include_directories(/home/liujinfu/Downloads/TensorRT-8.2.5.1/samples/common)
set(TENSORRT_LIB_PATH "/home/liujinfu/Downloads/TensorRT-8.2.5.1/lib")
file(GLOB LIBS "${TENSORRT_LIB_PATH}/*.so")
# add CUDA
find_package(CUDA 11.3 REQUIRED)
message("CUDA_LIBRARIES:${CUDA_LIBRARIES}")
message("CUDA_INCLUDE_DIRS:${CUDA_INCLUDE_DIRS}")
include_directories(${CUDA_INCLUDE_DIRS})
# link
target_link_libraries(TensorRT_test ${LIBS} ${CUDA_LIBRARIES})3--代码注释
// 包含头文件
#include "argsParser.h"
#include "buffers.h"
#include "common.h"
#include "logger.h"
#include "NvCaffeParser.h"
#include "NvInfer.h"
#include
#include
#include
#include
#include
#include
using samplesCommon::SampleUniquePtr;
const std::string gSampleName = "TensorRT.sample_mnist";
// 定义 SampleMNIST 类
class SampleMNIST
{
public:
// 构造函数
SampleMNIST(const samplesCommon::CaffeSampleParams& params)
: mParams(params)
{
}
// 用于 build engine 的成员函数
bool build();
// 用于 inference 的成员函数
bool infer();
// 用于 清理状态 的成员函数
bool teardown();
private:
// 使用 caffe 的 parser 创建网络并标记输出层
bool constructNetwork(
SampleUniquePtr& parser, SampleUniquePtr& network);
// 对输入数据进行前处理
bool processInput(
const samplesCommon::BufferManager& buffers, const std::string& inputTensorName, int inputFileIdx) const;
// 验证输出结果是否正确并打印
bool verifyOutput(
const samplesCommon::BufferManager& buffers, const std::string& outputTensorName, int groundTruthDigit) const;
std::shared_ptr mEngine{nullptr}; //!< The TensorRT engine used to run the network
samplesCommon::CaffeSampleParams mParams; //!< The parameters for the sample.
nvinfer1::Dims mInputDims; // 输入数据的维度
SampleUniquePtr
mMeanBlob; //! the mean blob, which we need to keep around until build is done
};
// build engine 的成员函数实现
bool SampleMNIST::build()
{
// 创建 builder
auto builder = SampleUniquePtr(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
if (!builder)
{
return false;
}
// 使用 builder 创建 network
auto network = SampleUniquePtr(builder->createNetworkV2(0));
if (!network)
{
return false;
}
// 创建config,用于配置模型
auto config = SampleUniquePtr(builder->createBuilderConfig());
if (!config)
{
return false;
}
// 创建parser,用于解析模型
auto parser = SampleUniquePtr(nvcaffeparser1::createCaffeParser());
if (!parser)
{
return false;
}
// 执行 constructNetwork() 成员函数,使用 parser 创建 MNIST network 并标记输出层
if (!constructNetwork(parser, network))
{
return false;
}
// 设置推理网络的相关参数
builder->setMaxBatchSize(mParams.batchSize); // 设定 batchsize
config->setMaxWorkspaceSize(16_MiB); // 设定 workspace
config->setFlag(BuilderFlag::kGPU_FALLBACK); // 启用GPU回退模式
// 设置精度计算
if (mParams.fp16) // 使用fp16精度
{
config->setFlag(BuilderFlag::kFP16);
}
if (mParams.int8) // 使用int8精度
{
config->setFlag(BuilderFlag::kINT8);
}
// 启用 DLA
samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore);
// 创建 Cuda stream
auto profileStream = samplesCommon::makeCudaStream();
if (!profileStream)
{
return false;
}
config->setProfileStream(*profileStream);
// builder->buildSerializedNetwork 创建推理引擎
SampleUniquePtr plan{builder->buildSerializedNetwork(*network, *config)};
if (!plan)
{
return false;
}
// 序列化模型后,创建 Runtime 接口
SampleUniquePtr runtime{createInferRuntime(sample::gLogger.getTRTLogger())};
if (!runtime)
{
return false;
}
// 反序列化
mEngine = std::shared_ptr(
runtime->deserializeCudaEngine(plan->data(), plan->size()), samplesCommon::InferDeleter());
if (!mEngine)
{
return false;
}
// 断定输入的 batchsize 为1,即单次只能处理一个样本
ASSERT(network->getNbInputs() == 1);
// 获取输入的维度,断定输入数据的维度为3
mInputDims = network->getInput(0)->getDimensions();
ASSERT(mInputDims.nbDims == 3);
// build engine 成功,返回True
return true;
}
// 输入数据前处理成员函数的实现
bool SampleMNIST::processInput(
const samplesCommon::BufferManager& buffers, const std::string& inputTensorName, int inputFileIdx) const
{
// 获取输入图像的高和宽,mInputDims 已在私有成员变量中定义
const int inputH = mInputDims.d[1];
const int inputW = mInputDims.d[2];
// 随机读取一个数字文件
srand(unsigned(time(nullptr)));
std::vector fileData(inputH * inputW);
readPGMFile(locateFile(std::to_string(inputFileIdx) + ".pgm", mParams.dataDirs), fileData.data(), inputH, inputW);
// 打印数字的 ASCII 表示,在控制台中用 ASCII 码显示图片
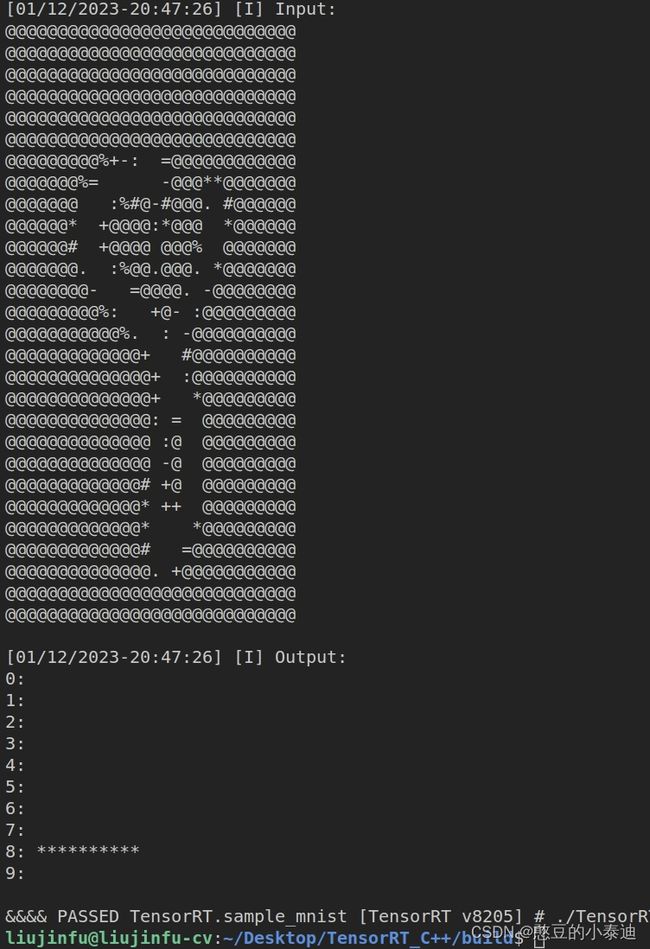
sample::gLogInfo << "Input:\n";
for (int i = 0; i < inputH * inputW; i++)
{
sample::gLogInfo << (" .:-=+*#%@"[fileData[i] / 26]) << (((i + 1) % inputW) ? "" : "\n");
}
sample::gLogInfo << std::endl;
// 将输入数据存储到主机(host)的内存中
float* hostInputBuffer = static_cast(buffers.getHostBuffer(inputTensorName));
for (int i = 0; i < inputH * inputW; i++)
{
hostInputBuffer[i] = float(fileData[i]);
}
return true;
}
// 成员函数实现,验证输出结果是否正确并打印
bool SampleMNIST::verifyOutput(
const samplesCommon::BufferManager& buffers, const std::string& outputTensorName, int groundTruthDigit) const
{
// 从 host 的 output buffer 中读取 输出结果
const float* prob = static_cast(buffers.getHostBuffer(outputTensorName));
// 打印输出分布的直方图
sample::gLogInfo << "Output:\n";
float val{0.0f};
int idx{0};
const int kDIGITS = 10;
for (int i = 0; i < kDIGITS; i++)
{
if (val < prob[i])
{
val = prob[i];
idx = i;
}
sample::gLogInfo << i << ": " << std::string(int(std::floor(prob[i] * 10 + 0.5f)), '*') << "\n";
}
sample::gLogInfo << std::endl;
return (idx == groundTruthDigit && val > 0.9f);
}
// constructNetwork()成员函数的实现
bool SampleMNIST::constructNetwork(
SampleUniquePtr& parser, SampleUniquePtr& network)
{
const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor = parser->parse(
mParams.prototxtFileName.c_str(), mParams.weightsFileName.c_str(), *network, nvinfer1::DataType::kFLOAT);
// 输出 Tensor 标记
for (auto& s : mParams.outputTensorNames)
{
network->markOutput(*blobNameToTensor->find(s.c_str()));
}
// 在网络开头添加减均值的操作(针对本示例而言)
nvinfer1::Dims inputDims = network->getInput(0)->getDimensions();
mMeanBlob
= SampleUniquePtr(parser->parseBinaryProto(mParams.meanFileName.c_str()));
nvinfer1::Weights meanWeights{nvinfer1::DataType::kFLOAT, mMeanBlob->getData(), inputDims.d[1] * inputDims.d[2]};
float maxMean
= samplesCommon::getMaxValue(static_cast(meanWeights.values), samplesCommon::volume(inputDims));
auto mean = network->addConstant(nvinfer1::Dims3(1, inputDims.d[1], inputDims.d[2]), meanWeights);
if (!mean->getOutput(0)->setDynamicRange(-maxMean, maxMean))
{
return false;
}
if (!network->getInput(0)->setDynamicRange(-maxMean, maxMean))
{
return false;
}
auto meanSub = network->addElementWise(*network->getInput(0), *mean->getOutput(0), ElementWiseOperation::kSUB);
if (!meanSub->getOutput(0)->setDynamicRange(-maxMean, maxMean))
{
return false;
}
network->getLayer(0)->setInput(0, *meanSub->getOutput(0));
samplesCommon::setAllDynamicRanges(network.get(), 127.0f, 127.0f);
return true;
}
// 推理过程的成员函数实现
bool SampleMNIST::infer()
{
// 创建 buffer 管理对象
samplesCommon::BufferManager buffers(mEngine, mParams.batchSize);
// 创建上下文 Context
auto context = SampleUniquePtr(mEngine->createExecutionContext());
if (!context)
{
return false;
}
// 随机选择一个数字进行推理
srand(time(NULL));
const int digit = rand() % 10;
// 断定数字的个数为1
ASSERT(mParams.inputTensorNames.size() == 1);
// 对输入数字进行前处理
if (!processInput(buffers, mParams.inputTensorNames[0], digit))
{
return false;
}
// 创建 Cuda stream
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// 异步地将 input_data 从 host 的 input buffer 拷贝到 device 的 input buffer (host -> device)
buffers.copyInputToDeviceAsync(stream);
// 异步地执行推理
if (!context->enqueue(mParams.batchSize, buffers.getDeviceBindings().data(), stream, nullptr))
{
return false;
}
// 推理结果从 device 转移到 host
buffers.copyOutputToHostAsync(stream);
// 等待 stream 中的 work 完成
cudaStreamSynchronize(stream);
// 释放stream
cudaStreamDestroy(stream);
// 断定输出结果只有一个Tensor
ASSERT(mParams.outputTensorNames.size() == 1);
// 执行函数 verifyOutput() 验证结果的正确性,并打印推理结果,这个函数可以理解成后处理函数
bool outputCorrect = verifyOutput(buffers, mParams.outputTensorNames[0], digit);
return outputCorrect;
}
// 成员函数实现,清理对象的所有状态
bool SampleMNIST::teardown()
{
nvcaffeparser1::shutdownProtobufLibrary();
return true;
}
// 使用命令行参数初始化结构体参数成员
samplesCommon::CaffeSampleParams initializeSampleParams(const samplesCommon::Args& args)
{
samplesCommon::CaffeSampleParams params;
if (args.dataDirs.empty()) // 输入参数的路径为空时,使用默认的路径
{
params.dataDirs.push_back("data/mnist/");
params.dataDirs.push_back("data/samples/mnist/");
}
else // 输入参数的路径不为空时,使用输入的路径
{
params.dataDirs = args.dataDirs;
}
// 从路径中读取相应的文件
params.prototxtFileName = locateFile("mnist.prototxt", params.dataDirs);
params.weightsFileName = locateFile("mnist.caffemodel", params.dataDirs);
params.meanFileName = locateFile("mnist_mean.binaryproto", params.dataDirs);
params.inputTensorNames.push_back("data");
params.batchSize = 1;
params.outputTensorNames.push_back("prob");
params.dlaCore = args.useDLACore;
params.int8 = args.runInInt8;
params.fp16 = args.runInFp16;
return params;
}
// 定义打印参数含义的函数
void printHelpInfo()
{
std::cout
<< "Usage: ./sample_mnist [-h or --help] [-d or --datadir=] [--useDLACore=]\n";
std::cout << "--help Display help information\n";
std::cout << "--datadir Specify path to a data directory, overriding the default. This option can be used "
"multiple times to add multiple directories. If no data directories are given, the default is to use "
"(data/samples/mnist/, data/mnist/)"
<< std::endl;
std::cout << "--useDLACore=N Specify a DLA engine for layers that support DLA. Value can range from 0 to n-1, "
"where n is the number of DLA engines on the platform."
<< std::endl;
std::cout << "--int8 Run in Int8 mode.\n";
std::cout << "--fp16 Run in FP16 mode.\n";
}
int main(int argc, char** argv)
{
// 解析参数的含义,例如--help
samplesCommon::Args args;
bool argsOK = samplesCommon::parseArgs(args, argc, argv);
// 参数不匹配
if (!argsOK)
{
sample::gLogError << "Invalid arguments" << std::endl;
printHelpInfo();
return EXIT_FAILURE;
}
// 输出参数帮助信息
if (args.help)
{
printHelpInfo();
return EXIT_SUCCESS;
}
// 定义用于 test 的logger
auto sampleTest = sample::gLogger.defineTest(gSampleName, argc, argv);
// 输出: 表明 test 开始
sample::gLogger.reportTestStart(sampleTest);
// 执行定义的 initializeSampleParams() 函数,使用命令行参数初始化结构体参数成员
samplesCommon::CaffeSampleParams params = initializeSampleParams(args);
// 使用 SampleMNIST 类根据params定义一个sample对象
SampleMNIST sample(params);
sample::gLogInfo << "Building and running a GPU inference engine for MNIST" << std::endl; // 打印信息
// 执行 sample.build() 编译推理引擎
if (!sample.build())
{
return sample::gLogger.reportFail(sampleTest); // 编译失败,使用gLogger报告信息
}
// 执行 sample.infer() 进行 inference 推理
if (!sample.infer())
{
return sample::gLogger.reportFail(sampleTest); // 推理失败,使用gLogger报告信息
}
// 清除 sample 的所有状态,释放内存
if (!sample.teardown())
{
return sample::gLogger.reportFail(sampleTest);
}
return sample::gLogger.reportPass(sampleTest);
}
4--运行结果
执行以下命令进行编译,生成可执行文件:
mkdir build
cd build
cmake ..
make执行以下命令运行可执行文件,并指定模型地址:
./TensorRT_test -d /home/liujinfu/Downloads/TensorRT-8.2.5.1/data/mnist运行结果截图: