自注意力机制
文章目录
- 前言
- 文献阅读
-
- 摘要
- 框架
- 目标函数
- 主要结果
- 深度学习
-
- 注意力机制的理解
- Encoder-Decoder框架
- 自注意力机制
- 总结
前言
This week,the paper which describe a deep learning framework to extract the short-term local dependence pattern between variables in long - and short-term time series network has been read. Then I learn about self-attention mechanism and its related code.
本周阅读了文献《Modeling Long- and Short-Term Temporal Patterns with Deep》主要提出了一种深度学习框架长短期时间序列网络提取变量之间的短期局部依赖模式,发现时间序列趋势的长期模式,然后学习了自注意力机制及其相关代码。
文献阅读
题目:Modeling Long- and Short-Term Temporal Patterns with Deep
Neural Networks
作者:Guokun Lai,Wei-Cheng Chang,Yiming Yang,Hanxiao Liu
摘要
多变量时间序列预测是一个跨许多领域的重要机器学习问题,现实中出现的时态数据往往包含长期和短期模式,对于这些模式,自回归模型和高斯过程等传统方法可能会失效。为此,提出了一种新颖的深度学习框架长短期时间序列网络来应对这一挑战。LSTNet使用卷积神经网络(convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Netwok,RNN)提取变量之间的短期局部依赖模式,发现时间序列趋势的长期模式。此外,利用传统的自回归模型来解决神经网络模型的尺度不敏感问题。在测试中,LSTNet取得了显著的性能提升。
自回归移动平均模型(ARIMA)
自回归移动平均模型是单变量时间序列模型之一。ARIMA模型由于计算代价高,很少用于高维多元时间序列预测。
框架
问题:给定一段历史数据,预测某个将来时刻的值。
LSTNet是专门为混合长短期模式的多元时间序列预测任务设计的深度学习框架。
LSTNet的第一层是一个无池化的卷积网络,目的是提取时间维度上的短期模式以及变量之间的局部依赖关系,卷积层由多个宽度和高度的滤波器组成。第K个滤波器扫过输入X输出:
![]()
卷积层的输出同时馈入循环分量,循环组件是具有门控循环单元,使用RELU函数作为隐藏更新激活函数。T时刻循环单元的隐藏状态计算:
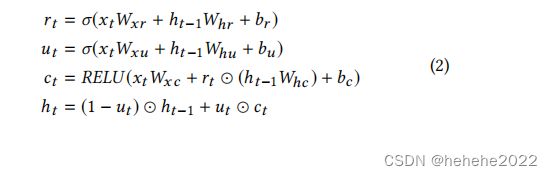
以GRU和LSTM为单元的循环层,具有相对的长期依赖关系,由于梯度消失,GRU和LSTM在实际应用中往往不能捕捉到非常长时间的相关性,所以开发了一种具有时间跳跃连接的循环结构,在当前隐藏单元和同一阶段的隐藏单元之间添加跳跃连接,更新过程为:
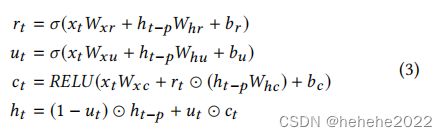 Recurrent Component和Recurrent-skip Component的输出结合。Recurrent Component中只需要最后一个时刻的隐向量,而Recurrent-skip Component中需要最后一个周期中的所有隐向量。最后将这些隐向量带权叠加。
Recurrent Component和Recurrent-skip Component的输出结合。Recurrent Component中只需要最后一个时刻的隐向量,而Recurrent-skip Component中需要最后一个周期中的所有隐向量。最后将这些隐向量带权叠加。

目标函数
平方误差是许多任务默认的损失函数,相应的优化目标表示为
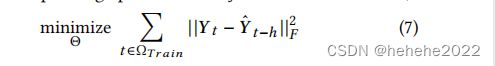
主要结果
采用了四个真实的数据集,和现有方法已经自身的ablation进行了对比,同时实验也验证了Autoregressive Component的重要性。LSTNet这种提出的模型在具有周期性模式的数据集上,一直比现有的最先进的模型具有更好的性能。此外,在太阳能,交通和电力数据集上,当时间为24时,LSTNet 的RSE指标分别比RNN-GRU提高9.2%。11.7%和22.2%,验证了该框架设计对复杂重复模式的有效性。
深度学习
注意力机制的理解
人类在关注一个事物的时候往往只关注一个小的信息点,这叫注意力,这些信息有的有帮助,有的没有帮助,没有帮助的信息这是噪声,我们要做的是解决某个问题,必须快速从众多信息中选出最重要的信息。所以注意力机制的核心目标是从众多信息中选出对当前任务目标更关键的信息并将注意力放在上面。
Encoder-Decoder框架

举机器翻译的例子:
输入:Tom chase Jerry
翻译生成:“汤姆” “追逐” “杰瑞”
输出的y1,y2,y3不是同时生成的,每次生成一个目标单词,并且每个目标单词的有效信息都不一样。在翻译某个词的时候,三个单词贡献的注意力是一样的,实际他的贡献度应该有所不同,所以引入注意力机制。
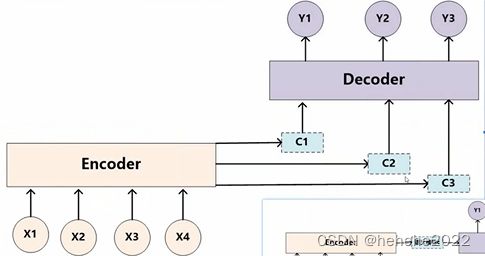
当生成y1的时候,c1会告诉输入哪一个与y1的相关性最高。
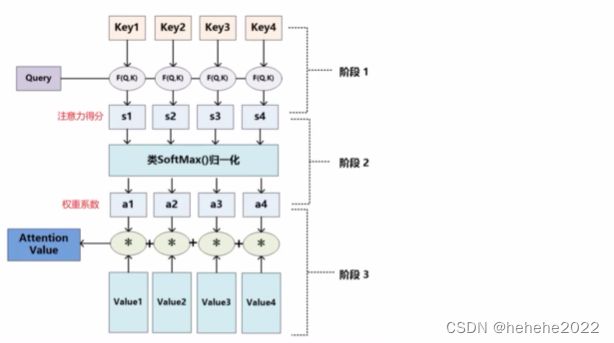
attention机制的本质思想是把attention理解成从大量信息中筛选出少量重要的信息并聚焦到这些信息中,体现在模型上就是通过权重系数计算,权重越大越聚焦到对应的value值上。
attention机制的具体计算过程:
1.根据query和key计算两者的相似性和相关性。
常见的方法:向量点积,cosine相似性,引入额外的神经网络求值
2.对1 的原始分值进行softmax归一化处理。
3.根据权重系数对value进行加权就和。
自注意力机制
给定序列X1,…,Xn,自注意力池化层将Xi当作key,value,query来对序列抽取特征得到y1,…,yn,这里
yi = f(xi,(x1,x1),…,(xn,xn))

优点:引入自注意力机制会更容易捕获句子中长距离的相互依赖的特征,因为RNN或者LSTM对于远距离的相互依赖的特征要经过若干时间步步骤信息的累计,距离越远,有效信息被稀释,捕获的可能性越小;自注意力不需要依赖次序序列计算,有助于增加计算的并行性。
代码
import torch
import numpy as np
import torch.nn as nn
import math
import torch.nn.functional as F
class selfAttention(nn.Module) :
def __init__(self, num_attention_heads, input_size, hidden_size):
super(selfAttention, self).__init__()
if hidden_size % num_attention_heads != 0 :
raise ValueError(
"the hidden size %d is not a multiple of the number of attention heads"
"%d" % (hidden_size, num_attention_heads)
)
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = hidden_size
self.key_layer = nn.Linear(input_size, hidden_size)
self.query_layer = nn.Linear(input_size, hidden_size)
self.value_layer = nn.Linear(input_size, hidden_size)
def trans_to_multiple_heads(self, x):
new_size = x.size()[ : -1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_size)
return x.permute(0, 2, 1, 3)
def forward(self, x):
key = self.key_layer(x)
query = self.query_layer(x)
value = self.value_layer(x)
key_heads = self.trans_to_multiple_heads(key)
query_heads = self.trans_to_multiple_heads(query)
value_heads = self.trans_to_multiple_heads(value)
attention_scores = torch.matmul(query_heads, key_heads.permute(0, 1, 3, 2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = F.softmax(attention_scores, dim = -1)
context = torch.matmul(attention_probs, value_heads)
context = context.permute(0, 2, 1, 3).contiguous()
new_size = context.size()[ : -2] + (self.all_head_size , )
context = context.view(*new_size)
return context
总结
自注意力池化层将xi当作key,value,query来对序列抽取特征;完全并行,最长序列为1(对于任何一个输出都参考了整个序列的信息),长序列计算成本高;位置编码在输入中加入位置信息,使得自注意力能够记忆位置信息。