MDFN: Multi-scale deep feature learning network for object detection 文章翻译及学习
MDFN: Multi-scale deep feature learning network for object detection
用于目标检测的多尺度深层特征学习网络
请结合论文共食。
3 Deep feature learning network
3.1 deep feature extraction and analysis
假设:
- 这些特征图应该能够提供精细的细节,尤其是对于较早的图层而言;
- 转换特征图的功能应扩展到足够深的层,以便可以将对象的高级抽象信息构建到特征图中;
- 特征图应包含适当的上下文信息,以便可以准确推断出被遮挡的对象,小对象,模糊或重叠的对象并对其进行稳健的定位。
因此,浅层和深层的特征对于目标识别和定位起着必不可少的作用。
为了有效地利用检测到的特征信息,应考虑另一约束条件,以防止特征被改变或覆盖。 我们声称,跨层的特征传输应降低特征因漂移误差而改变或被无关内容所覆盖的可能性,并应最大程度地减少冗余和噪声的累积,尤其是在深层中。 因此,网络本地部分内的特征传输或直接特征输出应该是有效使用此信息的更好解决方案。 为此,我们提出了以下多尺度深度特征提取和学习方案,该方案将支持上述强假设并满足相关条件。

m表示高级层,Ψm是m层相应的输出特征图。函数Fj将Ψj-1映射到同一层j中的多尺度空间响应。F由特征变换函数S作用,用w进行加权,高层产生的所有特征信息将由函数T直接送入最终检测层。
上面的函数(4),(5)和(6)构成了一个深度多尺度特征学习方案。它考虑了由具有高分辨率的浅层生成的特征图,这些高分辨率代表对象的精细细节。 这符合第一个提到的假设。 Fm专为网络的深层而设计,可将深层抽象引入输出特征图中。 此外,单个深层中的多尺度感受野在不同大小的上下文中对最重要的特征和对象敏感,这使得输出足够强大以支持检测和定位,并直接响应了强烈的建议。 同时,几个连续的深度Inception单元提供了以下可能性:来自中间级别的特征图可以从较低和较高的对应位置检索上下文信息。 这有利于检测重叠对象的确切位置,这些对象必须被可靠地推断出是被遮挡的,小的,甚至是模糊的或饱和的对象[33]。 满足上述假设2)和3)。
(我的理解是:这些Inception模块加在基础网络的中间层,在后面才看懂,不是这样的)
3.2 Deep feature learning inception modules
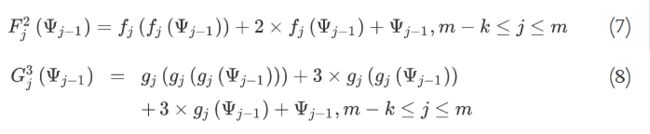
(7)和(8)的表达式实际上可以分别通过以下信息平方和三次运算来近似。
3.3 Multi-Scale object detection scheme
- 在我们的模型中,给每个给定位置k个盒子,计算c类分数和每个盒子四个顶点相对于默认盒子的四个偏移量。 最终,为特征图内的每个位置提供了总共k(c + 4)个过滤器。 因此,每个尺寸为m×n的特征图的输出数量应为k(c + 4)mn。 在[10]中已证实,使用各种默认的框形状将有助于为单发网络预测框的任务,从而提高了对象定位和分类的准确性。 我们采用这种多盒技术作为我们多尺度方案的第一个属性。
- 我们的深度特征学习起始模块被应用在四个连续的高级层单元中。 这四个层单元将其输出深度特征直接传输到最终预测层,这将信息传输完全缩短。 从训练的角度来看,这些缩短的连接使网络的输入和输出彼此更接近,这有益于模型的训练,即使深入的想法使高层层次变得复杂[11]。 高级层和最终预测层之间的直接连接缓解了梯度消失的问题,并增强了特征传播[11]。 另一方面,四个高级层单元的序列通过语义和上下文信息获取两种方式最大化了深度特征提取和表示的能力。 首先,它使后三个高层从先前的较低层获取上下文信息。 其次,同一级别的层可以提供不同范围的上下文信息,以及可以在当前层输出中自然构建的更精确的语义表达。 这个过程是我们多尺度方案的第二个特性。
- 我们使用多尺度过滤器来激活各种大小的接受域,以增强语义和上下文信息的提取。 要注意的另一个方面是要素图的大小。 在大多数网络中,特征图的大小会随着深度的增加而逐渐减小。 这考虑到我们系统的内存有限以及功能的比例不变。 因此,由于其输入特征图的分辨率比在较早的层中产生的分辨率小得多,因此在网络深处接受的多尺度滤波器将具有较少的计算负担。 这抵消了滤波操作增加带来的计算负担。 这是拟议的多尺度方案的第三个特性。
base network—VGG16
通过这张图(如下)能直观找到conv4_3的位置。

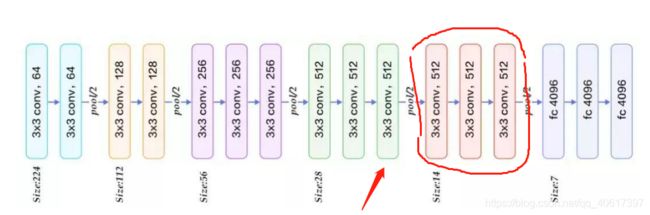
箭头所指的是conv4_3,后面是三层卷积层是所要加入Inception模块。如下图所示。
MDFN的预测层将conv4_3层中位于13深度处的低级特征组合在一起,其中输出特征图的分辨率为38×38。这提供了直接的高分辨率特征以及足够的 硬物体检测任务的详细信息。
Layer structure of deep inception module
提出了两种深度特征学习网络体系结构,分别成为MDFN-I1和MDFN-I2. 它们都具有四个high-level deep feature Inception单元。 每个单元均由1×1卷积层和随后的多尺度过滤层组成,其中引入1×1卷积作为瓶颈层,以减少输入特征图通道的数量[38]。 由于特征图的大小在网络的较深部分仍在不断减小,因此我们在两个MDFN模型的前两层conv_6层和conv_7层中引入了建议的信息立方Inception模块,其中输出特征图的分辨率分别为19×19、10×10。 因此,考虑到接下来两层的输入特征图的大小已经相对较小,我们将信息正方形模块都引入到MDFN-I2的后两个高级层中,即conv_8层和conv_9层,而仅引入信息正方形模块进入MDFN-1中的conv_8层。

学习指标积累: 提出的MDFN采用随机梯度下降(SGD)算法进行训练[39],[40]。
由于GPU内存的限制,我们的模型在KITTI上的最小批量大小为16,在PASCAL VOC和COCO上的最小批量大小为32。
所有数据集的动量都设置为0.9,权重衰减为0.0005,这与Liu等人的训练方法相同。 [10]。 对于KITTI和PASCAL
VOC,培训迭代的总数设置为120,000,对于COCO,则设置为400,000。
我们维持一个恒定的学习率衰减因子,对于KITTI和PASCAL
VOC,当前学习率乘以0.1时为80,000和100,000次迭代,对于COCO为280,000和360,000。
MDFN-I1和MDFN-I2模型在KITTI和COCO上分别采用0.0006、0.0007和在Pascal
VOC2007上分别采用0.0008、0.0007的学习率。
DFN将默认框与Jaccard重叠高于0.5阈值的任何地面真相框匹配。 MDFN将默认框的纵横比设置为{1,2,3,1 / 2,1 / 3}。 我们通过平滑的L1损失[41]和通过Softmax损失的置信度损失最小化关节定位损失,如下所示。
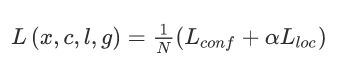
其中N表示匹配的默认框的数量,权重项α设置为1 [10]。 Lconf和Lloc分别代表置信度损失和定位损失。 对于数据扩充,我们采用与原始SSD模型相同的方法[10]。 我们不使用最新的SSD相关框架[10],[27]所使用的随机扩展扩充技巧。
4 Experiments
4.1 Dataset
KITTI:KITTI对象检测数据集是为自动驾驶而设计的,其中包含具有挑战性的对象,例如小型和封闭的汽车,行人和骑自行车的人。 它是通过立体摄像机和LiDAR扫描仪在高速公路,乡村和城市驾驶场景中获得的。 用于对象检测的KITTI包含用于训练和验证的7481张图像和用于测试的7518张图像,根据遮挡和截断的对象数量,提供了大约40,000个对象标签,分为易,中和硬标签。 由于测试集的基本事实尚未公开,因此我们按照[30],[44]中的方法,将7381个训练和验证图像随机平均地分为训练和验证集。 我们根据验证集评估提出的MDFN模型,并按照[18],[44]中的建议在三个难度级别上报告其平均精度(AP)。 对于KITTI实验,我们将所有输入图像缩放为1242×375,并使用16的批处理大小。我们的模型经过训练可以检测3类物体,包括汽车(与汽车合并),行人和骑自行车的人。 汽车,行人和骑单车的门槛分别为70%,50%和50%
PASCAL VOC 2007:在VOC实验中,我们遵循文献中的常规做法,对模型进行PASCAL VOC 2007和2012 Trainval集合的联合训练(16,551张图像),并在PASCAL VOC 2007测试集(4,952张图像)上进行了测试。 我们将所有输入图像缩放到500×500。我们的模型经过训练可以检测VOC上的20种物体。 VOC中每个类别的重叠阈值设置为0.5。 表6中列出的所有方法都遵循与上述相同的规则,除了输入图像的比例。
COCO:微软COCO[20]是一种广泛使用的视觉识别数据集,专注于全场景理解。 COCO中的对象包含多种比例和遮挡情况,其中对象的缩放比例小于PASCAL VOC。 我们利用trainval35k [45]进行训练,并遵循[10]中的策略。 实验在两个图像比例尺上进行,分别为300×300和512×512。结果显示在COCO test-dev2015上,并根据COCO样式的平均精度(AP)进行评估。
4.2 Detection results on KITTI
AP:
MDFN与10个最新模型对KITTI数据集进行评估。包括RPN [41],[46],SubCNN [44], MS-CNN [47],PNET [30],Pie [30],SqueezeDet [30],SqueezeDet + [30],VGG16 + ConvDet [30],ResNet50 + ConvDet [30]和SSD [10]。
从表2中可以看出,拟议的MDFN-I1和MDFN-I2网络在AP方面取得了显着改善,尤其是对于行人和骑自行车的人而言。 它在三个类别中所有三个难度级别的平均平均精度(mAP)大大优于所有最新方法。值得注意的是,对于所有三个类别,MDFN在检测属于中级和硬性级别的对象方面表现最佳,而针对中级和硬性对象的改进性能则为最终的最终mAP做出了贡献。 基于上述实验,很明显,MDFN在杂乱场景中检测较小和被遮挡的物体方面表现更好。


来自四个不同场景的四组图像。 在每组中,最上面的是原始图像,另外三个从上到下分别是SSD,MDFN-1和MDFN-1的结果。 在左上角,MDFN-I2检测到四辆汽车,三位行人的准确性很高,而SSD仅检测到两辆汽车和两名行人。 MDFN-I2甚至能够检测到红色汽车右肩上的微小被卡住的车辆,而其他所有模型都无法找到它。 在右上角的设置中,MDFN-I2比其他两种型号检测到的汽车多两辆,其中一辆位于图像的最左边,另一辆位于视图的尽头。 在左下角的设置中,与三个SSD相比,MDFN检测到四或五个行人。 在最后一组中,MDFN-I1检测到行人与骑自行车的人平行,而另一人则在左侧车后。 MDFN-I2错过了两个行人,但它是唯一一种检测场景右侧立柱所挡住自行车的模型。 这四个示例显示了MDFN在检测小的和被遮挡的物体方面的卓越能力。
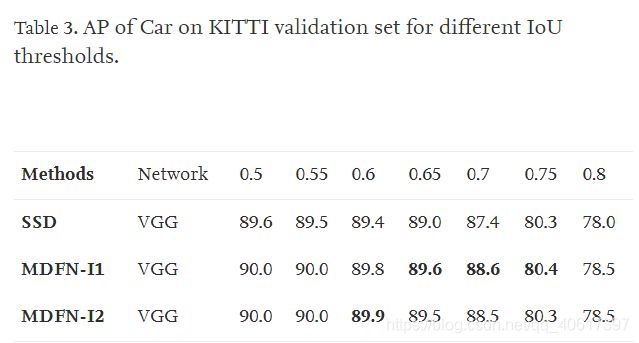
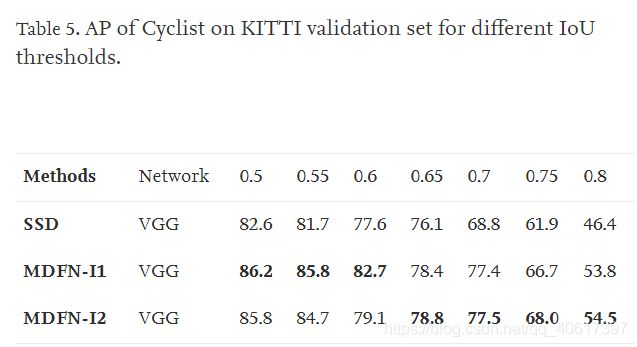
在多个IoU下的性能:我们采用具有不同IoU阈值的mAP进行进一步评估。 在表3和表5中,我们分别提供了IoU从0.5到0.8(以0.05为步长)对汽车,行人和骑自行车者的SSD和MDFN模型的性能。 我们可以观察到,在不同的IoU下,MDFN模型的性能始终优于SSD。 该实验进一步证实了从表2中得出的结论的稳健性。很明显,当骑自行车者和行人的IoU高于0.65时,MDFN-I2具有明显的优势。 例如,对于表4所示的行人,当IOU为0.75时MDFN-I2优于SSD 6%,而对于表5中所示的骑自行车者,当IoU为0.8时MDFN-I2优于SSD 8%。 该实验进一步证明了所提出的MDFN模型能够提供更准确,更强大的检测性能。

4.3 Detection results on PASCAL VOC dataset

VOC2007数据集上的四组SSD和MDFN模型的比较检测示例。 在每组中,从左到右的三个图像分别代表SSD,MDFN-1和MDFN-1的结果。
上图显示了VOC上的一些比较检测示例,其中MDFN模型在复杂场景中的性能更好。 例如,MDFN-I2检测到四个瓶子,而SSD在第一组中只有两个。 在第二组中,MDFN-1检测出另一只鸟。 第四组中较小的船由MDFN模型检测到,而SSD错过了。 在最后一组中,MDFN-I2检测到更多的人,尤其是戴红色帽子的前男孩闭塞的两个人。 与mAP相比,MDFN-1不高于MDFN-1。 在后面的小节中将对此现象进行更多的讨论和分析。
4.4 Detection results on COCO
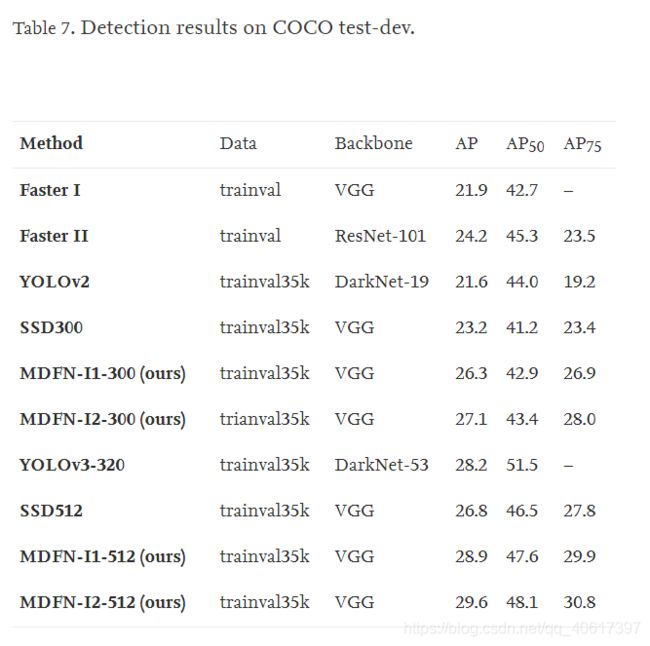
表7中显示了基于COCO基准的检测AP,同时还提供了主流检测模型的比较结果,包括Faster I [10],[46],Faster II [10],YOLOv2 [50],YOLOv3 [53]。 ,SSD300 [10]和SSD512 [10]。 在AP,AP50和AP75这三个条件下,所提出的MDFN-I2模型在512的图像分辨率下以最高的精度领先于电路板,其中AP表示80个类别(AP @ [。 50:.05:.95]:从0.5到0.95开始,步长为0.05)。 我们可以观察到,MDFN模型在所有三个标准上均显示出明显优于两级检测器(即Faster I和Faster II)和一级检测器(即YOLO和SSD)。 特别是对于AP75,MDFN显示出MDFN-12-512的收益率超过30%的优势。 与KITTI和VOC数据集相比,MDFN对于硬对象的性能更好。 相比之下,尽管YOLOv2和YOLOv3对于AP50都实现了更高的精度,但是AP和AP75的精度表明它们在困难情况下的性能较差。 这反映了YOLO模型在识别对象的精确位置方面的缺点。 显然,在300和512的图像比例上,MDFN与SSD相比均具有更强的鲁棒性,这支持了以下观点:深度特征在语义上是抽象的,适合于提取全局视觉图元。 MDFN-I2优于MDFN-I1的性能归因于更深的多尺度特征学习,对于更高的IoU阈值,这尤其明显,例如在0.75的IoU时,从SSD300到MDFN-I2-300显着提高4.6%。 ,而0.5时为2.2%。 对于500的图像比例,MDFN表现出相同的优势。 这些结果与第3节中的理论分析是一致的,并且与其他两个基准的性能相符。
4.5 Multi-scale feature depth vs performance
在这项研究中,我们提出了两个模型MDFN-1和MDFN-1,目的是探索在不同网络深度产生的特征的有效性。 在此,网络深度定义为从基础网络之后的多个深层中提取深度多尺度特征的最大层深度。 对于MDFN-I1,其多尺度特征深度为3,对于MDFN-I2,其为4。 MDFN-I2从预测层之前的所有四个深层提取深层特征。 从理论上讲,这将增强特征表达和场景理解的能力。 但是,根据KITTI和VOC2007上的mAP结果,MDFN-1不超过MDFN-1。 如果我们增加IoU的阈值,则MDFN-I2会显示出更高准确性的优势,尤其是从表4和表5中可以看出这一点。
从图5(a)和(b)中,MDFN-I2能够检测反射的物体,例如(a)中的飞机和(b)中屏幕上的女士。 这些对象通常具有模糊特征或比真实对象小得多的大小。 因此,对它们的成功检测展现了MDFN-I2的强大功能。 这是降低mAP的原因之一。 从图5(c)中,MDFN-I2对一些不确定的对象(例如绵羊)产生多种选择,回到视野中被检测为绵羊或母牛。 错误检测具有有限特征的对象也会导致mAP降低。 尽管如此,通过考虑更多上下文信息,MDFN-I2在大多数情况下仍能提供更准确的定位和更好的分类,例如(d)中的乐队演奏家,其中与MDFN-I1给出的零件识别相比,MDFN-I2完全确定了他的身影。 考虑到空间,我们在这里仅显示有限的示例。 但是,MDFN-I2有时无法检测到部分被遮挡的人,例如下半部分被遮盖的开花灌木丛后面的男人,或仅在集体照中露出头的女士。 这种泄漏检测是可能的,因为MDFN-I2会比MDFN-1更加考虑上下文信息,尤其是当此类对象占整个数据集的一小部分时。 这可能是在PASCAL VOC的总体mAP中MDFN-I2不能击败MDFN-I1的另一个原因。

4.6 Efficiency discussion
知识点补充
1、low-level feature 和 high-level feature
参考链接:
https://blog.csdn.net/nanhuaibeian/article/details/103305128
- Low-level feature: 通常是指图像中的一些小的细节信息,例如边缘(edge),角(corner),颜色(color),像素(pixeles), 梯度(gradients)等,这些信息可以通过滤波器、SIFT或HOG获取。
- high-level feature:是建立在low level feature之上的,可以用于图像中目标或物体形状的识别和检测,具有更丰富的语义信息。
high-level feature 常被人称为是高级的语义信息, 他的感觉就像通过环境信息 纹理信息,等等一些信息综合得出来的一个信息,然后分类or检测的时候在使用它去进行判断。
特点:
low-level feature 它是怎么来的?
它是原图通过很浅的几层卷积得到的输出,这里提一个感受野,浅层的特征他的感受野较小,例如:他只从5x5的区域提取一个边缘信息。 high-level feature 他的感受野大, 他可以从100x100的区域总结一个语义信息。
当只使用high-level的特征做预测的时候 他可以得到大体的目标的状态,一个很宏观的角度。当引入low-level的特征就会弥补很多细节信息。
其实low-level high-level 其实也要分任务的,不同任务理解也不太一样。
2 ground truth
简单说,就是参考标准。
在有监督学习中,数据是需要标注的,以(x,t)的形式出现,其中x是输入数据,t是标注。正确的标注是ground truth。
模型函数的数据是(x,y)的形式出现的,其中x是输入数据,y是模型预测的值。标注和模型的预测结果作比较。在损失函数中(loss function / error function)中会将y和t作比较,从而计算损耗。

3 mAP
AP 代表Average Precision 即平均精确度。
mAP 代表 Mean Average Precision 即均值平均精度。
计算mAP方法详见链接:https://blog.csdn.net/hsqyc/article/details/81702437?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
总结:
针对此篇文章的阅读,着重学习了此篇文章的思想,使用的方法。提出新的模型,在深层网络中添加信息立方和信息平方Inception模块。在不同数据集对此模型进行评估,可以说明此模型的创新性在小目标、被遮挡的目标检测中有更好的精读。另外,文章也将MDFN-I1模型与MDFN-I2模型进行比较。两者在网络上的区别主要是前一个深度为3,第二个深度为4。通过对比发现,虽然I1模型的mAP略高于I2,但是I2模型能够检测出模糊特征或比真实对象小得多的图像,比如说玻璃反光的图像或者是电脑屏幕中的对象。说明I2模型能更加结合上下文信息和语义信息,对物体进行检测。但是,在文章中,也提到I2模型有漏检的情况以及对不确定的物体出现有多个标签的情况。这也是mAP低于I1的原因。