Time Series
时间序列预测
时间序列预测问题有多种处理方式,时序问题都看成是回归问题,只是回归的方式(传统时序建模、线性回归、树模型、深度学习等)有一定的区别。传统的时序建模方法如利用平滑技术、自回归等模型思想上有着一定的启发意义。在实际的工程化应用场景中,为了同时兼顾速度与精度,通常采用像Lightgbm[1]、Xgboost[2]、CatBoost[3]、gpboost类的机器学习模型,这类方法一般就是把时序问题转换为监督学习,通过特征工程和机器学习方法去预测;这种模型可以解决绝大多数的复杂的时序预测模型。支持复杂的数据建模,支持多变量协同回归,支持非线性问题。不过这种方法需要较为复杂的人工特征过程部分,特征工程需要一定的专业知识或者丰富的想象力。特征工程能力的高低往往决定了机器学习的上限,而机器学习方法只是尽可能的逼近这个上限。特征建立好之后,就可以直接套用树模型算法进行调参并反复去重构特征。神经网络如Wavenet[4]、Tabnet[5]等也可以用来解决时序问题。循环神经网络如RNN、LSTM[6]等在大多数时候都会是主流的一种对比的选择,LSTM、GRU便是专门为解决时间序列问题而设计的。Transformer[7]类模型对于数据量的要求较大,且推理速度更慢,如今学术界也不断地针对其缺点进行改进进行时序预测。除此之外,很多时间序列工具如prophet[8]、Flow Forecast[13]等也可以快速帮助理解特征等。更多形式的正则化、预处理、迁移学习来提高性能会在未来出现。
- 时间序列预测任务的特征工程构建
各种数据挖掘竞赛以及实际工业场景中,大家使用的模型都较为类似,特征工程的构建是重中之重。一个典型的时间序列数据,会包含以下几列:时间戳,时序值,序列的属性变量,比如下图,日期就是时间戳,销量就是时序值,如果是多序列的话可能还会有序列的属性变量,如城市、产品、价格等。如下图图1所示,时间序列的特征工程也大多是基于这三个数据衍生出来。时间戳衍生:时间戳虽然只有一列,但是也可以根据这个就衍生出很多很多变量了,具体可以分为三大类:时间特征、布尔特征,时间差特征(距离重大节日等)。时序值衍生:因为时间序列是通过历史来预测未来,那么,这个时序值的历史数据,也就是当前时间点之前的信息就非常有用,通过他可以发现时间序列的趋势因素、季节性周期性因素以及一些不规则的变动,具体来说这部分特征可以分为三种:滞后值、滑动窗口统计和拓展窗口统计。预测滞后值的同时采用递归容易产生累计误差。滑动窗口统计需要注意多步预测时会出现的问题。而连续变量可以作为一个特征,类别变量在较少时可以采用one-hot编码或是label encoder,若类别变量较多时可以和因变量做特征交互。
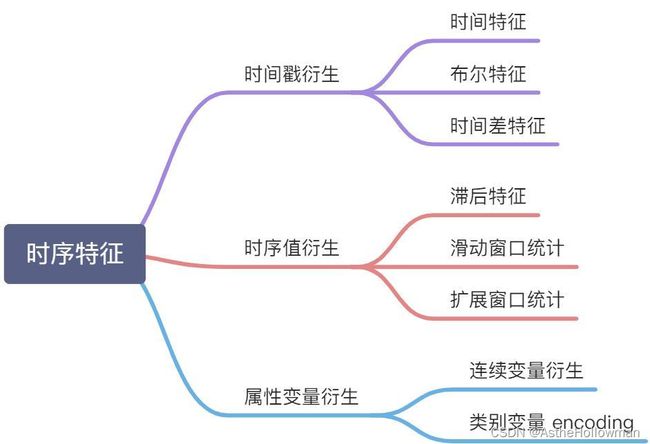
图1
- Transformer类模型
时间序列相比文本序列也有很多特点,例如时间序列具有自相关性或周期性、时间序列的预测经常涉及到周期非常长的序列预测任务等。这些都给Transformer在时间序列预测场景中的应用带来了新的挑战,也使学术界出现了一批针对时间序列任务的Transformer改造。由于参数量、计算量、数据量等的限制,实际场景中很少采用Transformer类模型,但它有着极大的挖掘潜力等着我们去探索与发现。以下是近期的Transformer类模型在时间序列预测任务上的改进。
图2为AutoFormer[9]。Autoformer是Transformer的升级版本,针对时间序列问题的特性对原始Transformer进行了一系列优化。

图2
第一个模块是Series Decomposition Block,这个模块主要目的是将时间序列分解成趋势项和季节项。在最基础的时间序列分析领域,一个时间序列可以被视为趋势项、季节项、周期项和噪声。对于这4个因素的拆解,有加法模型、乘法模型等,其中加法模型认为这4个因素相加构成了当前时间序列。文章采用了加法模型,认为时间序列由趋势项+季节项构成。为了提取出季节项,文章采用了滑动平均法,通过在原始输入时间序列上每个窗口计算平均值,得到每个窗口的趋势项,进而得到整个序列的趋势项。模型的输入结合Series Decomposition Block模块。Encoder部分输入历史时间序列,Decoder部分的输入包括趋势项和季节项两个部分。趋势项由两部分组成,一部分是历史序列经过Series Decomposition Block分解出的趋势项的后半部分,相当于用历史序列近期的趋势项作为Decoder的初始化;趋势项的另一部分是0填充的,即目前尚不知道的未来序列的趋势项,用0进行填充。季节项和趋势项类似,也是由两部分组成,第一部分为Encoder分解出的近期季节项,用于初始化;第二部分为Encoder序列均值作为填充。
第二个模块是Auto-Correlation Mechanism,是对传统Transformer在时间序列预测场景的升级。Auto-Correlation Mechanism的核心思路是利用时间序列的自相关系数,寻找时间序列最相关的片段。时间序列的自相关系数计算时间序列和其滑动一个步长后的时间序列的相关系数。举例来说,如果一个时间序列是以年为周期,那么序列平移365天后,原序列和平移后的序列相关系数是很高的。
剩余的变种模型包括Informer[10]、FEDformer[11]等,采用的想法类似。一就是要把复杂度、计算量、计算时间降下来,这也是所有Transformer类模型的问题,另外就是采取如傅里叶变换等操作,在频域使用Transformer,帮助Transformer更好的学习全局信息。接着一些方法采取无监督方式,对于输入的多元时间序列,会mask掉一定比例的子序列(不能太短),并且每个变量分别mask,而不是mask掉同一段时间的所有变量从而进行预训练。剩下的较多方法便是如AutoFormer一样进行类似分解。再有方法像各种LSTM、CNN、GNN、GCN等与Transformer进行一个叠加操作,提取每个点上下文信息的同时,有的还可以充当Position Encoding。未来Transformer类模型在时间序列任务上定会大放光彩。
- 时间序列的多步预测问题
我之前做过的那个时间序列任务是,留出训练集的最后一段时间作为验证集,在这部分数据上做评价。那个场景中就是用前n个月训练,n+1月进行验证较为可靠。当然也可能会出现其他都不变的情况下用N-1个月训练,用N+1验证比用N个月训练,N+1验证的结果要好的情况。在时间序列预测中,预测的horizon往往是一段时间,比如下一周的股票价格、销量、天气等等,但是,在将时间序列数据转化为有监督学习时,往往会构造很多特征,其中一个很重要的就是滞后值特征和滑动窗口统计特征,一旦加入这些特征,就会导致有监督学习的多步预测出现问题。
目前针对时间序列预测的多步输出问题中针对机器学习的有直接法、递归法还有直接-递归混合法,这几种方法在kaggle上都有应用,也没有说哪种方法就一定好,这个就需要具体问题具体分析,多尝试一下才能知道在某种问题上哪种方法表现更好。大体上采用的方法为使用lag信息,用一段时间的数据构建训练一个模型并对一段时间进行预测,预测值可作为下一个时间段的特征。会有累计误差的存在但多步预测确实可以保证精度的实现。多输出策略对比于多步预测如采用seq2seq模型在一些实际问题也有着出色的效果。
参考文献:
1. Ke, G., et al., Lightgbm: A highly efficient gradient boosting decision tree. 2017. 30.
2. Chen, T. and C. Guestrin. Xgboost: A scalable tree boosting system. in Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016.
3. Prokhorenkova, L., et al., CatBoost: unbiased boosting with categorical features. 2018. 31.
4. Oord, A.v.d., et al., Wavenet: A generative model for raw audio. 2016.
5. Arik, S.Ö. and T. Pfister. Tabnet: Attentive interpretable tabular learning. in Proceedings of the AAAI Conference on Artificial Intelligence. 2021.
6. Gers, F.A., J. Schmidhuber, and F.J.N.c. Cummins, Learning to forget: Continual prediction with LSTM. 2000. 12(10): p. 2451-2471.
7. Vaswani, A., et al., Attention is all you need. 2017. 30.
8. Taylor, S.J. and B.J.T.A.S. Letham, Forecasting at scale. 2018. 72(1): p. 37-45.
9. Wu, H., et al., Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. 2021. 34: p. 22419-22430.
10. Zhou, H., et al. Informer: Beyond efficient transformer for long sequence time-series forecasting. in Proceedings of the AAAI Conference on Artificial Intelligence. 2021.
11. Zhou, T., et al., FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. 2022.
12. arXiv:1409.3215v3 [cs.CL] 14 Dec 2014
13. GitHub - AIStream-Peelout/flow-forecast: Deep learning PyTorch library for time series forecasting, classification, and anomaly detection (originally for flood forecasting).(Flow Forecast是一个开源的时序预测框架,它包含了以下模型:Vanilla LSTM (LSTM)、SimpleTransformer、Multi-Head Attention、Transformer with a linear decoder、DARNN、Transformer XL、Informer、DeepAR、DSANet 、SimpleLinearModel等等)