的用法 取一部分数据_邵励治的机器学习 1 / 100 天:「数据预处理」

前言
不积跬步,无以至千里。不积小流,无以成江海。
打今儿起,我就要开始连载机器学习 100 天的专栏了。
从零单排,big thing start small,望与诸位读者共同进步。
行文方面我尽量面面俱到,把一切含糊的点,都尝试以生动形象的文字解释解释。
下面我们开始第一天的学习吧!今天我们将要学习的是所有 ML 的第一步:数据预处理!
第一步:引入函数库
import numpy as np
import pandas as pd- numpy 是一个装满了数学函数的函数库,很屌。
- pandas 是一个可以帮助我们 导入 和 管理 数据的函数库,也很屌。
第二步:导入数据“Data.csv”
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 3].values- .csv 格式的文件,我们可以将其理解为表格
- pandas 的 read_csv 函数,帮我们导入了 .csv 数据文件
- pandas 的 iloc 函数,帮我们把 .csv 数据文件中的数据,切割提取变成 Array【数组】
- ( )很明显,iloc 函数的语法谁也看不懂。
问题 2-1:Data.csv 在哪里下载?
答:Data.csv
问题 2-2:我们为啥看不懂 iloc 函数的用法?
答:因为我们需要学习一下 Python 的 切片 语法。
问题 2-3:Python 的切片是啥意思?
答:简单的说,切片就是一种从数组中取数据的办法。来,我给大家讲讲切片!
// 我们先创建一个数组,它有 8 个元素
>> list = ['Los Angeles','Lakers','Can','Not','Play','In','The','Playoffs']
// 现在我们想取出其的前三个,用切片的方式
>> temp = list[0:3]
// 我们打印一下
>> print(temp)
['Los Angeles','Lakers','Can']
// 我们还可以这样表示,把 0 给省略了,这个意思是从头取到 3
>> temp = list[:3]
>> print(temp)
['Los Angeles','Lakers','Can']
// 在 Python 中,list[-1] 的意思是取 list 这个数组的倒数第一个元素
// 所以,我们还可以这样用切片,下面这个意思是从倒数第 2 个取到最后
>> temp = list[-2:]
>> print(temp)
['The','Playoffs']
// 另外,如果以数组脚标的视角来看的话,切片是一个左闭右开的区间
// 不信你看,下面的这个切片,是不输出倒数第一个切片的
>> temp = list[-2:-1]
>> print(temp)
['The']
// 还有一招很绝的,叫从头到尾
>> temp = list[:]
>> print(temp)
['Los Angeles','Lakers','Can','Not','Play','In','The','Playoffs']
//(附加) 还可以设置每隔 n 个取一个数,比如
>> temp = list[0:8:2]
>> ['Los Angeles','Not','The']问题 2-4:现在我懂切片了,可以理解 .iloc 函数了嘛?
答:可以了,我们结合切片来看 .iloc 函数的用法。
- 我们先看 Data.csv 文件:

2. 我们看一下 .iloc 函数的用法:
X = dataset.iloc[:, :-1].values
Y = dataset.iloc[:10, 3].valuesX 是 [ : , : -1],很明显是两个切片,不难想象是代表行与列,于是翻译一下:
- X 的行是 Data.csv 的所有行
- X 的列是 Data.csv 的 1-3 列
验证一下,我们 print(X):
>> print("X:")
>> print(X)
X:
[['France' 44.0 72000.0]
['Spain' 27.0 48000.0]
['Germany' 30.0 54000.0]
['Spain' 38.0 61000.0]
['Germany' 40.0 nan]
['France' 35.0 58000.0]
['Spain' nan 52000.0]
['France' 48.0 79000.0]
['Germany' 50.0 83000.0]
['France' 37.0 67000.0]]验证 OJBK,就是我们想象的那样。
值得注意的是,它在缺少的值的那块,补充了 "nan" 字段。
3. 继续分析一下 .iloc 函数在 Y 上的用法:
Y 是 [ : 10, 3 ],翻译一下:
- Y 的行是从第 1 行到第 9 行
- Y 的列是第 4 列
验证一下,我们 print(Y):
>> print("Y:")
>> print(Y)
Y:
['No' 'Yes' 'No' 'No' 'Yes' 'Yes' 'No' 'Yes' 'No' 'Yes']咦,似乎好像不是我们想象的那样,解释一下,以上现象是因为以下两个原因:
- iloc 不把表头,也就是表的第一行视作数据
- 数组的脚标从 0 开始
图解:“Y 的行是从第 1 行到第 9 行”
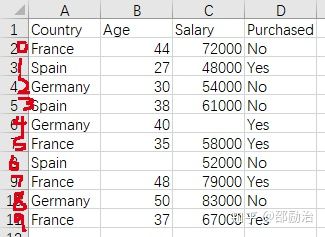
第三步:处理丢失的数据
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
imputer = imputer.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])- 我们得到的数据很少是完整的,数据可能会因为各种原因丢失,于是我们需要把丢掉的数据填充上。
- 一般的做法是:用所有数据的平均数或者中位数对缺失的数据进行填充。
- 在这里,我们使用 sklearn 库的 Imputer 类来帮助我们完成这个任务。
问题 3-1:sklearn 是什么类型的函数库?
答:一个简单、有效的数据挖掘和数据分析的工具。
问题 3-2:Imputer 是一个怎么样的类?
答:很明显,是一个帮助我们计算修复缺省值的类。具体用法都在代码上了,这里取修复的是X的所有行、后两列,替换的值是平均值(mean)。
问题 3-3:处理完了 X 长什么样?
答:就都填充上了,如下。
>> print("X:")
>> print(X)
X:
[['France' 44.0 72000.0]
['Spain' 27.0 48000.0]
['Germany' 30.0 54000.0]
['Spain' 38.0 61000.0]
['Germany' 40.0 63777.77777777778]
['France' 35.0 58000.0]
['Spain' 38.77777777777778 52000.0]
['France' 48.0 79000.0]第四步:将非Number类型的数据编码,以便做数学运算
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])- 很明显,我们的数据中会出现一些非 Number 类型的数据
- 很明显,我们的数学公式需要计算 Number 类型的数据
- 于是乎,我们需要把这些非 Number 型的数据,编码成 Number 的数据
- 我们使用的工具是:sklearn 库的 LabelEncoder 函数
问题 4-1:编码完了的 X 变成了啥样?
答:就像代码中写的,我们对 X 的所有行,第 1 列进行了编码,结果如下。
>> print("X:")
>> print(X)
[[0 44.0 72000.0]
[2 27.0 48000.0]
[1 30.0 54000.0]
[2 38.0 61000.0]
[1 40.0 63777.77777777778]
[0 35.0 58000.0]
[2 38.77777777777778 52000.0]
[0 48.0 79000.0]
[1 50.0 83000.0]
[0 37.0 67000.0]]可以看到,第一行的“国家名”变成了数字。
第四步半:使用 One-Hot 编码
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)问题 4.5-1:什么叫 One-Hot 编码?
答:这样的编码就叫 One-Hot 编码:
["男","女"]
- 男 => 10
- 女 => 01
["中国","美国","法国"]
- 中国 => 100
- 美国 => 010
- 法国 => 001
["足球","篮球","羽毛球","乒乓球"]
- 足球 => 1000
- 篮球 => 0100
- 羽毛球 => 0010
- 乒乓球 => 0001
大家自己找规律吧!
问题 4.5-2:One-Hot 编码之后的结果?
答:上述代码中,我们把 X 的所有数据都用 One-Hot 编了个码,然后把 Y 做了个常规的编码,结果如图。
>> print("X:")
>> print(X)
>> print("Y:")
>> print(Y)
X:
[[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.40000000e+01
7.20000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 2.70000000e+01
4.80000000e+04]
[0.00000000e+00 1.00000000e+00 0.00000000e+00 3.00000000e+01
5.40000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.80000000e+01
6.10000000e+04]
[0.00000000e+00 1.00000000e+00 0.00000000e+00 4.00000000e+01
6.37777778e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.50000000e+01
5.80000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.87777778e+01
5.20000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.80000000e+01
7.90000000e+04]
[0.00000000e+00 1.00000000e+00 0.00000000e+00 5.00000000e+01
8.30000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.70000000e+01
6.70000000e+04]]
Y:
[0 1 0 0 1 1 0 1 0 1]第五步:将数据分成“测试集”和“训练集”
// 原文中为 from sklearn.cross_validation import train_test_split,但已被遗弃
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)- 陀思妥耶夫斯基曾经说过,数据集,要分成测试用的和训练用的
- 训练用的数据集,用于训练模型
- 测试用的数据集,用于检测训练出来的模型,是否有效
- 我们使用 sklearn 库的 train_test_split() 函数进行数据切割
- 一般数据集和测试集的分割比例是 2 : 8
问题 5-1:我们现在到底 TM 在干什么?
答:我认为,到现在,一切都已经很明朗了。
机器学习的结果,是获得一个函数。
以便之后我们通过给该函数一个自变量 X,可以获得一个因变量 Y。
假如我们的机器学习选用的模型是一个一元二次方程,那么整件事情就会变得很简单:
y = ax^2 + bx + c
我们只需要确定三个参数即可。
但是这个函数模型一定不能解决一些很复杂的问题,于是我们的机器学习用的不是该模型。
我们用一些更复杂的模型,这些模型中也会有各种参数(a,b,c,d.....)需要我们确定。
于是我们输入大量的数据,来求这个模型的各种参数(a,b,c,d.....)。
数据量越大,参数求的越准,最后得出的函数也就越准确。
恐怖的是,我们现在的模型,越来越能适用于世间的一切情况。
问题 5-2:我们切割完的数据长什么样子?
答:我们这里只看 Y 的
>> print("训练集 Y")
>> print(Y_train)
>> print("测试集 Y")
>> print(Y_test)
训练集 Y
[1 1 1 0 1 0 0 1]
测试集 Y
[0 0]可以看到,训练集和测试集是随机抽取的。
第六步:特征缩放(Feature Scaling)
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)大多数的机器学习算法,使用欧几里得距离计算两个数据的差别。而我们的特征的大小、单位、幅度都各不相同。那些高幅度特征在计算距离的时候往往比低幅度的特征更好用,因此我们往往会通过“特征标准化”或者“Z-score”归一化来处理特征值。
问题 6-1:什么叫欧几里得距离?
答:上过高中的朋友们,这是我们的老朋友了,欧几里得距离的计算公式如下。

问题 6-2:什么叫特征(Feature)?
答:还是以我们的数据集为例,我们在下面的这个表格中,共有 3 个特征,1 个标签。
它们是 Country(特征1)、Age(特征2)、Salary(特征3) 与 Purchased(标签)。
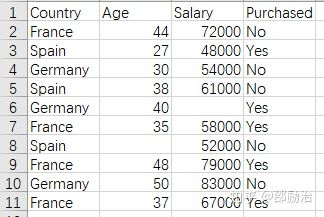
问题 6-3:什么叫特征的幅度(Feature Magnitudes)?
答:还是回到我们的数据,可以看到 Age 是 两位数 ,而 Salary 的是 五位数,我们这时就可以理解 Age 比 Salary 的 Magnitudes 小很多。
问题 6-4:什么叫特征标准化?
答:我们之前不是说用这个“欧几里得距离”算数据之间的差别么,假如我们的特征数据的幅度差特别多,比如上面的 Age(两位数) 与 Salary(五位数),那么我们算出的结果,明显就没 Age 啥事儿了————全看 Salary 一个人的表演就成了。
这可不行。
所以我们要进行数据标准化,给 Salary 进行特征缩放(Feature Scaling)
问题 6-5:什么叫“Z-score”标准化?
答:也是一种特征标准化的方法。用一句话解释
Z-Score通过(x-μ)/σ将两组或多组数据转化为无单位的Z-Score分值,使得数据标准统一化,提高了数据可比性,削弱了数据解释性。
问题 6-6:什么叫特征缩放?
答:特征缩放就是在特征标准化。这俩意思差不多。
问题 6-7:特征缩放完了的结果是?
答:结果有点出乎我的意料,为啥 X_train 和 X_test 的格式都不一样了呢?
>> print("X_train:")
>> print(X_train)
>> print("X_test:")
>> print(X_test)
X_train:
[[-1. 2.64575131 -0.77459667 0.26306757 0.12381479]
[ 1. -0.37796447 -0.77459667 -0.25350148 0.46175632]
[-1. -0.37796447 1.29099445 -1.97539832 -1.53093341]
[-1. -0.37796447 1.29099445 0.05261351 -1.11141978]
[ 1. -0.37796447 -0.77459667 1.64058505 1.7202972 ]
[-1. -0.37796447 1.29099445 -0.0813118 -0.16751412]
[ 1. -0.37796447 -0.77459667 0.95182631 0.98614835]
[ 1. -0.37796447 -0.77459667 -0.59788085 -0.48214934]]
X_test:
[[ 0. 0. 0. -1. -1.]
[ 0. 0. 0. 1. 1.]]总结
啊,不管怎么着,还是完成了机器学习第一天的任务。
总结一下,今天主要是学习了这个“数据处理部分”。
新知识点包括:
- Python 切片
- 引入 .csv 文件,并获取 特征值集合(X)与 标签集合(Y)
- 处理丢失的数据
- 给非 Number 类型的数据编码
- One-Hot 编码
- 切割数据集,变成“训练集”与“测试集”
- 特征缩放
每天学习机器学习一小时?妈的,天知道这点东西我学了多久。


希望之后可以提速!