经典论文复现 | LSGAN:最小二乘生成对抗网络
过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”。这是今年 AAAI 会议上一个严峻的报告。 人工智能这个蓬勃发展的领域正面临着实验重现的危机,就像实验重现问题过去十年来一直困扰着心理学、医学以及其他领域一样。最根本的问题是研究人员通常不共享他们的源代码。
可验证的知识是科学的基础,它事关理解。随着人工智能领域的发展,打破不可复现性将是必要的。为此,PaperWeekly 联手百度 PaddlePaddle 共同发起了本次论文有奖复现,我们希望和来自学界、工业界的研究者一起接力,为 AI 行业带来良性循环。
作者丨文永亮
学校丨华南理工大学
研究方向丨目标检测、图像生成
笔者这次选择复现的是 Least Squares Generative Adversarial Networks,也就是 LSGANs。

近几年来 GAN 是十分火热的,由 Goodfellow 在 14 年发表论文 Generative Adversarial Nets [1] 开山之作以来,生成式对抗网络一直都备受机器学习领域的关注,这种两人零和博弈的思想十分有趣,充分体现了数学的美感。从 GAN 到 WGAN[2] 的优化,再到本文介绍的 LSGANs,再到最近很火的 BigGAN [3],可以说生成式对抗网络的魅力无穷,而且它的用处也是非常奇妙,如今还被用在例如无负样本的情况下如何训练分类器,例如 AnoGAN [4]。
LSGANs 这篇经典的论文主要工作是把交叉熵损失函数换做了最小二乘损失函数,这样做作者认为改善了传统 GAN 的两个问题,即传统 GAN 生成的图片质量不高,而且训练过程十分不稳定。
LSGANs 试图使用不同的距离度量来构建一个更加稳定而且收敛更快的,生成质量高的对抗网络。但是我看过 WGAN 的论文之后分析这一损失函数,其实并不符合 WGAN 作者的分析。在下面我会详细分析一下为什么 LSGANs 其实并没有那么好用。
论文复现代码:
http://aistudio.baidu.com/aistudio/#/projectdetail/25767
LSGANs的优点
我们知道传统 GAN 生成的图片质量不高,传统的 GANs 使用的是交叉熵损失(sigmoid cross entropy)作为判别器的损失函数。
在这里说一下我对交叉熵的理解,有两个分布,分别是真实分布 p 和非真实分布 q。
信息熵是 ,就是按照真实分布 p 这样的样本空间表达能力强度的相反值,信息熵越大,不确定性越大,表达能力越弱,我们记作 H(p)。 交叉熵就是
,就是按照真实分布 p 这样的样本空间表达能力强度的相反值,信息熵越大,不确定性越大,表达能力越弱,我们记作 H(p)。 交叉熵就是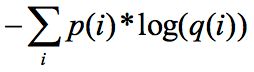 ,可以理解为按照不真实分布 q 这样的样本空间表达能力强度的相反值,记作 H(p,q)。
,可以理解为按照不真实分布 q 这样的样本空间表达能力强度的相反值,记作 H(p,q)。
KL 散度就是 D(p||q) = H(p,q) - H(p),它表示的是两个分布的差异,因为真实分布 p 的信息熵固定,所以一般由交叉熵来决定,所以这就是为什么传统 GAN 会采用交叉熵的缘故,论文也证明了 GAN 损失函数与 KL 散度的关系。
我们知道交叉熵一般都是拿来做逻辑分类的,而像最小二乘这种一般会用在线性回归中,这里为什么会用最小二乘作为损失函数的评判呢?
使用交叉熵虽然会让我们分类正确,但是这样会导致那些在决策边界被分类为真的、但是仍然远离真实数据的假样本(即生成器生成的样本)不会继续迭代,因为它已经成功欺骗了判别器,更新生成器的时候就会发生梯度弥散的问题。
论文指出最小二乘损失函数会对处于判别成真的那些远离决策边界的样本进行惩罚,把远离决策边界的假样本拖进决策边界,从而提高生成图片的质量。作者用下图详细表达了这一说法:

我们知道传统 GAN 的训练过程十分不稳定,这很大程度上是因为它的目标函数,尤其是在最小化目标函数时可能发生梯度弥散,使其很难再去更新生成器。而论文指出 LSGANs 可以解决这个问题,因为 LSGANs 会惩罚那些远离决策边界的样本,这些样本的梯度是梯度下降的决定方向。
论文指出因为传统 GAN 辨别器 D 使用的是 sigmoid 函数,并且由于 sigmoid 函数饱和得十分迅速,所以即使是十分小的数据点 x,该函数也会迅速忽略样本 x 到决策边界 w 的距离。这就意味着 sigmoid 函数本质上不会惩罚远离决策边界的样本,并且也说明我们满足于将 x 标注正确,因此辨别器 D 的梯度就会很快地下降到 0。
我们可以认为,交叉熵并不关心距离,而是仅仅关注于是否正确分类。正如论文作者在下图中所指出的那样,(a)图看到交叉熵损失很容易就达到饱和状态,而(b)图最小二乘损失只在一点达到饱和,作者认为这样训练会更加稳定。

LSGANs的损失函数
传统 GAN 的损失函数:

LSGANs 的损失函数:

其中 G 为生成器(Generator),D 为判别器(Discriminator),z 为噪音,它可以服从归一化或者高斯分布,![]() 为真实数据 x 服从的概率分布,
为真实数据 x 服从的概率分布,![]() 为 z 服从的概率分布。
为 z 服从的概率分布。![]() 为期望值,
为期望值,![]() 同为期望值。
同为期望值。
def generator(z, name="G"):
with fluid.unique_name.guard(name+'_'):
fc1 = fluid.layers.fc(input = z, size = 1024)
fc1 = fluid.layers.fc(fc1, size = 128 * 7 * 7)
fc1 = fluid.layers.batch_norm(fc1,act = 'tanh')
fc1 = fluid.layers.reshape(fc1, shape=(-1, 128, 7, 7))
conv1 = fluid.layers.conv2d(fc1, num_filters = 4*64,
filter_size=5, stride=1,
padding=2, act='tanh')
conv1 = fluid.layers.reshape(conv1, shape=(-1,64,14,14))
conv2 = fluid.layers.conv2d(conv1, num_filters = 4*32,
filter_size=5, stride=1,
padding=2, act='tanh')
conv2 = fluid.layers.reshape(conv2, shape=(-1,32,28,28))
conv3 = fluid.layers.conv2d(conv2, num_filters = 1,
filter_size=5, stride=1,
padding=2,act='tanh')
# conv3 = fluid.layers.reshape(conv3, shape=(-1,1,28,28))
print("conv3",conv3)
return conv3
▲ 生成器代码展示
def discriminator(image, name="D"):
with fluid.unique_name.guard(name+'_'):
conv1 = fluid.layers.conv2d(input=image, num_filters=32,
filter_size=6, stride=2,
padding=2)
conv1_act = fluid.layers.leaky_relu(conv1)
conv2 = fluid.layers.conv2d(conv1_act, num_filters=64,
filter_size=6, stride=2,
padding=2)
conv2 = fluid.layers.batch_norm(conv2)
conv2_act = fluid.layers.leaky_relu(conv2)
fc1 = fluid.layers.reshape(conv2_act, shape=(-1,64*7*7))
fc1 = fluid.layers.fc(fc1, size=512)
fc1_bn = fluid.layers.batch_norm(fc1)
fc1_act = fluid.layers.leaky_relu(fc1_bn)
fc2 = fluid.layers.fc(fc1_act, size=1)
print("fc2",fc2)
return fc2
▲ 判别器代码展示
作者提出了两种 abc 的取值方法:
1. 使 b - c = 1,b - a = 2,例如 a = -1,b = 1,c = 0:

2. 使 c = b,用 0-1 二元标签,我们可以得到:

作者在文献中有详细推倒过程,详细说明了 LSGAN 与 f 散度之间的关系,这里简述一下。
通过对下式求一阶导可得到 D 的最优解:

代入:
![]()
其中另加项![]() 并不影响
并不影响![]() 的值,因为它不包含参数 G。
的值,因为它不包含参数 G。
最后我们设 b - c = 1,b - a =2 就可以得到:

其中![]() 就是皮尔森卡方散度。
就是皮尔森卡方散度。
LSGANs未能解决的地方
下面我会指出 LSGANs 给出的损失函数到底符不符合 WGAN 前作的理论。关于 WGAN 前作及 WGAN 论文的分析可以参考本文 [5]。
上面我们指出了 D 的最优解为公式(5),我们最常用的设 a=-1,b=1,c=0 可以得出:
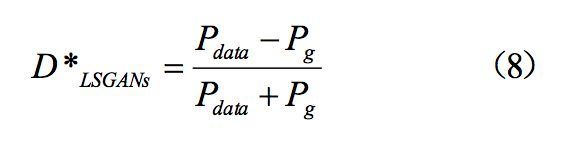
把最优判别器带入上面加附加项的生成器损失函数可以表示为:
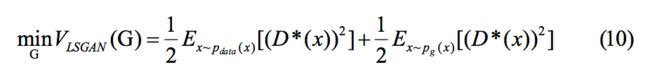
也就是优化上面说的皮尔森卡方散度,其实皮尔森卡方散度和 KL 散度、JS 散度有一样的问题,根据 WGAN 给出的理论,下面用 P1,P2 分别表示![]() 和
和![]() 。
。
当 P1 与 P2 的支撑集(support)是高维空间中的低维流形(manifold)时,P1 与 P2 重叠部分测度(measure)为 0 的概率为 1。也就是 P1 和 P2 不重叠或重叠部分可忽略的可能性非常大。
对于数据点 x,只可能发生如下四种情况:
1. P1(x)=0,P2(x)=0
2. P1(x)!=0,P2(x)!=0
3. P1(x)=0,P2(x)!=0
4. P1(x)!=0,P2(x)=0
可以想象成下面这幅图,假设 P1(x) 分布就是 AB 线段,P2(x) 分布就是 CD 线段,数据点要么在两条线段的其中一条,要么都不在,同时在两条线段上的可能性忽略不计。

情况 1 是没有意义的,而情况 2 由于重叠部分可忽略的可能性非常大所以对计算损失贡献为 0,情况 3 可以算出 D*=-1,损失是个定值 1,情况 4 类似。
所以我们可以得出结论,当 P1 和 P2 不重叠或重叠部分可忽略的可能性非常大时,当判别器达到最优时,生成器仍然是不迭代的,因为此时损失是定值,提供的梯度仍然为 0。同时我们也可以从另一个角度出发,WGAN 的 Wasserstein 距离可以变换如下:
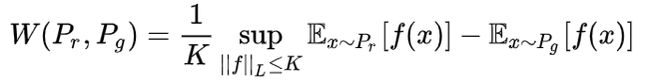
它要求函数 f 要符合 Lipschitz 连续,可是最小二乘损失函数是不符合的,他的导数是没有上界的。所以结论就是 LSGANs 其实还是未能解决判别器足够优秀的时候,生成器还是会发生梯度弥散的问题。
两种模型架构和训练
模型的结构
作者也提出了两类架构:
第一种处理类别少的情况,例如 MNIST、LSUN。网络设计如下:
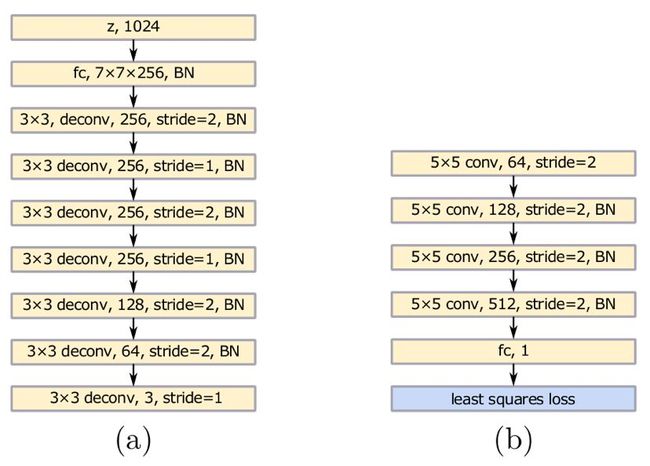
第二类处理类别特别多的情形,实际上是个条件版本的 LSGAN。针对手写汉字数据集,有 3740 类,提出的网络结构如下:

训练数据
论文中使用了很多场景的数据集,然后比较了传统 GANs 和 LSGANs 的稳定性,最后还通过训练 3740 个类别的手写汉字数据集来评价 LSGANs。

▲ 本文使用的数据集列表
在 LSUN 和 HWDB1.0 的这两个数据集上使用 LSGANs 的效果图如下,其中 LSUN 使用了里面的 bedroom, kitchen, church, dining room 和 conference room 五个场景,bedroom 场景还对比了 DCGANs 和 EBGANs 的效果在图 5 中,可以观察到 LSGANs 生成的效果要比那两种的效果好。


图 7 则体现了 LSGANs 和传统 GANs 生成的图片对比。

通过实验观察,作者发现 4 点技巧:
1. 生成器 G 带有 batch normalization 批处理标准化(以下简称 BN)并且使用 Adam 优化器的话,LSGANs 生成的图片质量好,但是传统 GANs 从来没有成功学习到,会出现 mode collapse 现象;
2. 生成器 G 和判别器 D 都带有 BN 层,并且使用 RMSProp 优化器处理,LSGANs 会生成质量比 GANs 高的图片,并且 GANs 会出现轻微的 mode collapse 现象;
3. 生成器 G 带有 BN 层并且使用 RMSProp 优化器,生成器 G 判别器 D 都带有 BN 层并且使用 Adam 优化器时,LSGANs 与传统 GANs 有着相似的表现;
4. RMSProp 的表现比 Adam 要稳定,因为传统 GANs 在 G 带有 BN 层时,使用 RMSProp 优化可以成功学习,但是使用 Adam 优化却不行。
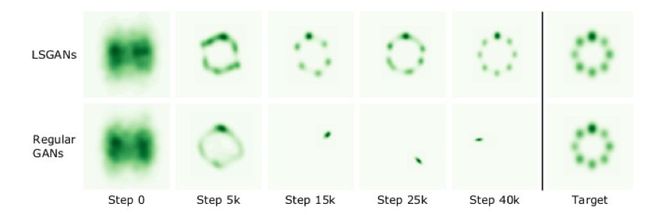
下面是使用 LSGANs 和 GANs 学习混合高斯分布的数据集,下图展现了生成数据分布的动态结果,可以看到传统 GAN 在 Step 15k 时就会发生 mode collapse 现象,但 LSGANs 非常成功地学习到了混合高斯分布。
论文具体实现
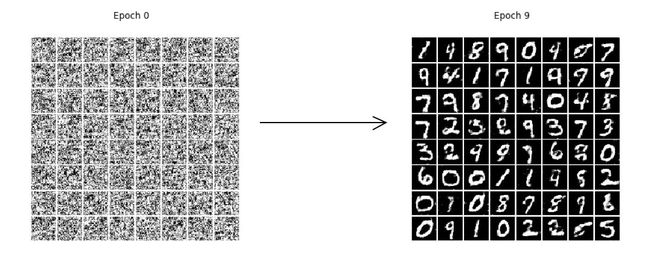
笔者使用了 MNIST 数据集进行实验,具体实现效果如下:
LSGANs:
GAN:

从本次用 MNIST 数据训练的效果来看,LSGANs 生成的效果似乎是比 GAN 的要清晰高质量一些。
总结
LSGANs 是对 GAN 的一次优化,从实验的情况中,笔者也发现了一些奇怪的现象。我本来是参考论文把判别器 D 的损失值,按真假两种 loss 加起来一并放入 Adam 中优化,但是无论如何都学习不成功,梯度还是弥散了,最后把 D_fake_loss 和 D_real_loss 分为两个 program,放入不同的 Adam 中优化判别器D 的参数才达到预期效果。
这篇论文中的思想是非常值得借鉴的,从最小二乘的距离的角度考量,并不是判别器分类之后就完事了,但是 LSGANs 其实还是未能解决判别器足够优秀的时候,生成器梯度弥散的问题。
关于PaddlePaddle
笔者反馈:帮助文档有点少,而且我本来就直接写好了想改成使用 GPU 运算,没找到怎么改;
PaddlePaddle团队:关于如何使用 GPU 运行,可以看下执行器 Executor(单 GPU 或单线程 CPU 执行器)或 ParallelExecutor(多 GPU 或多线程 CPU 执行器,也可以单 GPU/线程 CPU 执行)的文档,前者指定 place 为 CUDAPlace,后者接口有个 use_cuda,具体请参考文档。也可以看 models repo 例子,比如 image_classification 或 text_classification 的例子。
笔者反馈:Program 这个概念有点新颖,一个模型可以有多个 Program,但是我实现的 GAN 可以只用一个,也可以分别放进三个 Program,没有太了解到 Program 这个概念的优越之处,我还是像计算图那样使用了,官方也没给出与 TensorFlow 的对比。
PaddlePaddle团队:关于 Program 设计可以参考官方文档。这里提一点,在用户使用的直观感受中和 TensorFlow graph 不同的是,凡是放在一个 Program 里 op,只要运行该 Program,这些 op 就都会执行;而 TensorFlow,指定一个 variable,只运行以该 variable 为叶子节点的 graph,其他多余 node 不执行,这是最大的用户感受到的区别。
至于一个 Program 还是多个 Program,看用户使用需求而定,多个 Program 时要注意的东西就比较多,例如是否要参数共享等,当然运行多次的时间代价也稍多。 如果是 GAN 也可以参考 models repo 的例子。
小道消息:听说全新版本的 PaddlePaddle 已于今日发布哦。
参考文献
[1]. I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems (NIPS), pp. 2672–2680, 2014.
[2]. M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein GAN. arXiv preprint arXiv:1701.07875, 2017.
[3]. Andrew Brock, Jeff Donahue and Karen Simonyan. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv:1809.11096, 2018.
[4]. Schlegl, Thomas, et al. "Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery." arXiv preprint arXiv:1703.05921 (2017).
[5]. https://zhuanlan.zhihu.com/p/25071913?from_voters_page=true

文章来源:PaperWeekly
