【动手学深度学习】多层感知机(MLP)
1 多层感知机的从零开始实现
torch.nn
继续使用Fashion-MNIST图像分类数据集
导入需要的包
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) ##获取迭代器1.1 初始化模型参数
nn.Parameter()
为什么要乘0.01?
多层感知机中的超参数:隐藏层个数,每个隐藏层的隐藏单元个数(通常为2的若干次幂)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
# num_hiddens为单隐藏层中隐藏单元的个数
W1 = nn.Parameter(torch.randn( num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]1.2 激活函数
为了进一步了解实现的细节,我们在这里自己定义一个ReLU激活函数,而不是直接调用内置relu函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a) # 返回0和X中的最大值1.3 模型
@
代表矩阵乘法运算,相当于torch.mul()
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)1.4 损失函数
nn.CrossEntropyLoss()
用于分类任务使用
直接使用内置函数计算softmax和交叉熵损失
loss = nn.CrossEntropyLoss(reduction='none')1.5 训练
torch.optim
torch.optim 有各种优化算法,可以使用优化器的 step 来进行前向传播,而不用人工的更新所有参数
opt.step()
opt.zero_grad() # 将所有的梯度置为 0,需要在下个批次计算梯度之前调用
多层感知机的训练过程与softmax回归的训练过程完全相同。 可以直接调用d2l包的train_ch3函数
num_epochs, lr = 10, 0.1 #num_epochs表示迭代周期数
updater = torch.optim.SGD(params, lr=lr) # 实例化优化算法
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)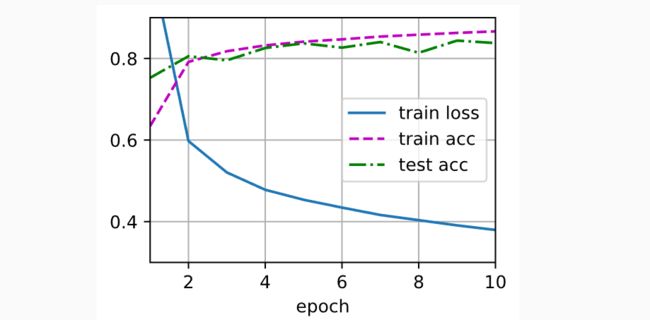
1.6 模型评估
在测试数据上应用这个模型,调用d2l包的train_ch3函数
d2l.predict_ch3(net, test_iter)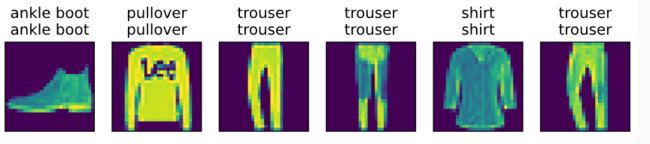
2 多层感知机的简洁实现
导入需要的包
import torch
from torch import nn
from d2l import torch as d2l2.1 模型
全连接层
全连接层之前的层的作用是提取特征
全连接层的作用是分类
net.apply
与softmax回归的简洁实现( 3.7节)相比, 唯一的区别是我们添加了2个全连接层(之前我们只添加了1个全连接层)
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(), # 调用激活函数
nn.Linear(256, 10)) # 输出时不需要调用激活函数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)2.2 小结
对于相同的分类问题,多层感知机的实现与softmax回归的实现相同,只是多层感知机的实现里增加了带有激活函数的隐藏层
3 拓展学习
3.1 torch.nn
参考:[Pytorch系列-30]:神经网络基础 - torch.nn库五大基本功能:nn.Parameter、nn.Linear、nn.functioinal、nn.Module、nn.Sequentia_文火冰糖的硅基工坊的博客-CSDN博客
3.1.1 torch.nn概述
nn是torch提供的帮助程序员设计和训练神经网络的库,帮助程序员执行以下与神经网络相关的行为:
创建神经网络
训练神经网络
保存神经网络
恢复神经网络
包括了以下五大基本功能模块
torch.nn.Parameter
torch.nn.Linear(in_features,out_features,bias=True)
torch.nn.Module
torch.nn.Sequential
3.1.2 torch.nn.Linear(in_features,out_features,bias=True)
用于创建一个多输入、多输出的全连接层
nn.Linear本身并不包含激活函数
in_features
指的是输入的二维张量的大小
in_features的数量,决定的参数的个数 Y = WX + b, X的维度就是in_features,X的维度决定的W的维度, 总的参数个数 = in_features + 1(?还没看懂)
out_features
指的是输出的二维张量的大小
3.1.3 torch.nn.Parameter *
Parameter实际上也是Tensor,也就是说是一个多维矩阵,是Variable类中的一个特殊类。
当我们创建一个model时,nn会自动创建相应的参数parameter,并会自动累加到模型的Parameter 成员列表中。
3.1.4 torch.nn.Module *
是一个抽象的概念,既可以表示神经网络中的某个层(layer),也可以表示一个包含很多层的神经网络
model.parameter()
model.butters()
model.state_dict()
model.modules()
forward(),to()
https://pytorch.org/docs/stable/nn.html#torch.nn.Module
3.1.5 torch.nn.Sequential*
nn.Sequential是一个有序的容器,该类将按照传入构造器的顺序,依次创建相应的函数,并记录在Sequential类对象的数据结构中,同时以神经网络模块为元素的有序字典也可以作为传入参数。
因此,Sequential可以看成是有多个函数运算对象,串联成的神经网络,其返回的是Module类型的神经网络对象。
3.2 卷积神经网络(CNN)入门讲解
CNN 入门讲解:什么是全连接层(Fully Connected Layer)? - 知乎 (zhihu.com)
CNN入门讲解:如何理解卷积神经网络的结构(Structure)? - 知乎 (zhihu.com)
今天无意中找到了知乎一系列CNN入门讲解专栏,读下来觉得很好理解,今天先看了两篇,以后每天也多看看。
去成为你想成为的人吧。