使用springboot集成redis实现一个简单的热搜功能。
- 搜索栏展示当前登录的个人用户的搜索历史记录;
- 删除个人用户的搜索历史记录;
- 插入个人用户的搜索历史记录;
- 用户在搜索栏输入某字符,则将该字符记录下来以zset格式存储在redis中,记录该字符被搜索的个数;
- 当用户再次查询了已在redis存储了的字符时,则直接累加个数;
- 搜索相关最热的前十条数据;
实例
@Transactional
@Service("redisService")
public class RedisService {
@Resource
private StringRedisTemplate redisSearchTemplate;
/**
* 新增一条该userId用户在搜索栏的历史记录,searchKey代表输入的关键词
*
* @param userId
* @param searchKey
* @return
*/
public int addSearchHistoryByUserId(String userId, String searchKey) {
String searchHistoryKey = RedisKeyUtil.getSearchHistoryKey(userId);
boolean flag = redisSearchTemplate.hasKey(searchHistoryKey);
if (flag) {
Object hk = redisSearchTemplate.opsForHash().get(searchHistoryKey, searchKey);
if (hk != null) {
return 1;
} else {
redisSearchTemplate.opsForHash().put(searchHistoryKey, searchKey, "1");
}
} else {
redisSearchTemplate.opsForHash().put(searchHistoryKey, searchKey, "1");
}
return 1;
}
/**
* 删除个人历史数据
*
* @param userId
* @param searchKey
* @return
*/
public long delSearchHistoryByUserId(String userId, String searchKey) {
String searchHistoryKey = RedisKeyUtil.getSearchHistoryKey(userId);
return redisSearchTemplate.opsForHash().delete(searchHistoryKey, searchKey);
}
/**
* 获取个人历史数据列表
*
* @param userId
* @return
*/
public List getSearchHistoryByUserId(String userId) {
List history = new ArrayList<>();
String searchHistoryKey = RedisKeyUtil.getSearchHistoryKey(userId);
boolean flag = redisSearchTemplate.hasKey(searchHistoryKey);
if (flag) {
Cursor> cursor = redisSearchTemplate.opsForHash().scan(searchHistoryKey, ScanOptions.NONE);
while (cursor.hasNext()) {
Map.Entry map = cursor.next();
String key = map.getKey().toString();
history.add(key);
}
return history;
}
return null;
}
/**
* 新增一条热词搜索记录,将用户输入的热词存储下来
*
* @param searchKey
* @return
*/
public int addHot(String searchKey) {
Long now = System.currentTimeMillis();
ZSetOperations zSetOperations = redisSearchTemplate.opsForZSet();
ValueOperations valueOperations = redisSearchTemplate.opsForValue();
List title = new ArrayList<>();
title.add(searchKey);
for (int i = 0, length = title.size(); i < length; i++) {
String tle = title.get(i);
try {
if (zSetOperations.score("title", tle) <= 0) {
zSetOperations.add("title", tle, 0);
valueOperations.set(tle, String.valueOf(now));
}
} catch (Exception e) {
zSetOperations.add("title", tle, 0);
valueOperations.set(tle, String.valueOf(now));
}
}
return 1;
}
/**
* 根据searchKey搜索其相关最热的前十名 (如果searchKey为null空,则返回redis存储的前十最热词条)
*
* @param searchKey
* @return
*/
public List getHotList(String searchKey) {
String key = searchKey;
Long now = System.currentTimeMillis();
List result = new ArrayList<>();
ZSetOperations zSetOperations = redisSearchTemplate.opsForZSet();
ValueOperations valueOperations = redisSearchTemplate.opsForValue();
Set value = zSetOperations.reverseRangeByScore("title", 0, Double.MAX_VALUE);
//key不为空的时候 推荐相关的最热前十名
if (StringUtils.isNotEmpty(searchKey)) {
for (String val : value) {
if (StringUtils.containsIgnoreCase(val, key)) {
//只返回最热的前十名
if (result.size() > 9) {
break;
}
Long time = Long.valueOf(valueOperations.get(val));
if ((now - time) < 2592000000L) {
//返回最近一个月的数据
result.add(val);
} else {
//时间超过一个月没搜索就把这个词热度归0
zSetOperations.add("title", val, 0);
}
}
}
} else {
for (String val : value) {
if (result.size() > 9) {
//只返回最热的前十名
break;
}
Long time = Long.valueOf(valueOperations.get(val));
if ((now - time) < 2592000000L) {
//返回最近一个月的数据
result.add(val);
} else {
//时间超过一个月没搜索就把这个词热度归0
zSetOperations.add("title", val, 0);
}
}
}
return result;
}
/**
* 每次点击给相关词searchKey热度 +1
*
* @param searchKey
* @return
*/
public int incrementHot(String searchKey) {
String key = searchKey;
Long now = System.currentTimeMillis();
ZSetOperations zSetOperations = redisSearchTemplate.opsForZSet();
ValueOperations valueOperations = redisSearchTemplate.opsForValue();
zSetOperations.incrementScore("title", key, 1);
valueOperations.getAndSet(key, String.valueOf(now));
return 1;
}
}
在向redis添加搜索词汇时需要过滤不雅文字,合法时再去存储到redis中,下面是过滤不雅文字的过滤器。
public class SensitiveFilter {
/**
* 敏感词库
*/
private Map sensitiveWordMap = null;
/**
* 最小匹配规则
*/
public static int minMatchType = 1;
/**
* 最大匹配规则
*/
public static int maxMatchType = 2;
/**
* 单例
*/
private static SensitiveFilter instance = null;
/**
* 构造函数,初始化敏感词库
*
* @throws IOException
*/
private SensitiveFilter() throws IOException {
sensitiveWordMap = new SensitiveWordInit().initKeyWord();
}
/**
* 获取单例
*
* @return
* @throws IOException
*/
public static SensitiveFilter getInstance() throws IOException {
if (null == instance) {
instance = new SensitiveFilter();
}
return instance;
}
/**
* 获取文字中的敏感词
*
* @param txt
* @param matchType
* @return
*/
public Set getSensitiveWord(String txt, int matchType) {
Set sensitiveWordList = new HashSet<>();
for (int i = 0; i < txt.length(); i++) {
// 判断是否包含敏感字符
int length = checkSensitiveWord(txt, i, matchType);
// 存在,加入list中
if (length > 0) {
sensitiveWordList.add(txt.substring(i, i + length));
// 减1的原因,是因为for会自增
i = i + length - 1;
}
}
return sensitiveWordList;
}
/**
* 替换敏感字字符
*
* @param txt
* @param matchType
* @param replaceChar
* @return
*/
public String replaceSensitiveWord(String txt, int matchType, String replaceChar) {
String resultTxt = txt;
// 获取所有的敏感词
Set set = getSensitiveWord(txt, matchType);
Iterator iterator = set.iterator();
String word = null;
String replaceString = null;
while (iterator.hasNext()) {
word = iterator.next();
replaceString = getReplaceChars(replaceChar, word.length());
resultTxt = resultTxt.replaceAll(word, replaceString);
}
return resultTxt;
}
/**
* 获取替换字符串
*
* @param replaceChar
* @param length
* @return
*/
private String getReplaceChars(String replaceChar, int length) {
String resultReplace = replaceChar;
for (int i = 1; i < length; i++) {
resultReplace += replaceChar;
}
return resultReplace;
}
/**
* 检查文字中是否包含敏感字符,检查规则如下:
* 如果存在,则返回敏感词字符的长度,不存在返回0
*
* @param txt
* @param beginIndex
* @param matchType
* @return
*/
public int checkSensitiveWord(String txt, int beginIndex, int matchType) {
// 敏感词结束标识位:用于敏感词只有1位的情况
boolean flag = false;
// 匹配标识数默认为0
int matchFlag = 0;
Map nowMap = sensitiveWordMap;
for (int i = beginIndex; i < txt.length(); i++) {
char word = txt.charAt(i);
// 获取指定key
nowMap = (Map) nowMap.get(word);
// 存在,则判断是否为最后一个
if (nowMap != null) {
// 找到相应key,匹配标识+1
matchFlag++;
// 如果为最后一个匹配规则,结束循环,返回匹配标识数
if ("1".equals(nowMap.get("isEnd"))) {
// 结束标志位为true
flag = true;
// 最小规则,直接返回,最大规则还需继续查找
if (SensitiveFilter.minMatchType == matchType) {
break;
}
}
}
// 不存在,直接返回
else {
break;
}
}
if (SensitiveFilter.maxMatchType == matchType) {
//长度必须大于等于1,为词
if (matchFlag < 2 || !flag) {
matchFlag = 0;
}
}
if (SensitiveFilter.minMatchType == matchType) {
//长度必须大于等于1,为词
if (matchFlag < 2 && !flag) {
matchFlag = 0;
}
}
return matchFlag;
}
}
@Configuration
@SuppressWarnings({"rawtypes", "unchecked"})
public class SensitiveWordInit {
/**
* 字符编码
*/
private String ENCODING = "UTF-8";
/**
* 初始化敏感字库
*
* @return
* @throws IOException
*/
public Map initKeyWord() throws IOException {
// 读取敏感词库,存入Set中
Set wordSet = readSensitiveWordFile();
// 将敏感词库加入到HashMap中
return addSensitiveWordToHashMap(wordSet);
}
/**
* 读取敏感词库 ,存入HashMap中
*
* @return
* @throws IOException
*/
private Set readSensitiveWordFile() throws IOException {
Set wordSet = null;
ClassPathResource classPathResource = new ClassPathResource("static/sensitiveWord.txt");
InputStream inputStream = classPathResource.getInputStream();
// 敏感词库
try {
// 读取文件输入流
InputStreamReader read = new InputStreamReader(inputStream, ENCODING);
// 文件是否是文件 和 是否存在
wordSet = new HashSet<>();
// BufferedReader是包装类,先把字符读到缓存里,到缓存满了,再读入内存,提高了读的效率。
BufferedReader br = new BufferedReader(read);
String txt = null;
// 读取文件,将文件内容放入到set中
while ((txt = br.readLine()) != null) {
wordSet.add(txt);
}
br.close();
// 关闭文件流
read.close();
} catch (Exception e) {
e.printStackTrace();
}
return wordSet;
}
/**
* 将HashSet中的敏感词,存入HashMap中
*
* @param wordSet
* @return
*/
private Map addSensitiveWordToHashMap(Set wordSet) {
// 初始化敏感词容器,减少扩容操作
Map wordMap = new HashMap(wordSet.size());
for (String word : wordSet) {
Map nowMap = wordMap;
for (int i = 0; i < word.length(); i++) {
// 转换成char型
char keyChar = word.charAt(i);
// 获取
Object tempMap = nowMap.get(keyChar);
// 如果存在该key,直接赋值
if (tempMap != null) {
nowMap = (Map) tempMap;
}
// 不存在则,则构建一个map,同时将isEnd设置为0,因为他不是最后一个
else {
// 设置标志位
Map newMap = new HashMap<>();
newMap.put("isEnd", "0");
// 添加到集合
nowMap.put(keyChar, newMap);
nowMap = newMap;
}
// 最后一个
if (i == word.length() - 1) {
nowMap.put("isEnd", "1");
}
}
}
return wordMap;
}
}
其中用到的sensitiveWord.txt文件在resources目录下的static目录中,这个文件是不雅文字大全,需要与时俱进,不断进步的。
测试
@GetMapping("/add")
public Object add() {
int num = redisService.addSearchHistoryByUserId("001", "hello");
return num;
}
@GetMapping("/delete")
public Object delete() {
long num = redisService.delSearchHistoryByUserId("001", "hello");
return num;
}
@GetMapping("/get")
public Object get() {
List history = redisService.getSearchHistoryByUserId("001");
return history;
}
@GetMapping("/incrementHot")
public Object incrementHot() {
int num = redisService.addHot("母亲节礼物");
return num;
}
@GetMapping("/getHotList")
public Object getHotList() {
List hotList = redisService.getHotList("母亲节礼物");
return hotList;
}
@GetMapping("/incrementScore")
public Object incrementScore() {
int num = redisService.incrementHot("母亲节礼物");
return num;
}
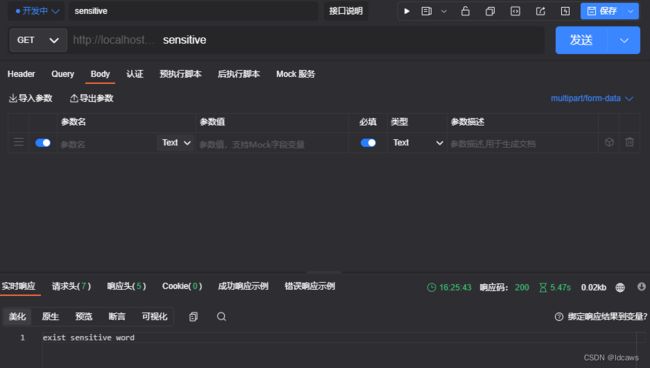
@GetMapping("/sensitive")
public Object sensitive() throws IOException {
//非法敏感词汇判断
SensitiveFilter filter = SensitiveFilter.getInstance();
int n = filter.checkSensitiveWord("hello", 0, 1);
if (n > 0) {
//存在非法字符
System.out.printf("这个人输入了非法字符--> %s,不知道他到底要查什么~ userid--> %s","hello","001");
return "exist sensitive word";
}
return "ok";
}
到此这篇关于springboot+redis实现热搜的文章就介绍到这了,更多相关springboot redis热搜内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!