Real-Time Rendering Fourth Edition 学习笔记之 -- 第三章:图形处理单元
过去的20年,图形硬件经历的惊人的演变。1999年,出现了第一个包含了顶点处理的用户图形芯片(NVIDIA’s GeForce256)。过去的几年,GPU从通过配置实现复杂的固定渲染管线,演变为用户可以实现自己的算法的高度可编程管线。出于性能考虑,部分阶段依然是可配置,不可编程的,但是也在走向可编程和更灵活性。
1 数据并行结构
GPU芯片是一大组专用的处理器,叫做(shader cores),它们的数量经常以千计。GPU是流处理器,处理相似的数据。另一个重要的点是,它们的调用是尽可能独立的,也就是说说它们不需要相邻的调用信息,并且不共享可写内存地址。虽然这个设计减少了可用的功能,但是也排除了潜在的延时(一个处理器可能等待另一个处理器完成)。
GPU针对吞吐量进行的优化(定义了数据可执行的最大速率),但是这样的快速处理有一定的开销。因为芯片专用于内存和逻辑控制的空间小,每个着色器内核产生的延迟要比CPU高很多。
假设有一个网格需要光栅化,以及有2千像素片元要等待被处理;一个像素着色器将要被调用2千次。如果只有一个着色器处理器,GPU肯定会挂掉。GPU会从第一个片元开始处理,对在寄存器上的值进行少量的运算,寄存器是局部的,访问速度很快。随后着色处理器遇到类似纹理访问的指令,一张纹理是全局的离散资源,不是像素程序的局部资源,并且纹理的访问会相对复杂。那么一个内存的取出会占用上百到上千的时钟周期( clock cycles),而这些时间,GPU无法做任何事情。这种情况下,着色处理器会停止,等到纹理颜色值的返回。
为了解决上述的问题,我们给每个片元一点寄存器储存空间。现在相比于等到纹理值取出,着色处理器润徐切换执行其他片元:第二个片元。与第一个相同,对其进行少量的运算,然后收到纹理值取出指令,这时再切换到第三个片元。切换的操作是非常快的,每个片元之间的计算也相互不受影响。最终两千的片元都以类似的方式进行处理,然后再返回第一个片元,这时候纹理颜色值已经取出,从而可以继续进行运算。这种方式,一个单独的片元会增加处理时间,但是全部的处理时间总和会明显的减少。
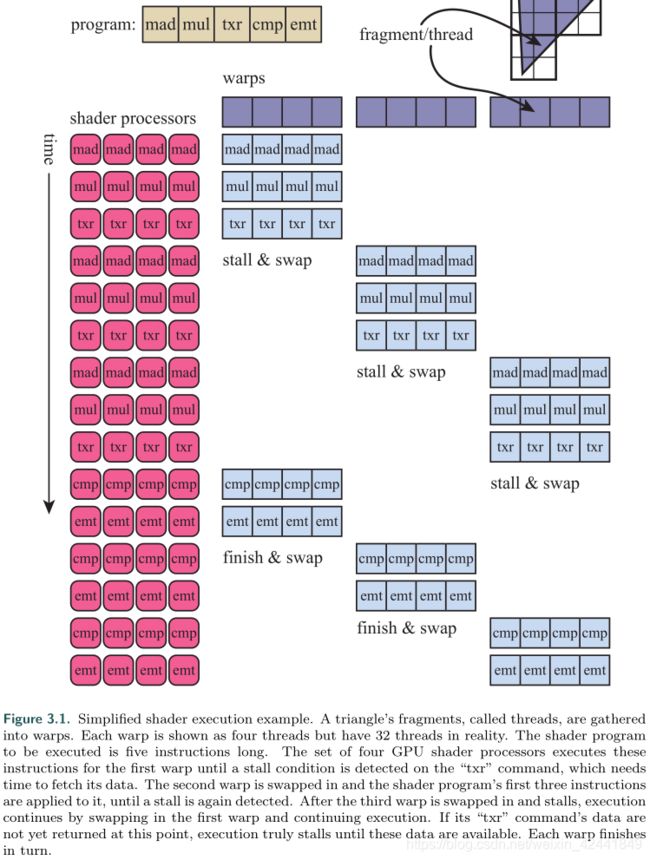
在这样的结构下,延时主要潜伏在GPU频繁的切换中;GPU针对这个问题,设计进一步对指令处理逻辑与数据进行分离。叫做单指令,多数据(single instruction, multiple data SIMD), 对固定数量的着色器程序在同一个lock-step中,处理相同的命令。相比于单独逻辑和分离的单元来处理每个程序,SIMD可以使用更少的silicon (and power)来专注于处理数据和切换。返回到我们之前提出的两千个片元的例子,每一个像素着色器的调用称之为一个线程,这个线程和CPU的线程不同,它包含了一点内存用以保存用于着色器的输入值。使用了相同着色器程序的线程打包成组,叫做warps(NVIDIA)或者wavefronts(AMD)。 warp/wavefront通过一定数量(8到64)的GPU着色器cores来通过SIMD调用执行,每一个线程映射到SIMD lane。
我们目前有2000个线程要执行,在NVIDIA GPU下,一个Warp有32个线程,所以就有 2000/32 = 62.5个warp,它表示有63个warp被分配,最后一个warp是半空的。每个warp的执行和单个的线程类型,其中的32个线程在同一个 lock-step中执行,单遇到内存读取时,会切换到下一个warp。这就比单个线程的切换要快。
在我们的简单的例子下,内存读取的延时会导致warp的切换。事实上warp的切换会有短暂的延时,即使切换的开销很小。有几种技术可以优化执行,但是在使用所有GPU的时候,warp切换还是主要潜在的延时。导致切换延时主要有几种因素,比如如果只有少数几个warp要被分配,那么潜在的延时就会比较大。
着色器程序结构是一个重要的影响性能的角色。一个重要的因素是寄存器可以使用在线程的数量。在我们的例子中,我们假设两千个线程可以同时存在于GPU中。那么如果线程之间可以共享更多的寄存器,那么久可以与更少的线程,也就有更少的warp。缺少warp代表交换不能减少等待。warp的数量叫做occupancy,高occupancy带包有大量warp;低occupancy常常会导致性能的下降。另外内存读取的频率也是潜在延时的因素。 Lauritzen [993]介绍了occupancy对性能的影响; Wronski [1911, 1914]。
另一个影响性能的因素是动态分支,由“if”语句和循环导致。当着色器程序遇到一个“if”语句时。如果所有线程评估和使用同一个分支,warp可以继续并且不考虑另一个分支。但是,如果有部分线程(甚至是只有一个线程)使用了另一个分支,那么整个warp的线程就不许计算每一个分支。这个问题叫做thread divergence,当有少数线程需要执行讯乱调用或者“if”语句而其他线程不需要的时候。
理解上述的逻辑将会帮助我们作为程序员,写出更高效的代码。
2 GPU管线预览
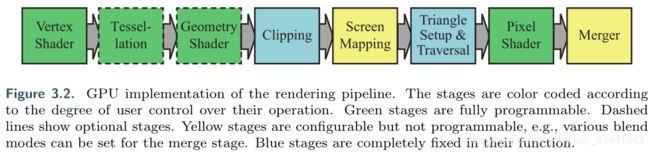
如上图所示,曲面细分(Tessellation)和几何着色(Geometry Shader)阶段是可选,而且不是所有GPU都支持,尤其是在移动设备。
3 可编程着色阶段
现在着色器程序使用的是统一的shader design,这代表着vertex,pixel,geometry和tessellation着色器共享一个相同的编程模型。在内部,它们有相同的指令集结构( instruction set architecture ISA)。在DX中,一个处理器实现这种模型叫做common-shader core,以及一个拥有这种core的GPU叫做使用同意的着色器架构。这种设计可以让着色器处理器进行多种方式使用,GPU可以根据需求合理进行分配。
一个draw call调用了图形API来绘制一组primitives,所以令图形管线来执行它的着色器。每一个可编程着色器阶段包含两种类型的输入:常量输入(uniform inputs),即每个draw call中是固定的;以及变量输入(varying inputs),来自顶点索引或者光栅化后的值。
底层的虚拟机为不同类型的输入和输出提供特殊的寄存器。统一的constant registers的数量要比变化的输入输出寄存器大很多。这是因为变化的输入输出寄存器是分别保存在顶点或者像素中的,所以就对其数量有限制。而统一的输入只保存一次,然后对每个顶点和像素的执行进行重用。虚拟机还包括多用途的temporary registers用作临时空间。所有寄存器可以使用在临时空间的整形数组索引。整体结构如下图:
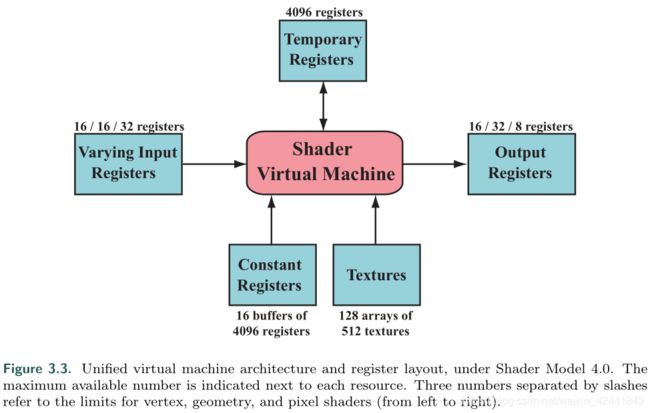
flow control代表了使用分支指令改变代码执行的流。比如if 或者 case语句。着色器支持两种流控制,一种是静态流控制,它基于常量值输入。它的好处主要是,代码可以使用在多种情况下,而且没有线程分歧。另一种动态流控制,它基于变量值输入,它功能更强,但是会影响性能。
4 可编程着色和API的演变
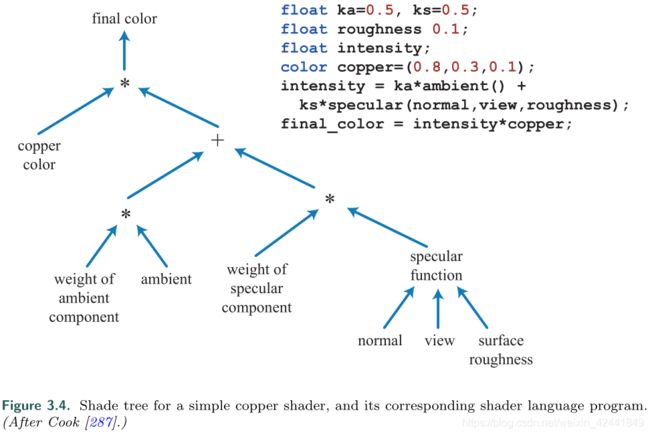
最早的可编程着色框架是1984年的Cook’s shade trees [287]。
用户级别显卡历程如下图:
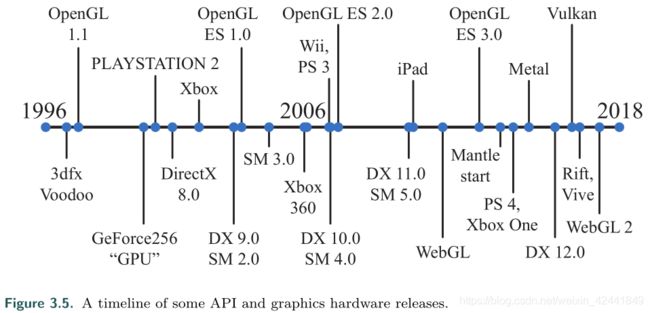
5 顶点着色器

类似于之前DX12介绍的文章:
https://blog.csdn.net/weixin_42441849/article/details/82894722
6 曲面细分阶段
曲面细分支持于:DX11,OpenGL4.0,OpenGL ES 3.2。
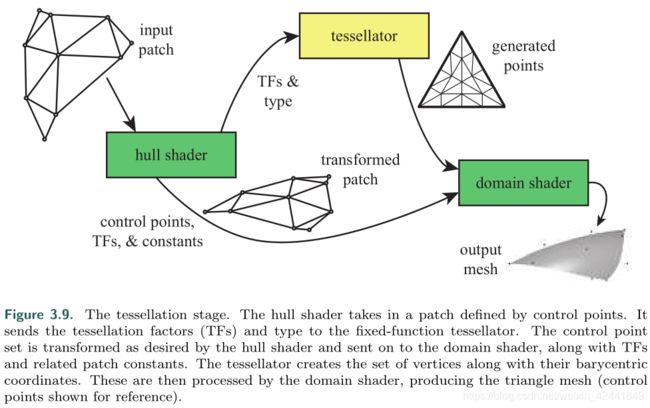
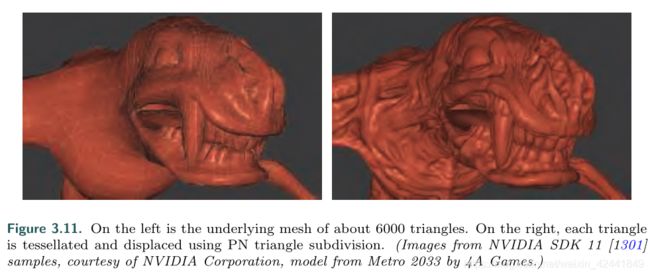
类似于之前DX12介绍的文章:
https://blog.csdn.net/weixin_42441849/article/details/84327457
7 几何着色器

类似于之前DX12介绍的文章:
https://blog.csdn.net/weixin_42441849/article/details/84247196
7.1 流输出
在SM4.0提出,在顶点处理之后可以输出流。可用以模拟水流或者其他例子效果等。也可以用以模型的蒙皮以及顶点的重用。
8 像素着色器
类似于之前DX12介绍的文章:
https://blog.csdn.net/weixin_42441849/article/details/82894722
9 输出合并阶段
类似于之前DX12介绍的文章:
https://blog.csdn.net/weixin_42441849/article/details/82894722
10 计算着色器

类似于之前DX12介绍的文章:
https://blog.csdn.net/weixin_42441849/article/details/84302251
进一步阅读
Giesen’s tour of the graphics pipeline [530] discusses many facets of the GPU at
length, explaining why elements work the way they do. The course by Fatahalian and
Bryant [462] discusses GPU parallelism in a series of detailed lecture slide sets. While
focused on GPU computing using CUDA, the introductory part of Kirk and Hwa’s
book [903] discusses the evolution and design philosophy for the GPU.
To learn the formal aspects of shader programming takes some work. Books such
as the OpenGL Superbible [1606] and OpenGL Programming Guide [885] include ma-
terial on shader programming. The older book OpenGL Shading Language [1512] does
not cover more recent shader stages, such as the geometry and tessellation shaders,
but does focus specifically on shader-related algorithms. See this book’s website,
realtimerendering.com, for recent and recommended books.