深度学习——门控循环单元GRU(笔记)

在某些情况下,希望存在某些机制能够实现:
①能够在一个记忆元里存储重要的早期信息
②能够跳过隐状态表示中的此类词元
③能够重置内部状态表示
1.关注一个序列
①不是每个观察值都是同等重要

ⅠRNN处理不了太长的序列,因为RNN把序列信息全部放在隐藏状态里面。当时间到达一定的长度的时候,隐藏状态积累过多的信息,不利于相对靠前的信息的提取。
Ⅱ序列的每个观察值不是同等重要。对于一个猫的图片的序列突然出现一只老鼠,老鼠的出现很重要,第一次出现猫也很重要,但是之后再出现猫就不那么重要了。句子的关键字重要,其他字不是很重要
ⅢRNN没有特别关心某些地方的机制,对于它来说是一个序列。门控循环单元通过一些额外的控制单元,使得在构造隐藏状态的时候能够挑选出重要的部分。
②只记住相关的观察需要:
Ⅰ能关注的机制(更新门)Zt:数据重要,更新隐藏状态
Ⅱ能遗忘的机制(重置门)Rt:此刻的输入不重要,或者丢掉隐藏状态的一些东西。
2.门
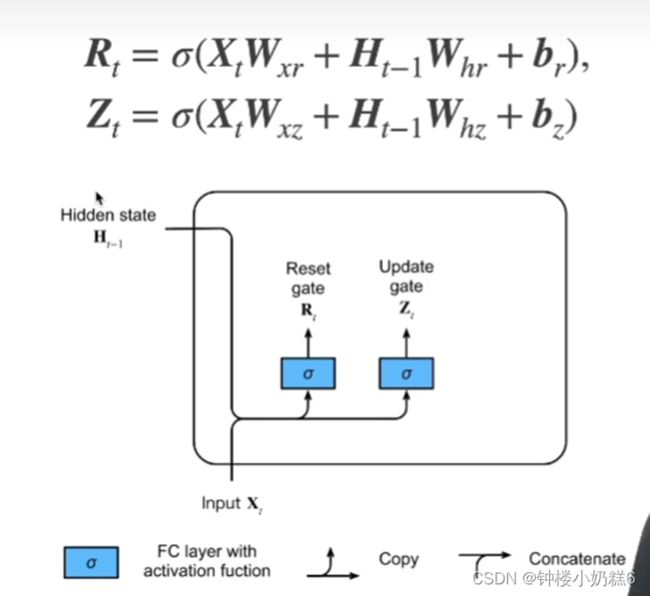
①门控循环单元模型:输入是当前时间步的输入和前一时间步的隐状态。重置门和更新门输出是使用sigmoid激活函数的两个全连接层。
②xt输入,H(t-1)隐藏状态
③Rt是重置门,Zt是更新门
3.候选隐状态:不是真正的隐状态,只是用来生成真正的隐藏状态
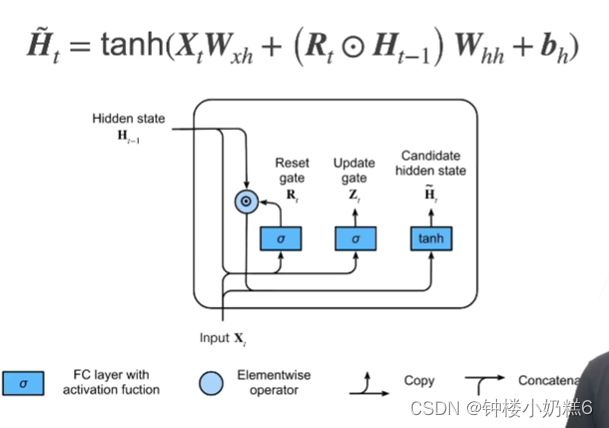
①Rt是取值0~1的值,Rt越靠近0,Rt和H(t-1)按元素乘法得到的结果就越靠近0,相当于上一时刻的隐藏状态忘掉。
②当Rt全部变为0,相当于从当前时刻开始,前面的信息全部不要,隐藏状态全部变为0.从初始化状态开始,任何预先存在的隐状态都会重置默认值。
③当Rt全部是1,当前时刻所有的信息更新,等价于RNN的隐状态更新方式
④Rt是一个可学习的参数。根据前面的信息学习哪些信息能够进入隐藏状态,哪些信息需要舍弃。自动进行的控制单元。
4.隐状态
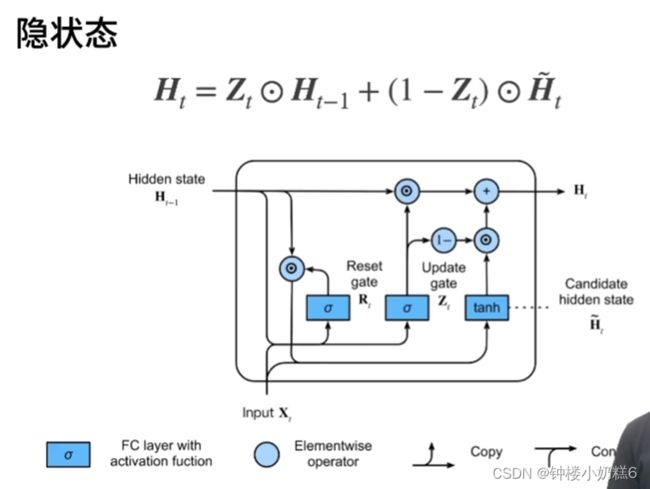
①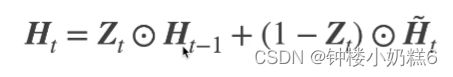
②Zt的取值范围是0~1
③当Zt是1的时候,即Ht等于H(t-1)。相当于不使用此刻的输入xt更新隐藏状态。隐状态使用过去H(t-1),xt的信息忽略。
③假设Zt是0。Ht等于候选隐状态
【总结】
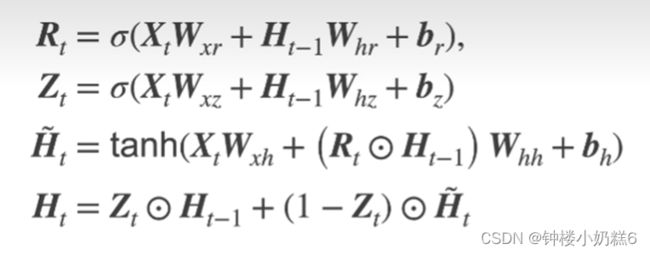
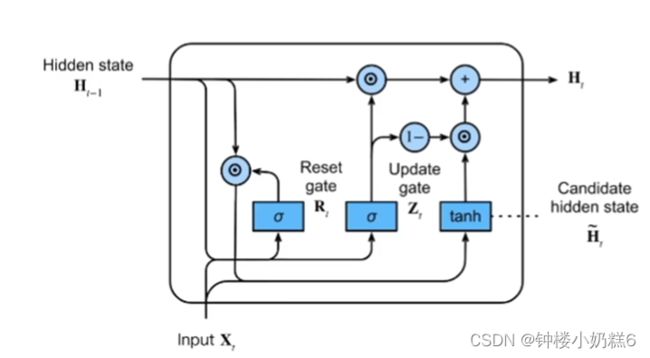
①Rt是衡量更新隐藏状态时,用到多少过去隐藏状态的信息
②Zt是衡量更新隐藏状态时,用到多少xt的相关信息。
③当Zt全为0,Rt为1等价于RNN
④Zt全为1时,忽略当前的Xt
【代码】
import torch
from torch import nn
from d2l import torch as d2l
# 批量大小32,句子长度35
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 初始化模型参数:标准差0.01的高斯分布,偏置项0,超参数num_hidden隐藏单元数量
# 初始化模型参数:标准差0.01的高斯分布,偏置项0,超参数num_hidden隐藏单元数量
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size # 字典大小
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
# 定义模型
# 定义模型
def init_gru_state(batch_size, num_hiddens, device):
'''隐藏状态初始化函数'''
return (torch.zeros((batch_size, num_hiddens), device=device), )
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z) # 更新门
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r) # 重置门
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)训练与预测
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)