一场国际赛事“悬赏”50万美元,向假视频宣战丨独家公开课实录(5)

近年来,AI 安全问题愈加受到行业关注。尽管人工智能技术取得长足进步,人工智能算法的安全性仍存在严重不足,甚至可以对视频进行技术处理达到换脸的目的。在对抗样本防御的过程中还有一类很相似的任务——DeepFake 识别。
有数据统计,仅仅2019年到2020年期间,Deepfake视频数量增长了就达到大概6820倍,从14678个视频增长到1亿个视频。
显然,这项曾负面缠身、让美国DARPA都为止头痛的"黑科技",已经大举入侵主流互联网平台。
近日,biendata 平台邀请科大讯飞金牌讲师阿水,共同打造一门针对人脸识别的 AI 对抗攻防系列课程,主题囊括对抗样本介绍、人脸识别对抗样本、对抗防御、视频人脸检测与对抗防御等。
除对抗攻防的知识讲解外,课程还设有实战项目演练:以时下两个热门的 AI 对抗主题的竞赛为案例,详细讲解赛题及 baseline 模型代码,让参与学习的同学能够学以致用,快速上手实战。过往公开课实录如下:
第一讲:
Biendata,公众号:数据实战派
它为什么是人脸识别中的 “不定时炸弹”?丨独家公开课实录
第二讲:
Biendata,公众号:数据实战派
60万元奖金 “人脸攻防战”,怎么打?丨独家公开课实录(附baseline)
第三讲:
biendata,公众号:数据实战派
60万奖金“人脸攻防大战”,全部进阶妙招奉上丨独家公开课实录(3)
第四讲:
Biendata,公众号:数据实战派
防住CV中这颗“不定时炸弹”,有哪些捷径?丨独家公开课实录(4)
本文为第五讲课程演讲实录整理,主要为对抗防御的方法及图像、视频和音频的对抗防御思路和 Trusted Media Challenge 比赛(目前正在进行中)的 baseline 讲解。
为了解决虚假媒体内容对社会和个人产生的负面影响,AI Singapore组织了Trusted Media Challenge 大赛。这项挑战赛的目标是探索如何利用人工智能技术打击虚假媒体。比赛侧重于检测视听虚假媒体,其中视频和音频都可能已被篡改。比赛数据集由AI Singapore提供,给定一组原始视频,参与者需构建模型并返回原始视频是虚假视频的概率数值。
本次比赛对来自学术界和工业界的全球参与者开放。获胜者将有机会赢得高达 700,000 新加坡元(约 500,000 美元)的奖金,奖金包括现金奖励和创业补助金。

比赛地址:
https://trustedmedia.aisingapore.org/?source=biendata_banner
点击文末“阅读原文”可获取公开课视频,“数据实战派”后台按指示获取 ppt。
加入课程及竞赛讨论群可添加小助手。

第五讲分享大纲:

一、Fake Video 介绍与产生思路
首先针对 Fake Video 介绍和产生思路进行讲解。其次介绍一下 Trusted Media Challenge 比赛和它的解题思路。最后系统讲解这个比赛的代码实践。
其实,对抗人脸对抗攻防整体的思路上很简单,本质上可以当做二分类进行处理:
随着深度学习的技术的不断发展,有很多伪造的图像视频以及相关的音频媒介不断出现。从 2018 年开始就有很多成熟的换脸应用了。如下图所示,右侧的图片就是给原始图像换了一张脸。
这个应用不仅仅可以换图片,也可以给定原始图片及目标的人脸,将目标人脸的脸型及细节贴到原始图片上面,尽可能保留五官的自然性和真实性。
于是,利用深度学习,特别是对抗神经网络的一些技术,能够生成虚假的人脸图像或视频。

具体在合成的过程中,需要考虑得到人脸表情的变化。因为要考虑在变化过程中像素是否足够平滑以及是否合理,所以视频 DeepFake 生成的难度会更大一些。
其次,视频包含了非常关键的音频信息。在合成虚假的人脸视频时,还需要考虑到音频与人的嘴型及整体的脸型是否相符合。
在虚假的人脸视频中,如果嘴巴的变化趋势与音频发出的声音不相匹配的话,很直接就可以识别出来。
二、Trusted Media Challenge 赛题介绍
本文介绍的Trusted Media Challenge比赛非常有意思,目前正在进行中。
比赛任务是给定了原始的视频和虚假的视频,参赛者必须在比赛的过程中构建分类模型,识别出给定视频是虚假视频的概率。

比赛的赛程是分为两个阶段,第一阶段在 2021 年 7 月 15 号开始,到 2021 年 11 月 15 号;第二阶段是在 2021 年 11 月 16 号到 2021 年 12 月 14 号,用 AUC 来进行评价。
比赛的数据大部分都是基于亚洲的人脸的视频数据进行合成的,且大部分都是带有音频的。因此,比赛的数据集中虚假的视频分为以下四类:
第一类是人的脸和声音都是被操纵的。
第二类是只有人的脸是被操纵的。
第三类是说话人的声音是被操纵的。
第四类是嘴唇动作和音频的内容是一致的。
比赛的标注只给出了这个视频是否为虚假视频,但是并没有给出是哪一种类型的。
比赛的视频在数据传输的过程中,有可能会出现压缩视频丢失的情况。因此,视频存在一定的质量问题也是很正常的。

那么,解题思路就是将比赛视为虚假人脸的检测的比赛,只需要做虚假人脸识别的任务即可。
虚假人脸识别的本质是完成二分类任务。
首先进行人脸的检测。在检测出人脸后,再将人脸对应的区域送到深度学习的神经网络里,完成类别的划分。类别划分的本质就是二分类的操作。
比赛的难点在于能给定的数据是视频类型的,且虚假视频的类型较多。
数据集包含了多模态。模态就是不同类型的数据,数据模态至少包含音频、视频。在解决问题时,可以把模态分开解决,分开来进行建模。
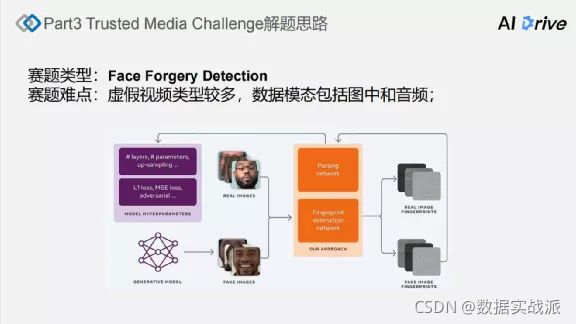
比赛的关键点就是如何识别出这些虚假的视频。
解题思路主要基于三类方法:
第一类基于单帧的图片。可以将视频提取出关键帧,再做人脸检测,构建二分类模型。这种方法也是最容易实现的。
第二类对于视频片段进行识别。将视频帧或整体的视频片段保留下来,构建视频的二分类模型。
第三类是从语音的角度提取音频,提取MFCC等音频特征,然后进行二分类。
三、Trusted Media Challenge 解题思路

代码实践
完整课程视频、讲义及模型代码见链接:
https://pan.baidu.com/s/1RiDqT20qaF_Gx7IKNHAJ9A
提取码:lkps
- 提取关键帧
# 抽取关键帧\n,
def extract_keyframe(path):\n,
query_id = path.split('/')[-1][:-4]\n,
\n,if not os.path.exists('./train_frame/'+query_id):\n,
os.mkdir('./train_frame/'+query_id)
\n,else:\n,return\n,
\n,# 命令行的工具\n,command = ['ffmpeg', '-i', path,\n,'-vf',
'\select=eq(pict_type\\,I)\',
\n,' -vsync', 'vfr', '-qscale:v',
'2',\n,'-f', 'image2', \n,'./train_frame/{0}/{0}_%05d.jpg'.format(query_id)]\n,
# 抽取关键帧\n,
os.system(' '.join(command))
人脸检测import cv2\n,
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')\n,
\n,
img = cv2.imread('./train_frame/0003a634b24a4854/0003a634b24a4854_00001.jpg', 0)\n,
faces = face_cascade.detectMultiScale(img, 1.1, 4)\n,
\n,
for (x, y, w, h) in faces:\n,
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)\n,
\n,
# 假如视频包含多个主体,关键点
- 关键帧检测到的人脸存储
# 提取关键帧人脸图片\n,
def extract_face(path):\n,
\n,
query_id = path.split('/')[-2]\n,
\n,
if not os.path.exists('./train_face/'+query_id):\n,
os.mkdir('./train_face/'+query_id)\n,
\n,
img = Image.open(path)\n,
\n,
faces = mtcnn.detect(img)[0]\n,
\n,
if faces is None:\n,
return\n,
\n,
if len(faces) > 1:\n,
faces = np.array(faces)\n,
face_idx = np.argmax((faces[:, 2]-faces[:, 0]) * (faces[:, 3]-faces[:, 1]))\n,
(x, y, w, h) = faces[face_idx]\n,
elif len(faces) == 1:\n,
(x, y, w, h) = faces[0]\n,
\n,
try:\n,
img = cv2.imread(path)\n,
cv2.imwrite('./train_face/{0}/{1}'.format(query_id, path.split('/')[-1]), \n,
img[int(y):int(h), int(x):int(w)])\n,
except Exception as err:\n,
print(err)\n,
pass
- 关键帧人脸二分类
train_df = pd.read_csv('train.csv')\n,
train_df.index = train_df['filename'].apply(lambda x: x[:-4])\n,
train_dfimport os, sys, codecs, glob\n,
from PIL import Image, ImageDraw\n,
\n,
import numpy as np\n,
import pandas as pd\n,
import cv2\n,
\n,
import torch\n,
torch.backends.cudnn.benchmark = False\n,
# torch.backends.cudnn.enabled = False\n,
\n,
import torchvision.models as models\n,
import torchvision.transforms as transforms\n,
import torchvision.datasets as datasets\n,
import torch.nn as nn\n,
import torch.nn.functional as F\n,
import torch.optim as optim\n,
from torch.autograd import Variable\n,
from torch.utils.data.dataset
import Datasetclass TMCDataset(Dataset):\n,
def __init__(self, img_path, transform):\n,
self.img_path = img_path\n,
self.transform = transform\n,
\n,
def __getitem__(self, index):\n,
img = Image.open(self.img_path[index]).convert('RGB')\n,
\n,
if self.transform is not None:\n,
img = self.transform(img)\n,
\n,
return img,
train_df.loc[self.img_path[index].split('/')[-2]]['label']\n,
\n,
def __len__(self):\n,
return len(self.img_path) train_face,
val_face = glob.glob('./train_face/*/*')[:-200],
glob.glob('./train_face/*/*')[-200:]\n,
\n,
train_loader = torch.utils.data.DataLoader(\n,
TMCDataset(train_face,
\n,
transforms.Compose([\n,
transforms.Resize((300, 300)),\n,
\n,
# 数据扩增方法:
\n,
transforms.RandomHorizontalFlip(),\n,
transforms.RandomVerticalFlip(),\n,
transforms.ToTensor(),\n,
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])\n, ])\n,),\n,
batch_size=10, shuffle=True, num_workers=5,\n,)\n,\n,
val_loader = torch.utils.data.DataLoader(\n,
TMCDataset(val_face,\n,
transforms.Compose([\n,
transforms.Resize((300, 300)),\n,
transforms.ToTensor(),\n,
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])\n,])\n,),\n,
batch_size=10, shuffle=False, num_workers=5,
\n,)