【目标检测】58、目标检测中的正负样本分配策略总结
文章目录
- 一、Anchor-bases 方法
-
- 1.1 Fast RCNN
- 1.2 Faster RCNN
- 1.3 SSD
- 1.4 RetinaNet
- 1.5 YOLOv1
- 1.6 ATSS
- 1.7 OTA
- 1.8 SimOTA
- 二、Anchor-free 方法
-
- 2.1 FCOS
- 2.2 AutoAssign
- 2.3 YOLOv2~vn
- 2.4 CenterNet
一、Anchor-bases 方法
1.1 Fast RCNN
使用 Selective Search 的方法进行 proposal 生成,得到约 2k proposal:
- 当 proposal 和 gt 的 IoU>=0.5 时,分配为正样本
- 当 proposal 和 gt 的 IoU 在 [0.1, 0.5) 之间时,标记为负样本
- 当 proposal 和 gt 的 IoU 在 [0, 0.1) 之间时,标记为负样本,用于难例挖掘
难例挖掘是在干什么(hard negative mining,难负样本挖掘):
- 对一些负样本进行分类的时候,loss 比较大的那些样本,就容易被分配成正样本,这样的样本就叫 hard negative,会对模型效果产生影响
- 一般来说,如果直接对初始的 proposal 根据 IoU 分配正负后,送入网络训练,那么负样本数量会远大于正样本,这样训练的分类器总是有限的,会出现很多预测为负例的正样本,因为模型直接将输入预测为负的就会有很高的准确率
- 所以,难例挖掘是挖掘困难负样本,也就是最容易预测错误的样本,在保证正负样本比例均衡的情况下,将更多的 hard negative 加入负样本集,会比使用更多 easy negative 对模型效果提升更大一些
- 难样本挖掘的具体操作是计算出所以负样本的损失进行排序,选取损失较大的TOP-K个负样本,这里的K设为正样本数量的3倍
如何进行难例挖掘:
- 先计算所有 proposal 的 loss
- 对 loss 从大到小进行排序
- 保留 loss 大的框,再次进行训练,即通过 loss 提高网络对这些难样本的关注
1.2 Faster RCNN
Faster RCNN 涉及到了两次正负样本的划分
检测网络的正负样本划分:
- 首先,对每个标定的 gt 框,与其 IoU 最大的 anchor 记为正样本 (保证每个ground true至少对应一个正样本anchor)
- 然后,剩余的 anchor,如果其与某个标定区域重叠比例大于 0.7,记为正样本。如果其与任意一个标定的重叠比例都小于 0.3,记为负样本
- 最后,上两步剩余的 anchor 作为 ignore 舍弃不用,且跨越图像边界的 anchor 弃去不用
RPN 网络的正负样本划分:
- 将 20000 多个 proposal 选出 256 个进行分类和回归位置
- 对于每一个 gt,选择和它 IoU 最高的一个 anchor 作为正样本
- 对于剩下的 anchor,从中选择和任意一个 gt 的 IoU 超过 0.7 的 anchor,作为正样本,正样本的数目不超过 128 个
- 随机选择和 gt 重叠度小于 0.3 的 anchor 作为负样本。负样本和正样本的总数为256。
1.3 SSD
- 与 gt 的 IoU > 0.5 的框判定为正样本
- 其它框作为负样本鉴定为背景
- 使用了难例挖掘
1.4 RetinaNet
- 在每个位置设定多个 anchor,使用 IoU 来区分前景、背景框
- IoU 大于某个阈值(如0.5)的为正样本,小于某个阈值(如0.3)的为负样本,其他框忽略。
缺点:IoU 阈值需要人工选择
1.5 YOLOv1
- 对每个 gt 只分配一个 anchor 作为正样本,分配的依据是和该 gt 的 IoU 最大
- 其他的 anchor 都分配为负样本
1.6 ATSS
ATSS 如何划分正负样本:
- 计算每个样本点和真实框中心点的 L2 距离,保留距离最小的前 k 个点
- 计算保留下来的 anchor 和真实框的 IoU,并计算这组 IoU 的均值和方差,均值和方差的和即为阈值
- 大于阈值的为正样本
上面为什么使用 anchor 和 object 的中心点距离来选择候选框?
- RetinaNet 中,如果两个框中心点距离越近,则其 IoU 得分会越高
- FCOS 中,anchor point 如果距离目标中心点的距离越近,则是高质量 point,会产生更好的检测结果。
为什么要使用均值和标准差这些统计结果来非固定的阈值?
这里使用的是 k × l k\times l k×l 个 anchor 的 IoU 的统计信息,也可以看做是选择了 level。
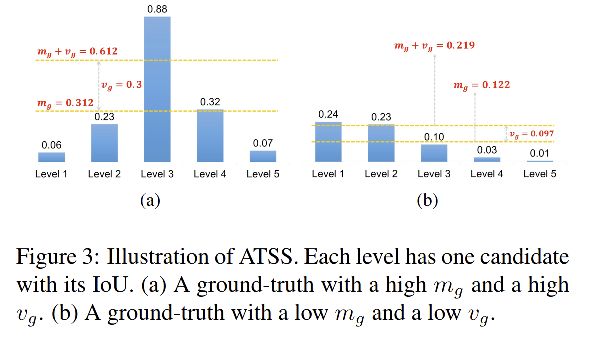
本文的阈值是一个统计结果,如图 3(a) 有一个高的阈值,这是因为这里的候选框质量都很高,如图3(b) 有一个低的阈值,说明这里的框的质量都不高,如果使用高阈值的话,会把绝大部分的框都滤掉,不合适,所以使用统计的量作为阈值是一个可取的方式。
1.7 OTA

RetinaNet 使用 IoU 来实现,FCOS 根据每个点是否在 gt box 内部来确定其正负。
这些方法忽略了一个问题:不同大小、形状、遮挡程度的目标,其 positive/negative 的判定条件应该是不同的。
所以就有一些方法使用动态的分配方法,来实现 label assignment。
- ATSS 根据统计信息,来分配正负样本
- Freeanchor、AutoAssign 等通过使用预测的 confidence score 来动态分配正负
作者认为,独立的给每个 gt 分配 pos/neg 不是最优的方法,缺失了上下文信息,当处理那些模棱两可的 anchor 时(如图 1 中的红色点,一个点处于多个 gt 中),上面的方法是靠手工的特征来选定属于哪个 gt 的(如 max-IoU、min-Area 等)。
CNN 的方法中,其实是 one-to-many 的形式,也就是一个 gt 会对应多个 anchor。
本文作者为了从 global 的层面来实现 CNN 中的 one-to-many assignment,将 label assignment 问题变成了一个 Optimal Transport(OT)问题(线性规划的一个特殊形式)。
OT 是这样的一个问题:
- 假设有 m 个供货商(gt),n 个需求方(anchor)
- 第 i i i 个供货商有 s i s_i si 单元的货物(一个 gt 对 s i s_i si 个 anchor 负责),第 j j j 个需求方需要 d j d_j dj 单元的货物(一个 anchor 只需要一个 label)
- 每个单元的货物从供货商 i i i 到需求方 j j j 的 Transporting cost 是 c i j c{ij} cij
- OT 问题的目标是寻找一个 transportation plan π*,让这个 Transporting cost 最小
OTA 的过程如下:
- 先经过推理,得到预测的 anchor 对应的类别和位置
- 确定每个 gt 负责的 anchor 个数 s i s_i si(根据 Dynamic k 得到的)
- 确定 background 负责的 anchor 个数 s m + 1 s_{m+1} sm+1(n-s)
- 每个 anchor 需要的 label 都是 1 个
- 计算每个 gt 对所有 anchor 的 cost(包括分类 cost、回归 cost、center prior cost)
- 优化 cost,得到最优传输方案 π*
- 每个 gt 根据前面计算得到的负责的 anchor 个数,则选择该 gt 对应的该行中,前 top-k 个位置的 anchor 作为候选框
- 如果多个 gt 对应了一个 anchor,则在这几个 gt 中选择 cost 最小的,对该 anchor 负责
1.8 SimOTA
SimOTA 是 YOLOX 中使用的 label assignment 的方式。都是旷世提出的方法。
在 OTA 中,总结了一个好的 label assignment 的方法一般有四个优点,且 OTA 也都满足了:
- Loss/quality aware
- Center prior
- Dynamic number of positive anchors for each g t gt gt
- Global view
OTA 将 label assignment 问题从 global 层面出发并看成了一个最优传输的问题,但 OTA 有一个问题,它需要使用 Sinkhorn-Knopp algorithm 来优化,这会增加 25% 的训练时间,假设使用 300 epoch,那增加的时长是不容小觑的。
所以孙剑等人又提出了 SimOTA,将 OTA 的优化过程简化了——dynamic top-k strategy,使用该优化策略得到一个大概的解决方案。
SimOTA 是如何简化的?
- 求每个真值和 anchor 的传输花费 c i j c_{ij} cij:在 SimOTA 中,真值 g i g_i gi 和预测 anchor p j p_j pj 的传输花费如下, λ \lambda λ 是权重,其余两者分别为 g i g_i gi 和 p j p_j pj 的分类 loss 和回归 loss:
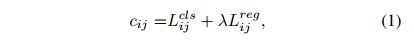
- 对于每个真值 g i g_i gi,在固定的 center 区域,选择花费最小的前 k 个 anchor,作为该 g i g_i gi 所负责的 anchor。也就是使用某种方法优化传输方式使得花费最小,而是直接选择计算后的 cost matrix 中,每行对应花费最小的 anchor。至于每个 gt 选择 k 个 anchor,这里的 k k k 仍然使用 OTA 中的 Dynamic k Estimation 方法。
SimOTA 的优势:
- 降低了训练时间
- 避免了 Sinkhorn-Knopp algorithm 优化过程中的超参数
- 在 YOLOX 中,将 AP 从 45%→47.3%
二、Anchor-free 方法
2.1 FCOS
FCOS 中,是以 anchor point 作为特征点,将每个点当做训练样本,使用点是否在框内来区域前景、背景点
缺点:需要设定阈值参数,且这些确定的规则虽然对大多数目标适用,但对一些 outer 的目标是不使用的,所以,对不同的目标应该用不同的规则。
2.2 AutoAssign
贡献:提出了让网络自主学习 anchor 正负的方法,首先提出了一种与类别相关且对不同位置使用不同权重的 label assign 方法,能够同时优化空间和尺度的 label assignment。具体来说,就是引入了两个加权系数:① Center weighting 用于学习不同类别的先验,让每个类别有自己的正样本采样方式;② confidence weighting 用于学习每个位置的前景权重和背景权重
现有的标签分配方法的不足:
- Anchor-free 方法中有些方法将落在 gt 中心点某个半径内的点看做正样本,也称为 center prior, 也就是认为距离中心点距离越近的点,越有可能是正样本。而这些前提都需要极强的先验知识,同时也是固定策略的正负样本,不能在训练过程中通过学习进行更改。
- 有海量的超参数需要调整:例如,anchor 的 num,size,aspect ratios;或者 radius,top-k,IoU 阈值等等
- 现有的 label assignment 方法对 spatial 和 scale 的 assign 是分别采用不同的方式解决的,没有同时解决。
其他方法是怎么解决上述问题的:
- GuidedAnchoring 和 MetaAnchor 在 sampling 之前,动态的改变 anchor 的形状
- 还有一些方法在空间维度(FreeAnchor、ATSS)和尺度维度(FSAF)动态修正采样的策略
其他方法的缺点:
- 上述的方法只能在数据维度添加动态的因子,还有需要人为设定的参数在里边。
AutoAssign 的做法:AutoAssign 的正负样本分配,可以看做把处于目标上的样本点看做正样本,把虽然在 bbox 内但不属于目标本身的样本点看做负样本(AutoAssign 认为在真实目标上采样,肯定比在背景上采样效果更好)。
AutoAssign 这样做的优势:让标签的分配依赖于数据先验的同时,也能对不同的类别进行不同的自适应,避免了人为选定参数,如 IoU 阈值、anchor 分布、top-k 等。
AutoAssign 的两个特点:
-
将每个尺度的每个位置平等看待,不直接划分正负样本:AutoAssign 的框架是建立在 FCOS 之上的,对每个 location 都平等对待,每个 location 都有正样本属性和负样本属性(即体现在原文中的w+ 和w-)。
也就是说,在优化的过程中,有些样本会同时受到来自它为正样本的监督和负样本的监督,两者利用 w + w^+ w+ 和 w − w^- w− 来平衡配比,此外,不在任何 gt 框里的 location 其正样本属性 w+ 必然为0,也就是那些位置必然是background。
-
联合优化分类和回归(将回归函数也处理成了似然形式): L i ( θ ) = L i c l s ( θ ) + λ L i l o c ( θ ) = − l o g ( P i ( θ ) ) L_i(\theta) = L_i^{cls}(\theta)+\lambda L_i^{loc}(\theta) =-log(P_i(\theta)) Li(θ)=Licls(θ)+λLiloc(θ)=−log(Pi(θ))
加权机制:
- Center weighting module:class-aware,给每个类别学习一个正负样本分配方式,给正负样本加权,一般认为距离中心越近,是正样本的权重越大,但这里是对每个类别分别学习先验,可以调整中心点的位置和开口的尺度
- Confidence weighting module:instance-aware,给每个位置分别学习正负样本的权重 w + w^+ w+ 和 w − w^- w−,作为权重控制最终的 loss。
从 label assignment 的角度来看,AutoAssign 究竟做了什么:
- 能够从特征图中动态的找到 FPN 的合适的尺度,和空间位置
2.3 YOLOv2~vn
1、YOLOv2-v3 中引入了 anchor:
- 正样本:每个 grid 会有 3 个预定义的 anchor,假设某个 anchor 的中心落在了某个 grid 上,计算中心落入该 grid 内的所有 anchor 和 gt 的 IoU,获得最大 IoU 的 anchor 作为正样本,每个对每个 gt 分配一个和其 IoU 最大的 anchor 作为正样本,参与正样本 loss 计算
- 忽略样本:但是由于 v2 中的边界框其实比 v1 多,此时定了一个 IoU 阈值,anchor 和 gt 的 IoU<阈值 的才是负样本,如果在阈值和最大 IoU 之间的样本均作为忽略样本
2、YOLOv4:
3、YOLOv5:
-
首先,anchors 和 gt 匹配,看哪些 gt 是当前特征图的正样本
在 yolov5 中,会将一个特征点分为四个象限,针对步骤 1 中匹配的 gt,会计算该 gt(图中蓝色点)处于四个象限中的哪一个,并将邻近的两个特征点也作为正样本。若 gt 偏向于右下角的象限,就会将 gt 所在 grid 的右边、下边特征点也作为正样本。
-
接着,将当前特征图的正样本分配给对应的 grid

4、YOLOX:
-
anchor free。
-
simOTA 能够做到自动的分析每个 gt 要拥有多少个正样本。
-
能自动决定每个 gt 要从哪个特征图来检测。
5、YOLOv6:
-
第一版使用 simOTA
-
论文版本使用 TAL
6、YOLOv7:
YOLOv7 也仍然是 anchor base 的目标检测算法,YOLOv7 将 YOLOv5 和 YOLOX中的正负样本分配策略进行结合,流程如下:
-
YOLOv5:
- 使用 YOLOv5 正负样本分配策略分配正样本。
-
YOLOX:
- 计算每个样本对每个 GT 的 Reg+Cls loss(Loss aware)
- 使用每个GT的预测样本确定它需要分配到的正样本数(Dynamic k)
- 为每个GT取loss最小的前dynamic k个样本作为正样本
- 人工去掉同一个样本被分配到多个GT的正样本的情况(全局信息)
其实主要是将 simOTA 中的第一步 「使用中心先验」替换成「YOLOv5」中的策略。相比只使用 YOLOv5,YOLOv7 加入了 loss aware,利于当前模型的表现,能够再进行一次精筛。而融合策略相较于只使用 YOLOX 中 simOTA,能够提供更精确的先验知识。
7、YOLOv8
- 使用 TAL
2.4 CenterNet
Centernet 的正负样本判定很简单,将目标检测建模成了一个基于关键点检测的结构,当 gt 中心落在哪个位置,那个位置就是正样本,其余位置都是负样本。
由于这样正负样本极度不平衡,所以,Loss 上做了很大的文章,参考 Focal loss 构建了属于自己的损失函数。