2022年深度学习在时间序列预测和分类中的研究进展综述
时间序列预测的transformers的衰落和时间序列嵌入方法的兴起,还有异常检测、分类也取得了进步
2022年整个领域在几个不同的方面取得了进展,本文将尝试介绍一些在过去一年左右的时间里出现的更有前景和关键的论文,以及Flow Forecast [FF]预测框架。
时间序列预测
1、Are Transformers Really Effective for Time Series Forecasting?
https://arxiv.org/pdf/2205.13504.pdf
Transformer相关研究对比Autoformer、Pyraformer、Fedformer等,它们的效果和问题
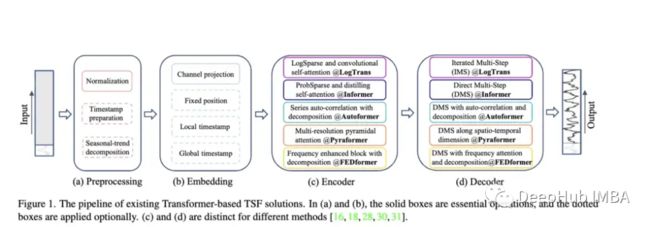
随着 Autoformer (Neurips 2021)、Pyraformer (ICLR 2022)、Fedformer (ICML 2022)、EarthFormer (Neurips 2022) 和 Non-Stationary Transformer (Neurips) 等模型的出现,时间序列预测架构的 Transformer 系列不断发展壮)。但是这些模型准确预测数据并优于现有方法的能力仍然存在疑问,特别是根据新研究(我们将在稍后讨论)。
Autoformer :扩展并改进了 Informer 模型的性能。Autoformer 具有自动关联机制,使模型能够比标准注意力更好地学习时间依赖性。它旨在准确分解时态数据的趋势和季节成分。
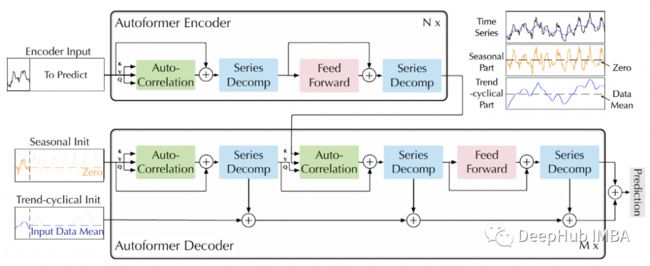
Pyraformer:作者介绍了“金字塔注意模块 (PAM),其中尺度间树结构总结了不同分辨率下的特征,尺度内相邻连接对不同范围的时间依赖性进行建模。”
Fedformer:该模型侧重于在时间序列数据中捕捉全球趋势。作者提出了一个季节性趋势分解模块,旨在捕捉时间序列的全局特征。
Earthformer: 可能是这些论文中最独特的一个,它特别专注于预测地球系统,如天气、气候和农业等。介绍了一种新的cuboid 注意力架构。这篇论文应该是潜力巨大的望,因为在河流和暴洪预测方面的研究,许多经典的Transformer都失败了。
Non-Stationary Transformer:这是使用transformer 用于预测的最新论文。作者旨在更好地调整 Transformer 以处理非平稳时间序列。他们采用两种机制:去平稳注意里和一系列平稳化机制。这些机制可以插入到任何现有的Transformer模型中,作者测试将它们插入 Informer、Autoformer 和传统的Transformer 中,都可以提高性能(在附录中,还表明它可以提高 Fedformer 的性能)。
论文的评估方法:与 Informer 类似,所有这些模型(Earthformer 除外)都在电力、交通、金融和天气数据集上进行了评估。主要根据均方误差 (MSE) 和平均绝对误差 (MAE) 指标进行评估:
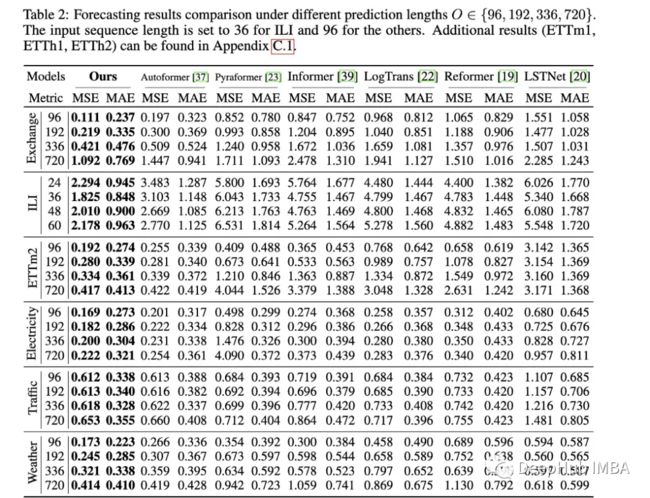
这篇论文很好,但是它只对比了Transformer相关的论文,其实应该与更简单的方法进行比较,比如简单的线性回归、LSTM/GRU、甚至是XGB等树形模型。另外就是它们应该不仅仅局限在一些标准数据集,因为我在其他时间序列相关数据集上没有看到很好的表现。比如说informer准确预测河流流量方面遇到了巨大的问题,与LSTM或甚至是普通的Transformer相比,它的表现通常很差。
另外就是由于与计算机视觉不同,图像维度至少保持不变,时间序列数据在长度、周期性、趋势和季节性方面可能存在巨大差异,因此需要更大范围的数据集。
在OpenReview的Non-Stationary Transformer的评论中,一位评论者也表达了这些问题,但它在最终的元评论中被否决了:
“由于该模型属于Transformer领域,而且Transformer之前已经在许多任务中表现出了最先进的水平,我认为没有必要与其他‘家族’方法进行比较。”
这是一个非常有问题的论点,并导致研究在现实世界中缺乏适用性。就像我们所认知的:XGB在表格数据的压倒性优势还没有改变,Transformer的闭门造车又有什么意义?每次都超越,每次都被吊打。
作为一个在实践中重视最先进的方法和创新模型的人,当我花了几个月的时间试图让一个所谓的“好”模型工作时,但是最后却发现,他的表现还不如简单的线性回归,那这几个月有什么意思?这个所谓的好”模型又有什么意义。
所有的 transformer 论文都同样存在有限评估的问题。我们应该从一开始就要求更严格的比较和对缺点的明确说明。一个复杂的模型最初可能并不总是优于简单模型,但需要在论文中明确指出这一点,而不是掩盖或简单地假设没有这种情况。
但是这篇论文还是很好的,比如Earthformer 在MovingMNIST 数据集和N-body MNIST数据集上进行了评估,作者用它来验证cuboid 注意力的有效性,评估了它的降水量即时预报和厄尔尼诺周期预报。我认为这是一个很好的例子,将物理知识整合到具有注意力的模型架构中,然后设计出好的测试。
2、Are Transformers Effective for Time Series Forecasting (2022)?
https://arxiv.org/pdf/2205.13504.pdf
这篇论文探讨了 Transformer 预测数据与基线方法的能力。结果在某种程度上再次证实了Transformers 的性能通常比更简单的模型差,而且难以调整。这篇论文中的几个有趣的观点:
- 用基本的线性层替换自注意力并发现:“Informer 的性能随着逐渐简化而增长,表明至少对于现有的 LTSF 基准来说,自注意力方案和其他复杂模块是不必要的”
- 调查了增加回溯窗口( look-back window )是否会提高 Transformer 的性能并发现:“SOTA Transformers 的性能略有下降,表明这些模型仅从相邻的时间序列序列中捕获相似的时间信息。”
- 探讨了位置嵌入是否真的能很好地捕捉时间序列的时间顺序。通过将输入序列随机混洗到Transformer中来做到这一点。他们在几个数据集上发现这种改组并没有影响结果(这个编码很麻烦)。
在过去的几年里,Transformer模型的无数次时间序列实验在绝大多数情况下结果都不太理想。在很长一段时间里,我们都认为一定是做错了什么,或者遗漏了一些小的实现细节。所有这些都被认为是下一个SOTA模型的思路。但是这个论文却有一致的思路就是?如果一个简单的模型胜过Transformer,我们应该继续使用它们吗?是所有的Transformer都有固有的缺陷,还是只是当前的机制?我们是否应该回到lstm、gru或简单的前馈模型这样的架构?这些问题我都不知道答案,但是这篇论文的整体影响还有待观察。到目前为止,我认为答案可能是退一步,专注于学习有效的时间序列表示。毕竟最初BERT在NLP环境中成功地形成了良好的表示。
也就是说,我不认为我们应该把时间序列的Transformer视为完全死亡。Fedformer的表现非常接近简单模型,并且在各种消融打乱任务中表现更好。虽然的基准在很多情况下都难以进行预测,但他们对数据的内部表示却相当不错。我认为还需要进一步了解内部表示和实际预测输出之间的脱节。另外就是正如作者所建议的那样,改进位置嵌入可以在提高整体性能方面发挥关键作用。最后有一个Transformer的模型,在各种异常检测数据集上表现非常好,下面就会介绍。
3、Anomaly Transformer (ICLR Spolight 2022)
https://arxiv.org/abs/2110.02642
相当多的研究都集中在将 transformers 应用于预测,但是异常检测的研究相对较少。这篇介绍了一种(无监督)Transformer 来检测异常。该模型结合使用特别构建的异常注意机制和 minmax 策略。
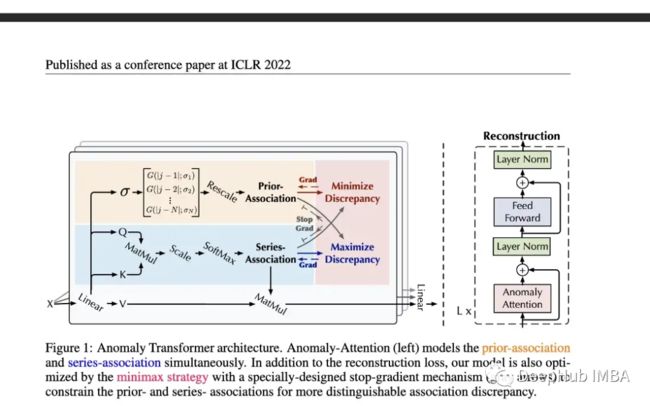
本文在五个真实世界的数据集上评估了模型的性能,包括Server Machine Dataset, Pooled Server Metrics, Soil Moisture Active Passive和NeurIPS-TS(它本身由五个不同的数据集组成)。虽然有人可能会对这个模型持怀疑态度,特别是关于第二篇论文的观点,但这个评估是相当严格的。Neurips-TS是一个最近创建的,专门用于提供更严格的异常检测模型评估的数据集。与更简单的异常检测模型相比,该模型似乎确实提高了性能。
作者提出了一种独特的无监督Transformer,它在过多的异常检测数据集上表现良好。这是过去几年时间序列Transformer领域最有前途的论文之一。因为预测比分类甚至异常检测更具挑战性,因为你试图预测未来多个时间步骤的巨大可能值范围。这么多的研究都集中在预测上,而忽略了分类或异常检测,对于Transformer我们是不是应该从简单的开始呢?
4、WaveBound: Dynamic Error Bounds for Stable Time Series Forecasting (Neurips 2022):
https://openreview.net/forum?id=vsNQkquutZk
论文介绍了一种新的正则化形式,可以改进深度时间序列预测模型(特别是上述transformers )的训练。
作者通过将其插入现有的 transformer + LSTNet模型来评估。他们发现它在大多数情况下显着提高了性能。尽管他们只测试了Autoformer 模型,而没有测试 Fedformer 这样的更新模型。
新形式的正则化或损失函数总是有用的,因为它们通常可以插入任何现有的时间序列模型中。如果你 Fedformer + 非平稳机制 + Wavebound 结合起来,你可能会在性能上击败简单的线性回归 。
时间序列表示
虽然Transformer 再预测方向上的效果并不好,但在创建有用的时间序列表示方面Transformer还是取得了许多进展。我认为这是时间序列深度学习领域中一个令人印象深刻的新领域,应该进行更深入的探索。
5、TS2Vec: Towards Universal Representation of Time Series (AAAI 2022)
https://arxiv.org/abs/2106.10466
TS2Vec是一个学习时间序列表示/嵌入的通用框架。这篇论文本身已经有些过时了,但它确实开始了时间序列表示学习论文的趋势。
对使用表示进行预测和异常检测进行评估,该模型优于许多模型,例如 Informer 和 Log Transformer。
6、Learning Latent Seasonal-Trend Representations for Time Series Forecasting(Neurips 2022)
https://openreview.net/forum?id=C9yUwd72yy
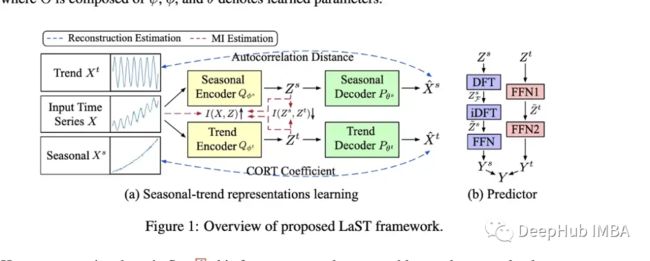
作者创建了一个模型(LAST),使用变分推理创建季节性和趋势的分离表示。
作者对他们的模型进行了下游预测任务的评价,他们通过在表示上添加一个预测器(见上图中的B)来做到这一点。它们还提供了有趣的图来显示表示的可视化。该模型在几个预测任务以及TS2Vec和成本方面都优于Autoformer。在一些预测任务上,它看起来也可能比上面提到的简单线性回归表现更好。

尽管我仍然对那些只评估标准预测任务的模型持怀疑态度,但这个模型的确很亮眼,因为它关注的是表征而不是预测任务本身。如果我们看一下论文中展示的一些图表,可以看到模型似乎确实学会了区分季节性和趋势。不同数据集的可视化表示也嵌入到相同的空间中,如果它们显示出实质性的差异,那将是很有趣的。
7、CoST: Contrastive Learning of Disentangled Seasonal-Trend Representations for Time Series Forecasting (ICLR 2022)
https://openreview.net/forum?id=PilZY3omXV2
这是2022年早些时候在ICLR上发表的一篇论文,在学习季节和趋势表示方面与LaST非常相似。由于LaST在很大程度上已经取代了它的性能,这里就不做过多的描述了。但链接在上面供那些想要阅读的人阅读。
其他有趣的论文
8、Domain Adaptation for Time Series Forecasting via Attention Sharing(ICML 2022)
https://arxiv.org/abs/2102.06828
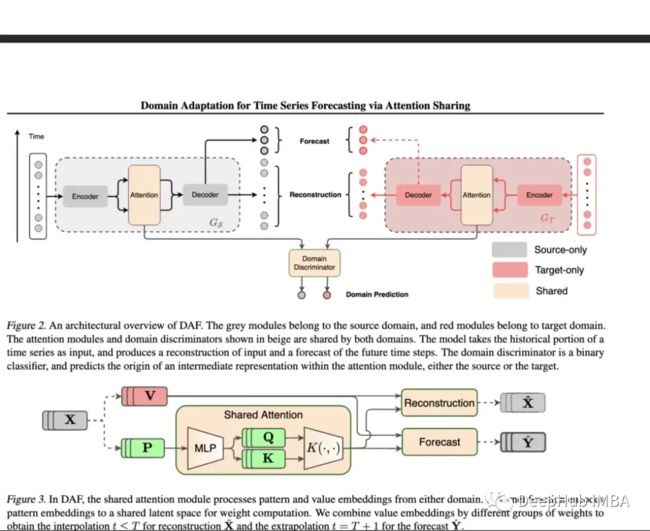
当缺乏训练数据时,预测对 DNN 来说是一项挑战。这篇论文对具有丰富数据的领域使用共享注意力层,然后对目标领域使用单独的模块。
它所提出的模型使用合成数据集和真实数据集进行评估。在合成环境中,测试了冷启动学习和少样本学习,发现他们的模型优于普通 Transformer 和 DeepAR。对于真实数据集采用了 Kaggle 零售数据集,该模型在这些实验中大大优于基线。
冷启动、少样本和有限学习是极其重要的主题,但很少有论文涉及时间序列。该模型为解决其中一些问题提供了重要的一步。也就是说他们可以在更多不同的有限现实世界数据集上进行评估,并与更多基准模型进行比较, 微调或正则化的好处在于可以对任何架构进行调整。
9、When to Intervene: Learning Optimal Intervention Policies for Critical Events (Neurips 2022)
https://openreview.net/pdf?id=rP9xfRSF4F
虽然这不是一篇“典型的”时间序列论文,但我选择将其列入这个列表,因为本文的重点是在机器发生故障之前找到进行干预的最佳时间。这被称为OTI或最佳时间干预
评估OTI的问题之一是潜在生存分析的准确性(如果不正确,评估也会不正确)。作者根据两个静态阈值评估了他们的模型,发现它表现得很好,并且绘制了不同政策的预期表现和命中与失败的比率。
这是一个有趣的问题,作者提出了一个新颖的解决方案,Openreview的一位评论者指出:“如果有一个图表显示失败概率和预期干预时间之间的权衡,那么实验可能会更有说服力,这样人们就可以直观地看到这个权衡曲线的形状。”
下面还有一些相关论文,如果你有兴趣可以看看
10、FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting (Neurips 2022)
https://openreview.net/forum?id=zTQdHSQUQWc
11、Adjusting for Autocorrelated Errors in Neural Networks for Time Series (Neurips 2021)
12、Dynamic Sparse Network for Time Series Classification: Learning What to “See” (Neurips 2022)
https://openreview.net/forum?id=ZxOO5jfqSYw
最近的数据集/基准
最后就是数据集的测试的基准
Monash Time Series Forecasting Archive (Neurips 2021):该存档旨在形成不同时间序列数据集的“主列表”,并提供更权威的基准。该存储库包含 20 多个不同的数据集,涵盖多个行业,包括健康、零售、拼车、人口统计等等。
https://forecastingdata.org/
Subseasonal Forecasting Microsoft (2021):这是 Microsoft 公开发布的数据集,旨在促进使用机器学习来改进次季节预测(例如未来两到六周)。次季节预报有助于政府机构更好地为天气事件和农民的决定做准备。微软为该任务包含了几个基准模型,与其他方法相比,一般来说深度学习模型的表现相当差。最好的 DL 模型是一个简单的前馈模型,而 Informer 的表现非常糟糕。
https://www.microsoft.com/en-us/research/project/subseasonal-climate-forecasting/
Revisiting Time Series Outlier Detection:本文评述了许多现有的异常/异常值检测数据集,并提出了35个新的合成数据集和4个真实世界数据集用于基准测试。
https://openreview.net/forum?id=r8IvOsnHchr
开源的时序预测框架FF
Flow Forecast是一个开源的时序预测框架,它包含了以下模型:
Vanilla LSTM (LSTM)、SimpleTransformer、Multi-Head Attention、Transformer with a linear decoder、DARNN、Transformer XL、Informer、DeepAR、DSANet 、SimpleLinearModel等等
这是一个学习使用深度学习进行时间预测的很好的模型代码来源,有兴趣的可以看看。
https://github.com/AIStream-Peelout/flow-forecast
总结
在过去的两年里,我们已经看到了Transformer在时间序列预测中的兴起和可能的衰落和时间序列嵌入方法的兴起,以及异常检测和分类方面的额外突破。
但是对于深度学习的时间序列来说:可解释性、可视化和基准测试方法还是有所欠缺,因为模型在哪里执行,在哪里出现性能故障是非常重要的。此外,更多形式的正则化、预处理和迁移学习来提高性能可能会在未来中出现。
也许Transformer对时间序列预测有好处(也许不是),就像VIT那样如果没有Patch的出现Transformer可能还会被认为不行,我们也将继续关注Transformer在时间序列的发展或者替代。
https://avoid.overfit.cn/post/ea577b0b468642fe8aa8616e2db4da7c
作者:Isaac Godfried