使用TensorRT对AlphaPose模型进行加速
最近刚完成使用TensorRT对AlphaPose人体姿态估计网络的加速处理,在这里记录一下大概的流程,具体代码我放在这里了。
目前主要有三种方式构建TensorRT的engine模型。
(1) 第一种是使用模型框架自带的方法生成engine模型,比如TensorFlow和MXNet框架支持直接转成TensorRT的engine模型,这种方式虽然便捷,但是运行效率较低;
(2) 第二种是使用C++或者python的API直接构建检测模型,这种方式虽然效率上限高,但是实现步骤较为繁琐,兼容性较低,一旦原推理模型发生变化,需要重新构建TensorRT的推理模型;
(3) 第三种方式就是先将原有模型转成中性模型框架比如ONNX模型,然后从ONNX模型转成TensorRT的engine模型,这是一种效率和实现难度都比较适中的方法。
因此,本文也主要是采用第三种方式,将AlphaPose模型转成onnx模型,然后再由onnx模型转成TensorRT 的engine模型进行推理加速。
1. 由PyTorch转成onnx模型
由PyTorch模型转成onnx模型的过程中,最重要的一个函数就是torch.onnx.export()。当我们指定了一定的输入之后,就会得到一个onnx模型。该函数的函数原型为:
torch.onnx.export(model, # 输入的模型(该模型必须已经加载了权重了)
args, # 输入数据
f, # 输出的onnx模型的名称
export_params=True,
verbose=False, # 打印onnx的具体网络架构(推荐为True)
training=False,
input_names=None, # 模型输入名称列表
output_names=None, # 模型输出名称列表
aten=False,
export_raw_ir=False,
operator_export_type=None,
opset_version=None,
_retain_param_name=True,
do_constant_folding=False, # 进行优化(推荐为True)
example_outputs=None,
strip_doc_string=True,
dynamic_axes=None, # 只对于dynamic shape的模型而言,输入是词典
keep_initializers_as_inputs=None)
根据输入数据的尺寸是否可变,可以将onnx分成static shape的onnx模型以及dynamic shape的onnx模型。前者表示onnx模型的输入数据尺寸只能与上述函数中args数据的尺寸一致,比如args的输入数据尺寸为1*3*416*416,那么最终的onnx模型也只能接收该尺寸的数据;后者表示onnx的输入数据尺寸可以随意变化,而args数据的尺寸可以当做是一个参考,具体细节我们在下文会着重介绍。无论我们需要转成哪一种onnx模型,代码的大致逻辑有三步:
(1)创建检测模型
(2)加载权重
(3)使用torch.onnx.export()函数导出onnx模型
1.1 转成static shape的onnx模型
在static shape的onnx模型转换的过程中,其处理步骤和上面的算法逻辑是一致的。这个代码我放在了pytorch2onnx_dynamic.py文件中了。
第一步:创建检测模型。源码中创建模型的方法有些复杂,就不再赘述。但是目的都是一样的,就是创建检测模型。
pose_model = builder.build_sppe(cfg.MODEL, preset_cfg=cfg.DATA_PRESET)第二步:加载权重。
pose_model.load_state_dict(torch.load(args.checkpoint, map_location=args.device))
pose_model = pose_model.to('cuda:0')第三步:转成onnx模型。这里需要实现设置一下函数的输入变量,比如输入的数据、输入输出的名称等等。
input_names = ['input'] # 模型数据的名称
output_names = ['output'] # 模型输出的名称
dummy_input = torch.randn(args.batch_size, 3, args.height, args.width, dtype=torch.float32).to('cuda:0') # 虚拟的输入数据
onnx_file_name = "alphaPose_{}_3_{}_{}_dynamic.onnx".format(args.batch_size, args.height, args.width) # onnx模型的名称
torch.onnx.export(pose_model, dummy_input, onnx_file_name, input_names=input_names, output_names=output_names,verbose=True, opset_version=11) # 导出onnx模型从上面可以看出,导出static shape的onnx模型的思路非常清晰,也非常的简单。无论对于什么样的模型,我们基本上都可以按照上面的三步走战略实现onnx模型的导出。而对于dynamic shape的onnx模型而言,就稍显复杂。不过,复杂也就复杂在dynamic_axes这个形参的设置上。 下面使用Netron软件来可视化onnx模型的输入输出:
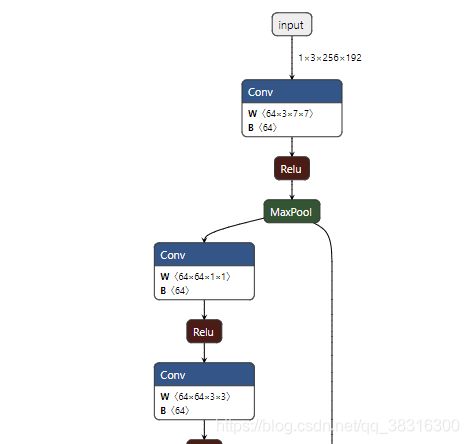
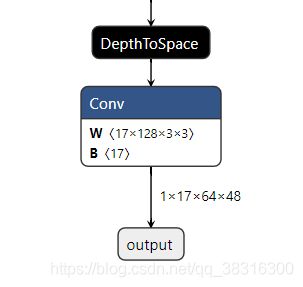
上面可视化部分的输入输出数据都是固定的数值,这表示onnx模型的输入数据的尺寸只能是1*3*256*192,输出数据也只能是1*17*64*48。这样,才表示该模型是static shape的,也就是只能接收固定输入输出尺寸的onnx模型。
1.2 转成dynamic shape的onnx模型
与static shape的onnx模型相比,我们如何让 dynamic shape的onnx模型接收任意形状的输入数据呢?一切的玄机都在torch.onnx.export函数中。在该函数中有一个重要的形参就是dynamic_axes,顾名思义,这个参数表示输入数据中可以动态变化的索引。一般来说,输入数据是一个四维张量(batch_size * C * H * W),当我们想要数据数据的batch size,H,W可以任意改变时,我们可以“告诉”函数,输入数据的第0,2,3个索引是可变的。怎样告诉这个函数呢?可以思考一下下面的例子:
dummy_input = torch.randn(1, 3, args.height, args.width, dtype=torch.float32).to('cuda:0')
onnx_file_name = "alphaPose_-1_3_{}_{}_dynamic.onnx".format(args.height, args.width)
dynamic_axes = {"input": {0: "batch_size", 2: "height", 3: "width"},
"output": {0: "batch_size", 2: "height", 3: "width"}}
torch.onnx.export(pose_model,dummy_input,onnx_file_name,export_params=True,opset_version=11,do_constant_folding=True,input_names=input_names, output_names=output_names,dynamic_axes=dynamic_axes)不难发现dynamic_axes是以词典的形式进行保存的,只要我们指定input和output数据中可变数据的索引就可以了。下面可视化了该onnx模型。
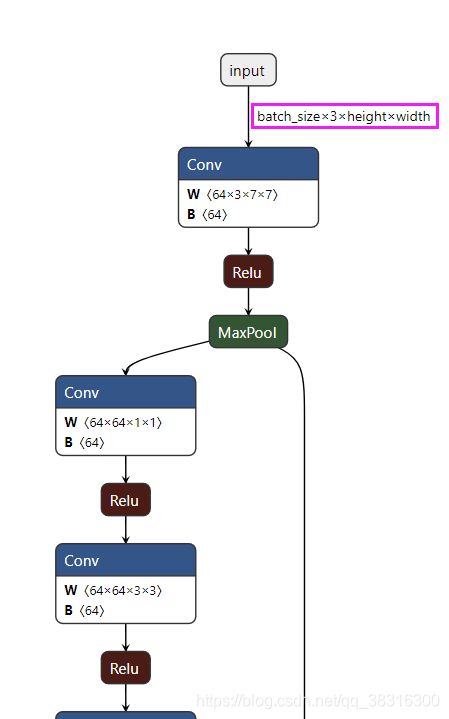

从上面的输入输出中不难发现,第0,2,3上的索引都变成了一个变量(该变量的名称与dynamic_axes中索引的value是一致的),这就意味着onnx模型的输入数据的batch size、height以及width是可变的,只是通道数channel是不能发生改变的。
2. 由onnx模型转成TensorRT 的engine模型
我们可以使用TensorRT自带的可执行程序trtexec将onnx模型导出为engine模型(首先需要安装TensorRT,trtexec存在于bin文件夹下)。trtexec的主要参数如下:
=== Model Options ===
--uff= UFF model
--onnx= ONNX model
--model= Caffe model (default = no model, random weights used)
--deploy= Caffe prototxt file
--output=[,]* Output names (it can be specified multiple times); at least one output is required for UFF and Caffe
--uffInput=,X,Y,Z Input blob name and its dimensions (X,Y,Z=C,H,W), it can be specified multiple times; at least one is required for UFF models
--uffNHWC Set if inputs are in the NHWC layout instead of NCHW (use X,Y,Z=H,W,C order in --uffInput)
=== Build Options ===
--maxBatch Set max batch size and build an implicit batch engine (default = 1)
--explicitBatch Use explicit batch sizes when building the engine (default = implicit)
--minShapes=spec Build with dynamic shapes using a profile with the min shapes provided
--optShapes=spec Build with dynamic shapes using a profile with the opt shapes provided
--maxShapes=spec Build with dynamic shapes using a profile with the max shapes provided
Note: if any of min/max/opt is missing, the profile will be completed using the shapes
provided and assuming that opt will be equal to max unless they are both specified;
partially specified shapes are applied starting from the batch size;
dynamic shapes imply explicit batch
input names can be wrapped with single quotes (ex: 'Input:0')
Input shapes spec ::= Ishp[","spec]
Ishp ::= name":"shape
shape ::= N[["x"N]*"*"]
--inputIOFormats=spec Type and formats of the input tensors (default = all inputs in fp32:chw)
--outputIOFormats=spec Type and formats of the output tensors (default = all outputs in fp32:chw)
IO Formats: spec ::= IOfmt[","spec]
IOfmt ::= type:fmt
type ::= "fp32"|"fp16"|"int32"|"int8"
fmt ::= ("chw"|"chw2"|"chw4"|"hwc8"|"chw16"|"chw32")["+"fmt]
--workspace=N Set workspace size in megabytes (default = 16)
--minTiming=M Set the minimum number of iterations used in kernel selection (default = 1)
--avgTiming=M Set the number of times averaged in each iteration for kernel selection (default = 8)
--fp16 Enable fp16 algorithms, in addition to fp32 (default = disabled)
--int8 Enable int8 algorithms, in addition to fp32 (default = disabled)
--calib= Read INT8 calibration cache file
--safe Only test the functionality available in safety restricted flows
--saveEngine= Save the serialized engine
--loadEngine= Load a serialized engine
=== Inference Options ===
--batch=N Set batch size for implicit batch engines (default = 1)
--shapes=spec Set input shapes for dynamic shapes inputs. Input names can be wrapped with single quotes(ex: 'Input:0')
Input shapes spec ::= Ishp[","spec]
Ishp ::= name":"shape
shape ::= N[["x"N]*"*"]
--loadInputs=spec Load input values from files (default = generate random inputs). Input names can be wrapped with single quotes (ex: 'Input:0')
Input values spec ::= Ival[","spec]
Ival ::= name":"file
--iterations=N Run at least N inference iterations (default = 10)
--warmUp=N Run for N milliseconds to warmup before measuring performance (default = 200)
--duration=N Run performance measurements for at least N seconds wallclock time (default = 3)
--sleepTime=N Delay inference start with a gap of N milliseconds between launch and compute (default = 0)
--streams=N Instantiate N engines to use concurrently (default = 1)
--exposeDMA Serialize DMA transfers to and from device. (default = disabled)
--useSpinWait Actively synchronize on GPU events. This option may decrease synchronization time but increase CPU usage and power (default = disabled)
--threads Enable multithreading to drive engines with independent threads (default = disabled)
--useCudaGraph Use cuda graph to capture engine execution and then launch inference (default = disabled)
--buildOnly Skip inference perf measurement (default = disabled)
=== Build and Inference Batch Options ===
When using implicit batch, the max batch size of the engine, if not given,
is set to the inference batch size;
when using explicit batch, if shapes are specified only for inference, they
will be used also as min/opt/max in the build profile; if shapes are
specified only for the build, the opt shapes will be used also for inference;
if both are specified, they must be compatible; and if explicit batch is
enabled but neither is specified, the model must provide complete static
dimensions, including batch size, for all inputs
=== Reporting Options ===
--verbose Use verbose logging (default = false)
--avgRuns=N Report performance measurements averaged over N consecutive iterations (default = 10)
--percentile=P Report performance for the P percentage (0<=P<=100, 0 representing max perf, and 100 representing min perf; (default = 99%)
--dumpOutput Print the output tensor(s) of the last inference iteration (default = disabled)
--dumpProfile Print profile information per layer (default = disabled)
--exportTimes= Write the timing results in a json file (default = disabled)
--exportOutput= Write the output tensors to a json file (default = disabled)
--exportProfile= Write the profile information per layer in a json file (default = disabled)
=== System Options ===
--device=N Select cuda device N (default = 0)
--useDLACore=N Select DLA core N for layers that support DLA (default = none)
--allowGPUFallback When DLA is enabled, allow GPU fallback for unsupported layers (default = disabled)
--plugins Plugin library (.so) to load (can be specified multiple times)
=== Help ===
--help Print this message 2.1 static shap的onnx模型转成static shape的engine模型
对于static shape的转换也非常简单,我们只需要指定输入的onnx模型路径(--onnx)、输出engine模型的名称即可 (--saveEngine),如果想要可视化过程。更详细的参数使用可以参考下面这个例子:
trtexec trtexec --onnx=fastPose.onnx
-saveEngine=fastPose.engine
--workspace=10240
--fp16
--verbose2.2 dynamic shap的onnx模型转成dynamic shape的engine模型
在dynamic shape的转换过程中,还需要设置一个最小尺寸和最大尺寸,这主要是为了后面分配显存考虑。minShapes设置能够输入数据的最小尺寸,optShapes可以与minShapes保持一致,maxShapes设置输入数据的最大尺寸,这三个是必须要设置的,可通过trtexec -h查看具体用法。具体用法为:
trtexec --onnx=alphaPose_-1_3_256_192_dynamic.onnx
--saveEngine=alphaPose_-1_3_256_192_dynamic.engine
--workspace=10240 --fp16 --verbose
--minShapes=input:1x3x256x192
--optShapes=input:1x3x256x192
--maxShapes=input:128x3x256x192
--shapes=input:1x3x256x192
--explicitBatch3. 使用engine模型进行推理加速
使用engine模型进行推理的算法逻辑我放到了tools/trt_lite.py文件的TrtTiny类中了。其算法逻辑主要有:
(1)反序列化engine模型
(2)分配显存
(3)进行推理(inference)
同样,算法逻辑也是非常简单的三步走战略。
3.1 反序列化engine模型
反序列化engine模型是因为我们使用trtexec从onnx模型转成engine模型的时候,为了下次可以直接使用engine模型,而不需要重复生成engine模型,我们经过技术将其序列化保存到磁盘中了。其代码逻辑为:
def _get_engine(self):
with open(self.engine_path, "rb") as f, trt.Runtime(self.logger) as runtime:
return runtime.deserialize_cuda_engine(f.read())3.2 分配显存
对于static shape的engine,显存大小需要根据输入数据的尺寸确定;对于dynamic shape的engine,我们先根据maxShape来分配最大的显存,之后每次得到新的数据数据进行inference的时候,再改变context的大小即可。
def _allocate_buffers(self):
for binding in self.engine:
dims = self.engine.get_binding_shape(binding)
if dims[0] < 0:
if binding == 'input':
self.context.set_binding_shape(binding=0, shape=(self.maxBs, 3, dims[2], dims[3]))
size = trt.volume(self.context.get_binding_shape(0 if binding == 'input' else 1))
else:
size = trt.volume(self.context.get_binding_shape(0 if binding == 'input' else 1)) * self.batch_size
dtype = trt.nptype(self.engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
self.bindings.append(int(device_mem))
# Append to the appropriate list.
if self.engine.binding_is_input(binding):
self.inputs.append(HostDeviceMem(host_mem, device_mem))
else:
self.outputs.append(HostDeviceMem(host_mem, device_mem))3.3 进行推理
在推理阶段中,如果engine是dynamic shape的模型,我们需要根据新的输入数据来设置context的binding shape。
def detect_context(self, img_in):
for binding in self.engine:
dims = self.engine.get_binding_shape(binding)
if dims[0] < 0 and binding == 'input':
self.context.set_binding_shape(binding=0, shape=img_in.shape)
# inference
def _do_inference(self):
# Transfer input data to the GPU.(optionally serialized via stream)
[cuda.memcpy_htod_async(inp.device, inp.host, self.stream) for inp in self.inputs]
# Run inference.
self.context.execute_async(bindings=self.bindings, stream_handle=self.stream.handle)
# Transfer predictions back from the GPU.(optionally serialized via stream)
[cuda.memcpy_dtoh_async(out.host, out.device, self.stream) for out in self.outputs]
# Synchronize the stream
self.stream.synchronize()
# Return only the host outputs.
return [out.host for out in self.outputs]具体的代码可以参考我的github。