顶刊TIP 2023|Rethinking无监督行人Re-ID,中科院研究团队表明采样策略是重中之重

论文标题:Rethinking Sampling Strategies for Unsupervised Person Re-Identification
论文链接:https://ieeexplore.ieee.org/document/9969623
代码仓库:https://github.com/ucas-vg/GroupSampling
作者单位:中国科学院大学、鹏城实验室、天津大学
欢迎关注微信公众号 CV顶刊顶会 ,严肃且认真的计算机视觉论文前沿报道~
期刊介绍:IEEE Transactions on Image Processing(IEEE TIP)是图像处理领域公认的顶级国际期刊,是中国计算机学会(CCF)推荐的A类期刊,代表了图像处理领域先进的重大进展,要求论文在理论和工程效果上对图像处理及相关领域具有重要推动作用,其最新的影响因子为15.8。
无监督的行人重识别 (person re-identification,re-ID) 是计算机视觉领域中一项具有挑战性的任务。之前大量的研究集中在框架设计和损失函数上,与人脸识别研究社区非常相似。但究竟显著影响重识别方法性能的因素是什么呢。来自中国科学院大学、鹏城实验室和天津大学的研究团队认为模型训练时的采样策略起着同样重要的作用,作者分析了同一框架和损失函数下各种采样策略之间性能差异的原因,认为模型的过度拟合是导致性能不佳的重要因素,而在统计层面增强模型的稳定性可以纠正这个问题。受此启发,作者团队提出了一种简单而有效的方法,称为组抽样(group sampling,GS),它将同一类的样本收集到组中进行归一化组训练,这有助于减轻个体样本的负面影响。受GS方法控制的伪标签生成的方式可以保证样本更有效地分类到正确的类别中。它可以调节表征学习的过程,以渐进的方式增强特征表示的统计稳定性。作者在 Market-1501、DukeMTMC-reID 和 MSMT17 三个标准行人重识别数据集上进行了广泛的实验,实验结果表明GS方法的性能可与最先进的方法相媲美,并且在与相机无关(camera-agnostic)的实验设置上达到SOTA效果,目前该文已发表在人工智能领域顶级期刊(IEEE Transactions on Image Processing,TIP)上。
1.引言
本文的主要研究对象为无监督的行人重识别,通过减少数据注释所需的人力消耗,目前的无监督的行人重识别框架可以扩展到实际的应用中。最近提出的SpCL[1]是一种self-paced的对比学习框架,该框架大大提高了无监督人员重识别的性能。因此本文将 SpCL 作为研究基线,在本文中称为对比基线。传统的 person re-ID 框架通过构建三元组(即锚点、正例和负例)来学习类间判别表示和类内相似性。相比之下,对比基线构建了一个记忆库来存储所有样本特征,以便在优化每个锚点时可以直接从记忆库中获取正负样本。这意味着对于对比基线,不需要通过三元组抽样(triplet sampling)参与训练,但令人惊讶的是,当作者使用最直接的随机抽样代替原来的三重抽样时,模型未能获得预期的结果。
本文试图分析和解释为什么不同的采样策略会导致这种异常。作者认为,当采用随机抽样时,个体样本的随机性和倾向性可能会主导整个类的优化方向,从而导致类的特征表示发生变化。具体来说,具有不同ground-truth标签的样本不断聚合,类逐渐失去个体身份特征,倾向于恶化特征表示。用此类形成的伪标签进行监督会导致模型失去区分类内相似性和类间差异的能力,这种现象我们称之为恶化的过拟合。相应地,triplet sampling 成功的关键在于它在每个 mini-batch 中从同一类中选择了一定数量的样本。同类样本的分组有助于降低单个样本对模型优化的影响,突出当前类的整体趋势。
2.采样策略研究
2.1 常用的几种采样策略
广泛用于re-ID训练的采样策略包括随机采样、Triplet Sampling(三元组采样)和重复增强采样等,其中三元组采样是对比基线中的默认方法。
1)随机抽样:随机抽样是深度学习中最简单也是最常用的抽样策略。它从训练集中随机抽取样本,因此每个 mini-batch 的样本组成是完全随机的。
2)Triplet Sampling:Triplet sampling是在每个mini-batch中抽取一定数量的正样本和负样本。具体来说,它以 P × K P\times K P×K 的方式进行数据采样,即随机选择 P P P 个类和每个类的 K K K 个样本。 当一个类中的样本数大于 K K K时,只随机抽取其中的 K K K个,其余的将被丢弃。 反之,当数量小于 K K K时,部分样本将被重新采样。
3)重复增强(Repeated Augmentation,RA)采样:在RA采样中,图像批次数量 B \mathcal{B} B是通过从数据集中采样 ⌈ ∣ B ∣ / m ⌉ \lceil|\mathcal{B}| / m\rceil ⌈∣B∣/m⌉不同的图像形成的,它会对同样的样本逐次抽取m次来填充mini-batch,因此,就 mini-batch 构造而言,RA 抽样与三重抽样的 P × K P\times K P×K 方式非常相似。不同的是,triplet sampling 侧重于对同一类内的不同实例进行采样,而 RA 是对每个实例重复采样。
作者分别对这几种采样策略进行测试,测试效果如下表所示,可以清楚地看出,与随机采样相比,三元组采样产生了很大的性能增益。

2.2 为什么三元组采样如此有效?
在对比基线中,利用样本间的特征相似性和差异性将样本分为不同的类,并为每个类分配伪标签,在这种训练策略下,样本以高度随机的方式在特征空间中更新。生成的类大致可以分为强类和弱类。强类的特征是样本数量相对较多,且在特征空间中的紧凑性,这意味着该类具有稳定的结构。相反,弱类的样本组成比较松散,这意味着它的结构不稳定,容易断裂。当一个类中存在大量具有不同标签的样本时,该类的整体特征变得泛化和粗糙,逐渐失去对个体身份的表征,称为恶化的特征表示。拟合这种具有大量噪声的伪标签,模型陷入学习恶化的特征表示中,从而失去区分类内相似性和类间差异的能力,作者称这种现象为恶化过拟合现象。
过度拟合恶化的后果是具有不同真实标签的各种样本混合在一个类中,如下图中的虚线所示,这样一来,身份的相似结构就淹没在类中,无法正常表达,最终的结果是语义信息的恶化,直接表现为伪标签中噪声的增加,这就是随机抽样导致训练崩溃的原因。
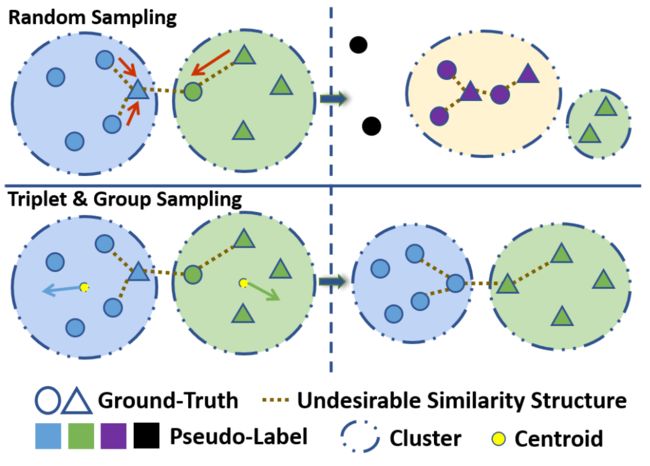
为了应对这一现象,作者提出使用一种统计稳定性的策略,统计稳定性保证类内的相似性结构不会被破坏,同时保持其他类之间的一定程度的区分度。只有类别保持其统计稳定性,模型才能不断探索样本之间本质和复杂的相似性,从而能够区分更详细的差异和粗略的相似性,以满足无监督行人重识别的需要。
其中triplet sampling是一种较为合理的解决方案,其中有一个重要的参数 K K K,即 mini-batch 中每个人身份的实例数。该操作使得属于同一类的一组样本同时被训练,强调了该组的整体趋势。群体中各样本的随机性和自身倾向性减弱,不易从群体中散开。
2.3 GS采样增强的行人重识别方法
虽然triplet sampling相比随机采样等方法实现了显着的性能改进,但其仍然存在一些问题。例如其需要在欠采样和过采样之间进行权衡,triplet sampling 为每个类随机选择固定数量的样本,这可能会导致过采样或欠采样。当发生欠采样时,内存库中的一些样本特征无法及时更新。当一个类中的样本数量过少导致过采样时,该类的样本权重会被放大,从而导致样本不平衡的问题,这两种情况都会影响模型的最终性能。
作者提出使用分组采样(GS)方法来改善triplet sampling。即首先将 C i C_i Ci 类中的样本打乱以增加随机性,然后将每 N N N 个相邻样本打包到每个 C i C_i Ci 中的一个组中,其中超参数 N N N 是每个组中的样本数。需要强调的是,当 C i C_i Ci中的样本数不能被 N N N整除或小于 N N N时,其余样本直接打包成一组,不重新采样。最后,将所有组聚集在一起,并打乱这些组的顺序。下图展示了分组采样的实现细节。
实际算法操作流程如下:

3.实验效果
本文的实验在Market-1501、DukeMTMC-reID 和 MSMT17 三个标准行人重识别数据集上进行,实验评价指标使用mAP和CMC,此外作者强调,本文的实验结果均没有使用后处理操作进行结果增强。
我们随机选择了四个身份,并可视化对比了随机抽样方式和GS方法在训练过程中样本在特征空间中的分布情况,如下图所示,对于随机抽样,这四个身份的样本被分成许多簇,每个簇包含多个身份实例。相比之下,GS抽样可以区分不同身份的样本,并且可以将相同身份的样本正确聚类。
此外,作者选取了从2015年到2021年间的21种re-Id方法进行了性能对比,对比结果如下表所示,可以看到,本文方法在无需任何相机知识的情况下,仍然能获得具有代表性的重识别性能。

4.总结
在本文中,作者对行人重识别任务中的采样策略进行了深入分析,阐述了普通采样方式的缺陷。此外,作者引入了一些新概念,包括恶化的过度拟合和统计稳定性,这些概念对有效提高模型性能具有重要意义。例如,由于过度拟合恶化,随机抽样容易出现训练崩溃的现象。相比之下,本文提出的GS采样方式有助于保持类内的统计稳定性,其有效地减轻了个体样本对统计稳定性的负面影响,充分发挥了对比基线的潜力。此外作者与目前流行的21中re-Id方法进行了广泛的实验对比,实验效果均证明所提方法的有效性。
参考
[1] Y. Ge, F. Zhu, D. Chen, R. Zhao, and H. Li, “Self-paced contrastive learning with hybrid memory for domain adaptive object re-ID,” in Proc. NeurIPS, 2020, pp. 11309–11321.