【读论文-笔记】——1.沐神读Alexnet
本文是看沐神阅读Alexnet的文章。原文链接如下:
https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
沐神特别提醒,如果我们仔细阅读一篇文章,实际上学到的东西会比零散的博客好很多,因为它是成体系的,而作者会把他的认知全部体现在这篇文章之中。我们作为新研究者,就是要将不同优秀研究者的观点融合,形成自己独特的观点。
1.1 我的Pass1
看标题,本文的任务在ImageNet上做分类,方法是用深度卷积神经网络。
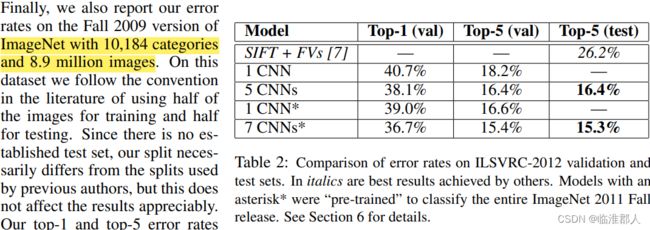
看摘要,似乎是四部分。本文的摘要主要分为两个部分,第一部分是说自己的工作的一个概况,训练了一个CNN去做图像的1000分类。第二部分是结果,在top-1和top-5错误率达到了最好的水平。第三部分是介绍自己的工作,包括网络的参数两、网络的结构,其中的技巧:激活函数(non-saturating neurons),部署技巧(GPU上的高效卷积),正则化技巧(Dropout)。最后又回过头来讲了讲结果,有点没搞懂为什么一开始是个2010比赛,后来又是2012…不过这不重要。
- 这篇摘要的写法很奇怪
看讨论。本文的总结一是在说实验结论,二是在说一些展望。作者的结论包括:
- 自己网络的效果显著;
- 不能轻易拿掉其中的卷积网络层,作者认为网络深度很重要;
- 这篇文章没有结论,而是讨论。。讨论一般是展望,而结论与摘要对应。
相关的展望内容:
3. 可以使用无监督预训练对网络进行初始化;(没想到这么早就有这样的想法了)
4. 在不增加有标签数据时,增加网络的大小,增加算力,可能可以提升网络的性能。(也属于是最近模型越来越暴力的前兆)。
5. 最终可以考虑用卷积网络处理视频数据,因为其中的序列讯息应该非常有用。(现在确实也开始卷视频理解等等内容了)。
看关键图,首先是模型架构。作者在方法部分说,方法是按照本文的技巧重要性组织的,当然这里先不看。。

这是简单的绘制了特征图的大小,以及分两个GPU部署的样子,看注释可以知道模型的通道图的变化大小。

上图是作者提出的ReLu函数比tanh好,并给出一个训练的损失下降的草图。不过图确实很草率了。。
然后就是一些结果图,包括卷积层的“视觉特征”,即频率特征和方向特征(有一说一,没很看懂这个图画的是什么)

最终的结果图,想说明网络在分类层给出的概率较高的物体,语义上也比较相似;以及最后的特征层给出的向量,其欧式距离近,在某种程度上说明了图像的语义相似。
不过这属于是没看解释,只看图中注解,然后我自行脑补的。。
1.2 沐神的Pass1
沐神提到,他一开始没看这篇文章,但是就已经听过第二作者的报告,报告的大意就是使用:图片增强、Relu、Dropout,赢得了Imagenet上的比赛,其实非常有意思,也就是用了技巧而效果好,而没有分析为什么效果好,在哪里效果好。。CV届就是比较喜欢刷榜。。。
客观的说,站在2012年深度学习还没火的时候,可能看题目还比较令人疑惑,例如卷积神经网络。而摘要中出现的神经元等等词语,也是如此。摘要的阅读和我差不多。
- 沐神说,这篇文章的摘要写作并不妙,类似于技术报告
再看讨论:
- 关于神经网络拿掉层次,而结果下降,实际上有可能是参数没好好调;但是从结果上看,确实神经网络的深度是重要的。
- 关于用无监督数据预热,作者这篇文章实际上就是说,直接用有监督的数据做监督学习就行了,这就比之前传统机器学习的效果好很多,而且打败无监督学习的思想。
- 时至今日,video的理解依然很难,并不是说试试就行。
然后是看重要的图片:
- 结果图,似乎Fig4就是说,对于相似的概念,预测的结果也是不错的;而之后说,拿出神经网络学习到的倒数第二层向量,实际上在语义空间上的表示是非常好的,非常适合使用简单的分类器进行分类。
- Fig3,刚刚来到CV这里,确实不怎么看得懂。
- 结构图,实际上也不怎么看得懂。
总的来说,本文实际上就是说用神经网络做图片分类,实验结果特别好,但是很多的内容可能难以看懂;如果是其它做ML的,那么不太容易去看;而如果是做图片分类的,那么我们就很有必要往下读,因为其效果很好。
2 沐神的pass2
这里我就不pass2了,直接听沐神讲解而不自己联系了。沐神讲解到,作为一片经典论文,其实不少观点在现在来看,是不太正确的;有些细节的内容是不必要的,过度的工程化,这些也是我们作为读者,不需要知道的;相应的,也有很多新的技巧,细节被引入,使得网络功能极其强大。
2.1 Introduction
部分一:将故事、背景,也就是说所做的研究,具体是什么方向,方向包含哪些内容,这个方向为什么重要。
本文段落一:做图像分类。ImageNet数据集的数据量大,数据多,所以比较好。
本文段落二:CNN是个好模型,但是CNN容易overfitting(当时主流其实并不是CNN…,这个视角并不好,最好说一说别人用什么方法)。
本文段落三:CNN训练不容易,现在有GPU,所以我们可以好好的利用GPU。
也就是说这里前三段都在讲故事。
部分二:本文工作,或者说本文的主要结构,本文的贡献。
本文段落四:本文做了一个大模型,具体在第三节中讲解,其中有unusual feature,然后是第四节将如何用新技术避免过拟合。这里提到的新特征和新技术,是让读者或者审稿人喜欢看的。如果做了一个纯粹是多模型集成或者超大模型,展示很好的效果,也就是让大家惊叹一下,但是没有启发,这一类是工程,而不是做研究发论文。
本文段落五:讲解了一些其中的工程细节。虽然把模型放在两个GPU上,分别训练,似乎工程量挺大,但是研究者其实不关注。。。这些内容平时要学,但是写文章可以不用写。。
- 一些值得注意的观点:现在似乎认为过拟合时的正则化并不是特别重要,因为设计一个好的网络结构似乎更为重要,因为好的网络是可以不用正则化,训练的好的。
2.2 数据集
这里对于数据集的介绍,一个是解释了研究者看到摘要中有两个不同的结果的疑惑,第二个是当时不容易重视的内容:端到端训练。
也就是说,使用raw RGB图片用于网络训练,进行简单的大小调整,就可以直接训练,而不需要做SIFT特征等等特征提取。端到端训练,即只需要原始图片,直接可以出结果。当时这篇文章并没有突出这个重点,但是现在看来,这确实是深度学习的一个核心价值观——暴力出奇迹。
- 只有简单,有效的内容才是真正的持久。
2.3 模型架构
总的来说,从第二遍读论文的角度,很多细节的内容其实读者是看不懂的。这里我们可以通过简要的叙述来说明这个问题。
3.1节,有如下叙述,如果我们对激活函数不熟悉,那么我们也会陷入迷惑,什么是所谓的saturating呢?当然,我们现在知道就是有界的函数,但如果对背景不了解,那么就容易看不懂。此外,文中提到following某人的工作,那么如果我们进行进一步的精读,那么这篇工作,也是值得一看的。

- Relu:现在看来,用Relu实际上也并不很快,或者Relu快的原因,并不正确。但是现在大家还在用,其实是因为计算很简单。
3.2节将如何将模型放到两个GPU上去训练,其实即使到现在,除了调用Pytorch接口,我也不会。。而且我只会把一模一样的模型放到多个GPU上,而不是一个模型切分为多个小组件。因此,如果只看论文,而不去看具体实现,那么他这一段话的价值可能和我知到它把模型切分放在GPU上,价值是一样的。因此,也不必详细的去看。
3.3节也讲了一个“局部正则化”,其实光看公式,也是感觉很迷惑的,只能说,大概感觉就类似于”局部输出的和BN等价的操作"。但关键问题是,并没有告诉别人为什么这样。。。和一个前人的工作做了简单的比较,但是没有在某个指标上进行比较。或者说,这样的操作是直觉性的,但是很难表达?

3.4节讲述的是有重叠的池化。也还是比较迷惑,虽然我们知道最大池化、中值池化等等,但其实还真没意识到以前的池化都是“不重复的”。总之,这里就是想说,使用的池化层和别人不一样,别人是不重复的,我是重复的这样吧。但是如果知到池化在做什么,就理解其实就是stride
作者就说,这是个提点技巧(其实也涨的不多),但是稍微难收敛一些。
3.5节讲述模型架构。沐神的评价是,模型架构图过于细节和偏向工程(OverEngineer),也就是说我们不需要看到这么细节的图。如果我们不知道它的实现方法,就不会看得懂这些大方框和其中的虚线是什么意思。
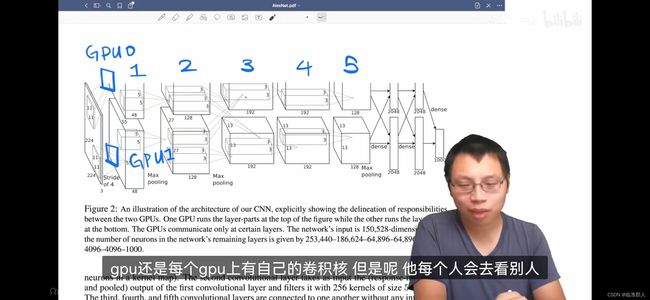
当然现在是知道了,大的框框就是表示图像的特征,虚线是相应的卷积核大小,还表示卷积的方向。例如,开始特征大小是(224,224,3),之后进过48个通道的,大小为11*11,步长为4的卷积,得到一个(55,55,48)的特征。其中,一共设置了5组卷积,在1、2、5层后还加了Maxpooling,并把模型放在了两个GPU上所得到的结果。其中,第2层卷积,发生一个模型的交互,也就是说GPU0上的卷积核对GPU0和GPU1上的特征图,都做卷积,得到第3层的特征。全连接的特征大概也是这样得到的,但是模型放在不同的GPU上,只在最后拼接,得到4096维特征。

- 从现代的观点看:卷积就是将空间信息压缩,是语义上的增加。而卷积的特征图数目,其实就是各通道都有一定的模式。最后全连接后,得到一个机器能看懂的语义向量,其具有语义相似性,体现在某种距离的相似性,可以用来检索、分类等等。也就是说,整个网络都在做一种压缩知识的过程,而我们只需要通过端到端的操作,而不需要做特征工程。
客观的说,整个模型架构比较复杂,而且把模型放在两个GPU上的做法,本身过于特殊,因此后续研究者在自己部署的时候,不会参考这一部分。且实际上经过妥善部署,也可以只用单GPU训练。就是说,切分成两个GPU这件事,作者认为是个贡献,可能是花了很大的力气,但是读者却未必买账。。但是现在来说,三十年河东,三十年河西,在大模型层出不穷的今天,model parallel成为一个研究方向。
2.4 过拟合
可以看到两个方法:数据增强(data augmentation)+Dropout,值得注意的是,都是别人提出过的方法。
数据增强具体还有两个方法。
方法一:随机从原图片中,获取224*224大小的区域。
方法二:颜色通道上使用PCA的增强方法,主要是在通道上做变换,使得图片颜色变化。
Dropout的意思,其实并不是模型的融合,而是一个正则化;在线性模型上等价于L2正则化,在复杂模型上,是个正则化,但是比较难以构造一个简单的正则化项目。
- 模型特别大的原因在于两个全连接。现代观点下,CNN不会用这么大的全连接,因此Dropout也不那么重要了。因此说,好的网络设计,就导致我们是否需要一些技巧来训练它。当然,Dropout在全连接、RNN、Attention上还都是比较有用的。
2.5 部署设置
首先是训练算法,使用了SGD。其中,weight decay是神经网络里的优化,在机器学习里叫做L2正则化。沐神说,本文之前其实比较喜欢用L-BFGS或者是GD、BGD之类的方法,但是后来大家发现SGD的不稳定性、噪声,都对模型的泛化性有好处,因此直接带动量的梯度下降,也成为了优化的一个主流。
然后是参数初始化的设置。这里比较魔,线性映射的矩阵,是用均值为0,标准差为0.01的正态分布进行初始化。这很难说,但是当时似乎对于这种不是特别深,不是特别复杂的网络,还是比较用的。现在Bert等等网络,也一般用N(0,0.02^2)进行初始化。然后某几层网络的神经元的偏置居然是1,这就比较奇怪了,因为如果数据的分布比较平衡,那么偏置应该是0…而不是某几个层次,偏置设为1,并且不调整。这就很奇怪了。。不过从网络训练的稳定性来收,也可以理解,虽然后来也没什么人用它这种方法。

另外学习率的调整,采用非常原始的方法,也就是看损失函数的下降情况,如果不下降,那么学习率乘上0.1,据说很长一段时间大家都是这样的。当然,后来学习率调整的方法也有所变化,例如Resnet,就是采用每训练30个Epoch,就对学习率乘上0.1。这是一种常见的作法,就是每个固定的时间,对学习率进行一个固定的缩减。不过这里很尴尬,一个是Epoch如何选,衰减率如何选?一开始学习率不能太大,衰减率也不能太慢,否则容易造成网络容易不收敛;学习率太小,衰减率太大,网络则学的太慢。
也有学习策略,包括warmup,或者使用cos函数对学习率进行退火。其中,红色的是warmup的学习率训练方法,蓝色就是这里的粗暴的学习方法。
值得注意的是,一开始图像的训练时间很长,因此调参很累;而现在由于文本进入预训练时代,所以调参也很费时间。一般来说,几个小时能够出结果,或者说半天能够出结果,都是符合预期的。
2.6 实验
实验是其实不那么重要的,我们一般只关注实验的效果,不关注实验的细节。
一般只有:领域专家、想要复现效果、审论文的时候,才比较关注实验的细节。
但是本文似乎主要是效果比较突出,这里对Imagenet的大数据集进行训练,也就是说有800多万张图片以及一万类的分类。
实际上,这里对于神经网络的可视化、可解释性也是做了一些工作,例如观察神经网络卷积层的输出特征。

这里的意思是,卷积核似乎学到了一些颜色的变化频率、方向以及颜色等等内容,这里提到GPU上的不同通道似乎学到了不同的内容;虽然现在看来,可以被解释为解耦学习,但是特定的GPU学习到特定的内容,其实可能是程序出现某种固定性。。底层的神经元学习到局部的纹理、方向等等局部特征,而高层神经元确实能够学习到全局的特征。

然后是这里说到,网络的特征向量在欧氏空间的相似性,表现为某些语义上的相似性,也是很有启发性的,为向量检索、分类等等都提供了启示,因为在像素空间上,两张相似图片的欧式距离并不小,而在特征空间上,其欧式距离是有相似性的。
- 不过总的来说,还是处在于一种启发式的状态,相对于传统机器学习模型,可解释性往往受到诟病,因为传统机器学习模型简单,构造的时候有强烈的启发性。近年来,对于神经网络的
公平性,有较多的研究,因为我们需要避免一些偏见,而去做比较公平的决策。
3. 尾声
实际上,作为一篇经典的文章,我们往往可能只需要读两遍,就大概知到其主要的内容;作为经典,很多的细节往往可以在别人的博客讲解中得到答案,而不需要我们真的再去递归的寻找文献,知到其引用的文献的做法。
但是如果读新的文章,我们就不容易在博客上找到其中的细节,我们就需要递归的读文献,直到收敛。
总的来说,看文章也需要关注一下年代,有些时候我们可以喜欢直接读博客去了解论文,但是博客已经是二手信息了;论文的细节在不同人眼里有不同价值,因此不如读原文,原文中有原作者对该话题最为详尽的理解。但读好的博客,也不失为第三遍阅读的一种替补,因为递归式的读文章其实还是挺累的,而有些内容其实到此为止就行,不需要特别详尽。