2022.1.15 第十三次周报
文章目录
- 前言
- 一、论文阅读《ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels》
-
- Abstract摘要
- Introduction介绍
- Method方法
-
- Kernels内核
- Transform转换
- Classifier分类器
- Complexity Analysis复杂性分析
- Experiments实验
- Conclusion结论
- 二、膨胀卷积
-
- 一般卷积
- 膨胀卷积
- 代码
- 总结
前言
This week ,《ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels》 has read and analyzed .Paper show that simple linear classifiers using random convolutional kernels achieve state-of-the-art accuracy with a fraction of the computational expense of existing methods. At the same time, the expansion convolution that is not understood in the paper is further studied.
一、论文阅读《ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels》
Abstract摘要
大多数时间序列分类方法都具有很高的计算复杂度,即使对于较小的数据集也需要大量的训练时间,并且对于较大的数据集也难以处理。此外,许多现有的方法都专注于单一类型的特征,如形状或频率。
基于卷积神经网络对时间序列分类的最近成功,论文证明了使用随机卷积核的简单线性分类器可以实现最先进的精度,而计算成本仅为现有方法的一小部分。
Introduction介绍
大多数时间序列分类方法都具有很高的计算复杂度,即使对于较小的数据集也需要大量的训练时间,并且根本无法扩展到大型数据集。这推动了更可扩展方法的开发,如邻近森林、TS-CHIEF 和InceptionTime 。
论文中表示,通过使用随机卷积核转换时间序列,并使用转换后的特征来训练线性分类器,即使是这些最新的、更可扩展的方法所需要的时间的一小部分,也可以实现最先进的分类精度。其中称这种方法为Rocket(随机卷积核变换)。
Rocket与最先进的分类器的比较:
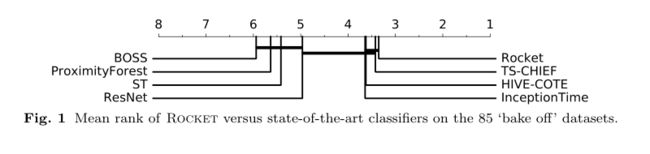
现有的时间序列分类方法通常侧重于单一表示,如形状、频率或方差。卷积核构成了一种单一的机制,可以捕获许多以前需要各自专门技术的特征,并且已被证明在卷积神经网络中有效地用于时间序列分类,如ResNet ,以及InceptionTime。
与典型卷积神经网络中使用的学习卷积核相比,作者证明了生成大量随机卷积核是有效的,这些随机卷积核结合起来可以捕获与时间序列分类相关的特征(尽管单独地,单个随机卷积核可能只能非常近似地捕获给定时间序列中的相关特征)。
Rocket在UCR档案中的数据集上实现了最先进的分类精度(Dau等人,2019年),但只需要现有方法训练时间的一小部分。图1显示了Rocket与来自UCR档案的85个“烘烤”数据集上的几种最先进的时间序列分类方法的平均排名(。受限于单个CPU核心,Rocket的总训练时间为:-拥有最大训练集的“烘烤”数据集(ElectricDevices,有8,926个训练示例)为6分钟,而邻近森林为1小时35分钟,TS-CHIEF为2小时24分钟,InceptionTime为7小时46分钟(在gpu上训练);时间序列最长的“bake off”数据集(HandOutlines,时间序列长度为2709)为4分52秒,而InceptionTime(在gpu上训练)为8小时10分钟,Proximity Forest为近3天,TS-CHIEF为4天以上。
Rocket在所有85个“烘烤”数据集上的总计算时间(训练和测试)是1小时50分钟,相比之下,InceptionTime(使用gpu训练和测试)超过6天,Proximity Forest和TS-CHIEF每个都超过11天。对于大型数据集,Rocket也更具有可扩展性,训练复杂度在时间序列长度和训练示例数量上都是线性的。Rocket可以在1小时15分钟内从100万个时间序列中学习,与邻近森林(Proximity Forest)的精度相似,后者需要超过16个小时才能对相同数量的数据进行训练。
Method方法
Rocket使用大量随机卷积核(即具有随机长度、权重、偏差、膨胀和填充的核)来转换时间序列。
转换后的特征被用来训练线性分类器。实际上,Rocket和逻辑回归的组合形成了一个具有随机核权重的单层卷积神经网络,其中转换的特征形成了训练过的softmax层的输入。然而,在实践中,对于除了最大的数据集之外的所有数据集,我们使用岭回归分类器,它具有正则化超参数(而没有其他超参数)快速交叉验证的优点。
尽管如此,由于使用随机梯度下降训练的逻辑回归对于非常大的数据集更具有可扩展性,当训练示例的数量远远大于特征的数量时,我们使用逻辑回归。
将Rocket与典型卷积神经网络中使用的卷积层,以及与之前使用时间序列的卷积核(包括随机核)四个方面的区别:
-
Rocket使用了大量的内核。由于只有一层核,并且不学习核权值,计算卷积的计算成本很低,并且可以使用大量的核,而计算成本相对较低。
-
Rocket使用了大量不同的内核。与典型的卷积网络相反,在典型的卷积网络中,一组内核共享相同的大小、膨胀和填充,对于Rocket来说,每个内核都有随机的长度、膨胀和填充,以及随机的权重和偏差。
-
特别是,Rocket关键地使用了内核膨胀。与卷积神经网络中扩张的典型使用相反,在卷积神经网络中,扩张随着深度呈指数级增长(例如,Yu和Koltun 2016;Bai等。2018;Franceschi et al. 2019),我们对每个内核随机进行膨胀采样,产生各种各样的内核膨胀,捕捉不同频率和尺度的模式,这对方法的性能至关重要。
-
除了使用生成的特征图的最大值(广义上讲,类似于全局最大池化),Rocket还使用了一个额外的,据我们所知,新颖的特性:正值的比例(或ppv)。这使分类器能够在时间序列中衡量给定模式的流行程度。这是Rocket架构中最关键的一个元素,对其卓越的精度至关重要。
实际上,Rocket的唯一超参数是核数k。
在设置k时,分类精度和计算时间之间存在权衡。一般来说,k值越大分类准确率越高(见4.3.1节),但代价是计算量相应地变长。(变换的复杂度与k成线性关系。)然而,即使有非常多的内核(我们默认使用10,000个),Rocket也非常快。
Kernels内核
Rocket使用卷积核来转换时间序列,就像在典型的卷积神经网络中发现的那样。本质上,内核的所有方面都是随机的:长度、权重、偏置、膨胀和填充。对于每个内核,这些值设置如下:
——长度。长度从{7,9,11}中随机选择,概率相等,使得内核在大多数情况下比输入时间序列短得多。
——重量。权重从正态分布∀w∈W, W∼N(0,1)中采样,设置后均值居中。
——偏见。偏差从均匀分布b ~ U(−1,1)中采样。仅使用特征图中的正值。
——扩张。膨胀以指数尺度d = 2x进行采样.
——填充。当生成每个内核时,将决定(随机地,具有相等的概率)在应用内核时是否使用填充。
——步伐永远是一个。我们不应用非线性,如ReLU的结果特征映射。
Transform转换
每个核应用于每个输入时间序列,产生一个特征映射。卷积运算涉及核和输入时间序列之间的滑动点积。对给定的时间序列X,从X中的位置i应用核ω,膨胀d,得到的结果为:
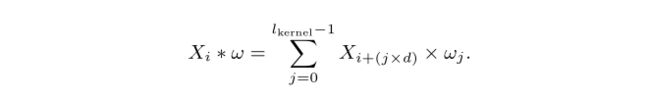
Rocket从每个特征映射中计算两个聚合特征,每个内核生成两个实数作为特征,并组成我们的变换:
——最大值(一般来说,相当于全局最大池);
——正值的比例(或ppv)。
池化,包括全局平均池化(Lin et al. 2014)和全局最大池化,用于卷积神经网络的降维和空间(或时间)不变性。Rocket在每个特征图上计算的另一个特征是ppv。ppv直接捕获与给定模式匹配的输入的比例。
对于k个内核,Rocket在每个时间序列中生成2k个特征(即ppv和max)。
Classifier分类器
转换后的特征被用来训练线性分类器。原则上,火箭可以与任何分类器一起使用。我们发现,当与线性分类器一起使用时,Rocket非常有效(线性分类器有能力利用大量特征中每个特征的少量信息)。
逻辑回归。Rocket可以与逻辑回归和随机梯度下降结合使用。
Complexity Analysis复杂性分析
Rocket的计算复杂度有两个方面:(1)变换本身的复杂度;(2)利用转换后的特征训练线性分类器的复杂度。
Experiments实验
本节在UCR档案评估了Rocket,证明了Rocket与当前最先进的方法相比具有竞争力,在85个“烘焙”数据集上获得了最佳平均排名。
根据训练集大小和时间序列长度来评估可伸缩性,证明Rocket比目前的方法快几个数量级。我们还评估了不同内核参数的影响,显示了Rocket的几个备选配置性能相似,这很好地表明了这个想法的力量,而不是它的微调。除非另有说明,所有实验都使用10,000粒核。
(实验结果不做分析)
Conclusion结论
卷积核是一种单一的、功能强大的工具,它可以捕获现有时间序列分类方法所使用的许多特征。论文表明,与其学习核权重,大量的随机核(虽然孤立地只近似相关模式)组合在一起对于捕获时间序列中的判别模式是非常有效的。
此外,随机核具有非常低的计算需求,使得学习和分类非常快。论文提出的方法利用随机卷积核来转换和分类时间序列,Rocket,以现有方法的一小部分计算成本实现了最先进的精度。Rocket还可以扩展到数百万个时间序列。
Rocket主要利用正数值的比例(或ppv)来总结特征图的输出,允许分类器在给定的时间序列中对模式的流行程度进行加权。论文发现这实际上比在传统的最大池化操作中应用的简单最大更有效。可以肯定的是,ppv对其他数据类型(如图像)也有效。
在未来的工作中,作者建议探索Rocket的特征选择,Rocket在多元时间序列中的应用,Rocket在时间序列数据之外的应用,以及将Rocket的方面与学习的内核一起使用。
二、膨胀卷积
一般卷积
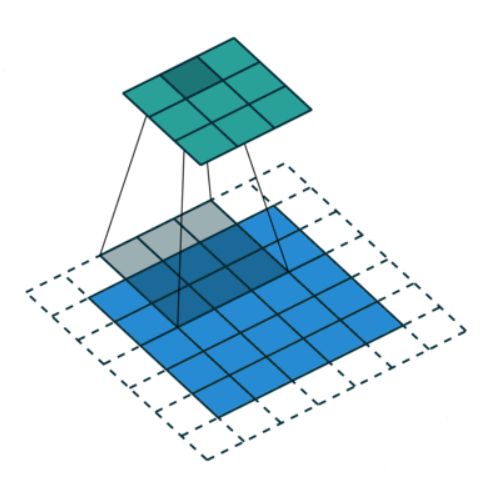
膨胀卷积
Dilation 卷积,也被称为:空洞卷积、膨胀卷积
dilation 是对 kernel 进行膨胀,多出来的空隙用 0 padding。用于克服 stride 中造成的 失真问题

如上图,膨胀卷积的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者自然语言处理中需要较长的sequence信息依赖的问题中,都能很好的应用。
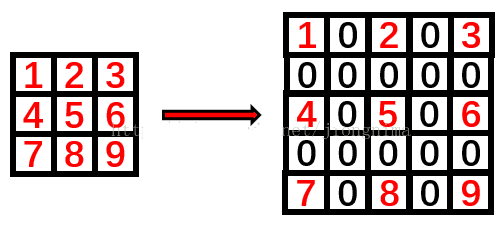
对应关系是 kd = ( k − 1 ) × d + 1, 对原始kernel 进行 d 倍 dilation 之后得到新的 kd , k 一般是奇数,d一般是偶数,从而保证了 kd 也是奇数。注意,使用dilation的时候,先把 k dilation 成 kd ,去卷积运算,生成下一层的 feature map。但是参数存储的还是原始的 k的大小.
例子:这样最大的好处就是卷积核的参数没变(还是9个),但是感受野从 3x3 变成了 5x5. 虽然一个格子,计算的是5x5 感受野里的 9个格子,但是卷积核整体看到了 7x7 的field,而不是 dilation 之前 5x5 的 field。
代码
tf.nn.atrous_conv2d(value,filters,rate,padding,name=None)
value:输入的卷积图像,[batch, height, width, channels]。
filters:卷积核,[filter_height, filter_width, channels, out_channels],通常NLP相关height设为1。
rate:正常的卷积通常会有stride,即卷积核滑动的步长,而膨胀卷积通过定义卷积和当中穿插的rate-1个0的个数,实现对原始数据采样间隔变大。
padding:”SAME”:补零 ; ”VALID”:丢弃多余的
总结
本周对论文《ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels》进行了学习,了解到了一个新的模型Rocket(随机卷积核变换),其中论文表明,与其学习核权重,大量随机卷积核(即具有随机长度、权重、偏差、膨胀和填充的核)组合在一起对于捕获时间序列中的判别模式是非常有效的。并且对论文中不懂的膨胀卷积进行了进一步学习。