迁移学习的模型训练
用深度学习解决目标检测有两个重要工作:
1、设计、实现、训练和验证模型
- 模型如果设计
- 模型如何编程实现
- 如何收集足够的数据来训练并验证模型是否符合预期
从头开始设计、实现、训练和验证模型是需要有众多深度学习算法人才做支撑,并且极其耗时耗力
2、深度学习模型应用
根据实际项目的要求,基于预训练模型做迁移学习,这个对刚入门的工程师来说可以快速的掌握
使用tensorflow预训练模型
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
预训练模型
已训练好的模型即预训练模型的命名规则

预训练模型的文件组成

迁移学习需要先从checkpoint文件读取现有模型的变量、权重等重要数据,然后基于新的训练数据集继续训练模型
由于checkpoint文件个数太多,不方便推理计算调用,所以当模型训练完毕后,执行模型frozen(冻结)操作,即把所有变量的值提取出来变成变量,与模型权重一起合并为一个*.pb文件
最后一个文件时文本格式,用于是哪个城tensorflow graph(计算图)的配置文件,迁移学习时,需要修改里面的一部分参数
开始
准备图片:下载猫狗数据集
第一种:直接从百度搜猫狗图片
第二种:从Kaggle直接下载猫狗数据集
下面演示kaggle数据集下载
kaggle数据集下载
第一步:注册账号https://www.kaggle.com/
第二步:可以直接下载https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/data
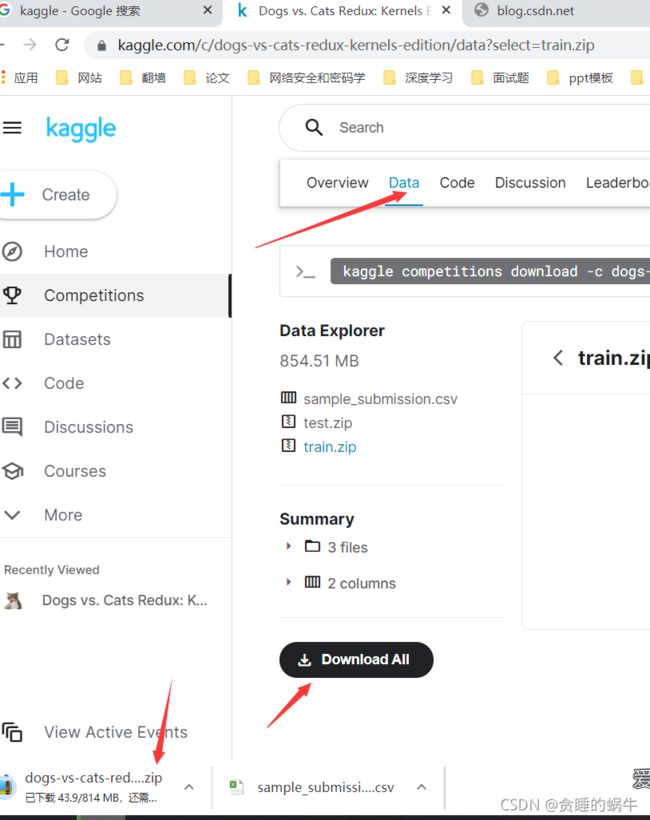
如果不能,激活tf_gpu虚拟环境 输入代码pip install kaggle
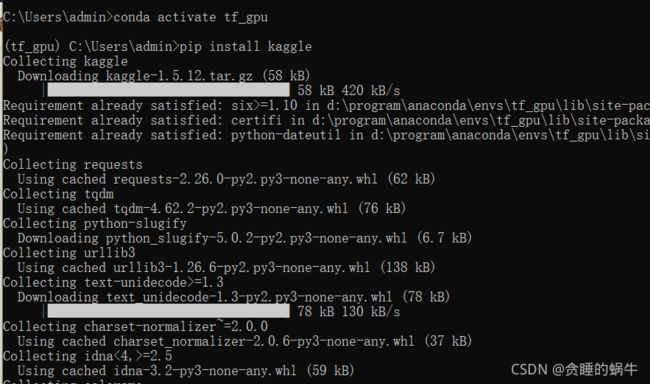
下载kaggle.json 需要登录kaggle账户页面,把username换成自己的账户号,也就是需要登录kaggle,然后再账户页面单击Create New API Token按钮,会开始下载kaggle.json文件
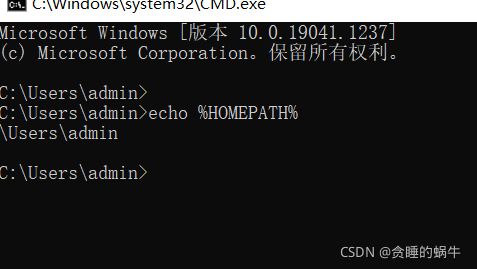
在cmd里输入命令 echo %HOMEPATH%
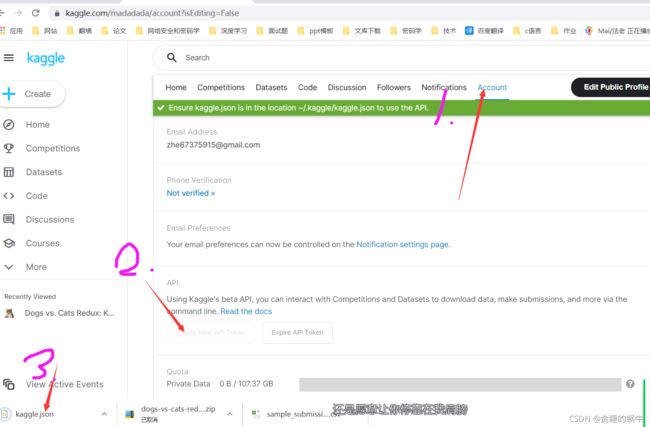
那么将上面下载的文件放入到c:\users\admin\.kaggle文件夹里面
注意前面确实有个点
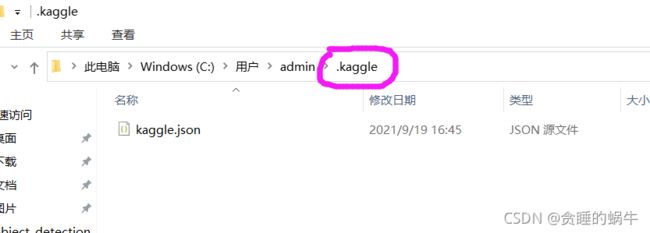
进入数据集下载页面,单击下载命令复制按钮

激活虚拟空间,输入指令
概念验证
一个新项目开始之前,先用100张/类的数量做技术评估,是一个常用的PoC(概念验证)方案,如果按100/类的数量训练出来的模型的识别准确率超过85%,那么这个新项目用深度学习技术来完成物体识别工作是基本没有问题的
训练图片的样本不平衡问题
如果一个训练数据集的A样本是99个,B样本只有1个,训练算法很有可能让AI模型放弃识别B,直接把所有样本都识别为A,为了实现训练样本数量平衡,通常使用数据增强处理
使用Labellmg标注图片
建立猫狗项目文件夹结构
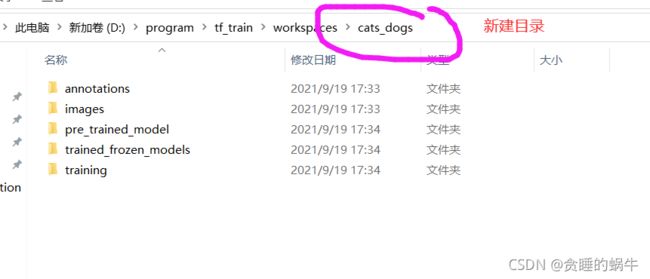
新建cats_dogs的文件夹,意思是用来识别猫和狗的
在cats_dogs文件夹下,依次新建上述文件夹
- annotations(标注)用于存放.csv文件、标签映射文件*.pbtxt和对应的TensorFlow *.tfrecord文件,这些文件存放图像的标注信息
- images(图像)存放着训练图片和测试图片,以及对应的*.xml LabelImg标注文件

将train数据集里面的100张狗,100张猫图片放入到train,将test数据集里面的二十张图片复制到test,将train文件夹中的图片标注完毕后,复制十分之一的图片连通标注文件到images\eval文件夹,供训练的评估evaluation操作使用
- pre_trained_model文件夹存放预训练模型,将先前下载的预训练模型全部复制到此文件夹中,包括文件夹
- trained_frozen_models文件夹保存训练完毕的冻结图模型文件(*.pb)
- training文件夹用于存放训练配置文件*.config,以及训练过程中产生的文件
标注图片
一、修改打标里面的predefined_classes.txt文件,将里面的标签改为cat和dog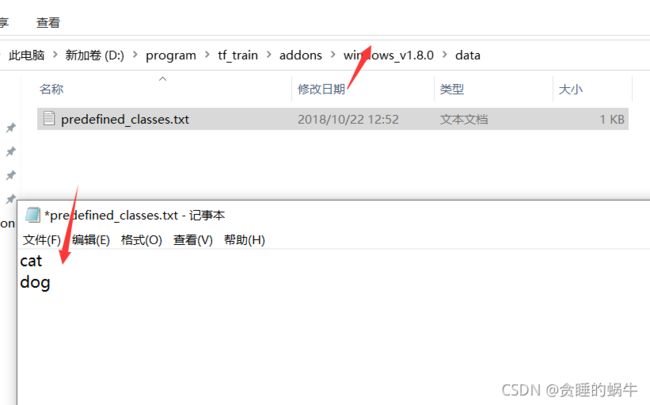
二、打标
打开打标程序,单击open dir按钮,选到训练图片所在的文件夹train
单击change save dir按钮,选择存放标注文件*.xml的文件夹,同样是放在 train
然后点击create rectbox启动标注功能,或者按w键
菜单中有自动保存选项,然后按w选框,也有默认标签可以进行设置,然后按d下一张
打开文件夹后可以发现里面每个文件旁边都有一个与之名字相对应的.xml文件
复制10%的数据到eval文件
深度学习的数据集分为训练(train)、评估(eval)、测试(test),训练数据和评估数据都在训练过程中使用,建议比例为train:eval=8:2。注意xml文件也要复制
依据标注类型创建标签映射文件
新建label_map.pbtxt文件。
如果有两个类型,那么id的编号从1到2,如果有四个类型,那么id就到4
item {
id:1
name: 'cat'
}
item{
id:2
name:'dog'
}
放到这里
创建TensorFlow TFRecord文件
使用脚本将xml_to_csv.py将多个xml文件转换成一个.csv文件
使用脚本generate_tfrecord.py将.csv文件转换为.tfrecord文件
由于这两个工具都使用了pandas库,所以conda install pandas安装pandas库
将.xml文件转换为.csv文件
运行那个python文件,首先到py所在的目录,地址栏输入cmd,然后调出虚拟环境,输入命令
这个命令要运行两次,一次是train文件夹里面进行转化,第二次是将eval文件夹里面的进行转化
python xml_to_csv.py -i [path_to_images_folder]\train -o \ [path_to_annotations_folder] \xxx_labels.csv第一个[] 用images文件夹的绝对路径替代
第二个[]用annotations文件夹的绝对路径替代
xxx_labels.csv替换为对应的train_labels.csv或者eval_labels.csv
所以
train标注数据转换完整命令
python xml_to_csv.py -i D:\program\tf_train\workspaces\cats_dogs\images\train -o D:\program\tf_train\workspaces\cats_dogs\annotations\train_labels.csveval标注数据转换完整命令
python xml_to_csv.py -i D:\program\tf_train\workspaces\cats_dogs\images\eval -o D:\program\tf_train\workspaces\cats_dogs\annotations\eval_labels.csv
将csv文件转换为tfrecord文件
修改generate_tfrecord.py文件

然后转化,到这个py所在位置,打开cmd,打开虚拟环境,输入代码
python generate_tfrecord.py -label0={label_name0} -label={label_name1} --csv_input=[path_to_annotatinos_folader]\xxx_labels.csv --output_path=[path_to_annotainos_folder]\xxx.tfrecord --img_path=[path_to_images_folder]\train
将{label_name0}、{label_name1}换成cat与dog
最后一个[]换成images绝对路径
[path_to_annotainos_folder]换成annotations文件夹的绝对路径
train_labels.csv文件转换为train.tfrecord文件的完整命令
前两个参数是名字,第三个参数是train_labels.csv文件所在的绝对路径
第四个参数是生成的.tfrecord文件放置的位置,放置到annotation里面
最后一个文件时train图片的绝对路径
python generate_tfrecord.py --label0=cat --label1=dog --csv_input=D:\program\tf_train\workspaces\cats_dogs\annotations\train_labels.csv --output_path=D:\program\tf_train\workspaces\cats_dogs\annotations\train.tfrecord --img_path=D:\program\tf_train\workspaces\cats_dogs\images\traineval_labels.csv文件转换成eval.tfrecord文件的完整命令
前两个参数是名字,第三个参数是eval_labels.csv文件所在的绝对路径
第四个参数是生成的.tfrecord文件放置的位置,放置到annotation里面
最后一个文件时eval图片的绝对路径
python generate_tfrecord.py --label0=cat --label1=dog --csv_input=D:\program\tf_train\workspaces\cats_dogs\annotations\eval_labels.csv --output_path=D:\program\tf_train\workspaces\cats_dogs\annotations\eval.tfrecord --img_path=D:\program\tf_train\workspaces\cats_dogs\images\eval
修改预训练模型的配置文件
API框架使用扩展名为.config的training pipeline配置文件来获得训练和评估过程的输入参数
预训练模型的配置文件
配置文件在下载的models里面,路径为models\research\object_detection\samples\configs

将其复制到
配置文件的结构
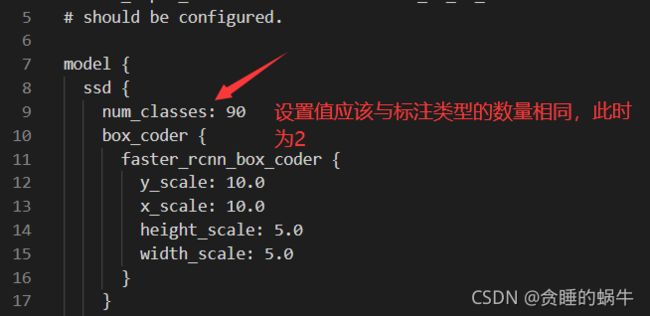
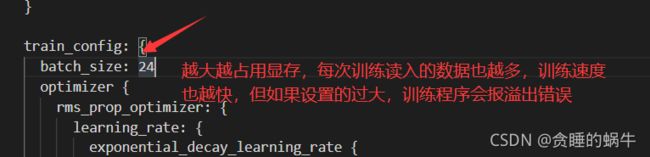
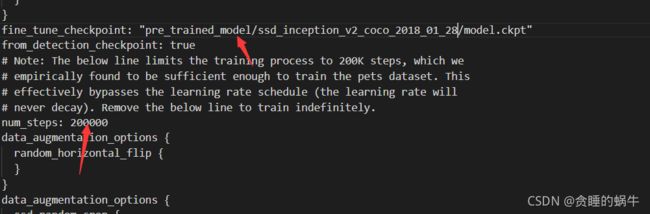


训练模型
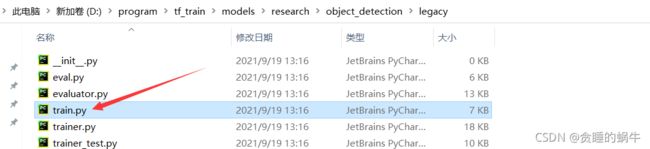
将这个py文件复制到cats_dogs文件夹中
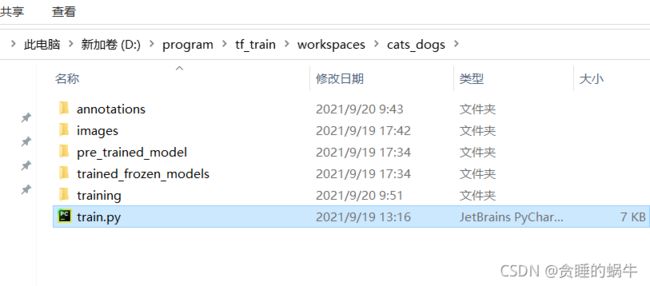
在cats_dogs文件夹里面激活虚拟环境
输入命令
python train.py --logtostderr --train_dir=training\ --pipeline_config_path=training\ssd_inception_v2_coco.config--logtostderr:把log信息记录到stderr
--train_dir:存放训练过程中生成文件的文件夹
--pipeline_config_path:预训练模型的配置文件
一键创建文件夹结构
搭建好模型环境后,以及将提供的srcipts文件复制到tf_train文件夹下面,
将提供的create_directories.py 文件复制到workspaces
在workspace启动激活环境,输入命令
python create_directories.py -n my_training_demo
将标注好的图片按要求复制到images里面的三个文件夹里面
将one_command_train.py 文件复制到my_training_demo文件夹中
在这个文件夹里面 启动环境 输入
python one_command_train.py --steps 500 --batch_size 12