目标检测(1)——数据预处理和数据集的切分
最近打算用yolov5做目标检测,首先了解了一下yolo的理论,然后开始踩坑实践。。
由于用labelimg标注后的图像标签是xml格式的,像这样的。

所以我们首先需要转换成yolo的标签格式,代码如下。
# xml-label to yolo-label
import os.path
import xml.etree.ElementTree as ET
class_names = ['mud', 'nonmud'] # 类别名
dirpath = r'./data/mud_labels' # 原来存放xml文件的目录
newdir = r'./data/labels' # 修改label后形成的txt目录
if not os.path.exists(newdir):
os.makedirs(newdir)
for fp in os.listdir(dirpath):
root = ET.parse(os.path.join(dirpath, fp)).getroot()
xmin, ymin, xmax, ymax = 0, 0, 0, 0
sz = root.find('size')
width = float(sz[0].text)
height = float(sz[1].text)
filename = root.find('filename').text
for child in root.findall('object'): # 找到图片中的所有框
name = child.find('name').text # 找到类别名
class_num = class_names.index(name)
sub = child.find('bndbox') # 找到框的标注值并进行读取
xmin = float(sub[0].text)
ymin = float(sub[1].text)
xmax = float(sub[2].text)
ymax = float(sub[3].text)
try: # 转换成yolo的标签格式,需要归一化到(0-1)的范围内
x_center = (xmin + xmax) / (2 * width)
y_center = (ymin + ymax) / (2 * height)
w = (xmax - xmin) / width
h = (ymax - ymin) / height
except ZeroDivisionError:
print(filename, '的 width有问题')
with open(os.path.join(newdir, fp.split('.')[0] + '.txt'), 'a+') as f:
f.write(' '.join([str(class_num), str(x_center), str(y_center), str(w), str(h) + '\n']))yolo的标签格式为:
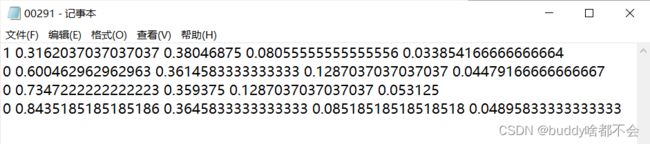
然后是训练 验证 测试集的划分,这里划分比例设置为6:2:2,代码如下。
# Train & Validation & Test set split
# -*- coding:utf8 -*-
import time
import os
import random
import cv2
t_1 = time.time()
imgs_path = './data/images/'
anns_path = './data/labels/'
name = 'dataset' # 划分后数据集文件夹名,随意更改
img_train_path ='./'+name + '/images/train/' #图片训练集保存路径
img_val_path = './'+name+'/images/val/' #图片验证集保存路径
img_test_path = './'+name+'/images/test/' #图片测试集保存路径
labels_train_path = './'+name+'/labels/train/' #标签训练集保存路径
labels_val_path = './'+name+'/labels/val/' #标签验证集保存路径
labels_test_path = './'+name+'/labels/test/' #标签测试集保存路径
if not os.path.exists(img_train_path):
os.makedirs(img_train_path)
if not os.path.exists(img_val_path):
os.makedirs(img_val_path)
if not os.path.exists(img_test_path):
os.makedirs(img_test_path)
if not os.path.exists(labels_train_path):
os.makedirs(labels_train_path)
if not os.path.exists(labels_val_path):
os.makedirs(labels_val_path)
if not os.path.exists(labels_test_path):
os.makedirs(labels_test_path)
imgs = os.listdir(imgs_path)
anns = os.listdir(anns_path)
random.seed(2021) #设置一个随机种子,确保每次运行都按照既定的随机形式
random.shuffle(imgs)
train_set_rate = 0.6
train_set_num = int(len(imgs) * train_set_rate)
val_set_rate = 0.2
val_set_num = int(len(imgs) * val_set_rate)
train_name_list = []
val_name_list = []
test_name_list = []
num_img = 0
num_train_set = 0
num_val_set = 0
num_test_set = 0
for i ,img in enumerate(imgs) :
image = cv2.imread(imgs_path + img)
if i <= train_set_num:
img = img.split('.')
train_name_list.append(img[0])
img = str.join('.', img)
cv2.imwrite(img_train_path + img , image)
num_train_set+=1
elif train_set_num < i <= train_set_num+val_set_num:
img = img.split('.')
test_name_list.append(img[0])
img = str.join('.', img)
cv2.imwrite(img_test_path + img, image)
num_test_set += 1
else:
img = img.split('.')
val_name_list.append(img[0])
img = str.join('.',img)
cv2.imwrite(img_val_path+ img, image)
num_val_set+=1
i+=1
num_img+=1
print('num_img----------------------',i)
print('train_set--------------',num_train_set)
print('val_set-----------------',num_val_set)
print('test_set-----------------',num_test_set)
print('图片总数量-----------------------',num_img)
ann_train = 0
ann_val = 0
ann_test = 0
num = 0
for ann in anns:
ann = ann.split('.')
if ann[0] in train_name_list:
ann = str.join('.', ann)
with open(anns_path + ann, 'r', encoding = 'UTF-8')as f:
with open(labels_train_path + ann, 'w')as s:
s.write(f.read())
ann_train+=1
elif ann[0] in val_name_list:
ann = str.join('.', ann)
with open(anns_path + ann, 'r', encoding = 'UTF-8')as f:
with open(labels_val_path + ann, 'w')as s:
s.write(f.read())
ann_val+=1
elif ann[0] in test_name_list:
ann = str.join('.', ann)
with open(anns_path + ann, 'r', encoding = 'UTF-8')as f:
with open(labels_test_path + ann, 'w')as s:
s.write(f.read())
ann_test+=1
num+=1
t_2 = time.time()
print('ann_train--------------------',ann_train)
print('ann_val----------------------',ann_val)
print('ann_test----------------------',ann_val)
print('totle_num---------------------',num)
print('time==========================',t_2 - t_1)
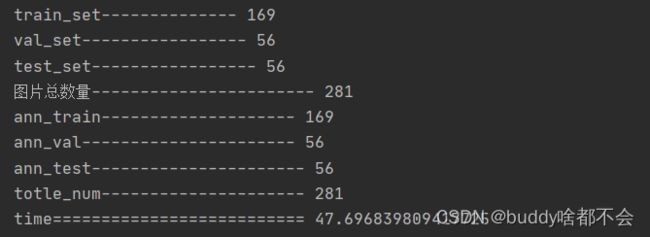
划分后训练集大小为169,验证集和测试集大小都为56,划分后的文件夹树状结构如下。

然后就可以进行网络的训练了~