机器学习--常用的特征工程方法
1、特征选择介绍
(1)特征选择的定义
对当前学习任务有价值的属性称为是“相关特征”,没有价值的属性称为是“无关特征”,从给定的特征集中选择出相关特征子集的过程,就称为是“特征选择”。
其中还有一种特征称为是“冗余特征”,这些特征指的是可以从其他特征中推演出来的特征。
(2)特征选择的重要性
特征选择是一个“数据预处理”过程,它的重要性体现在两个方面:
1)减轻维度灾难问题。
2)去除无关特征可以降低学习的难度。
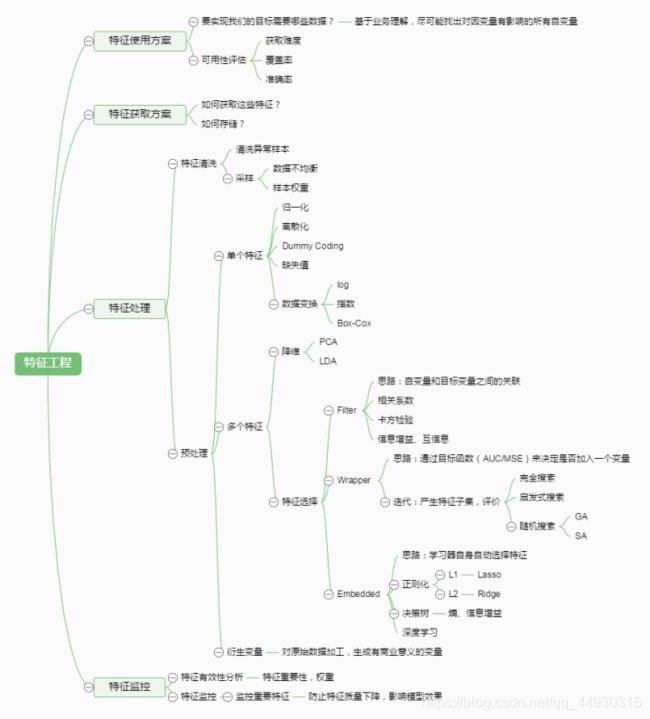
(3)特征工程是什么?
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通过总结和归纳,人们认为特征工程包括以下方面:
(4)特征选择的类型:
在现实生活中,一个对象往往具有很多属性(以下称为特征),这些特征大致可以被分成三种主要的类型:
相关特征:对于学习任务(例如分类问题)有帮助,可以提升学习算法的效果;
无关特征:对于我们的算法没有任何帮助,不会给算法的效果带来任何提升;
冗余特征:不会对我们的算法带来新的信息,或者这种特征的信息可以由其他的特征推断出;
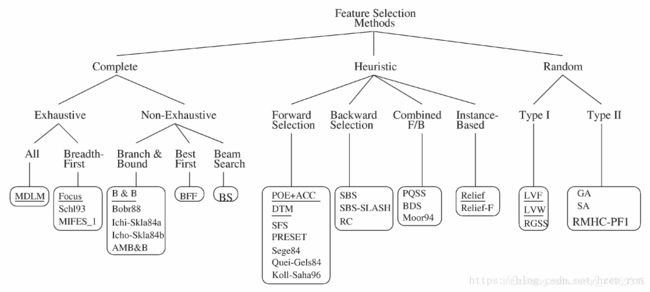
(5)特征选择算法:
根据上面的三种不同的搜索策略和五种不同的评价函数,会有很多具体的特征选择算法。以下是主要的分类:
2.特征选择方法
(1)特征选择:
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
(2)特征选择方法
-
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
-
Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
-
Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
详解:
过滤式选择
过滤式方法先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关。
Relief(Relevant FeaturesRelevant Features)是著名的过滤式特征选择方法,Relief 为一系列算法,它包括最早提出的 Relief 以及后来拓展的 Relief-F 和 RRelief-F ,其中最早提出的 Relief 针对的是二分类问题,RRelief-F 算法可以解决多分类问题,RRelief-F算法
包裹式选择
与过滤式选择不考虑后续学习器不同,包裹式选择直接把最终将要使用的学习器的性能作为特征子集的评价依据,也就是说,包裹式特征选择是为给定的学习器选择最有利的特征子集。
与过滤式选择相比,包裹式选择的效果一般会更好,但由于在特征选择过程中需要多长训练学习器,因此包裹式选择的计算开销要大很多。
LVW(Las Vegas Wrapper)是一种典型的包裹式特征选择方法,它在拉斯维加斯方法框架下使用随机策略来进行子集搜索,并以最终分类器的误差为特征子集评价准则。
嵌入式选择
在过滤式选择与包裹式选择方法中,特征选择过程与学习器训练过程有明显区别,与它们不同的是,嵌入式选择是将特征选择过程与学习器训练过程融合为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择。
基于 L1L1 正则化的学习方法就是一种嵌入式的特征选择方法,通过在目标函数中加入 L1L1 范数正则化,从而得到“稀疏”(sparsesparse)解,稀疏解可以使一些特征的权重为 00 ,那些非 00 的特征就可以视为是选择的特征,因此其特征选择过程与学习器训练过程融为一体,同时完成,可以视为是一种嵌入式的方法。值得一提的是,L1L1 范数相比于L2L2 范数更易获得稀疏解。
举例:
1. Filter
1.1 方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类来选择特征的代码如下:
from sklearn.feature_selection import VarianceThreshold
#方差选择法,返回值为特征选择后的数据
#参数threshold为方差的阈值
VarianceThreshold(threshold=3).fit_transform(iris.data)
1.2 相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。用
feature_selection库的SelectKBest类结合相关系数来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
#选择K个最好的特征,返回选择特征后的数据
#第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,
#输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
#参数k为选择的特征个数
SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
1.3 卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
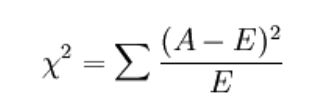
不难发现,这个统计量的含义简而言之就是自变量对因变量的相关性。用feature_selection库的SelectKBest类结合卡方检验来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#选择K个最好的特征,返回选择特征后的数据
SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)
1.4 互信息法
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:
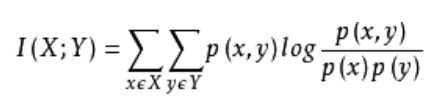
为了处理定量数据,最大信息系数法被提出,使用feature_selection库的SelectKBest类结合最大信息系数法来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from minepy import MINE
#由于MINE的设计不是函数式的,定义mic方法将其为函数式的,
#返回一个二元组,二元组的第2项设置成固定的P值0.5
def mic(x, y):
m = MINE()
m.compute_score(x, y)
return (m.mic(), 0.5)
#选择K个最好的特征,返回特征选择后的数据
SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
2 .Wrapper
2.1 递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
#递归特征消除法,返回特征选择后的数据
#参数estimator为基模型
#参数n_features_to_select为选择的特征个数
RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data, iris.target)
3 Embedded
3.1 基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
#带L1惩罚项的逻辑回归作为基模型的特征选择
SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target)
实际上,L1惩罚项降维的原理在于保留多个对目标值具有同等相关性的特征中的一个,所以没选到的特征不代表不重要。故,可结合L2惩罚项来优化。具体操作为:若一个特征在L1中的权值为1,选择在L2中权值差别不大且在L1中权值为0的特征构成同类集合,将这一集合中的特征平分L1中的权值,故需要构建一个新的逻辑回归模型:
from sklearn.linear_model import LogisticRegression
class LR(LogisticRegression):
def __init__(self, threshold=0.01, dual=False, tol=1e-4, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver='liblinear', max_iter=100,
multi_class='ovr', verbose=0, warm_start=False, n_jobs=1):
#权值相近的阈值
self.threshold = threshold
LogisticRegression.__init__(self, penalty='l1', dual=dual, tol=tol, C=C,
fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight=class_weight,
random_state=random_state, solver=solver, max_iter=max_iter,
multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
#使用同样的参数创建L2逻辑回归
self.l2 = LogisticRegression(penalty='l2', dual=dual, tol=tol, C=C, fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight = class_weight, random_state=random_state, solver=solver, max_iter=max_iter, multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
def fit(self, X, y, sample_weight=None):
#训练L1逻辑回归
super(LR, self).fit(X, y, sample_weight=sample_weight)
self.coef_old_ = self.coef_.copy()
#训练L2逻辑回归
self.l2.fit(X, y, sample_weight=sample_weight)
cntOfRow, cntOfCol = self.coef_.shape
#权值系数矩阵的行数对应目标值的种类数目
for i in range(cntOfRow):
for j in range(cntOfCol):
coef = self.coef_[i][j]
#L1逻辑回归的权值系数不为0
if coef != 0:
idx = [j]
#对应在L2逻辑回归中的权值系数
coef1 = self.l2.coef_[i][j]
for k in range(cntOfCol):
coef2 = self.l2.coef_[i][k]
#在L2逻辑回归中,权值系数之差小于设定的阈值,且在L1中对应的权值为0
if abs(coef1-coef2) < self.threshold and j != k and self.coef_[i][k] == 0:
idx.append(k)
#计算这一类特征的权值系数均值
mean = coef / len(idx)
self.coef_[i][idx] = mean
return self
使用feature_selection库的SelectFromModel类结合带L1以及L2惩罚项的逻辑回归模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel
#带L1和L2惩罚项的逻辑回归作为基模型的特征选择
#参数threshold为权值系数之差的阈值
SelectFromModel(LR(threshold=0.5, C=0.1)).fit_transform(iris.data, iris.target)
3.2 基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
#GBDT作为基模型的特征选择
SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
总结
以上即为常用的特征工程方法以及对他们的举例说明。