基于深度学习的自然语言处理笔记
学习基础与线性模型
第二章
2.1 有监督学习和参数化函数
有监督学习的精华是创造了一种通过观察样例进而产生泛化的机制。更具体地说,我们设计了一个算法,算法的输入是一组有标签的样例(比如,这组邮件是垃圾邮件,另一组不是),输出是一个接收实例(邮件),产生期望标签(是否是垃圾邮件)的函数。人们的期望是对于在训练中时没有见过的样例,最终函数可以产生正确的预测标签。
假设类也确定了学习器可以做什么、不可以做什么。一种常见的假设类是高维线函数,也就是这种形式的函数:f(x)=x*W+b ,其中,向量x是函数的输入,矩阵W和向量b是参数。机器学习的目标是确定参数的值,使得函数在输入值x1:k=x1, … ,xk和对应的输出y1, …,yk上表现得和预期相同。因此,搜索函数空间的问题被缩减成了参数空间的问题。通常把函数的参数表示成θ。在线性模型中,θ=W,b。有时候想要通过使用符号更明确地表达函数地参数化,我们将参数包含在函数地定义中:
f(x;W,b)=x*W+b。
线性模型虽然表达能力有限,但它也有几个我们想要地性质:训练简单高效,通常会得到凸优化目标,训练得到的模型也有点可解释性,它们在实践中往往非常有效。
2.2 训练集 验证集和测试集
在深入介绍线性模型之前,让我们重新考虑机器学习问题的通常定义。我们会面对有输入x1:k和相应标签y1:k组成的数据集,目的是构造一个函数f(x),该函数可以将训练集中的输入x正确地映射到输出ŷ。我们怎么知道构造地函数f()的确是好的呢?可以将训练样例x1:k输入f(),记录预测结果ŷ1:k,与其期望标签y1:k比较并计算准确率。然而,这个过程不会提供丰富的信息——我们主要关心的是f()正确扩展到未见实例的能力。函数f()被实现成一个查询表,既在记忆中查询输入x,若该样例已经出现过则返回相应的y值,否则返回一个随机值。这样的话,在这种预测下该函数将会得到满分,但显然这不是一个好的分类器,因为它没有泛化能力。我们宁愿选择一个在训练样例一部分上出错的函数f(),只要它可以得到未见的实例的正确标签。
留一法
留一法交叉验证:训练k个函数f1:k,每次取出一个不同的输入样例xi,评价得到的函数fi()预测xi的能力。之后,在完整的训练集x1:k上训练另一个函数f()。假设训练集是一个由代表性的样本集,在取出的样例上得到正确预测结果的函数fi()的占比应该是一个对f()在新输入上准确率的不错近似。然而,这个过程非常浪费时间,只会在已标注样例数量k特别小(小于100左右)的时候使用。(取平均)
留存法
就计算时间而言,一个更有效的方法是划分训练集为两个子集,可以按照8:2划分,在较大的子集上训练模型,在较小的子集上测试模型的准确率。进行划分时要注意一些事情——通常来说在划分数据前打乱样例,保证一个训练集和留存集之间平衡的样例分布。但是,有时随机的划分不是一个好的选择,比如输入选择的是几个月内的新闻文章,模型期待对新的故事提供预测。(测试集)
三路划分
如果训练一个单一的模型,想要评估它的质量,那么把数据集划分成训练集和留存集很有效。然而,实际上你通常要训练几个模型,比较他们的质量,然后选择最好的那一个。这时,两路划分方法是不够的。已被接收的方法是使用一种把数据划分为训练集,测试集和验证集的三路划分方法。这会给你两个留存集:一个是验证集,一个是测试集。所有的实验,调参,误差分析和模型选择都应该在验证集上进行。保证测试集尽可能纯洁。
2.3 线性模型
目前已经建立了一些方法论,我们返回来描述针对二分类和多分类问题的线性模型。
2.3.1 二分类
在二分类问题中,只有一个输出。f(x)=x*W+b ,函数的值域是(-∞,+∞),为了在二分类中使用该公式,通常将输出通过sign函数,把负数映射为-1(反类),正数映射为+1(正类)。学习的目的是设置W和b的值。有时候不可能使用一条直线将数据点分开,这种数据集被叫做非线性可分,是在线性分类器的假设类表示能力之外的。线性模型设计的一个核心是特征函数的设计,就是所谓的特征工程。深度学习的开创性之一是,它通过让模型设计者指定一个小的核心、或者自然的特征集,让可训练的神经网络结构将它们组合成更有意义的、更高层次的特征或者表示,从而大大地简化了特征工程的过程。
2.3.2 对数线性二分类
我们可能对决策的置信度或者分类器分配这个类别的概率感兴趣,一个可以代替的方法是将输出经过一个扁平函数从而干扰将其映射到[0,1]范围之内,比如sigmoid函数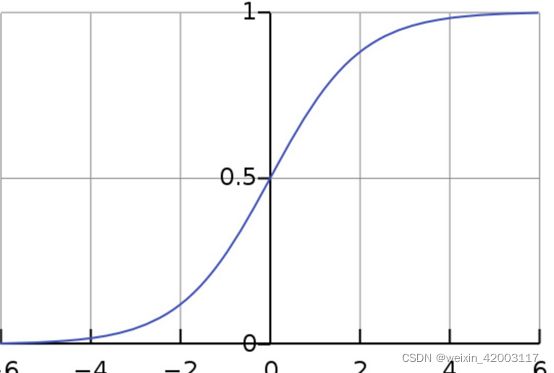 通过对数线性模型得到的二元预测可以被理解为x属于正类的概率估计g(f(x))=P(ŷ=1|x) (g代表sigmoid函数)。也可以得到 P(ŷ=0|x)=1-P(ŷ=0|x)=1-g(f(x))。
通过对数线性模型得到的二元预测可以被理解为x属于正类的概率估计g(f(x))=P(ŷ=1|x) (g代表sigmoid函数)。也可以得到 P(ŷ=0|x)=1-P(ŷ=0|x)=1-g(f(x))。
2.3.3多分类
之前的例子都是二分类问题,有两个可能的类别。二分类情况是存在的,但是大多数的分类问题是多分类的,在这种问题中我们应该把一个实例分配带k个不同的类别中的一个。比如一个6分类问题,ŷ=f(x)=argmax(xw+b)。考虑6个w1,w2…w6,偏置b1,b2…b6。并以最高分来预测结果。6个参数w和b的集合可以被排列成一个矩阵W和向量b*,因此公式可以被重写为:
ŷ=f(x)=x*W+b,
prediction=ŷ=argmaxŷ[i],
i=1,2,…6。
2.4 表示
上面得到的向量ŷ可以被认为是一个表示,它抓住了该文档中对我们重要的属性,也就是不同语言的得分。
表示是深度学习的核心。事实上,有人坚决主张深度学习的主要能力是学习好的表示能力。在线性情况下,这种表示可以理解,在某种意义上,我们可以为表示向量的每一维指派一个有意义的解释。但深度学习模型经常是一个级联的对输入表示,这些表示是不可理解的,我们不知道它们获得了输入的哪些属性,但它们对做出预测是有用的。
2.5 独热和稠密向量表示
独热向量对应于自身分量是1,其余分量均为0。BOW表示包含文档中所有单词的不考虑次序的个性信息。如下面例子:
Little House on the Prairie {“little”, “house”, “prairie”}
Mary had a Little Lambs {“mary”, “little”, “lamb”}
The Silence of the Lambs {“silence”, “lamb”}
Twinkle Twinkle Little Star {“twinkle”, “little”, “star”}
所以用于表示 A数据集 文档的特征如下:
little house prairie mary lamb silence twinkle star
0 1 1 1 0 0 0 0 0
1 1 0 0 1 1 0 0 0
2 0 0 0 0 1 1 0 0
3 1 0 0 0 0 0 2 1
一个独热表示可以被认为是一个单一单词的词袋。
2.6 对数线性分类
在二分类情况中,我们利用sigmoid函数把线性预测转变为一个概率估计,从而得到了一个对数线性模型。在多分类情况中是把分数通过一个softmax函数:
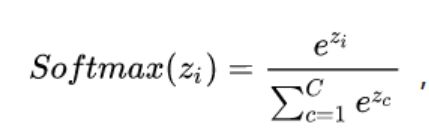
ŷ=softmax(xW+b),softmax函数强制ŷ中的值为正数,和为1,使得它们可以被认为是一个概率分布。
2.7 训练和最优化
算法的目的是返回一个正确地把输入实例与它们地期望标签对应起来地函数f(),即一个函数f()使得预测ŷ=f(x)在训练集上是正确的。因此,我们引入损失函数的概念,衡量当预测是ŷ而正确标签是y时遭受的损失。形式上,给定正确的y,损失函数L(y,ŷ)指派一个数值分数(标量)给预测输出ŷ。损失函数的最小值在预测正确取得。
学得的函数的参数(W,b)被设定成可以最小化训练集的损失的值。(通常是最小化不同样例上损失的总和)
具体地,给定一个已标注训练集(x 1:n,y 1:n)、单样例的损失函数和一个参数化函数f(x,θ),我们把关于参数θ的全局损失定义为所有训练样例上的平均损失:
L(θ)=1/nΣL(ŷ,y)
在这一观点下,参数的值决定损失大小。这时,训练算法的目的是设置参数值,使得L的值最小:
θ^=argminL(θ)=argmin[1/nΣL(ŷ,y)],这试图最小化在所有代价上的损失,可能会导致在训练集上过拟合。为了避免过拟合,我们经常对解决方案的形式加上软约束,同时我们想要函数值保持最小。通过想目标函数加入R,这个优化问题需要在低损失和低复杂度之间权衡:
θ^=min[1/nΣL(ŷ,y)+λR(θ)
函数R叫做正则项。损失函数和正则标准的不同组合会导致不同的学习算法,具体不同的归纳偏置。
2.7.1 损失函数
损失可以是把任何两个向量映射到一个标量的函数。为了最优化的实际目的,我们只考虑那些可以简单地计算梯度地函数。在大多数情况下,推荐使用常见的损失函数而不是自行定义。
hinge(二分类)
对于二分类问题,分类器的输出是单一的标量,预期的输出是{+1,-1}中的一个。分类规则是ŷ=sign(y’),如果y*y’>0,分类被认为是正确的,即y和y’是同号的。hinge损失也成为间隔损失或者支持向量机(SVM)损失,被定义为:L=(y’,y)=max(0,1-y’*y)
当y和y’是同号的并且|y|‘>=1时,损失为0.否则,损失与y’是成线性相关的。换句话说,二元hinge损失试图得到一个间隔至少是1的正确分类。其中,y是预测值(-1到1之间),y’为目标值(1或 -1)。其含义为,y的值在 -1到1之间即可,并不鼓励 |y|>1,即让某个样本能够正确分类就可以了,不鼓励分类器过度自信,当样本与分割线的距离超过1时并不会有任何奖励。目的在于使分类器更专注于整体的分类误差。
hinge(多分类)
hinge损失令ŷ=ŷ[1],…ŷ[n]为分类器的输出向量,y为正确输出类别的独热向量。
分类规则被定义为选择分数最高的那个类别:
predict=argmaxŷ[i]
令t=argmaxy[i]代表正确的类别,k=argmaxŷ[i]代表最高分数的类别,且t≠k。多分类hinge损失定义为:
L(y,ŷ)=max(0,1-(ŷ[t]-ŷ[k]))
多分类hinge损失试图使正确类别的得分比其他类别至少高出1。
二元交叉熵
二元交叉熵损失也叫logistic损失,被用于输出作为条件概率分布的二元分类中。假设两个被标注为0和1的目标类别,那么正确的标签是y∈{0,1},利用sigmoid函数将分类器的输出ŷ转换到[0,1]范围内,可以解释为条件概率ŷ=g(f(x))=P(Y=1|x)。预测的规则是0,ŷ<0.5
1, ŷ>0.5 网络被训练去最大化每一个训练样例(x,y)的对数条件概率P(y=1|x)。logistic损失被定义为L=(ŷ,y)=-[ylogŷ+(1-y)log(1-ŷ)],当我们想要网络产生针对一个二元分类问题的类别条件概率时,logistic损失是很有用的。当使用logistic损失时,假设输出层已经使用sigmoid函数转换过了。
分类交叉熵损失
当希望得分为概率时,使用分类交叉熵损失。当y=y[1],…y[n]为一个表示标签1…n上的正确的多项式分布向量,令ŷ=ŷ[1],…ŷ[n]为经过softmax函数转换的线性分类器的输出,代表类别条件分布ŷ[i]=P(y=i|x)。分类交叉熵损失度量正确标签分布y与预测标签分布ŷ之间的相异度,被定义为交叉熵:
L(ŷ,y)=-∑ y[i] log ŷ[i]。对于训练样例有且只有一个正确的类别这类严格的分类问题来说,y是一个代表正确类别的独热向量。在这种情况下,交叉熵可以被简化为:
L(y,ŷ)=-log (ŷ[i]), 其中,i为正确的类别指派,这试图指派概率质量给正确类别直到概率为1。由于得分经过softmax函数后变成非负的,和为1,则增加正确类别的概率意味着减少其他所有类别的概率。
交叉熵损失常见于对数线性模型和神经网络文献中,构造一个不仅仅可以预测最好的类别标签也可以预测一个可能类别的分布的多类分类器。使用交叉熵时,假设分类器输出经过softmax函数转换。
等级损失
在某些情况下,我们没有就标签而言的监督,只有一对正确项x和不正确项x’,我们的目的是给正确项打比不正确项高的分。这种训练情况出现在我们只有正例时,再通过破坏一个正例来产生负例。在这种情况下,一个有用的损失是基于间隔的等级损失,它是针对一组正确样例和错误样例而定义的:
L=(x,x’)=max( 0,1- ( f(x)-f(x’) ))
其中,f(x)是被分类器指派到输入向量x上的分数。目标是去给正确输入打分(分等级),使得分数比错误输入高至少一份的间隔。
一个常见的变形是使用等级损失的对数版本:
L=(x,x’)=log(1+exp [- ( f(x) -f(x’) ] ))
在语言任务中使用等级hinge损失的例子包括训练被用来产生预训练词嵌入的辅助任务,在该任务中给定了一个正确的单词序列和一个被破坏的单词序列,我们的目的是为正确的序列打分比错误序列更高的分。
2.7.2 正则化
考虑我们的语言识别的例子,有一种情形是训练集中有异常文档(记为x0):它是以德语书写的,却被标注为法语。为了降低损失,学习器会识别X0中的只出现在几个文档中的特征,赋予它们非常大的偏向(不正确)法语类别的权重。这时,其他出现这些特征的德语文档可能被错误的分类成法语,学习器将会发现其他的德语二元字母对,提高它们的权重从而将这些文档再一次的分类为德语。这不是一个好的学习方法,因为它学到了错误的知识,可能会造成与x0有许多相同单词的德语测试文档被错误的分类成法语。直觉的,我们可以通过驱使学习器远离有误导性的实例而偏向更自然的方案来控制这类情况,通过像优化目标中加入正则化R来完成以上的目的,这样做可以控制参数值的复杂性,避免过拟合情况的发生:
θ^=argmin L( θ ) + λ( θ )=argmin 1\n L(f(xi,θ),yi)+λR(θ)
正则化项根据参数值得出参数值的复杂度。然后,我们寻找既是低损失又是低复杂度的参数值。超参数λ被用来控制正则化的程度:与低损失相比是更想要简单的模型,反之亦然。基于开发集上的分类性能,λ的值被手动设置。
实际上,正则化器R等价于权重的大小,所以要尽量保证小的参数值。特别地,正则化器R度量了参数矩阵的范数,使学习器偏向具有低范数的解决方案。R的常用选择有L2范数,L1范数和弹性网络。
L2正则化 在L2正则化中,R取参数的L2范数的平方的形式,尽力保证参数值的平方和足够小:
R(W)=W1²+W2²+W3²…
注意到经过L2正则化的模型会因高的参数权值而受到及其严重的惩罚,但一旦参数值足够接近于0,L2正则化的作用几乎可以忽略不计。与把有相对低权重的10个参数的值都减少0.1相比,模型更偏向于把一个有高权重的参数的值减少1。
L1正则化 在L1正则化中,R取参数L1范数的形式,尽力保证参数值的绝对值和足够小:
R(W)=|W1|+|W2|+…
与L2正则器相比,L1正则器会因低参数值和高参数值而受到惩罚,会偏向于将所有的非零参数值减少到0。因此它会支持稀疏的答案——许多参数都是0的模型。L1正则器也叫做稀疏先验。
弹性网络 弹性网络正则器组合了L1正则和L2正则:
R(W)=λ1R l1 (W)+λ2R l2 (W)
Dropout 令一种在神经网络中非常有用的正则化方法是Dropout。
2.8 基于梯度的最优化
为了训练模型,解决优化问题,一种常用的方法是使用基于梯度的方法。大概来说,基于梯度的方法通过反复计算训练集上的损失L的估计和参数θ关于损失估计的梯度值,并将参数值向与梯度相反的方向调整。不同的最优化方法的区别在于如何对损失进行估计,如何定义向与梯度相反的方向调整参数值。我们先描述随机梯度下降(SGD)。
2.8.1 随机梯度下降(算法)
训练线性模型的一个有效方法是使用随机梯度下降算法或者它的变形。随机梯度下降是一个通用优化算法。它接收一个被θ参数化的函数f,一个损失函数L,以及期望的输入对x1:n,y1:n。然后算法尝试设定参数θ使得f在训练样例上的累积损失足够小。
输入:
函数f(x,θ)
由输入x1…xn以及期望输出y1…yn构成的训练集
损失函数L
1:while 不满足停止条件do
2:采样一个训练样本xi,yi
3:计算损失L(f(xi,θ),yi)
4:g^ <----L(f(xi,θ),yi)
5:θ<----θ-a *g^
算法的目的是设定参数θ以最小化训练集上的总体损失,算法的工作方式是反复随机抽取一个训练样本,计算这个样本的误差关于参数θ的梯度,假设输入和期望输出是固定的,损失被认为是一个关于参数θ的函数。然后,参数θ被与梯度相反的方向进行更新,比例系数为学习率a,学习率在训练过程中可以是不变的,也可以按照关于时间步t的函数衰减。
注意第3行计算的误差是基于一个训练样例的,因此仅仅是一个大概的对需要最小化的全局损失L的估计。损失计算中的噪音可能导致不准确的梯度。减少这种噪音的常见方法是在m个样例的抽样上估计误差和梯度。这引出了minibatch随机梯度下降算法。