ATSS论文阅读笔记
论文题目是Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection,翻译过来就是通过自适应训练样本选择来弥合基于锚和无锚检测的差距。(弥合这个词是翻译来的,还挺不错的)
摘要
论文的摘要部分作者主要提出了两点。作者首先指出了基于锚和无锚检测之间存在表现差异的一个重要原因是因为这两种方法定义正负样本的方式不同,并且作者拿RetinaNet和FCOS做了实验,如果RetinaNet使用和FCOS一样的trick(Group Normalization、GIoU Loss等),获得了几乎和FCOS一样的mAP(Fcos为37.8,RetinaNet为37.0),可以看到其中还是有0.8%的差距,于是作者之后又根据这0.8%的差距进行对比实验,最终确定这0.8%的差距是因为两种方法定义正负样本的方式不同造成的;第二点作者就提出了ATSS(Adaptive Training Sample Selection ),最终在MSCOCO数据集上获得了50.7%的map。
第一节:介绍
正文第一节作者首先介绍了一下anchor-based的一阶检测器和二阶检测器的特点以及表示目前常见检测基准的最好结果仍然由基于锚的检测器所保持;随后作者提到近些年由于FPN和Focal loss的提出,许多研究开始投入Anchor-free方向,并介绍了keypoint-based methods和center-based methods,这两种方法获得了和anchor-based相近的表现,并且由于去除了锚框的影响使得模型在泛化能力上有着更强大的潜力。之后作者拿anchor-based的RetinaNet和与anchor-based较为相似的anchor-free算法FCOS进行了对比,总结出了3点不同:
(1)每个位置的锚框数量不同。RetinaNet每个位置有好几个锚框,而FCOS只有一个锚点;
(2)正负样本的定义方式不一样。RetinaNet通过IOU而FCOS通过点与gt框的四条边的距离来确定正负样本
(3)回归开始状态不同。 RetinaNet 从预设的锚框回归对象边界框,而 FCOS 从锚点定位对象。
因此作者就这三个差异中的哪一个是性能差距的重要因素展开了研究。
第二节:相关工作
在这一部分作者主要总结了目前的two-stage和one-stage的anchor-based的代表性算法和原理,以及keypoint-based和center-based的anchor-free的算法原理,具体的就不作赘述了,感兴趣的朋友可以自行去阅读原文(https://arxiv.org/pdf/1912.02424.pdf)。
第三节:Anchor-based和Anchor-free检测的差异分析
3-1 实验设置
数据集。所有的实验都是在MS COCO数据集上进行的,并且trainval35K split中的115K张图像用于训练,minival split中的35k张图像用于验证,最后还将主要结果提交给了评估服务器以测试最终的性能。
训练细节。作者训练时使用具有 5 级特征金字塔结构的 ImageNet预训练 ResNet-50作为主干。新添加的层以相同的方式初始化。对于 RetinaNet,5 级特征金字塔中的每一层都与一个 8S 尺度的方形锚点相关联,其中 S 是总步幅大小。 在训练期间,我们调整输入图像的大小,使其短边为 800,长边小于或等于 1, 333。整个网络使用随机梯度下降进行训练算法进行 90K 次迭代,0.9 动量,0.0001 权重衰减和 16 批次大小。初始学习率设置为0.01,并且在迭代次数为60k和80k时分别衰减0.1.
推理细节。在推理阶段,作者用与训练阶段相同的方式调整输入图像的大小,然后将其输入到整个网络得到具有预测类别的预测边界框。之后,使用预设的分数 0.05 过滤掉大量的背景边界框,然后输出前 1000 个检测每个特征金字塔。 最后,使用非极大值抑制 (NMS), 每类图像设置 0.6 的 IoU 阈值,以生成每个图像的最终前 100 个置信检测。
3-2 去除不一致
在这一小节,作者对比了RetinaNet和FCOS的区别,为了保持对比的公平,将FCOS使用的tricks一一用在RetinaNet上来进行试验,结果如下表:
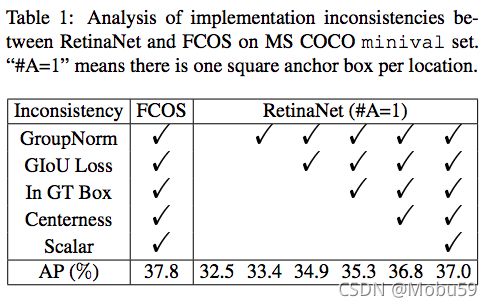
可以看到,尽管将FCOS所用的tricks都加在了RetinaNet上,Retinanet的ap也只有37.0,而FCOS能达到37.8.
3-3 重要的不同之处
通过3.2所做的工作,现在只有两个不同之处了:1是定义正负样本的方式不同;2是回归的起点不同(从框回归还是从点回归)。
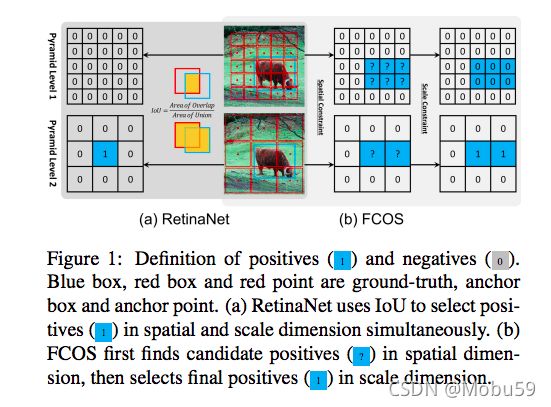
如上图所示,RetinaNet使用IOU作为评判,通过回归矩形框的2个角点偏置进行框位置和大小的预测,而FCOS是基于中心点预测四条边和中心点的距离进行预测框位置和大小的预测。
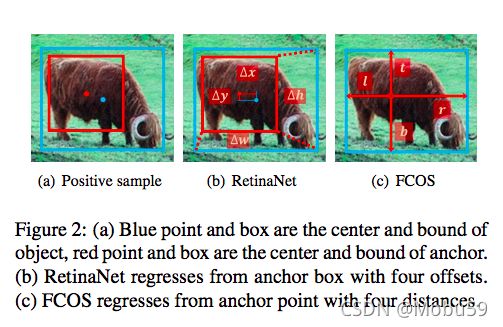
注:图中蓝色框和点表示GT,红色框表示RetinaNet的正样本,红色点表示FCOS的正样本。

这是作者根据上面提到的两点不同之处所做的实验。这个表可以这样看,按行来看的话,表示FCOS和RetinaNet都使用IOU(或者都使用空间和尺度约束)来作为正负样本选择的方式而回归的方式不一样,可以看到两者的AP值几乎相同;按列来看,表示FCOS和RetinaNet使用的正负样本选择的方式不一样,而回归的方式一样,这时候产生了0.8左右的AP差,正好和前文提到的一致。因此可以得出结论,产生差异的原因主要是正负样本选择的方式不一样。
第四节 ATSS

ATSS的步骤主要如下:
第2行之所以选择离gt的中心点最近的中心是因为这里对比了FCOS和RetinaNet的选择方式,因为FCOS使用的中心点距离,并且获得了更高的mAP值。第3到6行是根据anchor和GT的中心点距离选出候选正样本,每层K个;第7行是计算IoU;第8行到第15行是先计算IoU的均值和标准差从而得到阈值,然后根据阈值进行正负样本确定。
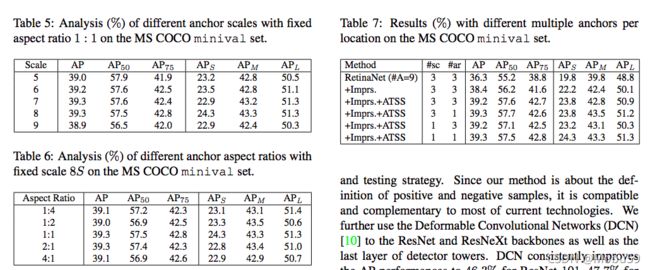
到了这里,文章的核心内容基本就结束了,之后就是应用了ATSS之后模型的一些提升以及作者跟目前的一些state-of-art的模型效果对比。下面贴上结果图:
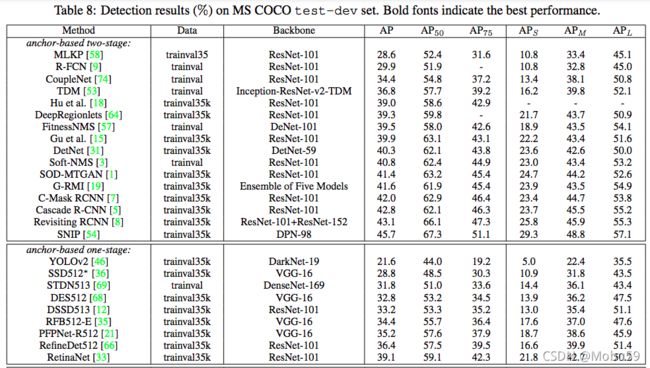
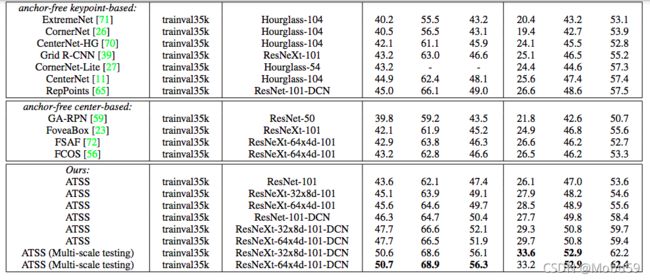 第五节 总结
第五节 总结
论文主要就是提出了Anchor-based和Anchor-free表现有差距的一个重要原因就是正负样本的选择方式不一样,并且提出了ATSS,一种自适应的训练样本选择方法,提高了模型的效果,其中有很多地方都是值得我们借鉴和思考的,并且ATSS也是一种很实用的方法,比如之后的Nanodet就用到了ATSS。