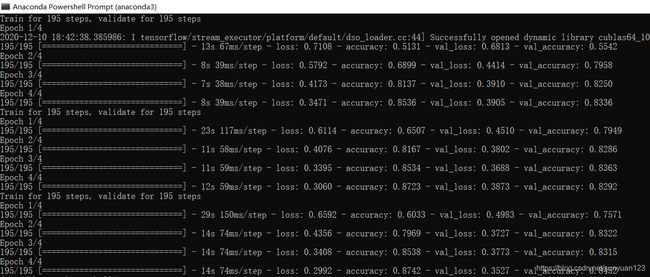
循环神经网络:用RNN训练数据集IMDB得到语句与偏好的关系
代码:
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
from tensorflow.keras.preprocessing import sequence
tf.random.set_seed(114514)
np.random.seed(114514)
# 只记录前10000个常用单词
total_words = 10000
# 令所有句子长度强制为80
max_len = 80
embedding_len = 100
(x_train,y_train), (x_test,y_test) = datasets.imdb.load_data(num_words=total_words)
x_train = sequence.pad_sequences(x_train, maxlen=max_len)
x_test = sequence.pad_sequences(x_test, maxlen=max_len)
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_db = train_db.shuffle(10000).batch(128, drop_remainder=True)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.batch(128, drop_remainder=True)
units = 64
simple_layers = [
layers.Embedding(total_words, embedding_len, input_length=max_len),
layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True),
layers.SimpleRNN(units, dropout=0.5, unroll=True),
layers.Dense(1, activation=tf.nn.sigmoid)
]
lstm_layers = [
layers.Embedding(total_words, embedding_len, input_length=max_len),
layers.LSTM(units, dropout=0.5, return_sequences=True, unroll=True),
layers.LSTM(units, dropout=0.5, unroll=True),
layers.Dense(1, activation=tf.nn.sigmoid)
]
gru_layers = [
layers.Embedding(total_words, embedding_len, input_length=max_len),
layers.GRU(units, dropout=0.5, return_sequences=True, unroll=True),
layers.GRU(units, dropout=0.5, unroll=True),
layers.Dense(1, activation=tf.nn.sigmoid)
]
model_simple = Sequential(simple_layers)
model_simple.compile(optimizer=optimizers.Adam(lr=2e-4), loss=tf.losses.BinaryCrossentropy(), metrics=['accuracy'])
model_simple.fit(train_db, epochs=4, validation_data=test_db)
model_lstm = Sequential(lstm_layers)
model_lstm.compile(optimizer=optimizers.Adam(lr=2e-4), loss=tf.losses.BinaryCrossentropy(), metrics=['accuracy'])
model_lstm.fit(train_db, epochs=4, validation_data=test_db)
model_gru = Sequential(gru_layers)
model_gru.compile(optimizer=optimizers.Adam(lr=2e-4), loss=tf.losses.BinaryCrossentropy(), metrics=['accuracy'])
model_gru.fit(train_db, epochs=4, validation_data=test_db)
实验结果: