2022.10.16 第二十六次周报
目录
前言
文献阅读-《基于卷积神经网络的手语静态手势识别及基于ORB描述符和Gabor滤波器的特征提取方法》
核心思路
主要操作
1.预处理
2.特征提取
3.结构的架构
工程-CNN内部结构与方案设计
卷积层
RELU层
池化层
全连接层
代码-CNN手写数字识别
总结
前言
What has been learned this week revolves around convolutional neural networks (CNNs).In the literature, it has been learned how CNN eliminates a relatively small role in the large number of extracted materials.We specifically understand the role and principle of various layers in CNN, such as convolutional layer, pooling layer, fully connected layer and so on.
本周学习的内容主要围绕卷积神经网络(CNN)来展开。在文献中学习到CNN如何在提取的大量素材中消除作用比较小的。我们具体了解到CNN中各种层的作用和原理,比如卷积层,池化层,全连接层等等。
文献阅读-《基于卷积神经网络的手语静态手势识别及基于ORB描述符和Gabor滤波器的特征提取方法》
题目:Static hand gesture recognition in sign language based on convolutional neural network with feature extraction method using ORB descriptor and Gabor filter
作者:
Mahin Moghbeli Damaneh;Farahnaz Mohanna;Pouria Jafari
核心思路
本文介绍了一种新的深度学习神经网络结构,用于识别手语中的静态手势。所提出的结构包括卷积神经网络(CNN)和经典的非智能特征提取方法。在所提出的结构中,手势图像经过预处理并去除其背景后,经过三个不同的特征提取流,以很好地提取有效特征并确定手势类。这三个流独立提取自己的特定特征,由手势分类中广泛使用的三种方法组成,分别称为 CNN、Gabor 滤波器和 ORB 特征描述符。然后将这些特征合并并形成最终的特征向量。通过结合这些有效的方法,除了在手势分类中实现非常高的精度外,所提出的结构还能够更好地抵抗手势中的旋转和模糊性等不确定性。
主要操作
1.预处理
从图像中识别静态手势的第一步是执行预处理操作。在建议的结构中,预处理包括调整手部区域大小和分割的两个操作。为了使用卷积神经网络提取特征,独立于输入图像并为所有不同的图像数据库创建统一的在线例程,每个输入图像的大小最初更改为32×32维。32 × 32 的图像大小是向 CNN 输入图像的最佳大小,以便在更短的时间内以更低的计算复杂性实现最高精度)。此外,为了提高分类的准确性并增加所提结构对手势的重点,从图像背景中分割了一个手部区域。
输入图像中手部区域的分割取决于所使用的图像数据库和相机捕获图像的位置。在这里,根据可用的标准和一般数据库,应用Canny边缘检测器方法。这种多步边缘检测器用于检测200×200输入图像中手势的尖锐不连续性或边缘,并减少图像背景的噪声。通过该算法提取手部边缘后,可以轻松地从输入图像中分割手部区域。下图显示了Canny边缘检测器在ASL字母图像数据库中的示例图像上的性能。

2.特征提取
我们主要在这里来了解一下CNN在该项目中的作用:NN是一种特殊类型的多层人工神经网络,它通过卷积数学运算而不是矩阵乘法来分析输入数据。与多层神经网络相比,这种方法大大减少了处理计算。这些网络的基本思想源于人脑视觉区域的神经结构,卷积网络的主要应用是在图像和视频帧上。CNN的主要部分由内核组成,这些内核可以在长度,宽度和深度三个维度上分析传入的图像。在每个卷积层中,内核在输入要素上水平和垂直移动并执行卷积运算。之后,内核输出通过非线性激活函数,如乙状体或RELU10到下一层。事实上,内核实际上是特征检测器,每个内核检测不同的特征。内核参数在开始时随机选择,但在训练过程中进行调整以实现适当的 CNN 输出。通常,除了卷积层之外,每个CNN还包括其他部分,例如一些池化层和几个完全连接的层。池化层放置在卷积层之间以执行子采样操作。完全连接的图层在拼合提取的特征后使用。全连接层的任务是在卷积层提取的特征与其预期类之间建立适当的连接。因此,全连接层的输出对应于CNN的输入图像类。
3.结构的架构

从顶部开始,在第一个流中,ORB 描述符用于提取输入图像的特征。Gabor过滤器和CNN位于第二个流中,在第三个流中,使用单个CNN。每个流的任务是独立提取自己的特征,这些不同的特征最终组合在最后两个图层中进行分类。
在后面两个流的开头,输入图像的大小调整为 32 × 32 个维度,然后输入到 CNN 流。如前所述,32 × 32 的图像大小是将图像输入到 CNN 的最佳大小,以便在更短的时间内以更低的计算复杂性实现最高精度。在第二个流中,手部图像的纹理特征是通过Gabor滤波器生成,然后输入到CNN中。在第三个流中,另一个CNN直接分析手部图像。第二和第三个流中的 CNN 具有相同的体系结构。然而,第二个流中的CNN是在纹理特征上进行训练的,但是第三个流中的CNN直接应用于32×32手的图像。通过这种方式,从两个不同的角度来看,两个 CNN 用于利用从输入图像识别手势类的所有有用功能。因此,除了通过 ORB 特征描述符提取手部图像特征外,其他两个流中的 CNN 使用两种不同的方法获得手部图像的更多特征。因此,实现了手部图像的独特和有效特征,以识别适当的类。
工程-CNN内部结构与方案设计
CNN是一种人工神经网络,CNN的结构可以分为3层:
- 卷积层(Convolutional Layer) - 主要作用是提取特征。
- 池化层(Max Pooling Layer) - 主要作用是下采样(downsampling),却不会损坏识别结果。
- 全连接层(Fully Connected Layer) - 主要作用是分类。
卷积层
1.提取特征
计算机不能直接对不知道的东西进行预测,比如我们告诉计算机下图是X。

但是如果我们再给出不同的X,比如这样。

计算机就不能识别出来这个是X。这时候CNN要做的,就是如何提取内容为X的图片的特征。
我们都知道,图片在计算机内部以像素值的方式被存储,也就是说两张X在计算机看来,其实是这样子的。


观察这两张X图,可以发现尽管像素值无法一一对应,但也存在着某些共同点。因此,我们就考虑,要将这两张图联系起来,无法进行全体像素对应,但是否能进行局部地匹配?

所以我们从标准的X中提取了三个特征,我们发现只要用这三个feature便可定位到X的某个局部。
feature在CNN中也被成为卷积核(filter),一般是3X3,或者5X5的大小。

2.卷积运算
卷积运算中有两个点非常值得注意,那就是步长和运算规则。
运算规则就是对应相乘,取 feature里的(1,1)元素值,再取图像上蓝色框内的(1,1)元素值,二者相乘等于1。把这个结果1填入新的图中。同理再继续计算其他8个坐标处的值。接下来的工作是对右图九个值求平均,得到一个均值,将均值填入一张新的图中。
这张新的图我们称之为 feature map (特征图)

这个蓝色框我们称之为 “窗口”,窗口的特性呢,就是要会滑动。其实最开始,它应该在起始位置。进行卷积对应相乘运算并求得均值后,滑动窗便开始向右边滑动。根据步长的不同选择滑动幅度。比如,若 步长 stride=1,就往右平移一个像素。若步长 stride=2,就往右平移两个像素。就这么移动到最右边后,返回左边,开始第二排。同样,若步长stride=1,向下平移一个像素。stride=2则向下平移2个像素。直到把一张完整的feature map填满了。
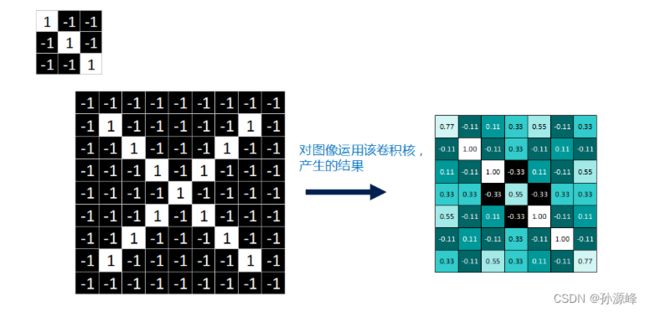
feature map是每一个feature从原始图像中提取出来的“特征”。其中的值,越接近为1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。
一个feature作用于图片产生一张feature map,对这张X图来说,我们用的是3个feature,因此最终产生3个 feature map。

RELU层
在神经网络中用到最多的非线性激活函数是Relu函数,它的公式定义如下:
f(x)=max(0,x)
即,保留大于等于0的值,其余所有小于0的数值直接改写为0。
为什么要这么做呢?上面说到,卷积后产生的特征图中的值,越靠近1表示与该特征越关联,越靠近-1表示越不关联,而我们进行特征提取时,为了使得数据更少,操作更方便,就直接舍弃掉那些不相关联的数据。
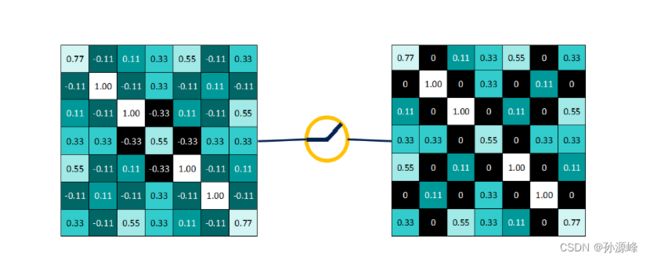
池化层
卷积操作后,我们得到了一张张有着不同值的feature map,尽管数据量比原图少了很多,但还是过于庞大,因此接下来的池化操作就可以发挥作用了,它最大的目标就是减少数据量。
池化分为两种,Max Pooling 最大池化、Average Pooling平均池化。顾名思义,最大池化就是取最大值,平均池化就是取平均值。
拿最大池化举例:选择池化尺寸为2x2,因为选定一个2x2的窗口,在其内选出最大值更新进新的feature map。

最终得到池化后的feature map。可明显发现数据量减少了很多。
因为最大池化保留了每一个小块内的最大值,所以它相当于保留了这一块最佳匹配结果(因为值越接近1表示匹配越好)。这也就意味着它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。这也就能够看出,CNN能够发现图像中是否具有某种特征,而不用在意到底在哪里具有这种特征。这也就能够帮助解决之前提到的计算机逐一像素匹配的死板做法。

全连接层
全连接层要做的,就是对之前的所有操作进行一个总结,给我们一个最终的结果。它最大的目的是对特征图进行维度上的改变,来得到每个分类类别对应的概率值。
局部连接与参数共享是卷积神经网络最重要的两个性质
卷积层采用的是“局部连接”的思想,回忆一下卷积层的操作,是用一个3X3的图与原图进行连接操作,很明显原图中只有一个3X3的窗口能够与它连接起来。那除窗口之外的、未连接的部分怎么办呢? 我们都知道,采用的是将窗口滑动起来的方法后续进行连接。这个方法的思想就是“参数共享” ,参数指的就是filter,用滑动窗口的方式,将这个filter值共享给原图中的每一块区域连接进行卷积运算。

原图片尺寸为9X9,在一系列的卷积、relu、池化操作后,得到尺寸被压缩为2X2的三张特征图。

得到了2X2的特征图后,对其应用全连接网络,再全连接层中有一个非常重要的函数----Softmax,它是一个分类函数,输出的是每个对应类别的概率值。【0.5,0.03,0.89,0.97,0.42,0.15】就表示有6个类别,并且属于第四个类别的概率值0.97最大,因此判定属于第四个类别。
本例中因为只有两个类别X和O,而且数据量到此已经非常少了,因此直接将三个特征图改变维度直接变成一维的数据。(相当于全连接层的每个参数均为1)展开的数据即为属于类别X的概率值,值大小也在对应X的线条粗细中表现出来了。以上所有的操作都是对标准的原图X来进行的,因此最终分类显示即为X毋庸置疑。

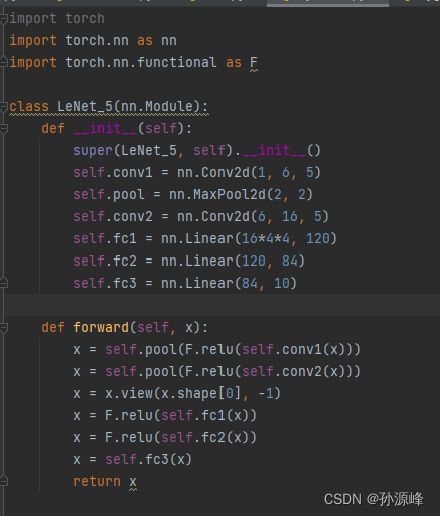
代码-CNN手写数字识别

总结
本周我们主要是针对CNN的框架和每层的作用和结构展开学习。但是说白了这只是一个大致的框架的设计而已,里面的参数具体是多少则是需要训练的。
那么神经网络到底需要训练什么呢?训练的就是那些卷积核(filter)。
下周我们继续学习神经网络的训练与优化,具体的训练方法就是赫赫有名的BP算法---BackProp反向传播算法。