ResNet原理讲解和复现( Keras)
文章目录
- 前言
- 一、ResNet
-
- 1.为什么要引入残差结构
- 2.残差网络
- 二、ResNet50
-
- 1.网络结构及实现
- 2.数据读取与模型训练
- 总结
前言
本片博客,通过参考了pytorch复现的代码,成功复现了ResNet50,并使用270 Bird Species also see 73 Sports Dataset去训练了ResNet50。最后在验证集和测试集上都达到了80%~83%的准确率。本篇文章还会介绍一下ResNet网络的一些理论,简要分析一下为什么ResNet能够加深到100层甚至1000层。
| 内容 | 地址 |
|---|---|
| kaggle | 链接 |
| 数据集 | 链接 |
| 百度网盘 | 链接 提取码cd0i |
| 论文地址 | 链接 |
一、ResNet
1.为什么要引入残差结构
通过前面介绍的AlexNet,VGG,GoogLeNet网络的出的结论——随着卷积神经网络的不断加深,网络的性能越来越好。于是人们就开始不断的加深卷积网络,然后效果却不是那么理想。我们可以看一幅图:
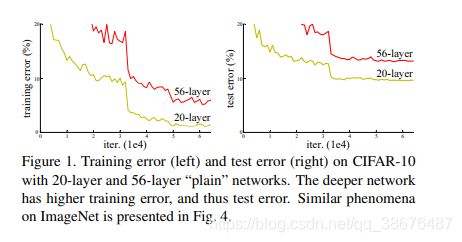
这两幅图比较了56层卷积网络(VGG)和20层卷积网络(VGG)在数据集CIFAR10上的表现。左边是train error,右图是 Test error。显然深层的网络错误了高于了浅层网络。于是何凯明教授就提出了残差学习结构,用于解决这一问题。如下图所示:
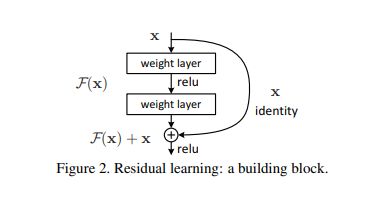
这种连接方式成为 “shortcut connection”,类似于电路中的“短路”现象。上述结构可以表示为:
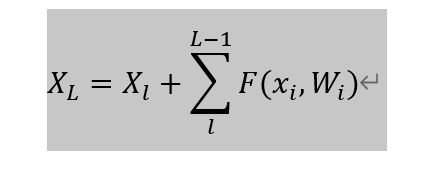
其中 X l X_l Xl是上一个残差快的输出,公式
∑ i = l L − 1 F ( X i , W i ) \sum\limits_{i=l}^{L-1}F(X_i,W_i) i=l∑L−1F(Xi,Wi)表示残差函数, X L X_L XL表示叠加的输出。
通过链式法则,反向求梯度可得

小括号里有个1,就算残差梯度为0,梯度也不会消失 哦!
什么 ?没听懂?那我们就再来看两幅图:
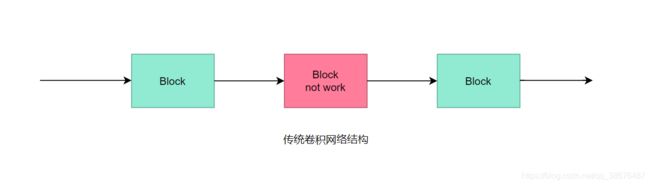
首先我们来看一下传统的“串联”卷积神经网络,如上图所示,如果中间的块(如图中红色块所示)出现了梯度消失的问题,那么反向传播,就不会再传到它前面的块中,网络就很难被训练出一个好的性能了。那么残差是如何解决这一问题的呢?我们看下面两幅图:

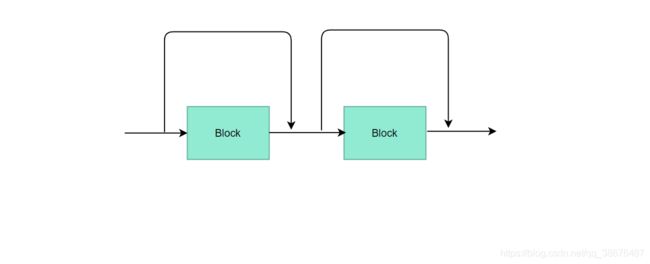
当残差网络中的某些块不工作时,那么梯度仍然也不会消失。如上图所示,当红色的块不工作时,那么这部分的网络结构就变成了如第二张图所示,由三块变成了两块。在残差网络中也是如此,虽然残差结构能堆叠很多很多很多的层。但是其中真正工作的并没有那么多层哦。
2.残差网络

这是34层残差结构,虚线部分表示通道数会改变。图片可能不太清晰可以去原论文中去查看。论文也对比了残差网络在ImageNet效果。如下图所示:
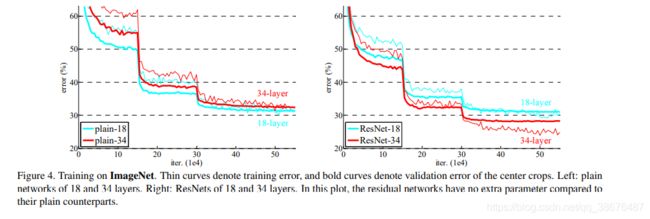
可以从图中清楚的看到残差明显解决了,文章上面提到的问题,ResNet34的效果明显优于ResNet18。
作者在后续的过程中引入了不同层数的残差网络.

上表是在 CIFAR-10 数据集上的测试结果,最高引入了 1202层,但效果没110层效果好。在论文中作者还做了很多有趣的工作。感兴趣的话可以去论文中看看。
二、ResNet50
1.网络结构及实现
ResNet中有两种基本的块,Conv Block 和Identity Block
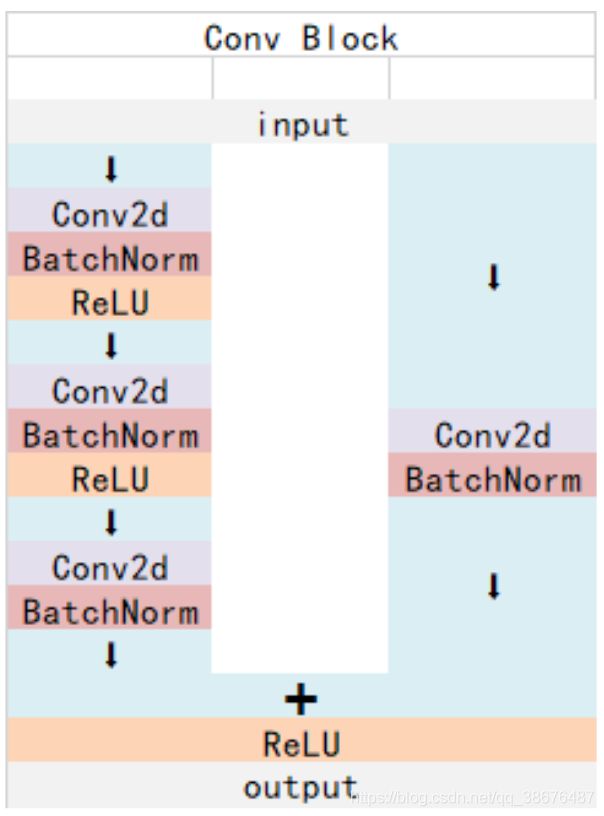
Conv Block输入和输出的维度(通道数和size)是不一样的,它的作用是改变网络的维度。
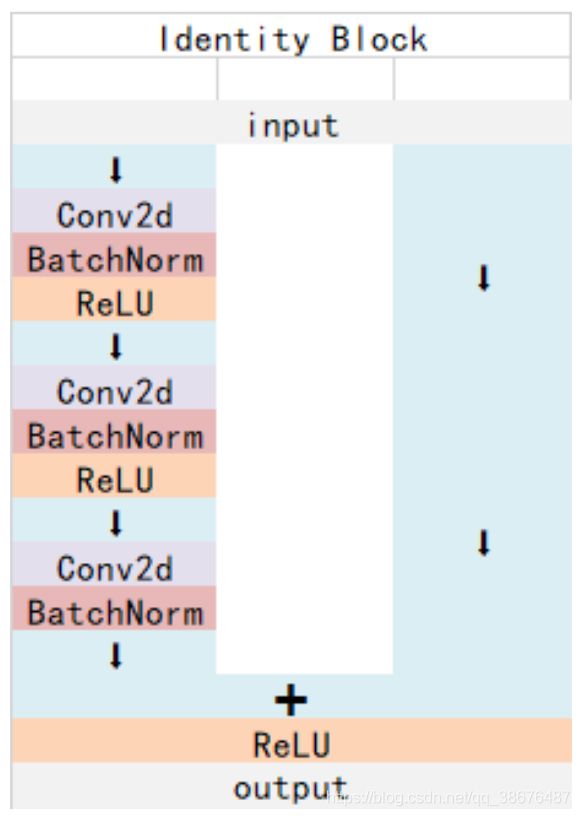
Identity Block输入维度和输出维度(通道数和size)相同,用于加深网络的。
基于这两种结构我们用编写model的方式去实现。
#残差网络中主要是残差块,那么残差块分两种,如图所示残差边含卷积得是因为维度会发生改变
#不含残差边得维度不改变
#开始定义block
class Block(Model):
def __init__(self,input_channels,output_channels,use_conv=False,identity_strides=1):
super().__init__()
self.conv1=Conv2D(input_channels,kernel_size=1,strides=identity_strides)
self.conv2=Conv2D(input_channels,kernel_size=3,strides=1,padding='same')
self.conv3=Conv2D(output_channels,kernel_size=1,strides=1,padding='same')
self.conv_identity=None
if use_conv:
self.conv_identity=Conv2D(output_channels,kernel_size=1,strides=identity_strides,padding='same')
self.bn1=BatchNormalization()
self.bn2=BatchNormalization()
self.bn3=BatchNormalization()
self.bn_identity =BatchNormalization()
def call(self,X):
#这里采用传统残差
Y=self.conv1(X)
Y = self.bn1(Y)
Y= relu(Y)
Y=self.conv2(Y)
Y = self.bn2(Y)
Y= relu(Y)
Y=self.conv3(Y)
Y = self.bn3(Y)
Y= relu(Y)
if self.conv_identity is not None:
X=self.conv_identity(X)
X=self.bn_identity(X)
Y+=X
Y=relu(Y)
return Y
其中input_channels,output_channels 对应块的输入\输出通道,use_conv 表示是否使用卷积边,identity_strides表示卷积边卷积时候的步长。
ResNet50的整体结构:
接着我们用代码来实现它:
#接下来 我们要去组件我们的ResNet 50 了
from tensorflow.python.keras import backend
from tensorflow.python.keras.engine import training
from tensorflow.python.keras.utils import layer_utils
from tensorflow.keras import optimizers, losses, initializers
from tensorflow.keras.activations import relu
def ResNet50(input_shape=(224, 224, 3), input_tensor=None,classes=1000):
if input_tensor is None:
img_input = Input(shape=input_shape)
else:
if not backend.is_keras_tensor(input_tensor):
img_input = Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
X=Conv2D(filters=64,kernel_size=7,strides=2,padding='same')(img_input)
X= BatchNormalization()(X)
X=relu(X)
X= MaxPooling2D(pool_size=3, strides=2, padding='same')(X)
#stage1
X=Block(64,256,True,1)(X)
X=Block(64,256,False)(X)
X=Block(64,256,False)(X)
#Stage2
X=Block(128,512,True,2)(X)
X=Block(128,512,False)(X)
X=Block(128,512,False)(X)
#Stage3
X=Block(256,1024,True,2)(X)
X=Block(256,1024,False)(X)
X=Block(256,1024,False)(X)
X=Block(512,2048,True,2)(X)
X=Block(512,2048,False)(X)
X=Block(512,2048,False)(X)
#这里的输出有点大,我们不用Flatten了 ,采用GlobalAveragePooling2D()吧
#X = Flatten()(X)
#这里我才用全局平均池化来做这件事情
X=GlobalAveragePooling2D()(X)
X=Dense(classes,activation='softmax')(X)
if input_tensor is not None:
inputs = layer_utils.get_source_inputs(input_tensor)
else:
inputs = img_input
model = training.Model(inputs, X, name='ResNet50')
return model
可以从代码注释中看到每个stage的具体实现。下面我们要开始训练模型了~
2.数据读取与模型训练
这次训练配置新加入了一下东西,所以还是看看吧.
配置训练过程:
#配置训练过程
from tensorflow.keras.callbacks import (EarlyStopping, ReduceLROnPlateau,
TensorBoard)
log_dir="logs/"
logging = TensorBoard(log_dir=log_dir)
#monitor:监测的值,可以是accuracy,val_loss,val_accuracy
#factor:缩放学习率的值,学习率将以lr = lr*factor的形式被减少
#patience:当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
reduce_lr = ReduceLROnPlateau(monitor='val_loss',factor=0.5,patience=3)
'''
monitor: 监控的数据接口,有’acc’,’val_acc’,’loss’,’val_loss’等等。正常情况下如果有验证集,就用’val_acc’或者’val_loss’。但是因为笔者用的是5折交叉验证,没有单设验证集,所以只能用’acc’了。
min_delta:增大或减小的阈值,只有大于这个部分才算作improvement。这个值的大小取决于monitor,也反映了你的容忍程度。例如笔者的monitor是’acc’,同时其变化范围在70%-90%之间,所以对于小于0.01%的变化不关心。加上观察到训练过程中存在抖动的情况(即先下降后上升),所以适当增大容忍程度,最终设为0.003%。
patience:能够容忍多少个epoch内都没有improvement。这个设置其实是在抖动和真正的准确率下降之间做tradeoff。如果patience设的大,那么最终得到的准确率要略低于模型可以达到的最高准确率。如果patience设的小,那么模型很可能在前期抖动,还在全图搜索的阶段就停止了,准确率一般很差。patience的大小和learning rate直接相关。在learning rate设定的情况下,前期先训练几次观察抖动的epoch number,比其稍大些设置patience。在learning rate变化的情况下,建议要略小于最大的抖动epoch number。笔者在引入EarlyStopping之前就已经得到可以接受的结果了,EarlyStopping算是锦上添花,所以patience设的比较高,设为抖动epoch number的最大值。
'''
early_stopping = EarlyStopping(monitor='val_loss',min_delta=0,patience=10)
lr_schedule=tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=0.0001, #初始下降速度
decay_steps=train_generator.n//train_generator.batch_size, #多少步长衰减一次
decay_rate=0.95, #衰减率
staircase=True
)
开始训练:
from tensorflow.keras.optimizers import Adam
#模型配置并训练
epochs=15 #训练15 epochs
opt=Adam(lr_schedule)
model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=['acc'])
model.fit(train_generator,validation_data=valid_generator,
steps_per_epoch=train_generator.n//train_generator.batch_size,
validation_steps=valid_generator.n//valid_generator.batch_size,
epochs=epochs,callbacks=[reduce_lr,early_stopping]
)
我训练了15 个epochs,训练有点过拟合了,我建议10个 epochs 差不多了
最后呢是在验证集和测试集上的准确率
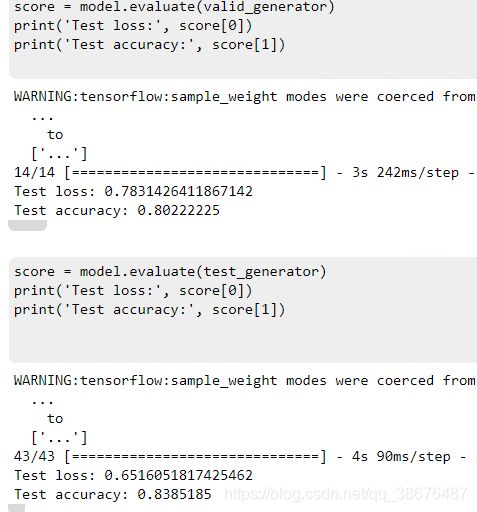
准确率在80%~83%左右.
总结
通过前面网络的复现呢,这篇文章复现还是比较容易的,ResNet网络呢,其实更多的是应用与特征提取,它的能力可不单单值局限与图像分类哦!!那么图像分类的网络就告一段落了,这里还有Net in Net 和 DenseNet 没有去复现了,其实图像分类网络的套路都是一致的,接下来可能是目标检测,目前在啃SSD,里面还有很多不理解的地方, 后续又是机会的也可以了解一下最新的网络.比如炒得很火的transformer,还有讨论它提出来的一些使用多层感知机(MLP)得网络结构.实在复现不出来我就水博客了,机器学习和图像处理 都可以拿来水水.这篇文章还算详细,你的支持是我创作的动力.