PyTorch深度学习入门笔记(十一)神经网络池化层
我是 雪天鱼,一名FPGA爱好者,研究方向是FPGA架构探索和数字IC设计。
关注公众号【集成电路设计教程】,获取更多学习资料,并拉你进“IC设计交流群”。
QQIC设计&FPGA&DL交流群 群号:866169462。
课程学习笔记,课程链接
文章目录
- 一、MaxPool2d简介
- 二、代码演示
一、MaxPool2d简介
这一节讲解池化层。还是通过Pytorch官方文档来进行学习:
打开 torch.nn的pooling layers,最常用的函数是nn.MaxPool2d,需要提供的参数如下所示:


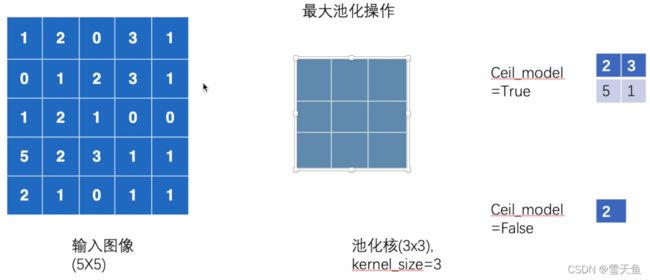
kernel_size是指窗口的大小,可以是int或是tuple数据类型dilation:改变窗口的间隔。如下图所示,蓝色是输入,灰色是窗口,可以看到窗口是3*3大小,且间隔即dilation为1。一般情况下不需要进行设置。

cell_mode::当cell_mode为 True时,将用cell模式代替floor模式去计算输出。简单解释下cell模式和floor模式:

Floor 模式就是将数值向下取整,如 2.31 取值为 2 ,而 Cell 模式就是将数值向上取整,如 2.31 取值为 3。在最大池化操作中,当为cell模式时,如果窗口和输入未完全重合,也会进行一次计算;为floor模式则会放弃此次计算。
最大池化就是取窗口中最大的数,例:
二、代码演示
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
# N C H W
input = torch.reshape(input, (-1, 1, 5, 5))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
net1 = Net()
output = net1(input)
print(output)
输出结果:
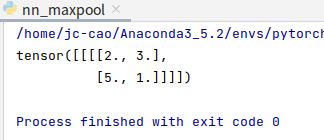
与之前的推算一致。
最大池化的作用是在保存数据特征的前提下去减小数据量。
再看一个例子:
示例:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
net1 = Net()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = net1(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
用tensorboard查看结果:
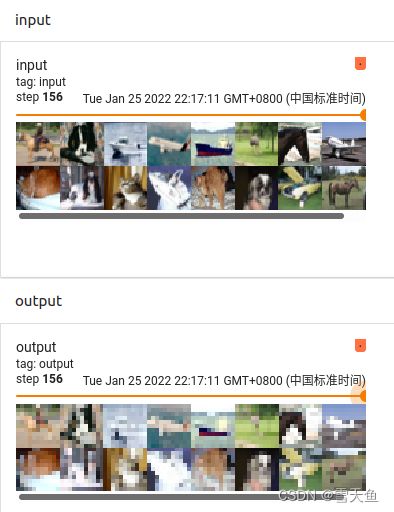
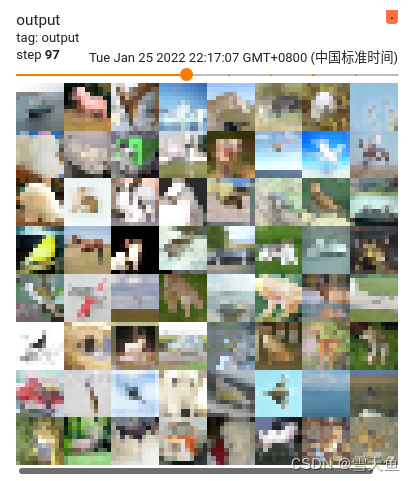
可以看出最大池化操作的直接效果就是将图片的像素给降低了,即模糊了,只保留原图像的最突出的特征。