目标检测算法——YOLO[v4~v6]
目录
1 YOLO v4
1.1 网络结构
1.2 特点
2 YOLO v5
2.1 Yolo v5s网络结构图
2.2 四种模型结构的参数
2.3 特点
3 YOLO v6
1 YOLO v4
2020年4月23日出现的YOLO v4是一种端到端的目标检测方法,它将目标检测问题转化为回归问题,直接检测图像。
1.1 网络结构
网络结构如图所示。每一个网格会预先设定三个先验框,每个先验框会通过YOLO Head生成矩形框定位位置,判定类别,留下置信度高于阈值的矩形框。
![目标检测算法——YOLO[v4~v6]_第1张图片](http://img.e-com-net.com/image/info8/98efc06da071462dade661708a2f9b86.jpg)
与YOLO v3区别:增加CSP结构,PAN结构。
各组件含义:
CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
Concat:张量拼接,维度会扩充,和Yolov3中的解释一样,对应于cfg文件中的route操作。
add:张量相加,不会扩充维度,对应于cfg文件中的shortcut操作。
其它:
(1)YOLO v4以CSPDarknet-53为主干特征提取网络。
CSPDarknet-53是由v3中的Darknet-53改进的,将Darknet-53中的残差块进行修改,引入了CSPNet结构。将原本的残差块进行了拆分,拆成左右两个部分,主干部分依然继续将残差块一个一个地堆叠,而另一部分只需要作少量的操作就可以直接与残差块的尾部相连,使得CSPDarknet-53中存在一个大的残差边。
对于YOLO v4这种深层网络来说,残差边可以把信息传递到网络的深层,将浅层信息与深层信息进行结合,避免了梯度消失的问题,增强网络特征提取能力。
(2)CSPDarknet-53将卷积中的激活函数由Leaky-ReLU换为Mish。
a.Mish函数 ()=tanh(ln(1+)) 具有平滑和连续等特点,可以让网络具有更好的泛化能力,使信息可以更深入网络。
b.Mish函数无上界且有下界,无上界可以避免有界封顶而造成饱和,其非单调性、有下界和对负值的小范围允许也都有助于网络的训练。
1.2 特点
(1)YOLO v4对训练时的输入端做出改进,包括Mosaic数据增强、cmBN和SAT自对抗训练。
Mosaic数据增强采用4张图片随机缩放、随机裁剪、随机排布的方式进行拼接。这大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好,并且减少了GPU。
(2)BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock。
CSPDarknet53:
包含了5个CSP模块,每个CSP模块前面的卷积核的大小都是3*3,stride=2,可以起到下采样的作用。因为Backbone有5个CSP模块,输入图像是608*608,所以特征图变化的规律是:608->304->152->76->38->19。
采用CSPDarknet53网络结构的优点:增强CNN的学习能力,使得在轻量化的同时保持准确性;降低计算瓶颈;降低内存成本。
Mish激活函数:
Yolov4的Backbone中都使用了Mish激活函数,能提高精度;而后面的网络则还是使用leaky_relu函数。
Dropblock:
和常见网络中的Dropout功能类似,是缓解过拟合的一种正则化方式。
(3)Yolov4的Neck结构主要采用了SPP模块、FPN+PAN的方式。
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。
(4)Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms。
2 YOLO v5
2020年6月10日发布的YOLO v5,是一个模型家族,包括了YOLOv5s(最小)、YOLOv5m、YOLOv5l、YOLOv5x(最大)四个模型,可以通过设置参数来自动地控制模型大小,各版本性能比较如图所示。
(注:Yolov5的作者没有发表论文)
![目标检测算法——YOLO[v4~v6]_第2张图片](http://img.e-com-net.com/image/info8/6fa7a8882cd64468906296a2f0be62ec.jpg)
Yolo v5s网络是Yolov5系列中深度最小,特征图的宽度最小、AP精度最低的网络。后面的3种都是在此基础上不断加深,不断加宽。
2.1 Yolo v5s网络结构图
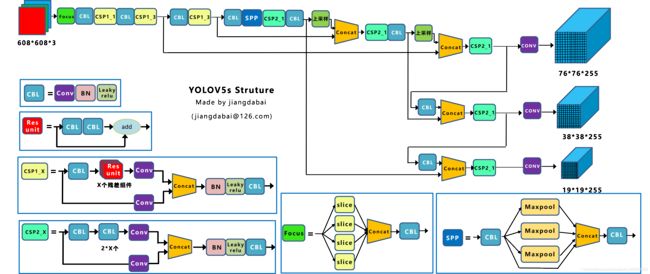
2.2 四种模型结构的参数
YOLOv5代码中的四种模型都是以yaml的形式来呈现,而且四个文件的内容基本上是一样的,区别在于depth_multiple和width_multiple两个参数不同。
| depth_multiple | width_multiple | |
| Yolov5s | 0.33 | 0.50 |
| Yolov5m | 0.67 | 0.75 |
| Yolov5l | 1.0 | 1.0 |
| Yolov5x | 1.33 | 1.25 |
注:YOLOv5s(v 6.0)是目前速度和精度均较好的轻量化检测算法,但是它仍不能很好地提取通用目标检测数据集的小目标特征,故检测性能仍需要进一步提升。
2.3 特点
(1)输入端
Yolo v5的输入端采用了和Yolo v4一样的Mosaic数据增强的方式,对小目标的检测效果很不错。
a 自适应锚框计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框进行比对,计算两者差距,再反向更新,迭代网络参数。
Yolo v5将计算初始锚框的值的功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
b 自适应图片缩放
在常用的目标检测算法中,不同图片的尺寸都不相同,因此需统一缩放到一个标准尺寸,再送入检测网络中。
Yolov5对代码中letterbox函数进行了修改,对原始图像自适应的添加最少的黑边。使得计算量减少,目标检测速度得到提升。
(2)Backbone
a Focus结构
以Yolov5s的结构为例,原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核(其他三种结构使用的数量有所增加)的卷积操作,最终变成304*304*32的特征图。
b CSP结构
Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。而Yolov4中只有主干网络使用了CSP结构。
c Neck
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构。不同的是,v4的Neck结构中采用的都是普通的卷积操作,而Yolov5的Neck结构中采用CSP2结构,加强了网络特征融合的能力。
d 输出端
Yolov5采用CIOU_Loss做Bounding box的损失函数。
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作,Yolov5则采用加权nms的方式。
3 YOLO v6
YOLOv6是美团视觉智能部研发的一款目标检测框架,致力于工业应用,于2022年6月份在GitHub上开源。紧随其后发布了YOLOv6 2.0版本,对轻量级网络进行了全面升级,推出了性能更强的全系列模型。YOLOv6具有硬件友好的高效设计和高性能,超越 了Yolov5,YoloX。
特点:主要特点是速度快、精度高、部署友好
(1)性能更强的全系列模型
(2)量身定制的量化方案
(3)完备的开发支持和多平台部署适配
v6源码地址:https://github.com/meituan/YOLOv6
注:这里仅对v6做简单了解。
参考文献:
1.YOLO v4论文原文:《YOLOv4: Optimal Speed and Accuracy of Object Detection》
2.深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎 (zhihu.com)
3.Yolov3、v4、v5、Yolox模型权重及网络结构图资源下载_江大白*的博客-CSDN博客
4.Yolov4可视化网络结构图_江大白*的博客-CSDN博客
5.YOLO v6论文原文:《YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications》
6.目标检测开源框架YOLOv6全面升级,更快更准的2.0版本来啦 - 腾讯云开发者社区
注:
本文是学习所参考文献与资料后的整理与归纳,仅作学习记录,如有侵权请联系作者删除!欢迎大家指正与交流。