Pytorch可视化工具:tensorboardX
pytorch可用的可视化工具:tensorboardX、Visdom、VisualDL
好像还是tensorboardX用的更多一些,功能也更多,pytorch好像也在集成tensorboard,不需要再安装tensorboardX了。
关于visdom,不建议安装最新的0.1.8.9版本哟,好多css和js的script都没有放在包里,还需要再下载,翻了墙scripts也下不下来还是挺难受的,可能是假的。
文章目录
- tensorboardX
-
- 安装
- 使用
-
- 建立event writer实体
- 记录数值
- 记录图像
- 记录直方图、声音、文字
- 记录网络框架
- 查看
- Example
-
- example 1
- example 2
- example 3
- Visdom
- VisualDL
tensorboardX
tensorboardX是为了非tensorflow框架也可以使用tensorboard的可视化功能而开发的。
学习并参考了tensorboardX文档、Pytorch使用tensorboardX可视化
(搬运工x)
安装
pip install tensorflow
pip install tensorboardX
默认都会安装最新版本,建议安装tensorboardX稳定的较低版本,出现网络访问超时问题记得换源。
使用
建立event writer实体
以下为建立event writer实体的几种调用方法:
from tensorboardX import SummaryWriter
# method1:在当前工作目录下建立文件目录‘runs/exp-1’,用于存放数据
writer = SummaryWriter('runs/exp-1')
# method2:在当前工作目录下建立文件目录‘runs/当前时间_机器名字' ex. 'runs/Feb15_11-35-17_xxx'
writer = SummaryWriter()
# method3:在当前工作目录下建立文件目录‘runs/当前时间_机器名字_comment名字' ex. 'runs/Feb15_11-35-17_xxx_3xLR'
writer = SummaryWriter(comment='3xLR')
建议:当文件夹中的内容发生变化时重命名文件夹,文件夹命名可以是用时间命名或者直接把参数当文件夹名称。
用完之后记得writer.close()
记录数值
可以用如下函数来记录loss、accuracy、learning rate等,value可以是pytorch tensor、numpy、float、int等python数值类型。
writer.add_scalar('myscalar', value, iteration)
记录图像
图像通常用一个三维矩阵来表示(三个维度分别为红绿蓝通道),通常训练过程会有多张图像需要记录,最后得到的文件大小应该为[batch size,channel,height,weight]的矩阵。需要注意的是如果是Opencv/numpy矩阵,通常为[channel,weight,height],调用tensorboardX函数之前需要调用numpy.transpose,转换到[channel,height,weight]来进行存储,此外所有数据的值需要被映射到[0,1]之间,而不能是[0,255]。
writer.add_image('imresult', image, iteration)
记录直方图、声音、文字
writer.add_histogram('hist', array, iteration)
# 声音只能记录单通道
writer.add_audio('myaudio', audio, iteration, sample_rate)
# 文字支持markdown格式
writer.add_text('mytext', 'this is a pen', iteration)
记录网络框架
# 单一输入
add_graph(m, (x, ))
# 多输入
add_graph(m, (x, y, z))
查看
tensorboard --logdir <your_log_dir>
Example
example 1
在工作目录下新建一个py文件,包含一下内容:
import tensorboardX
from tensorboardX import SummaryWriter
import numpy as np
writer = SummaryWriter('runs/exp-1')
for epoch in range(10):
writer.add_scalar('scalar/test',np.random.rand(),epoch)
writer.add_scalars('scalar/scalars_test',{'xsinx':epoch*np.sin(epoch),'xcos':epoch*np.cos(epoch)},epoch)
writer.close()
编译运行以后,会自动新建文件夹和添加数据文件,工作目录下的文件结构如下:
- runs
- exp-1
- scalar
- scalar_test
- xsinx
- xcos
- scalar_test
- events.out.tfevents.1581737378.计算机名
- scalar
- exp-1
然后在cmd中运行tensorboardX
tensorboard --logdir runs

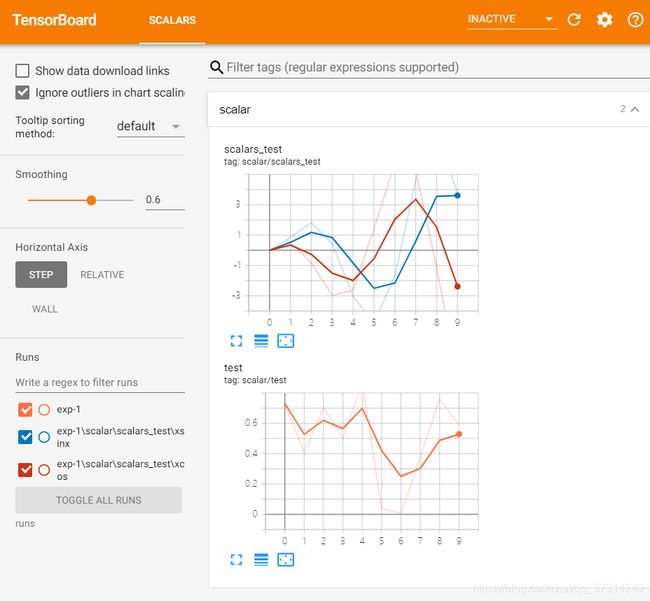
example 2
实现一个简单的LeNet模型,并查看网络结构
import torch
import time
from torch import nn,optim
from tensorboardX import SummaryWriter
# LeNet模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv=nn.Sequential(
nn.Conv2d(1,6,5,1,2),# in_channels, out_channels, kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2,2), # kernel_size, stride
nn.Conv2d(6,16,5),
nn.Sigmoid(),
nn.MaxPool2d(2,2)
)
self.fc=nn.Sequential(
nn.Linear(16*5*5,120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.Sigmoid(),
nn.Linear(84,10)
)
def forward(self,x):
x=self.conv(x)
x=self.fc(x.view(x.shape[0],-1))
return x
dummpy_input=torch.rand(13,1,28,28)
net = LeNet()
with SummaryWriter('runs/LeNet') as w:
w.add_graph(net,(dummpy_input,))
在tensorboard中查看:
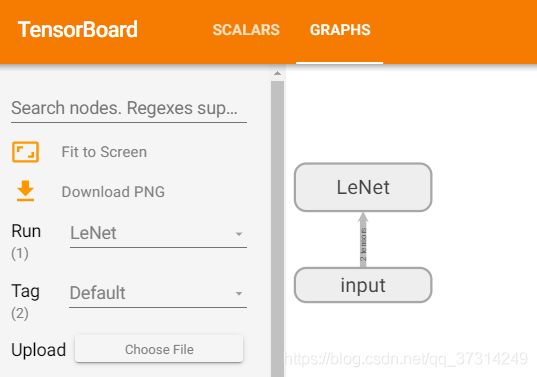

example 3
训练example2的网络,loss、accuracy可视化
writer=SummaryWriter('runs/LeNet')
# 获取数据和训练模型
batch_size=256
train_iter,test_iter=utils.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy(data_iter,net,device=None):
if device is None and isinstance(net,torch.nn.Module):
# 如果没指定device就使用net的device
device=list(net.parameters())[0].device
acc_sum,n=0.0,0
with torch.no_grad():
for X,y in data_iter:
if isinstance(net,torch.nn.Module):
net.eval()
acc_sum+=(net(X.to(device)).argmax(dim=1)==y.to(device)).float().sum().item()
net.train()
else:
if('is_training' in net.__code__.co_varnames):
acc_sum+=(net(X,is_training=False).argmax(dim=1)==y).float().sum().item()
else:
acc_sum+=(net(X).argmax(dim=1)==y).float().sum().item()
n+=y.shape[0]
return acc_sum/n
def train(net,train_iter,test_iter,batch_size,optimizer,device,num_epochs):
net=net.to(device)
print('training on',device)
loss=torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
train_l_sum,train_acc_sum,n,batch_count,start=0.0,0.0,0,0,time.time()
for X,y in train_iter:
X=X.to(device)
y=y.to(device)
y_hat=net(X)
l=loss(y_hat,y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum+=l.cpu().item()
train_acc_sum+=(y_hat.argmax(dim=1)==y).float().sum().item()
n+=y.shape[0]
batch_count+=1
test_acc=evaluate_accuracy(test_iter,net)
writer.add_scalar('train_loss',train_l_sum/batch_count,epoch)
writer.add_scalar('train_acc',train_acc_sum/batch_count,epoch)
writer.add_scalar('test_acc',test_acc,epoch)
print('epoch %d, loss %d, train acc %f, test acc %f, time %.1f sec'
%(epoch+1,train_l_sum/batch_count,train_acc_sum/n,test_acc,time.time()-start))
lr=0.001
net=LeNet()
num_epochs=10
optimizer=torch.optim.Adam(net.parameters(),lr=lr)
train(net,train_iter,test_iter,batch_size,optimizer,device,num_epochs)
writer.close()
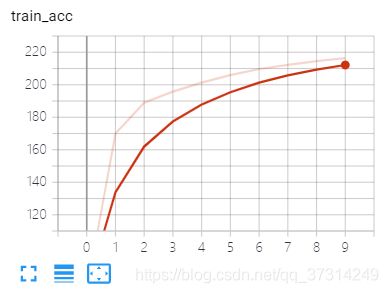
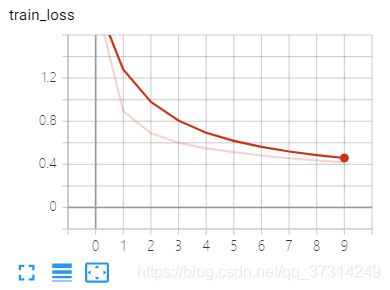

Visdom
参考 Visdom 可视化工具 教程 (pytorch) 、GitHub visdom
visdom建议安装版本0.1.8.8,目前的最新版本是0.1.8.9,新版本可能会出现一些小小的问题(下载scripts网络超时啥的)。
pip install visdom==0.1.8.8
# 启动
python -m visdom.server
VisualDL
VisualDL