PageRank算法 -- 图算法
一、简述:
PageRank算法是一个迭代求解算法,可以处理网页排名(根据网页的重要性进行排序)、社会影响力分析、文本摘要 等问题。
PageRank算法在1996年由Page和Brin提出
PageRank适用于解决用有向图表示的图数据
二、各节点重要性的迭代计算公式:
PageRank算法是在图上执行一个随机游走模型,根据随机游走者 在有向图上 通过对 节点访问次数或访问概率 的高低 来判断有向图上各个节点的重要程度
首先给出算法的迭代公式,而后用一个实例对该迭代公式的各个部分的意义进行解释:
对于各个节点,其重要程度(其被访问概率)可以按以下公式迭代计算得出:
(以节点X为例)
![]()
其中:
PR(X)表示节点的PR值,即节点 X 被访问到的概率,当迭代结束后,PR(X)则代表节点X的重要程度
d 表示 阻尼系数,指用户达到了当前节点后,愿意沿图上的出边情况 挑选任一节点 继续向后游走的概率
 表示 在图上指向节点X的节点
表示 在图上指向节点X的节点
![]() 表示 节点的出度
表示 节点的出度
三、用一个实例来解释公式的各个部分:
最初的PageRank算法是用于对网页的重要程度进行排名,那么我们就以网页排名作为该算法的一个实际例子对迭代公式的各部分进行解释:
在我们访问网页的时候,网页A可能会链接到其他网页上,比如链接到网页B和网页C。如果将这种网页间的链接关系体现在图结构数据上的话:那么,在图数据中,网页A、B、C均作为节点出现,且由于网页A可以链接到网页B和网页C,那么,在图上节点A应有两条出边,分别指向节点B和节点C。
现在有如下的网页间的链接关系:
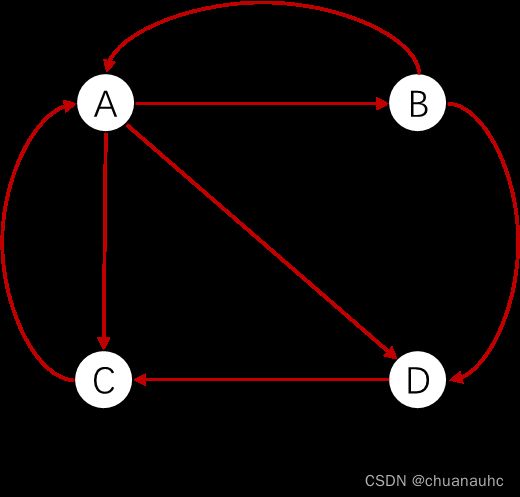
如图1示,有ABCD四个网页,网页间的链接关系有:A链接到BCD;B链接到AD;C链接到A;D链接到C
PageRank算法的核心思想就是:假设有一个随机游走者,在图上进行随机游走。随机游走者经过多次游走后,对不同的节点有着不同的访问次数。显然,随机游走者访问次数多的节点有着更高的重要性。算法就是在模拟随机游走者在图上的随机游走过程,所以每次算法对各个节点PR值的迭代更新都对应着随机游走者在图上的一次随机游走。
PS:随机游走者的"游走"体现为:如图 1 示若随机游走者当前所处位置为节点A,那么,随机游走者可以向BCD三个节点进行下一步的游走;随机游走者的"随机"体现在:随机游走者可以按照概率去随机选择下一个要游走到的节点
(一)常规情况:
直观来感受,若当前随机游走者在网页B上,由于网页B有两条出边分别链接到网页A和D,那么,它有1/2的概率跳转到网页A,有1/2的概率跳转到网页D。由于网页B没有对网页C的跳转链接,所以图数据上BC两节点间没有边,所以由网页B跳转到网页C的概率为0
因此,PageRank算法定义,对于一个网页,若它可以跳转到k个其他网页上去(即,它在图上有k条出边),那么它跳转到这k个网页的概率都是 1/k
以图1为例,先初始化每个网页的被访问概率值PR=1,
即:PR(A)=PR(B)=PR(C)=PR(D)=1
然后,对各个节点进行随机游走分析:
如果随机游走者想访问到网页A,那么要分别从:网页B以1/2的概率链接到节点A;从网页C以1/1的概率链接到节点A;从网页D以0的概率链接到节点A。然后分别代入访问网页BCD的访问概率值 与 对应各个网页链接到网页A的概率相乘,将上述三种情况发生的概率加和 得到 最终可以访问网页A的访问概率。
因此,各个节点的PR值迭代公式应为 :![]()
其中:
PR(X)表示 节点的PR值,即节点X被访问到的概率,当迭代结束后,PR(X)则代表节点X的重要程度
表示 在图上指向节点 X 的节点
![]() 表示 节点的出度
表示 节点的出度
每次迭代时,由于图结构不变,所以计算各节点的访问概率时,只有对应链接到该节点的对应节点PR值在变动,所以,为了加速计算,很自然的想到用矩阵来存储图的链接结构,我们称该矩阵为转移矩阵M
若拓扑图上有n各个节点,那么转移矩阵M的大小应该为n*n的方阵。
如果网页 j 有 k 个出链,那么对于每一个出链所指向的网页 i ,其 M[i][j] = 1/k
对于没有被出链指向的网页 t , 其 M[t][j] = 0
那么,对于本图结构,矩阵M为:

第一次迭代可以计算为: ![]()
![]() 表示第 i 次迭代后的各个节点的访问概率;
表示第 i 次迭代后的各个节点的访问概率;
“  ” 表示数值的点乘;
” 表示数值的点乘; 表示矩阵乘法
表示矩阵乘法
初始时,
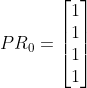
那么经过一次迭代后,
按这种方式迭代10次,各节点的PR值变化如下:

迭代1000次,各点的PR值分别为:
PR(A)=1.494391 PR(B)=0.498127 PR(C)=1.245322 PR(D)=0.747192
对应代码如下:
#include
using namespace std;
int main()
{
double matrix[4][4]={0,0.5,1,0 , 0.33333,0,0,0 , 0.33333,0,0,1 , 0.33333,0.5,0,0 };
double PR[4]={1,1,1,1};
double PRtt[4]={0,0,0,0};
/*for(int i=0;i<4;i++)
for(int j=0;j<4;j++)
{
printf("%f ",matrix[i][j]);
}*/
for(int num=0;num<1000;num++)
{
for(int i=0;i<4;i++)
{
double tt=0;
for(int j=0;j<4;j++)
{
tt += matrix[i][j]*PR[j];
}
PRtt[i]=tt;
}
PR[0]=PRtt[0];PR[1]=PRtt[1];PR[2]=PRtt[2];PR[3]=PRtt[3];
//printf("PR(A)=%f PR(B)=%f PR(C)=%f PR(D)=%f\n",PR[0],PR[1],PR[2],PR[3]);
}
printf("PR(A)=%f PR(B)=%f PR(C)=%f PR(D)=%f\n",PR[0],PR[1],PR[2],PR[3]);
return 0;
} 注意:
“每一轮迭代”的意思是,对节点ABCD的PR值都进行了一次更新。
在上述的这种迭代方式中,对于第 i 轮的迭代:对每个节点的PR值进行更新的时候,都是用的上一轮(即 i-1 轮次)中各个节点的PR值进行计算的。即:在第i轮迭代中,虽然对于节点B来说,新的PR值已经计算完了,但是,在计算CD节点的PR值时,仍旧采用的是B节点在 i-1 轮次的旧PR值。
那么,读者可能会有疑惑,如果实时更新,在同一轮中,用最新的节点PR值对接下来的其他节点进行更新会产生与上述方法有什么不同么?
我们还是采用图 1 对应的图结构进行数值上的对比。只不过在这次的更新方式上,即使在同一轮,PR(A)的值计算结束,接下来计算PR(B)的值时选择用刚刚得到的 更新后的 新的 PR(A)的值。对同一轮的其它节点的计算方法同理。
那么,代码如下:
#include
using namespace std;
int main()
{
double matrix[4][4]={0,0.5,1,0 , 0.33333,0,0,0 , 0.33333,0,0,1 , 0.33333,0.5,0,0 };
double PR[4]={1,1,1,1};
/*for(int i=0;i<4;i++)
for(int j=0;j<4;j++)
{
printf("%f ",matrix[i][j]);
}*/
for(int num=0;num<10;num++)
{
for(int i=0;i<4;i++)
{
double tt=0;
for(int j=0;j<4;j++)
{
tt += matrix[i][j]*PR[j];
}
PR[i]=tt;
}
printf("PR(A)=%f PR(B)=%f PR(C)=%f PR(D)=%f\n",PR[0],PR[1],PR[2],PR[3]);
}
//printf("PR(A)=%f PR(B)=%f PR(C)=%f PR(D)=%f\n",PR[0],PR[1],PR[2],PR[3]);
return 0;
} 按这种方式迭代10次,各节点的PR值变化如下:

迭代1000次,各点的PR值分别为:
PR(A)=1.655606 PR(B)=0.551863 PR(C)=1.379663 PR(D)=0.827795
这样一对比,虽然最终对于这四个节点计算得来的PR值不同,但是迭代后得出的网页节点排名是相同的:A>C>D>B。同时,对于收敛速度来看,仅对该图1对应的例子来说,是第一种方法收敛速度更快。
但,直觉上,我还是会觉得采用第二种方式来更新各个节点的PR值更好一些,所以接下来的演示会采用第二种方式。
(二)非常规情况:终止点问题
上述的PageRank算法可以收敛,需要满足一个条件:
· 处理的图是强连通图,即,从任意节点可以到达其他的节点
但是显然网页节点间的相互链接组成的图,或者其他现实生活中产生的拓扑图是不一定满足这种强连接性的。总有一些网页不指向任何其他的网页节点,即,该网页节点在拓扑图上没有任何的出边。
此时,如果仍旧按照上述的PageRank算法,那么,随机游走者到达这样的网页节点后就会走投无路,随着一次又一次的迭代,随机游走者不断地到达这个不指向任何其他网页节点的 “终止点网页” ,这就会导致在迭代过程中,前面累积的转移概率越变越小,最终变为0。
我们对图 1 进行修改,将节点C →节点A的边去掉,得到图 2 。观察图 2 我们会发现此时的节点C就是一个“终止点”,在拓扑图上,节点C没有任何的出边。

那么 ,此时的转移矩阵M为:

按这种方式迭代10次,各节点的PR值变化如下:

可以很明显的看出来,各点的PR值都在逐渐地变为0
(三)非常规情况:陷阱问题
网页间的链接情况除了上述的终止点问题以外,还有一种情况就是,某个节点只存在一条唯一的出边,并且这条出边指向自己。如下图3所示:

如图3所示的这种情况下,随机游走者到达节点 C 后就无法进入其他的网页节点,相当于被困在了网页节点 C 处。 所以,随着迭代的进行,转移概率会全部集中到节点 C 对应的网页上。这样会使得网页排名无效。
按照上述的PageRank算法,图三所示的转移矩阵M应为:

按这种方式迭代10次,各节点的PR值变化如下:

可以明显的看出来,除了陷阱节点C以外,其他节点的PR值都显著的变为了0。
(四)解决终止点和陷阱点问题
上面过程中,我们认为随机游走者是一个盲目的,只按照节点的出边情况进行盲目游走的游走者
但是,真实情况下的上网者并不会如此盲目
所以,我们用随机游走者模拟上网者时,当它游走到一个终止点的网页时,它可以选择重新在浏览器搜索栏中输入一个新的网址再次进行游走;当它游走到一个陷阱节点时,它同样可以采用向浏览器中搜索栏中输入一个新网址的方式跳出陷阱再次进行游走。
当然,向浏览器中输入的新网址可以是导致当前游走终止的终止点网页或导致游走陷入循环的陷阱点网页,但也有可能是 让游走者进入新的网页,从而跳出终止或者陷阱情况的新网络节点。
为了达到这样的目标,对 “(一)常规情况 ”中提出的节点PR值的迭代计算公式进行更新:
假设拓扑图上的网页节点有N个,那么游走者通过在搜索栏中输入网址到达某个网页节点的概率为 1/N
同时,假设游走者每一步游走时查看当前网页(或者说,按照当前网页给出的链接进一步访问后面的网页)的概率为 d,那么,他拒绝查看当前网页(或者说,拒绝按照当前网页所给出的链接进一步访问后面网页,而是选择从浏览器搜索栏中随机输入某一网页地址进行访问)的概率为 (1-d)
那么,各个节点的PR值迭代计算公式由原来的:![]()
变为:
![]()
所以,很明显,当随机游走者拒绝按照当前网页所给出的链接进一步访问后面网页,而是选择从浏览器搜索栏中随机输入某一网页地址进行访问,那么拓扑图中网页节点的数目为n,那么,进入某任一网页节点的概率自然就是:![]()
而由于 按照当前网页给出的链接进一步访问后面的网页 的概率为 d,所以,原来的PR值迭代公式前面需要再一同乘上参数d。
那对于更新过的PR值结算迭代公式,其代码如下:
#include
using namespace std;
int main()
{
double matrix[4][4]={0,0.5,0,0 , 0.33333,0,0,0 , 0.33333,0,1,1 , 0.33333,0.5,0,0 };
double PR[4]={1,1,1,1};
double d=0.85; //阻尼系数
int N=4; //节点个数
/*for(int i=0;i<4;i++)
for(int j=0;j<4;j++)
{
printf("%f ",matrix[i][j]);
}*/
for(int num=0;num<10;num++)
{
for(int i=0;i<4;i++)
{
double tt=0;
for(int j=0;j<4;j++)
{
tt += matrix[i][j]*PR[j];
}
PR[i]=tt*d + (1-d)/ N ;
}
printf("PR(A)=%f PR(B)=%f PR(C)=%f PR(D)=%f\n",PR[0],PR[1],PR[2],PR[3]);
}
//printf("PR(A)=%f PR(B)=%f PR(C)=%f PR(D)=%f\n",PR[0],PR[1],PR[2],PR[3]);
return 0;
} 按这种方式迭代10次,各节点的PR值变化如下:

迭代1000次后的结果如下:

所以,这四个网页间的重要性排名为:C>D>A>B
参考链接:https://blog.csdn.net/gamer_gyt/article/details/47443877