VITS论文阅读
论文链接:Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
文章目录
- 摘要
- 简介
- 方法
-
- Variational Inference
-
- 概述
- 重建损失
- KL散度
- Alignment Estimation
-
- 单调对齐搜索/MONOTONIC ALIGNMENT SEARCH
- 基于文本的持续时间预测
- 对抗训练
- 最后的损失
- 模型架构
-
- 后验编码器
- 先验编码器
- 解码器
- 判别器
- 随机持续时间预测器
- 实验
-
- 数据集
- 预处理
- 训练
- 对比实验设置
- 结果
-
- 语音合成质量
- Mutil-Speakers TTS的泛化
- 语音变化
- 合成速度
- 相关工作
-
- 端到端TTS
- VAE
- 非自回归TTS的持续时间预测
- 结论
- 补充材料
-
- A.单调对齐搜索
- B.模型配置
-
- B.1.先验编码器和后验编码器
- B.2.解码器和判别器
- B.3.随机持续时间预测器
- C.并排评估
- D.语音转换
摘要
最近有人提出了几个支持单阶段训练和并行采样的端到端文本到语音(TTS)模型,但它们的样本质量与两阶段TTS系统的样本质量不匹配。这项工作提出一种并行的端到端TTS方法,比目前的两级模型产生更自然的探测音频。本方法采用归一化流程扩充的变分推理(基于归一化流的变分增广)和对抗性训练过程,提高了生成式建模的表达能力。还提出了一个随机持续时间预测器来从输入文本中合成具有不同节奏的语音。通过潜在变量的不确定性建模和随机持续时间预测器,提出的方法表达了自然的一对多关系,即文本输入可以以不同音高和节奏的多种方式说话。在LJSpeech上的MOS表明,该方法优于最佳的公开可用TTS系统,并实现了与gt数据相当的MOS。
简介
文本到语音 (TTS) 系统通过几个组件从给定文本合成原始语音波形。随着深度神经网络的快速发展,除了文本规范化和音素化等文本预处理之外,TTS 系统管道已被简化为两阶段生成建模。第一阶段是从预处理的文本中生成中间语音表示,例如mel谱图或语言特征;第二阶段是以中间表示为条件生成原始波形。每个两级管道的模型都是独立开发的。
基于神经网络的自回归TTS系统已显示出合成逼真语音的能力,但它们的顺序生成过程使得难以充分利用现代并行处理器。为了克服这一限制并提高合成速度,已经提出了几种非自回归方法。在文本到频谱图生成步骤中,尝试从预训练的自回归教师网络中提取注意力图,以降低学习文本和频谱图之间对齐的难度。最近,基于可能性的方法通过估计或学习最大化目标梅尔谱图可能性的对齐,进一步消除了对外部对齐器的依赖。同时,生成对抗网络 (GAN) 已在第二阶段模型中进行了探索。基于GAN的前馈网络具有多个判别器,每个判别器区分不同尺度或周期的样本,实现高质量的原始波形合成。
尽管并行TTS系统取得了进展,但两阶段管道仍然存在问题,因为它们需要顺序训练或微调以进行高质量生产,其中后期模型使用早期模型的生成样本。此外,它们对预定义的中间特征的依赖妨碍了应用学习到的隐藏表示来进一步提高性能。最近,一些工作,即FastSpeech 2s和EATS,提出了有效的端到端训练方法,例如对短音频片段而不是整个波形进行训练,利用mel谱图解码器来帮助文本表示学习,并设计一个专门的谱图损失来缓解目标和生成的语音之间的长度不匹配。然而,尽管通过利用学习的表示可能会提高性能,但它们的合成质量仍落后于两阶段系统。
这项工作提出了一种并行的端到端TTS方法,它比当前的两阶段模型生成更自然的声音。使用变分自动编码器 (VAE, Auto-Encoding Variational Bayes),通过潜在变量连接TTS系统的两个模块,以实现高效的端到端学习。为了提高本方法的表达能力以便可以合成高质量的语音波形,将归一化流应用于条件先验分布和波形域的对抗训练。除了生成细粒度的音频外,TTS系统表达一对多的关系也很重要,在这种关系中,文本输入可以以多种方式说出,具有不同的变化(例如,音高和持续时间)。为了解决一对多的问题,还提出了一个随机持续时间预测器,以从输入文本中合成具有不同节奏的语音。通过对潜在变量的不确定性建模和随机持续时间预测器,提出的方法捕获了无法用文本表示的语音变化(随机的原因是因为随机预测器是一个基于flow的vae架构,预测的是一个分布,使用时需要随机采样)。
与具有HiFi-GAN的最佳公开TTS系统Glow-TTS相比,本方法获得了更自然的语音和更高的采样效率。官方源码:https://github.com/jaywalnut310/vits
方法
所提出的方法主要在前三个小节中描述:有条件的VAE公式;从变分推断得出的对齐估计;提高合成质量的对抗性训练。图1a和1b分别显示了本文方法的训练和推理过程。将提出的方法称为变分推理与端到端文本到语音的对抗学习(VITS)。

Variational Inference
概述
VITS可以表示为条件VAE,其目标是最大化变分下限,也称为置信下限(ELBO),是一个不可解的对数似然 log p θ ( x ∣ c ) \log p_θ(x|c) logpθ(x∣c):
log p θ ( x ∣ c ) ≥ E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) − log q ϕ ( z ∣ x ) p θ ( z ∣ c ) ] \log p_θ(x|c)≥E_{q_{\phi}(z|x)}[\log p_θ(x|z)-\log\frac{q_{\phi}(z|x)}{p_θ(z|c)}] logpθ(x∣c)≥Eqϕ(z∣x)[logpθ(x∣z)−logpθ(z∣c)qϕ(z∣x)]
其中 p θ ( z ∣ c ) p_θ(z|c) pθ(z∣c)表示给定条件 c c c的潜在变量 z z z的先验分布, p θ ( x ∣ z ) p_θ(x|z) pθ(x∣z)是数据点 x x x的似然函数, q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x)是一个近似的后验分布。训练损失就是负ELBO,可以看成是重构损失(- log p θ ( x ∣ c ) \log p_θ(x|c) logpθ(x∣c))和KL散度( log q ϕ ( z ∣ x ) − l o g p θ ( z ∣ c ) \log{q_{\phi}(z|x)}-log{p_θ(z|c)} logqϕ(z∣x)−logpθ(z∣c))的和,其中 z z z符合后验分布 q ϕ ( z ∣ x ) q_{\phi}(z|x) qϕ(z∣x)。
重建损失
作为重建损失中的目标数据点,使用梅尔谱图而不是原始波形,用 x m e l x_{mel} xmel表示。通过解码器将潜在变量 z z z上采样到波形域 y ^ \hat{y} y^并将 y ^ \hat{y} y^变换到梅尔谱图域 x ^ m e l \hat{x}_{mel} x^mel。然后将预测和目标梅尔谱图之间的 L 1 L1 L1损失用作重建损失: L r e c o n = ∣ ∣ x m e l − x ^ m e l ∣ ∣ 1 L_{recon} = ||x_{mel} - \hat{x}_{mel}||_1 Lrecon=∣∣xmel−x^mel∣∣1。
这可以看作是假设数据分布的拉普拉斯分布并忽略常数项的最大似然估计。定义了 mel谱图域中的重建损失,以通过使用近似人类听觉系统响应的mel谱图尺度来提高感知质量。请注意,原始波形的梅尔谱图估计不需要可训练的参数,因为它只使用 STFT 和线性投影到梅尔尺度上。此外,估计仅在训练期间使用,而不是在推理期间使用。在实践中,不会对整个潜在变量 z 进行上采样,而是使用部分序列作为解码器的输入,这是用于高效端到端训练的窗口生成器训练。
KL散度
先验编码器的输入条件 c c c由从文本中提取的音素 c t e x t c_{text} ctext以及音素和潜在变量之间的对齐 A A A组成。对齐矩阵 A A A是一个尺寸为 ∣ c t e x t ∣ × ∣ z ∣ |c_{text}|×|z| ∣ctext∣×∣z∣的硬单调注意矩阵,表示每个输入音素扩展多长时间以与目标语音时间对齐。因为对齐没有真实标签,必须在每次训练迭代时估计对齐。在问题设置中,目标是为后编码器提供更高分辨率的信息。因此,使用目标语音 x l i n x_{lin} xlin的线性尺度频谱图而不是mel频谱图作为输入。请注意,修改后的输入不违反变分推理的属性。KL散度是: L k l = l o g q ϕ ( z ∣ x l i n ) − l o g p θ ( z ∣ c t e x t , A ) , z ∽ q ϕ ( z ∣ x l i n ) = N ( z ; μ ϕ ( x l i n ) , σ ϕ ( x l i n ) ) L_{kl}=logq_{\phi}(z|x_{lin})-logp_θ(z|c_{text},A), z \backsim q_{\phi}(z|x_{lin})=N(z;\mu_{\phi}(x_{lin}),\sigma_{\phi}(x_{lin})) Lkl=logqϕ(z∣xlin)−logpθ(z∣ctext,A),z∽qϕ(z∣xlin)=N(z;μϕ(xlin),σϕ(xlin))
分解的正态分布用于参数化先验和后验编码器。发现增加先验分布的表现力对于生成真实样本很重要。因此,应用归一化流 f θ f_θ fθ,它允许在分解的正态先验分布之上,按照变量变化的规则将简单分布可逆地转换为更复杂的分布:
p θ ( z ∣ c ) = N ( f θ ( z ) ; μ θ ( c ) , σ θ ( c ) ) ∣ d e t ∂ f θ ( z ) ∂ z ∣ , c = [ c t e x t , A ] p_θ(z|c)=N(f_θ(z);\mu_θ(c), \sigma_θ(c))|det\frac{\partial f_θ(z)}{\partial z}|, c=[c_{text}, A] pθ(z∣c)=N(fθ(z);μθ(c),σθ(c))∣det∂z∂fθ(z)∣,c=[ctext,A]
Alignment Estimation
单调对齐搜索/MONOTONIC ALIGNMENT SEARCH
为了估计输入文本和目标语音之间的对齐 A,采用单调对齐搜索 (MAS,Glow-TTS),这是一种搜索对齐的方法,该方法可以最大化由归一化流 f 参数化的数据的可能性:
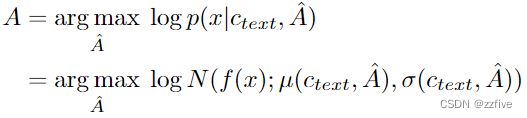
其中由于人类按顺序阅读文本而不跳过任何单词,因此候选对齐被限制为单调且不可跳过。为了找到最佳对齐方式,Glow-TTS中使用动态规划。在本方法的设置中直接应用 MAS 很困难,因为目标是 ELBO,而不是精确的对数似然。因此,本方法重新定义 MAS 以找到最大化 ELBO 的对齐方式,这简化为找到最大化潜在变量 z 的对数似然的对齐方式:
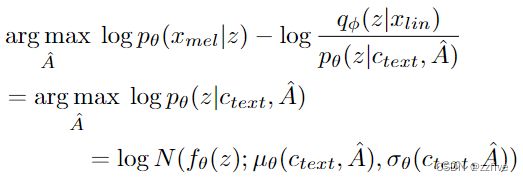
附录 A 包括 MAS 的伪代码。
基于文本的持续时间预测
可以通过对估计的对齐的每一行中的所有列求和,即 ∑ j A i , j \sum_jA_{i,j} ∑jAi,j来计算每个输入标记 d i d_i di的持续时间。如Glow-TTS所提出的,持续时间可用于训练确定性持续时间预测器,但它无法表达一个人每次以不同语速说话的方式。为了生成类似人类的语音节奏,设计了一个随机持续时间预测器,以便其样本遵循给定音素的持续时间分布。随机持续时间预测器是基于流的生成模型,通常通过最大似然估计进行训练。然而,最大似然估计的直接应用是困难的,因为每个输入音素的持续时间是 1) 一个离散整数,需要对其进行反量化以使用连续归一化流,以及 2) 一个标量,它可以防止高维变换可逆性。应用变分去量化和变分数据增强来解决这些问题。具体来说,引入了两个随机变量 u u u和 ν ν ν,它们具有与持续时间序列 d d d相同的时间分辨率和维度,分别用于变分去量化和变分数据增强。将 u u u的支持限制为 [0, 1),以便 d − u d - u d−u成为正实数序列,并且将 ν ν ν和 d d d逐个通道连接以形成更高维的潜在表示;通过一个近似的后验分布 q ϕ ( u , ν ∣ d , c t e x t ) q_{\phi}(u, ν|d, c_{text}) qϕ(u,ν∣d,ctext)对这两个变量进行采样。由此产生的目标是音素持续时间的对数似然的变分下限:
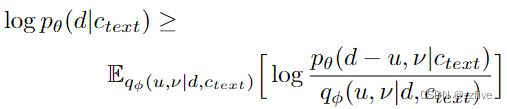
训练损失 L d u r L_{dur} Ldur是负变分下限。将停止梯度算子应用于输入条件,以防止对输入的梯度进行反向传播,以便持续时间预测器的训练不会影响其他模块的训练。采样过程相对简单,通过随机时长预测器的逆变换从随机噪声中采样音素时长,然后将其转换为整数
对抗训练
为了在学习系统中采用对抗性训练,增加了一个鉴别器D,该鉴别器D区分由解码器G产生的输出和地面真实波形y。在这项工作中,使用了两种在语音合成中成功应用的损失类型:用于对抗性训练的最小二乘损失函数,以及用于训练生成器的附加特征匹配损失:
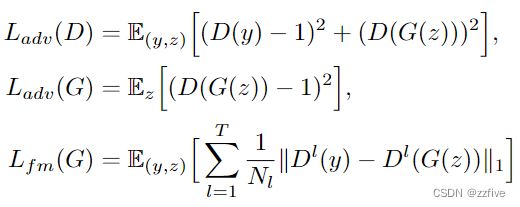
其中, T T T表示鉴别器中的总层数,而 D l D^l Dl输出具有 N l N_l Nl个特征的鉴别器的第 l l l层的特征映射。值得注意的是,特征匹配损失可以被视为在建议作为VAE的基于元素的重建损失的替代方案的鉴别器的隐藏层中测量的重建损失。
最后的损失
结合VAE和GAN训练,有条件的VAE训练的总损失可以表示如下:
L v a e = L r e c o n + L k l + L d u r + L a d v ( G ) + L f m ( G ) L_{vae}=L_{recon}+L_{kl}+L_{dur}+L_{adv}(G)+L_{fm}(G) Lvae=Lrecon+Lkl+Ldur+Ladv(G)+Lfm(G)
模型架构
所提出模型的整体架构由后验编码器、先验编码器、解码器、鉴别器和随机持续时间预测器组成。后验编码器和鉴别器仅用于训练,不用于推理。架构细节可在附录 B 中找到。
后验编码器
对于后验编码器,使用 WaveGlow和 Glow-TTS中使用的非因果 WaveNet 残差块。 WaveNet 残差块由具有门控激活单元和skip连接的扩张卷积层组成。WaveNet 残差块上方的线性投影层产生正态后验分布的均值和方差。对于mutil-speakers的情况,在残差块中使用全局调节来添加说话人嵌入。
先验编码器
先验编码器由处理输入音素 c t e x t c_{text} ctext的文本编码器和提高先验分布灵活性的标准化流 f θ f_θ fθ组成。文本编码器是一种Transformer编码器,它使用相对位置表示而不是绝对位置编码。可以通过文本编码器和文本编码器上方的线性投影层从 c t e x t c_{text} ctext中获取隐藏表示 h t e x t h_{text} htext,该线性投影层产生用于构造先验分布的均值和方差。归一化流是由一堆WaveNet残差块组成的仿射耦合层堆栈。为简单起见,将归一化流设计为雅可比行列式为1的体积不变的变换。对于mutil-speakers设置,通过全局调节将speaker嵌入添加到归一化流中的残差块中。
解码器
解码器本质上是HiFi-GAN V1生成器。它由一堆转置卷积组成,每个转置卷积后面都有一个多感受野融合模块(MRF)。MRF的输出是具有不同感受野大小的残差块的输出之和。对于mutil-speakers设置,添加了一个线性层来转换speaker嵌入并将其添加到输入潜在变量 z z z。
判别器
遵循HiFi-GAN中提出的多周期鉴别器的鉴别器架构。多周期鉴别器是基于马尔可夫窗口的子鉴别器的混合体,每个子鉴别器都对输入波形的不同周期模式进行操作。
随机持续时间预测器
随机持续时间预测器根据条件输入 h t e x t h_{text} htext估计音素持续时间的分布。为了随机持续时间预测器的有效参数化,将残差块与扩张和深度可分离的卷积层堆叠在一起。还将neural spline flows应用到耦合层,它通过使用单调有理二次样条采用可逆非线性变换的形式。与常用的仿射耦合层相比,neural spline flows以相似数量的参数提高了变换表达能力。对于mutil-speakers设置,添加一个线性层来转换speaker嵌入并将其添加到输入 h t e x t h_{text} htext。
实验
数据集
对两个不同的数据集进行了实验。使用LJSpeech数据集与其他公开可用的模型和 VCTK 数据集进行比较,以验证本模型是否可以学习和表达不同的语音特征。LJSpeech数据集由单个speaker的13100个短音频片段组成,总长度约为24小时。音频格式是16位 PCM,采样率为22 kHz,使用它没有任何操作。将数据集随机分为训练集(12,500 个样本)、验证集(100 个样本)和测试集(500 个样本)。VCTK 数据集包含大约 44,000 个简短的音频片段,由 109 位以不同口音为母语的英语人士发出。音频剪辑的总长度约为 44 小时。音频格式为 16 位 PCM,采样率为 44 kHz。将采样率降低到 22 kHz。将数据集随机分为训练集(43,470 个样本)、验证集(100 个样本)和测试集(500 个样本)。
预处理
使用可以通过短时傅里叶变换(STFT)从原始波形中获得的线性频谱图,作为后编码器的输入。变换的 FFT 大小、窗口大小和跳数大小分别设置为 1024、1024 和 256。使用 80 波段 mel 尺度谱图进行重建损失,这是通过将 mel 滤波器组应用于线性谱图获得的。使用国际音标(IPA)序列作为先验编码器的输入,使用开源软件Bernard将文本序列转换为IPA音素序列,并在Glow-TTS实现后将转换后的序列点缀一个空白令牌。
训练
使用AdamW优化器训练网络, β 1 = 0.8 , β 2 = 0.99 β_1=0.8,β_2=0.99 β1=0.8,β2=0.99,权重衰减 λ = 0.01 λ=0.01 λ=0.01。在初始学习速率为 2 × 1 0 − 4 2×10^{−4} 2×10−4的情况下,每个epoch的学习速率衰减按 0.99 9 1 / 8 0.999^{1/8} 0.9991/8倍进行。在先前的工作(FastSpeech2和EATS)的基础上,采用了加窗生成器训练,这是一种只生成部分原始波形的方法,以减少训练时间和训练期间的内存使用。随机提取窗口大小为32的潜在表示片段,以提供给解码器,而不是提供整个潜在表示,并从GT原始波形中提取相应的音频片段作为训练目标。在4个NVIDIA V100 gpu上使用混合精确训练。批处理大小设置为每个GPU 64个,模型训练到800k步。
对比实验设置
将提出的模型与最好的公开模型进行了比较,使用自回归模型Tacotron 2和基于流的非自回归模型Glow-TTS作为第一阶段模型,HiFi-GAN作为第二阶段模型;使用他们的公共实现和预先训练的权重。由于两阶段 TTS 系统理论上可以通过顺序训练实现更高的合成质量,因此将微调的 HiFi-GAN 包含在第一阶段模型的预测输出中,最高可达 100k 步。凭经验发现,在教师强制模式下使用从 Tacotron 2 生成的梅尔谱图对 HiFi-GAN 进行微调,与使用从 Glow-TTS 生成的梅尔谱图进行微调相比,Tacotron 2 和 GlowTTS 的质量更好,所以将更好的微调 HiFi-GAN 添加到 Tacotron 2 和 Glow-TTS。
由于每个模型在采样过程中都具有一定程度的随机性,因此在整个实验过程中固定了控制每个模型随机性的超参数。 Tactron 2 的 pre-net 中 dropout 的概率设置为 0.5。对于 GlowTTS,先验分布的标准差设置为 0.333。对于 VITS,随机持续时间预测器的输入噪声的标准偏差设置为 0.8,将比例因子 0.667 乘以先验分布的标准偏差。
结果
语音合成质量
进行了众包 MOS 测试来评估质量。评分者聆听随机选择的音频样本,并以从 1 到 5 的 5 分等级对其自然度进行评分。评分者被允许对每个音频样本进行一次评估,对所有音频片段进行归一化以避免幅度差异对分数的影响。这项工作中的所有质量评估都是以这种方式进行的。
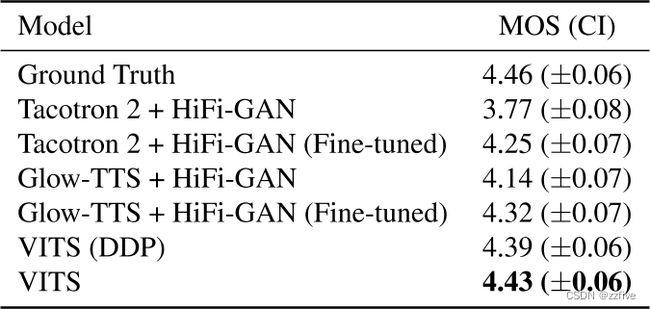
评估结果如表1所示。VITS优于其他 TTS 系统,并实现了与 ground truth 相似的 MOS。 VITS (DDP) 采用与 GlowTTS 中相同的确定性持续时间预测器架构,而不是随机持续时间预测器,在MOS评估中的TTS系统中得分第二高。这些结果表明:1)随机持续时间预测器产生的音素持续时间比确定性持续时间预测器更真实;2)本文的端到端训练方法是一种比其他TTS模型更有效的方法,即使保持相似的持续时间预测器架构。
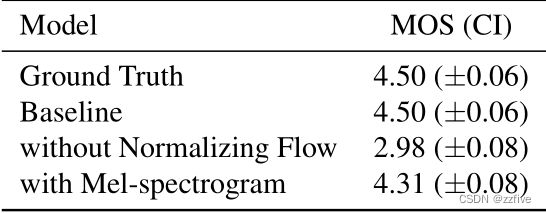
进行了消融研究,以证明本文的方法的有效性,包括先验编码器中的归一化流和线性尺度谱图后输入。消融研究中的所有模型都被训练到300k步。结果如表2所示。去除先验编码器中的归一化流,结果比基线降低1.52 MOS,表明先验分布的灵活性显著影响合成质量。用mel谱图代替后输入的线性尺度谱图,其质量下降(-0.19 MOS),表明高分辨率信息对VITS的合成质量是有效的。
Mutil-Speakers TTS的泛化
为了验证提出的模型可以学习和表达不同的语音特征,将模型与 Tacotron 2、Glow-TTS 和 HiFi-GAN 进行了比较,它们展示了扩展到mutil-speakers语音合成的能力。在 VCTK 数据集上训练模型,将说话人嵌入添加到模型中。对于 Tacotron 2,广播了扬声器嵌入并将其与编码器输出连接,对于 Glow-TTS,在之前的工作之后应用了全局调节。评估结果如表 3 所示,提出的模型比其他模型实现了更高的 MOS,表明本模型以端到端的方式学习和表达各种语音特征。

语音变化
验证了随机持续时间预测器产生了多少不同长度的语音,以及合成样本有多少不同的语音特征。
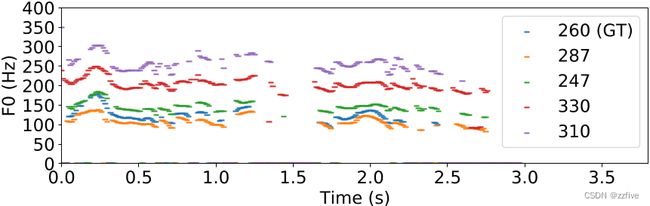
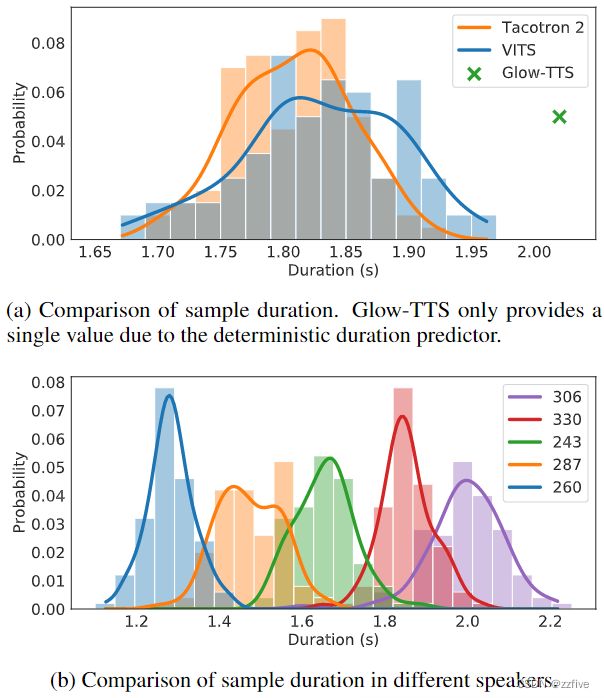
与Flowtron类似,这里的所有样本都是从一句话“How much variation is there?”中生成的。图2a显示了每个模型生成的100个话语长度的直方图。由于确定性的持续时间预测器,Glow-TTS只生成固定长度的话语,而模型中的样本遵循与Tacotron 2相似的长度分布。图2b显示了在mutil-speakers设置下,提出的模型中使用五个说话者身份生成的100个话语的长度,这意味着模型学习了speaker依赖的音素持续时间。图3中用YIN算法提取的10个话语的F0轮廓显示,本模型生成了具有不同音高和节奏的语音,图3d中由每个不同speaker生成的五个样本显示,模型对每个speaker表达了非常不同的长度和音高。值得注意的是,Glow-TTS可以通过增加先验分布的标准差来增加基音的多样性,但相反,它会降低合成质量。
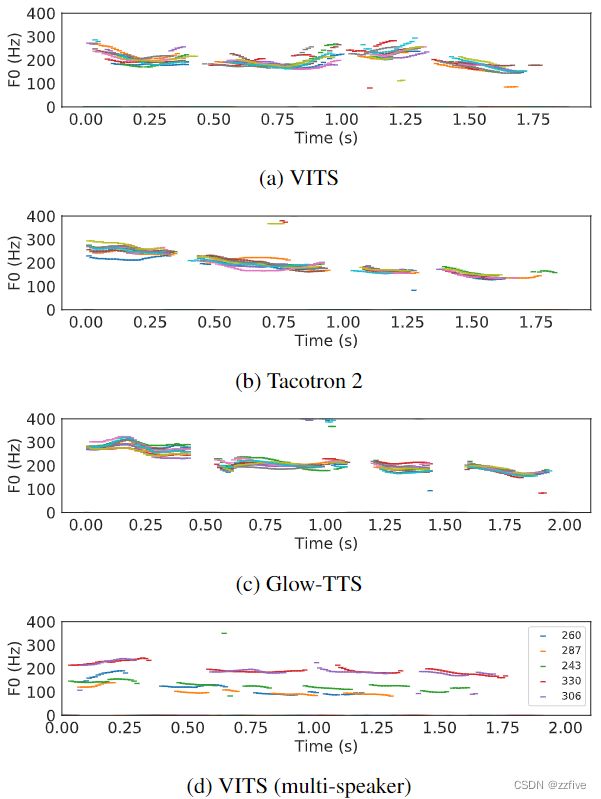
合成速度
将模型的合成速度与并行的两阶段 TTS 系统 Glow-TTS 和 HiFi-GAN 进行了比较。测量了整个过程的同步经过时间,以从音素序列生成原始波形,其中 100 个句子从 LJSpeech 数据集的测试集中随机选择。使用单个 NVIDIA V100 GPU,批量大小为 1。结果如表 4 所示。由于提出的模型不需要模块来生成预定义的中间表示,因此它的采样效率和速度得到了极大的提高。

相关工作
端到端TTS
目前,具有两阶段管道的神经 TTS 模型可以合成类人语音;但是,它们通常需要使用第一阶段模型输出训练或微调的声码器,这会导致训练和部署效率低下。它们也无法获得端到端方法的潜在好处,这种方法可以使用学习的隐藏表示而不是预定义的中间特征。最近,单级端到端 TTS 模型被提出来解决直接从文本生成原始波形的更具挑战性的任务,这些原始波形包含比梅尔频谱图更丰富的信息(例如,高频响应和相位)。FastSpeech 2s (Ren et al., 2021) 是 FastSpeech 2 的扩展,它通过采用对抗训练和帮助学习文本表示的辅助 mel 频谱图解码器实现端到端并行生成。然而,为了解决一对多的问题,FastSpeech 2 必须从用作训练输入条件的语音中提取音素持续时间、音高和能量。EATS 也采用了对抗性训练和可区分的对齐方案。为了解决生成语音和目标语音之间的长度不匹配问题,EATS采用了通过动态规划计算的软动态时间规整损失。Wave Tacotron将标准化流与 Tacotron 2 相结合,形成端到端结构,但仍保持自回归。上述所有端到端 TTS 模型的音频质量都低于两阶段模型。
与上述端到端模型不同,通过使用条件 VAE,本模型 1) 学习直接从文本中合成原始波形,而不需要额外的输入条件,2) 使用动态编程方法 MAS 来搜索最佳对齐而不是与计算损失相比,3) 并行生成样本,4) 优于公开可用的最佳两阶段模型。
VAE
VAEs是最广泛使用的基于似然的深度生成模型之一。对 TTS 系统采用有条件的 VAE。条件 VAE 是一种条件生成模型,其中观察到的条件调节用于生成输出的潜在变量的先验分布。BVAE-TTS基于双向 VAE并行生成梅尔谱图。与之前将 VAE 应用于第一阶段模型的工作不同,本论文将VAE应用于并行的端到端 TTS 系统。为了提高先验分布的表示能力,本文将归一化流添加到条件先验网络中,从而生成更真实的样本。
与本论文工作类似,FlowSeq是一种条件VAE,在用于非自回归神经机器翻译的条件先验网络中对流进行归一化。然而,本文提出的模型可以显式地将潜在序列与源序列对齐这一事实与 FlowSeq 不同,后者需要通过注意力机制学习隐式对齐。本文的模型通过 MAS 将潜在序列与时间对齐的源序列匹配,从而消除了将潜在序列转换为标准正态随机变量的负担,这允许更简单的标准化流架构。
非自回归TTS的持续时间预测
自回归 TTS 模型通过其自回归结构和一些技巧(包括在推理和启动期间保持退出概率)生成具有不同节奏的多样化语音。另一方面,并行 TTS 模型依赖于确定性持续时间预测。这是因为并行模型必须在一条前馈路径中预测目标音素持续时间或目标语音的总长度,这使得难以捕捉语音节奏的相关联合分布。本工作提出了一种基于流的随机持续时间预测器,它学习估计的音素持续时间的联合分布,从而并行生成不同的语音节奏。
结论
本工作提出了一个并行 TTS 系统 VITS,它可以以端到端的方式学习和生成。进一步引入了随机持续时间预测器来表达不同的语音节奏。由此产生的系统直接从文本中合成自然发音的语音波形,而无需经过预定义的中间语音表示。实验结果表明,本方法优于两阶段 TTS 系统并达到接近人类的质量。希望所提出的方法将用于许多使用两阶段 TTS 系统的语音合成任务,以实现性能提升并享受简化的训练过程。同事指出,尽管本方法在 TTS 系统中集成了两个分离的生成管道,但仍然存在文本预处理问题。研究语言表示的自我监督学习可能是删除文本预处理步骤的一个可能方向。
补充材料
A.单调对齐搜索
在图4中展示了MAS的伪代码。虽然搜索最大化ELBO的对齐而不是数据的精确对数似然,但可以使用 Glow-TTS 的 MAS 实现。

B.模型配置
主要描述 VITS 的新增部分,因为对模型的几个部分遵循Glow-TTS和HiFi-GAN的配置:使用与Glow-TTS相同的Transformer编码器和WaveNet残差块;解码器和多周期鉴别器分别与HiFi-GAN的生成器和多周期鉴别器相同,只是为解码器使用不同的输入维度并附加一个子鉴别器。
B.1.先验编码器和后验编码器
先验编码器中的归一化流是由4个仿射耦合层叠加而成,每个耦合层由4个WaveNet残差块组成。由于限制仿射耦合层为体积保持变换,所以耦合层不产生尺度参数。后验码器由16个WaveNet残差块组成,采用线性尺度对数幅度谱图并产生具有192个通道的潜在变量。
B.2.解码器和判别器
解码器的输入是先验或后验编码器生成的潜在变量,因此解码器的输入通道大小为 192。对于解码器的最后一个卷积层,移除了一个偏置参数,因为它在混合精度训练期间导致不稳定的梯度尺度。
对于鉴别器,HiFi-GAN使用包含五个周期子鉴别器[2,3,5,7,11]的多周期鉴别器和包含三个子鉴别器的多尺度鉴别器。为了提高训练效率,只留下操作于原始波形的多尺度鉴别器的第一个子鉴别器,而丢弃操作于平均池波形的两个子鉴别器。由此得到的鉴别器可以看作具有周期[1,2,3,5,7,11]的多周期鉴别器。
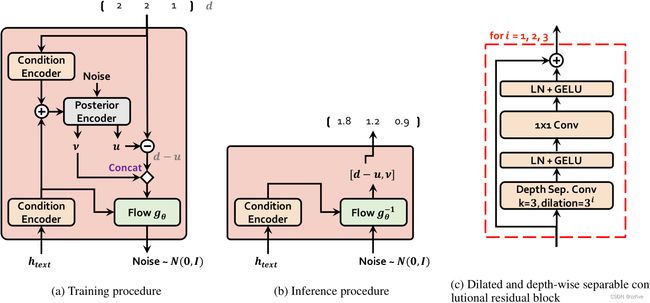
B.3.随机持续时间预测器
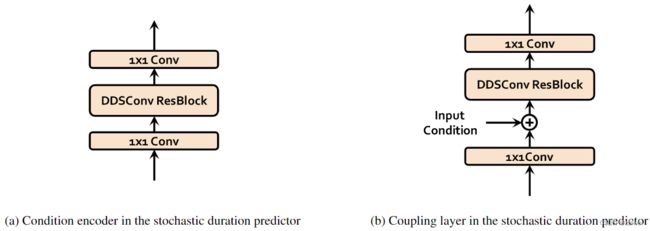
图5a和5b分别显示了随机持续时间预测器的训练和推理过程。随机持续时间预测器的主要构建块是膨胀和深度可分离卷积 (DDSConv) 残差块,如图5 所示。DDSConv块中的每个卷积层后跟一个层归一化层和 GELU 激活函数。选择使用扩张和深度可分离的卷积层来提高参数效率,同时保持较大的感受野大小。
持续时间预测器中的后验编码器和归一化流模块是基于流的神经网络,具有相似的架构。不同之处在于后验编码器将一个高斯噪声序列转化为两个随机变量 ν ν ν和 u u u来表达近似的后验分布 q ϕ ( u , ν ∣ d , c t e x t ) q_{\phi}(u, ν|d, c_{text}) qϕ(u,ν∣d,ctext),归一化流模块将 d − u d-u d−u和 ν ν ν转化为高斯噪声序列来表达增强和去量化数据日志 p θ ( d − u , ν ∣ c t e x t ) p_θ(d − u, ν|c_{text}) pθ(d−u,ν∣ctext)。
所有输入条件都通过条件编码器进行处理,每个条件编码器由两个 1x1 卷积层和一个 DDSConv 残差块组成。后编码器和归一化流模块有四个耦合层的神经样条流。每个耦合层首先通过 DDSConv 模块处理输入和输入条件,并生成 29 个通道参数,用于构造 10 个有理二次函数。将所有耦合层和条件编码器的隐藏维度设置为 192。图6a和6b显示了随机持续时间预测器中使用的条件编码器和耦合层的架构。
C.并排评估
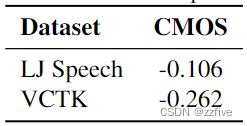
通过对 50 个项目的 500 个评级,在 VITS 和基本事实之间进行了 7 点比较平均意见评分 (CMOS) 评估。提出的模型在 LJ Speech 和 VCTK 数据集上分别实现了 -0.106 和 -0.270 CMOS,如表 5 所示。这表明尽管模型优于最好的公开可用的 TTS 系统、Glow-TTS 和 HiFi-GAN,并且实现了在 MOS 评估中与基本事实相当的分数,与本模型相比,评估者对基本事实的偏好仍然很小。
D.语音转换
在mutil-speakers设置中,不向文本编码器提供说话人身份,这使得从文本编码器估计的潜在变量学习与说话人无关的表示。使用与speaker无关的表示,可以将一个speaker的录音转换为另一个speaker的声音。对于给定的说话人身份 s s s和说话人的话语,可以从相应的话语音频中获得线性频谱图 x l i n x_{lin} xlin。可以通过后编码器和先验编码器中的归一化流将 x l i n x_{lin} xlin换为与说话者无关的表示 e e e:
z ~ q ϕ ( z ∣ x l i n , s ) z~q_{\phi}(z|x_{lin},s) z~qϕ(z∣xlin,s) e = f θ ( z ∣ s ) e=f_θ(z|s) e=fθ(z∣s)
然后,可以通过归一化流 f θ − 1 f^{-1}_θ fθ−1和解码器 G G G的逆变换,从表示 e e e合成目标说话者身份 s ^ \hat{s} s^的语音 y ^ \hat{y} y^:
y ^ = G ( f θ − 1 ( e ∣ s ^ ) ∣ s ^ ) \hat{y}=G(f^{-1}_θ(e|\hat{s})|\hat{s}) y^=G(fθ−1(e∣s^)∣s^)
学习与speaker无关的表示并将其用于语音转换可以看作是Glow-TTS中提出的语音转换方法的扩展。本文的语音转换方法提供原始波形而不是Glow-TTS中的mel谱图。语音转换结果如图 7 所示。它显示了不同音高水平的音高轨迹的相似趋势。