谣言检测相关论文阅读笔记:PAKDD2020-SAFE: Similarity-Aware Multi-Modal Fake News Detection
目录
Abstract
1.Introduction
2.Related Work
3.Methodology
3.1 Multi-modal Feature Extraction
3.2 Modal-independent Fake News Prediction
3.3 Cross-modal Similarity Extraction
3.4 Model Integration and Joint Learning
4.Experiment
Abstract
作者指出现在的谣言检测文章很少考虑视觉和文本之间的关系(相似性),但是这种相关性是很重要的,比如说一个假新闻文章为了吸引读者的注意力,用了一张和文本毫不相干的图片。所以作者提出了一个相似性感知假新闻检测模型—SAFE。这个模型从新闻文章中调查了大量的多模态信息。首先,用神经网络分别提取文本和视觉特征用于新闻表示,接下来研究提取的多模态间的关系,最后将新闻的文本、视觉特征表示和他们之间的关系联合学习用来预测假新闻。作者提出的方法有助于根据新闻文章的文本、图像或“不匹配”来识别其虚假性。
1.Introduction
两种谣言检测方法:基于社交上下文和基于内容的。
基于社交上下文的检测方法:不利于在早期传播时检测假新闻,因为早期上下文信息较少。
基于内容的检测方法:通常是视觉和文本信息,作者提出,当创作者使用非操纵图像来支持非事实场景或陈述时,虚假新闻的文本信息和视觉信息之间存在“鸿沟”。因此,作者认为加入文本和图像间的相关性来检测谣言是有必要的。
作者提出的方法由三个模块组成(如下图):(1)多模态(文本和视觉)特征提取;(2) 模态内(或者说模态无关)虚假新闻预测;(3) 跨模态相似性提取。
大致流程是:首先采用神经网络自动获取文本和视觉信息的潜在表示,并在此基础上定义它们之间的相似性度量。然后,这些新闻文本和视觉信息的表示及其相似性被联合学习并用于预测假新闻。该方法旨在识别新闻文章的文本或图像的虚假性,或文本和图像之间的“不匹配”。
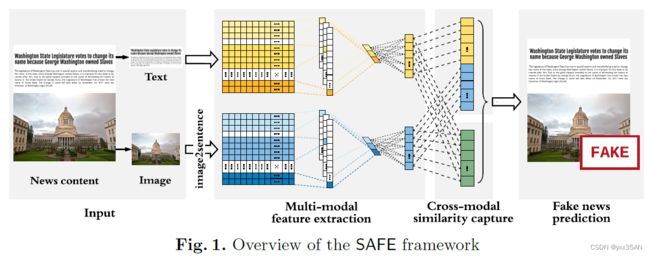
主要贡献:1.提出了调查新闻文本和视觉信息之间的关系(相似性)在预测虚假新闻中的作用的第一种方法;2.提出了一种新的方法,联合利用多模态(文本和视觉)和关系信息来学习新闻文章的表示和预测虚假新闻;3.对大规模真实数据进行了大量实验,证明了所提方法的有效性。
2.Related Work
这部分主要介绍前有相关工作。
3.Methodology
这部分主要介绍模型使用的方法,三个模块及最后的联合预测。
问题定义和主要的符号:给定一个新闻文章表示为![]() ,
, 为文本信息,
为文本信息, 为视觉信息。
为视觉信息。![]() 作为相应的表示,其中
作为相应的表示,其中![]() ,让
,让![]() 来表示
来表示 和
和 之间的相似度,并且
之间的相似度,并且![]() ,我们的目标是通过文章的文本信息,视觉信息和他们的关系来预测A是假新闻
,我们的目标是通过文章的文本信息,视觉信息和他们的关系来预测A是假新闻![]() 还是真实新闻
还是真实新闻![]() 。
。
即:
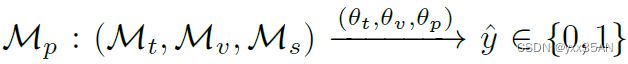
![]() 是要学习的参数
是要学习的参数
3.1 Multi-modal Feature Extraction
text:作者引入了一个额外的全连接层的扩展Text-CNN来自动提取每个新闻文章的文本特征。Text-CNN架构如图所示:
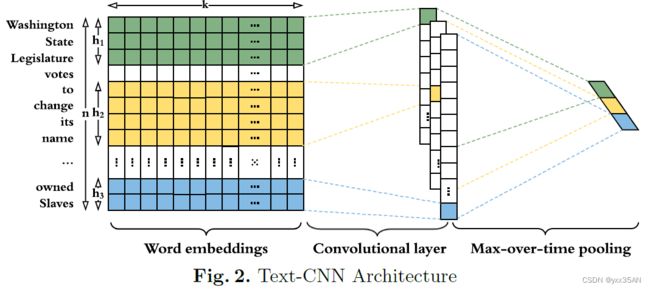
具体过程:给定一条有 个单词的内容,每个单词首先被嵌入表示为向量
个单词的内容,每个单词首先被嵌入表示为向量![]() ,卷积层是将本地输入序列
,卷积层是将本地输入序列![]() 经过一个过滤器
经过一个过滤器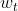 后生成特征映射图,表示为
后生成特征映射图,表示为![]() 。如图所示,每一个本地输入序列是一组连续的
。如图所示,每一个本地输入序列是一组连续的 个单词。计算公式如下:
个单词。计算公式如下:
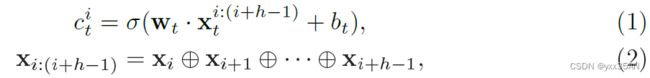
其中 是一个连接操作,
是一个连接操作, 是ReLU函数,
是ReLU函数,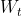 和
和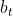 是Text_CNN中要被学习的参数。
是Text_CNN中要被学习的参数。
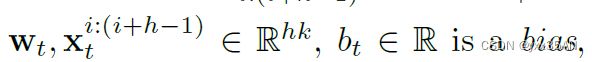
然后,最大池化运算用来得到维度缩小的特征映射图,如![]() 。最后,新闻的文本被表示为
。最后,新闻的文本被表示为![]() ,其中
,其中![]() ,
, 是选择的不同窗口数大小,
是选择的不同窗口数大小,![]() 是要学习的参数。
是要学习的参数。
Image:为了表示图像,还是使用有一个额外的全连接层的Text-CNN,但是在这之前先使用一个预训练的image2sentence模型。最后计算方法一样,图像表示为![]() 。
。
3.2 Modal-independent Fake News Prediction
将提取的新闻内容的文本和视觉特征正确地映射到其虚假的可能性,进而映射到其实际标签。数学上,这种可能性可以通过下式得到:
![]()
其中,![]() , 是拼接运算,
, 是拼接运算,![]() 是参数,为了让预测新闻时假新闻的可能性更加接近真实标签,定义一个交叉熵损失:
是参数,为了让预测新闻时假新闻的可能性更加接近真实标签,定义一个交叉熵损失:
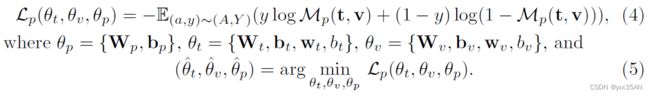
3.3 Cross-modal Similarity Extraction
将新闻文章的视觉和文本信息之间的相关性定义为微调的余弦相似性:
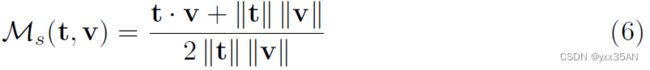
![]() 一定是正数并且在0到1之间,0表示和之前几乎不相似,1表示和几乎是相同的。
一定是正数并且在0到1之间,0表示和之前几乎不相似,1表示和几乎是相同的。
然后基于交叉熵来定义损失:

3.4 Model Integration and Joint Learning
检测虚假新闻目标是正确识别虚假新闻,其虚假性在于(1)文本和/或视觉信息,或(2)它们的关系。为了涉及这两种情况,将最终损失函数指定为:
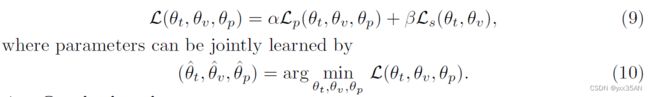 4.Experiment
4.Experiment
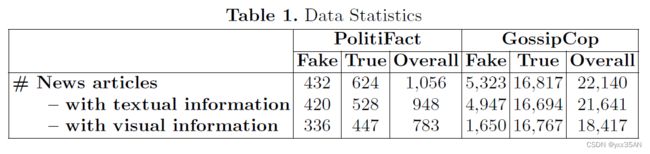
Dataset
Results
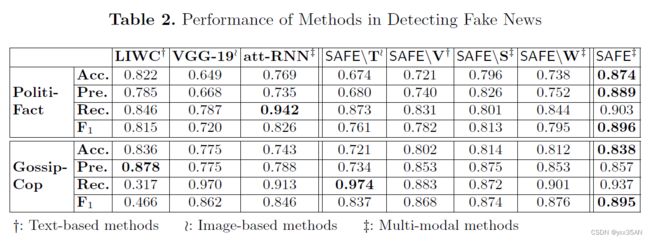
实验结果表明,多模态特征和跨模态关系(相似度)在虚假新闻检测中具有相当重要的价值。进行的案例研究进一步验证了该方法在评估此类相似性和预测虚假新闻方面的有效性。
作者提出的模型主要在文本和视觉相似性上做出了创新,因为作者发现很多虚假新闻的文本和图片并没有什么关系,很多图片只是为了吸引读者注意,还有一些图片本身就是错误的。并且比单模态和多模态简单融合有更好的效果。