综述论文阅读”A comprehensive survey on graph neural networks“(TNNLS2020)
论文标题
A comprehensive survey on graph neural networks
论文作者、链接
作者:Wu, Zonghan and Pan, Shirui and Chen, Fengwen and Long, Guodong and Zhang, Chengqi and Philip, S Yu
链接:A Comprehensive Survey on Graph Neural Networks | IEEE Journals & Magazine | IEEE Xplore
Introduction
逻辑
神经网络在众多任务中取得了成功(部分归功于算力的增加:GPU,可用数据数量的增加以及深度学习可用高效的提取欧式数据的潜在特征)——深度学习可用有效捕捉欧式数据的特征,但是也出现了很多需要使用图谱数据的应用场景(推荐算法,分子结构,引文网络)——图谱数据的处理难点在于:结构的不确定性,结点的无序性,结点可能有不同的邻居结点(这些特性导致一些重要的操作,比如卷积,难以应用到图谱数据上)——现有的算法的一个基本假设是每一个实例都是相互独立的,但是在图谱中是不成立的,因为图谱中每一个结点都与其他结点相连,并且链接关系也有很多种
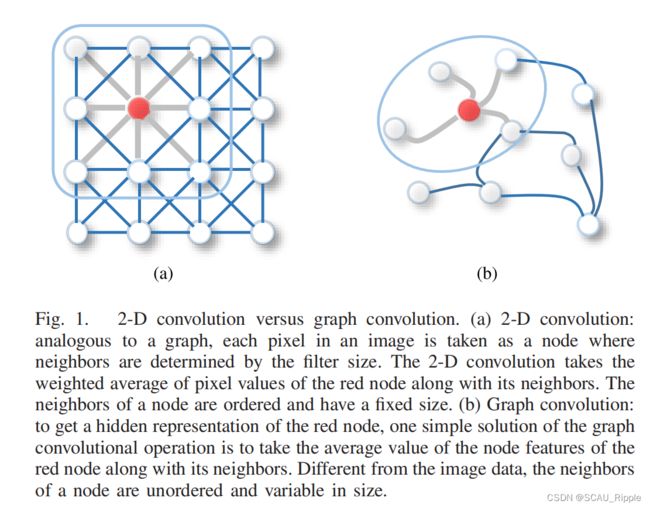
图卷积与2-D卷积的对比(见图1)——其他人对GNN的总结不全面
本文主要贡献
新的分类方式:分成4类:(1)循环图神经网络recurrent GNNs (RecGNN),(2)卷积图神经网络convolutional GNNs (ConvGNNs),(3)图自编码器graph autoencoders (GAEs),(4)空间-时间图神经网络spatial–temporal GNNs (STGNNs)
全面的总结
丰富的GNN资源:GNN模型,benchmark数据集,代码,实际应用
未来的发展方向
背景
图神经网络简史
Sperduti and Starita首先将神经网络应用到无环图中(属于循环图神经网络一类,它们通过迭代的方式传播邻居信息来学习目标节点的表示,直到到达一个稳定的不动点,但是这种方法计算消耗比较大)——重新设计了针对图的卷积操作(属于卷积图神经网络一类,该类分为两个主流:基于图谱的方法以及基于空间的方法)
图神经网络与网络嵌入
网络嵌入:将网络的结点表示为低维度向量表示,同时保存网络的拓扑结构和结点的特征信息。
图神经网络(GNN):是一种端到端式的聚焦于图相关任务的深度学习模型。大多数GNN都是显式地提取高维特征。
这两者的主要区别:GNN是一组神经网络模型,是针对不同的任务设计的,而网络嵌入则涵盖了针对同一任务的多种方法。
因此,GNN可以通过GAE框架解决网络嵌入问题。另一方面,网络嵌入包含其他非深度学习方法,如矩阵分解和随机游走。
图神经网络与图核(graph kernel)方法
图核方法历来是解决图分类问题的主要技术。这些方法是利用一个核函数去衡量图谱对之间的距离,比如:支持向量机。与GNN相似,图核方法可以将图谱或者是结点通过映射函数嵌入到向量空间,而区别在于,不同的是这个映射函数是确定性的而不是可学习的。图核方法由于是两两相似度计算,计算瓶颈明显。一方面,GNN基于提取的图谱表示直接进行图分类,因此比图核方法效率高得多。
标识符定义
与其他文章相似,本文使用加粗的大写字母表示矩阵,加粗的小写字母表示向量。如表一所示:

定义1(图谱)
一个图表示为 ,其中
,其中 是是vertices顶点或者nodes节点的集合,
是是vertices顶点或者nodes节点的集合, 是边的集合。
是边的集合。![]() 代表一个结点,然后
代表一个结点,然后![]() 代表由
代表由 指向
指向 的边。结点
的边。结点 的邻居结点的定义为
的邻居结点的定义为![]() 。邻接矩阵
。邻接矩阵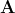 是一个
是一个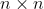 的矩阵,其中如果
的矩阵,其中如果![]() 那么
那么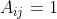 ,否则
,否则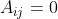 。一个图可能有结点特征
。一个图可能有结点特征 ,其中
,其中![]() 是结点特征矩阵,
是结点特征矩阵,![]() 代表结点的特征向量。一个图谱也可能有边特征
代表结点的特征向量。一个图谱也可能有边特征![]() ,其中
,其中![]() 是边特征矩阵,矩阵中的元素
是边特征矩阵,矩阵中的元素![]() 代表边
代表边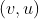 的特征向量。
的特征向量。
定义2(有向图)
有向图是所有边都有向的图,从一个节点指向另一个节点。当两个节点连通时,无向图被认为是有向图的一种特殊情况,即存在一对方向相反的边。无向图的邻接矩阵是对称的。
定义3(时空图)
时空图是结点特征根据时间动态变化的。时空图的定义为:![]()
GNN的分类和模型框架
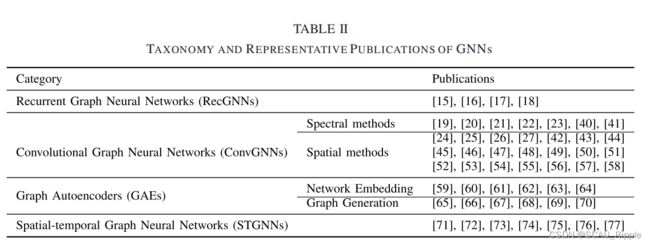
图神经网络分类
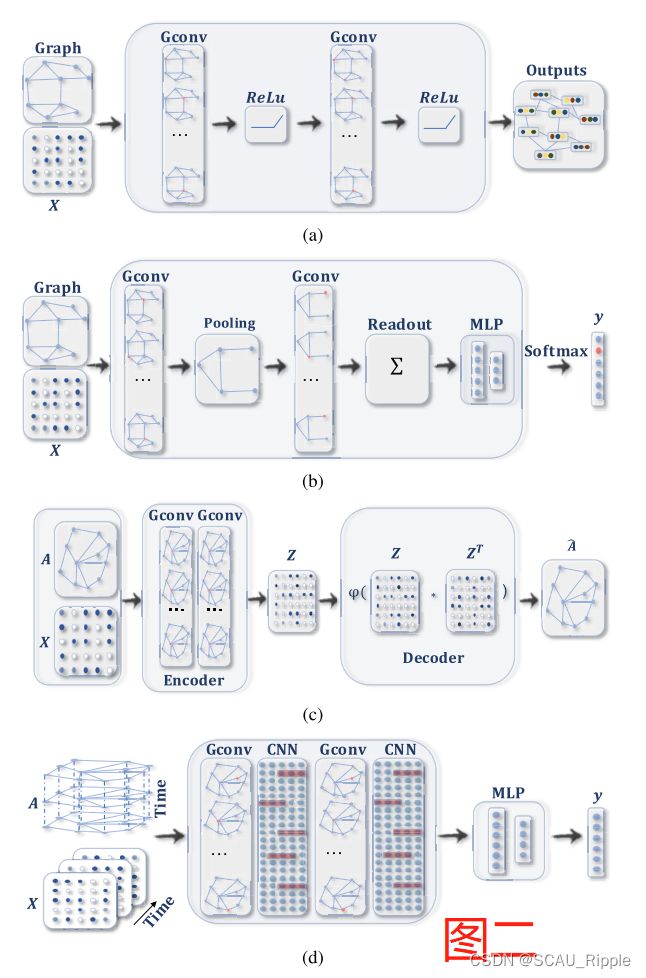
(1)循环图神经网络(RecGNN)
这些大多是GNN的先驱之作。RecGNNs往往通过循环神经结构学习结点特征表示。它们假设图中的一个节点不断地与它的邻居交换信息/消息,直到达到一个稳定的平衡。
(2)卷积图神经网络(ConvGNN)
这些方法将运算从网格数据推广到图谱数据。主要构思是通过将该本结点特征![]() 和邻居结点的特征
和邻居结点的特征![]() 聚合生成一个结点的特征表示,其中
聚合生成一个结点的特征表示,其中![]() 。与RecGNN不同的是,ConvGNN通过叠加多个图卷积层来提取高维节点特征表示。图二(a)和(b)分别展示了一个针对结点分类的ConvGNN和针对图谱分类的ConvGNN。
。与RecGNN不同的是,ConvGNN通过叠加多个图卷积层来提取高维节点特征表示。图二(a)和(b)分别展示了一个针对结点分类的ConvGNN和针对图谱分类的ConvGNN。
(3)图自编码器(Graph Autoencoder)
这些是无监督学习框架,将节点/图谱编码到一个潜在的向量空间,并从编码信息重建图数据。GAEs用于学习网络嵌入和图生成分布。对于网络嵌入,GAEs通过重构图结构学习潜在结点表达。对于图生成,一些方法是一步步生成结点和边,另一些方法是一次性生成一整个图。图二(c)展示了网络嵌入的GAE。
(4)时空图神经网络(Spatial–Temporal Graph Neural Networks)
这些是为了从时间-空间图中学习潜在模式。主要思想是同时考虑空间依赖性和时间依赖性。现有的方法主要利用图卷积来捕捉时间依赖性,利用RNN或者CNN模型捕捉空间依赖性。图二(d)展示了一个时空图神经网络的预测模型。
图神经网络框架
根据不同的下游任务分类
(1)节点级:输出与节点回归和节点分类任务有关。RecGNN和ConvGNN可以通过信息传播/图卷积提取高维结点特征表示。通过多层感知机和softmax层,可以在端到端的模型中完成节点级任务。
(2)边级:输出与边分类和边预测任务有关。以来自GNN的两个节点的隐藏表示为输入,利用相似函数或神经网络来预测边缘的标签/连接强度。
(3)图级:输出与图分类网络有关。为了在图级上获得紧凑的表示,GNN通常与pooling和readout操作结合使用。
根据训练模式分类
(1)针对结点级分类的半监督学习:给定一个部分节点被标记而其他节点未标记的网络,ConvGNN可以学习到一个有效识别未标记节点类标签的鲁棒模型。为此,可以通过叠加一对图卷积层和一个用于多类分类的softmax层来构建端到端学习框架。
(2)针对图级分类的有监督学习:图级分类的目标是预测一整个图的类别标签。用图卷积层来提取高维特征,图池化层做下采样,readout层将每个图的节点表示合并为一个图表示。通样可以添加MLP和softmax来构建端到端的学习模型。如图二(b)所示。
(3)针对图嵌入的无监督学习:这些算法用两种方法探究边级的信息。一种简单的方法是利用一个自编码器,其中编码器使用图卷积将图谱嵌入到潜在特征空间中,解码器负责将图结构重构出来。另一种流行的方法是利用负采样方法,将部分节点对采样为负对,而图中存在链接的节点对为正对。最后用一个逻辑归回层来区别正负样本对。
循环图神经网络(RecGNN)
它们在图中的节点上反复应用同一组参数,以提取高维节点表示。受限于算力,早期算法往往只考虑无环图。
GNN*(此GNN非指图神经网络,而是指这一个特定的算法)是一个早期可以应对多重图谱的算法,包括:无环、有环、有向和无向图。基于信息腐蚀机制,GNN*根据循环交换邻居信息来更新结点状态直到达到一个平衡状态。一个结点的隐藏状态由以下公式循环更新:
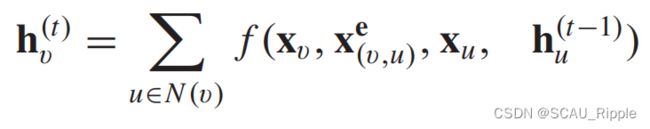
其中 表示含参函数,
表示含参函数,![]() 是随机初始化的。求和操作使GNN*适用于所有节点(即使邻居的数量不同,且不知道邻居的顺序)。为了保证收敛性,递归函数必须是一个收缩映射,将两点投影到一个潜在空间后,收缩两点之间的距离。当f(·)为神经网络的情况下,必须对参数雅可比矩阵施加惩罚项。当满足收敛条件时,最后一步节点隐藏状态被转发到readout层。GNN*交替进行节点状态传播阶和参数梯度计算阶段来最小化训练目标(这使得GNN*可以应对无环图)。
是随机初始化的。求和操作使GNN*适用于所有节点(即使邻居的数量不同,且不知道邻居的顺序)。为了保证收敛性,递归函数必须是一个收缩映射,将两点投影到一个潜在空间后,收缩两点之间的距离。当f(·)为神经网络的情况下,必须对参数雅可比矩阵施加惩罚项。当满足收敛条件时,最后一步节点隐藏状态被转发到readout层。GNN*交替进行节点状态传播阶和参数梯度计算阶段来最小化训练目标(这使得GNN*可以应对无环图)。
graph echo state network (GraphESN):对递归状态网络进行了扩展,以提高GNN*的训练效率。由一个编码器和一个输出层构成。编码器是随机初始化的不需要训练。它实现了一个收缩状态转换函数,不断更新节点状态,直到全局图状态收敛。然后以固定的节点特征作为输入,对输出层进行训练。
Gated GNN (GGNN):采用门控递归单元(GRU)作为递归函数,将递归减少到固定的步骤数。优点是不需要固定参数来保证收敛。一个结点的隐藏状态,是由前一个结点隐藏状态和邻居结点的隐藏状态决定,如下公式:
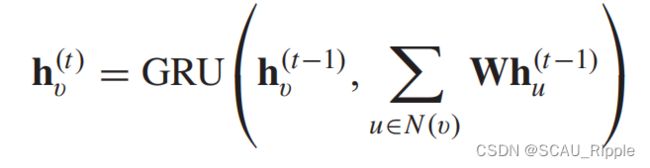
其中![]() 。GGNN采用时间反向传播(backpropagation through time, BPTT)算法学习模型参数。面对大型图时会出现问题,因为要对所有的结点计算循环函数。
。GGNN采用时间反向传播(backpropagation through time, BPTT)算法学习模型参数。面对大型图时会出现问题,因为要对所有的结点计算循环函数。
Stochastic steady-state embedding(SSE):提出了一种可扩展到大型图的学习算法。SSE以随机和异步的方式周期性更新节点隐藏状态。它交替采样一批节点用于状态更新和一批节点用于梯度计算。为了保持稳定性,将SSE的递归函数定义为历史状态和新状态的加权平均,其形式为
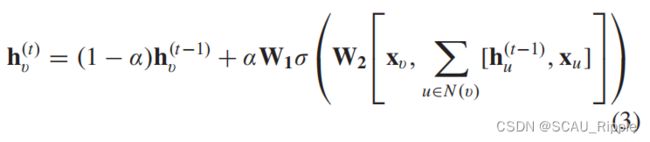
其中 是超参,
是超参, ![]() 是随机初始化的。SSE虽然在概念上很重要,但在理论上并不能证明反复应用公式(3)会使节点状态逐渐收敛到稳定点。
是随机初始化的。SSE虽然在概念上很重要,但在理论上并不能证明反复应用公式(3)会使节点状态逐渐收敛到稳定点。
卷积图神经网络ConvGNN
ConvGNN与RecGNN相关。与使用收缩约束迭代节点状态不同,convgnn在体系结构上使用固定数量的层,每层具有不同的权值来解决循环相互依赖问题。这个关键想法在图三中展示,如下
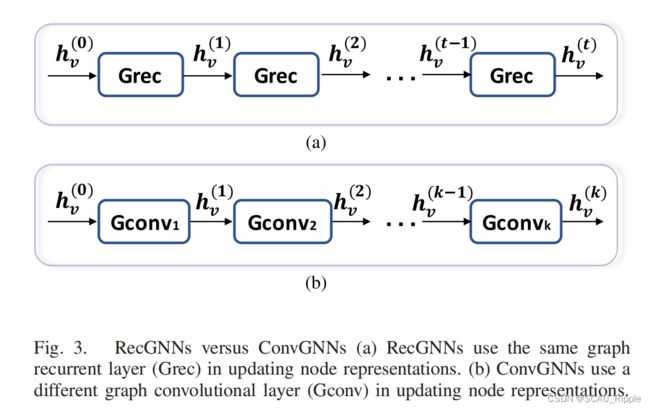
![]() 由于图卷积更高效、更方便地与其他神经网络复合,ConvGNN近年来得到了迅速的普及。ConvGNN分成两个类别:基于图谱的和基于空间的。基于图谱的方法定义图卷积为:从图信号处理的角度引入滤波器,其中图卷积运算被解释为从图信号中去除噪声。基于空间的方法继承了RecGNN的的想法,通过信息传递来定义图卷积。由于GCN弥合了基于谱的方法和基于空间的方法之间的差距,基于空间的方法由于其诱人的效率、灵活性和通用性,近年来发展迅速。
由于图卷积更高效、更方便地与其他神经网络复合,ConvGNN近年来得到了迅速的普及。ConvGNN分成两个类别:基于图谱的和基于空间的。基于图谱的方法定义图卷积为:从图信号处理的角度引入滤波器,其中图卷积运算被解释为从图信号中去除噪声。基于空间的方法继承了RecGNN的的想法,通过信息传递来定义图卷积。由于GCN弥合了基于谱的方法和基于空间的方法之间的差距,基于空间的方法由于其诱人的效率、灵活性和通用性,近年来发展迅速。
(A)Spectral-Based ConvGNN
基于光谱的方法在图形信号处理中有坚实的数学基础。假设图是无 向图。归一化的拉普拉斯矩阵是无向图的数学表达,定义如下:
向图。归一化的拉普拉斯矩阵是无向图的数学表达,定义如下:![]() ,其中
,其中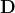 是节点度的对角矩阵,
是节点度的对角矩阵,![]() 。归一化图拉普拉斯矩阵具有实对称正半定的性质。
。归一化图拉普拉斯矩阵具有实对称正半定的性质。
根据这个性质,归一化拉普拉斯矩阵可以分解为:是根据特征值排序的特征矩阵,
![]() 是特征向量的对角矩阵,
是特征向量的对角矩阵,![]() 。归一化拉普拉斯矩阵的特征向量形成了一个正交空间,即
。归一化拉普拉斯矩阵的特征向量形成了一个正交空间,即![]() 。在图像处理中,一个图的信号
。在图像处理中,一个图的信号![]() 是一个图谱内所有结点的特征向量,其中
是一个图谱内所有结点的特征向量,其中 是第
是第 个结点的特征向量。图根据信号的傅里叶变换定义:
个结点的特征向量。图根据信号的傅里叶变换定义:![]() ,然后傅里叶逆变换为
,然后傅里叶逆变换为![]() ,其中
,其中![]() 表示图傅里叶变换的结果信号。图傅里叶变换将输入图信号投影到标准正交空间,其中的基由归一化图拉普拉斯特征向量构成。转换后的信号
表示图傅里叶变换的结果信号。图傅里叶变换将输入图信号投影到标准正交空间,其中的基由归一化图拉普拉斯特征向量构成。转换后的信号![]() 的元素是图形信号在新空间中的坐标,因此输入信号可以表示为
的元素是图形信号在新空间中的坐标,因此输入信号可以表示为 ,这正是反图傅里叶变换。至此,输入信号与滤波器
,这正是反图傅里叶变换。至此,输入信号与滤波器 的图卷积定义如下:
的图卷积定义如下:
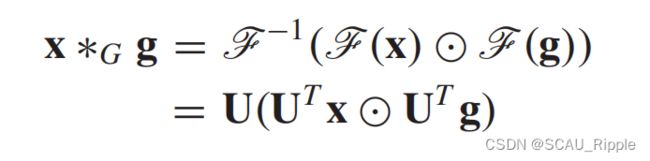
其中 表示逐个元素的点乘,如果我们定义一个滤波器
表示逐个元素的点乘,如果我们定义一个滤波器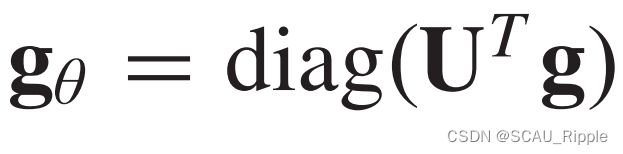 ,然后光谱图卷积就简化为:
,然后光谱图卷积就简化为:
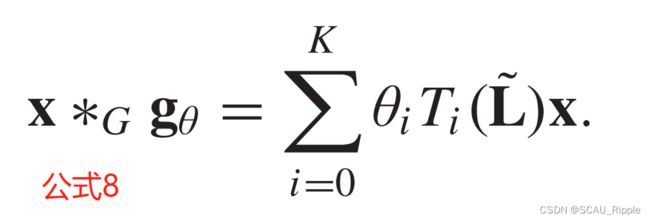
基于光谱的ConvGNN都是根据这个定义的,它们的不同之处在于滤波器![]() 的定义
的定义
Spectral CNN:假设滤波器 是一组可以可学习的参数并且从多通道考虑图信号。Spectral CNN的图卷积层定义如下:
是一组可以可学习的参数并且从多通道考虑图信号。Spectral CNN的图卷积层定义如下:
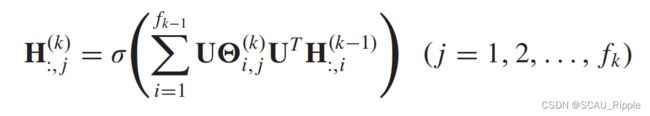
其中 是层数的编号,
是层数的编号,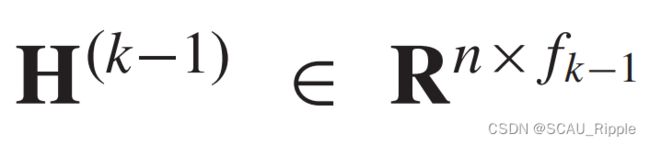 是输入的图信号,有
是输入的图信号,有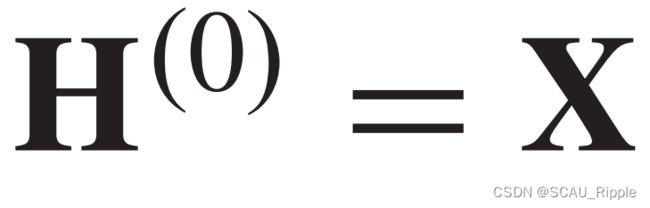 ,
,![]() 是输入的通道数量,
是输入的通道数量,![]() 是输出的通道数量。
是输出的通道数量。 是一个由可学习的参数构成的对角矩阵。由于拉普拉斯矩阵的特征分解,Spectral CNN面临三个局限性:(1)图的任何扰动都会导致根本特征的改变(2)所学习的滤波器是域相关的,这意味着它们不能应用于具有不同结构的图(3)需要
是一个由可学习的参数构成的对角矩阵。由于拉普拉斯矩阵的特征分解,Spectral CNN面临三个局限性:(1)图的任何扰动都会导致根本特征的改变(2)所学习的滤波器是域相关的,这意味着它们不能应用于具有不同结构的图(3)需要 的计算复杂度。
的计算复杂度。
Chebyshev spectral CNN (ChebNet):用特征值对角矩阵的切比雪夫多项式逼近滤波器![]() ,即
,即 ,其中
,其中![]() 的 取值范围是[-1,1]。由递归地定义了切比雪夫多项式:
的 取值范围是[-1,1]。由递归地定义了切比雪夫多项式:![]() 。图信号在滤波器
。图信号在滤波器![]() 下的卷积为:
下的卷积为:
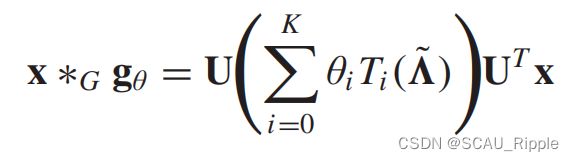
其中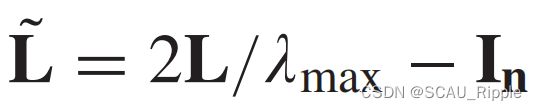 。对于
。对于 ,它能被上的归纳证明,ChebNet是以下形式:
,它能被上的归纳证明,ChebNet是以下形式:
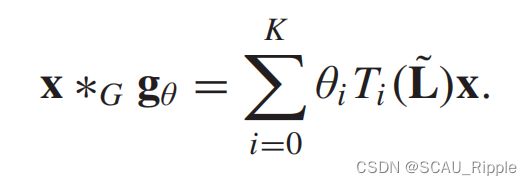
作为对Spectral CNN的改进,ChebNet定义的滤波器在空间上是本地化的,这意味着滤波器可以独立于图的大小提取局部特征。ChebNet的范围被映射到[-1,1]。
CayleyNet:进一步利用含参的有理复函数Cayley多项式捕获窄频带,CayleyNet的图卷积定义为:
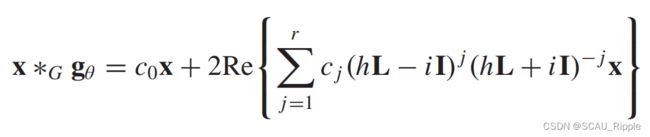
其中![]() 返回复数的实数部分,
返回复数的实数部分,![]() 是一个实系数,
是一个实系数, 是一个复数系数,是虚数,
是一个复数系数,是虚数, 为控制Cayley滤波器频谱的参数。在保留空间局部性的同时,CayleyNet表明ChebNet可以被认为是CayleyNet的一个特例。
为控制Cayley滤波器频谱的参数。在保留空间局部性的同时,CayleyNet表明ChebNet可以被认为是CayleyNet的一个特例。
Graph convolutional network (GCN) :引入了ChebNet的一阶近似。令 并且
并且![]() ,那么公式8则简化为
,那么公式8则简化为
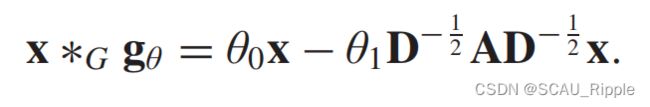
为了减少参数的数量并且避免过拟合,GCN进一步假设 于是图卷积变成如下的形式:
于是图卷积变成如下的形式:
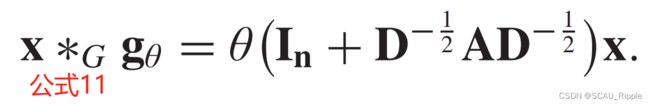
为了使得可以进行多通道的输入和输出,GCN将公式11修改为一个复合层,如下:
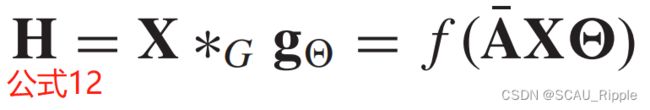
其中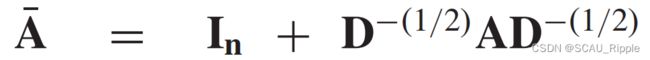 并且是一个激活函数。使用
并且是一个激活函数。使用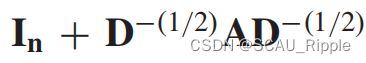 会导致GCN的数值不稳定。为了解决这个问题,GCN使用了一个归一化的技巧将替换为
会导致GCN的数值不稳定。为了解决这个问题,GCN使用了一个归一化的技巧将替换为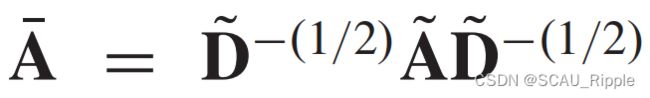 其中有
其中有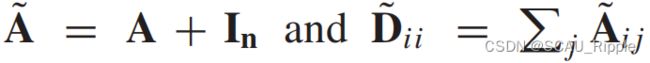 。作为一种基于光谱的方法,GCN也可以解释为一种基于空间的方法。从基于空间的角度来看,GCN可以被认为是从节点的邻域中聚合特征信息。公式12也可以换一种解释的方式:
。作为一种基于光谱的方法,GCN也可以解释为一种基于空间的方法。从基于空间的角度来看,GCN可以被认为是从节点的邻域中聚合特征信息。公式12也可以换一种解释的方式:
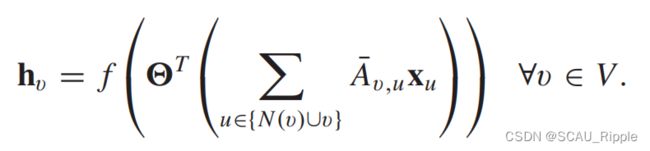
Adaptive GCN (AGCN):学习图邻接矩阵未指明的隐藏结构关系。它通过一个以两个节点的特征为输入的可学习距离函数,构造了一个所谓的剩余图邻接矩阵。
Dual GCN (DGCN):介绍了一种双图卷积架构,具有两个并行的图卷积层,这两个卷积层是参数共享的。他们使用归一化的邻接矩阵![]() 以及正点互信息(pointwise mutual information ,PPMI)矩阵,通过从图中采样的随机游动来捕获节点共存信息。PPMI矩阵定义如下:
以及正点互信息(pointwise mutual information ,PPMI)矩阵,通过从图中采样的随机游动来捕获节点共存信息。PPMI矩阵定义如下:
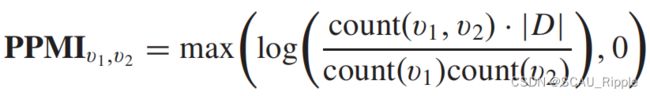
其中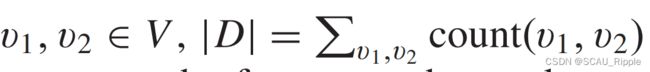 并且
并且![]() 函数返回节点和(/或)节点
函数返回节点和(/或)节点 在抽样随机游动中同时出现(/出现)的频率。DGCN通过集成双图卷积层的输出,对局部和全局结构信息进行编码,而不需要叠加多个图卷积层。
在抽样随机游动中同时出现(/出现)的频率。DGCN通过集成双图卷积层的输出,对局部和全局结构信息进行编码,而不需要叠加多个图卷积层。
(B)Spatial-Based ConvGNNs
与传统CNN对图像的卷积运算类似,基于空间的方法根据节点的空间关系定义图的卷积。图像可以被认为是一种特殊形式的图,其中每个像素代表一个节点。如图1(a)所示,每一个像素都与其相邻的像素直连。对一个3 × 3的patch进行滤波,对每个通道的中心节点和相邻节点的像素值进行加权平均。类似地,基于空间的图卷积将中心节点的表示与其相邻节点的表示进行卷积,得到更新后的中心节点表示,如图1(b)所示。从另一个角度来说,基于空间的ConvGNN利用了RecGNN的想法,即信息传播/消息传递。空间图卷积运算本质上是沿着边缘传播节点信息。
neural network for graphs (NN4G):与GNN*是并行提出的,这是第一个向着基于空间的ConvGNN的工作。与RecGNN的显著不同在于,NN4G通过每一层具有独立参数的复合神经结构学习图的相互依赖性。NN4G通过将结点的邻居信息直接求和来进行图卷积操作。也同样使用了残差链接和跳跃链接去储存每一层的信息。NN4G生成下一层的结点信息通过以下公式:
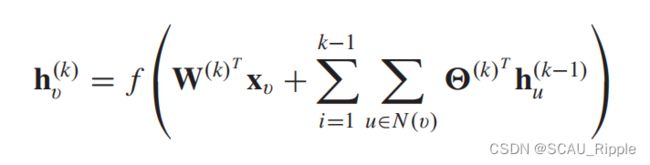
其中是激活函数,并且有 。上式可以被写成矩阵的形式:
。上式可以被写成矩阵的形式:
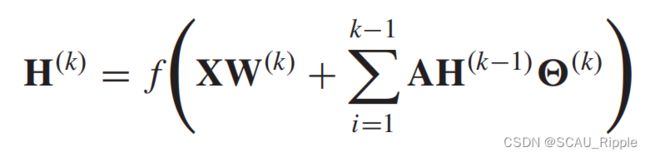
类似于GCN的形式。不同之处在于,NN4G使用了非归一化的邻接矩阵,这可能会潜在地导致隐藏的节点状态具有非常不同的规模。
Contextual graph Markov model (CGMM):受到NN4G的启发,提出了一个概率模型。维持空间局部性的同时,GGMM也会收益于概率可解释性的优点。
Diffusion CNN (DCNN):将图卷积视为那个腐蚀过程。它假设信息以一定的转移概率从一个节点转移到它的相邻节点,使信息分布在几轮后达到平衡。DCNN对腐蚀图卷积(diffusion graph convolution ,DGC)的定义如下:
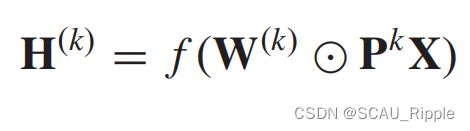
其中是一个激活函数,概率迁移矩阵 是由
是由 计算得到。值得注意的是,在DCNN中,潜在特征矩阵
计算得到。值得注意的是,在DCNN中,潜在特征矩阵![]() 的维度与输入的特征矩阵的维度相同,并且它不是它前一个潜在特征矩阵
的维度与输入的特征矩阵的维度相同,并且它不是它前一个潜在特征矩阵![]() 的一个函数。DCNN将
的一个函数。DCNN将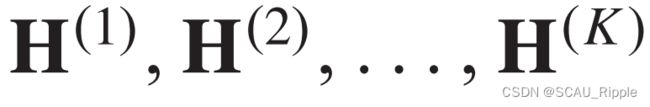 拼接起来作为模型的最后输出。
拼接起来作为模型的最后输出。
DGC:由于扩散过程的平稳分布是概率转移矩阵幂级数的求和,DGC对每个扩散步骤的输出求和,而不是串联。DGC定义如下:
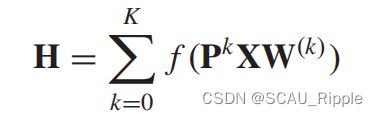
其中 并且是一个激活函数。
并且是一个激活函数。
PGC-DGCNN:利用转移概率矩阵的幂意味着远邻对中心节点贡献的信息很少。PGC-DGCNN在最短路径的基础上增加远端邻居的贡献。定义一个最短距离近邻矩阵![]() 。如果从结点到结点的距离是
。如果从结点到结点的距离是 ,那么
,那么![]() 否则为0。用超参
否则为0。用超参 去控制感受野的大小,PGC-DGCNN提出了如下的一种卷积操作:
去控制感受野的大小,PGC-DGCNN提出了如下的一种卷积操作:
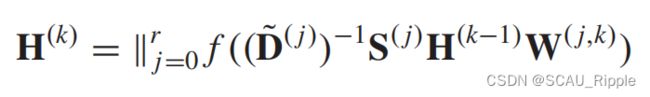
其中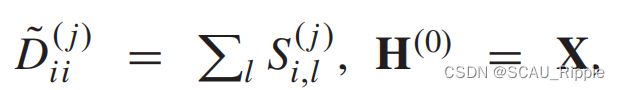 ,然后
,然后![]() 代表向量的链接操作。缺点是时间复杂度可能达到
代表向量的链接操作。缺点是时间复杂度可能达到
Partition graph convolution (PGC):根据不局限于最短路径的特定条件,将节点的邻居结点划分为 个组。PGC根据预定义的邻居结点构建个邻接矩阵。然后,PGC将具有不同参数矩阵的GCN应用到每个邻居组,并对结果求和:
个组。PGC根据预定义的邻居结点构建个邻接矩阵。然后,PGC将具有不同参数矩阵的GCN应用到每个邻居组,并对结果求和:
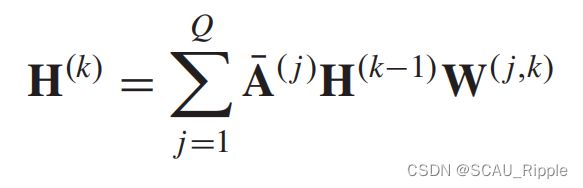
其中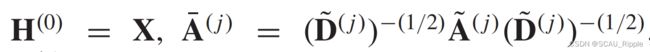 并且有
并且有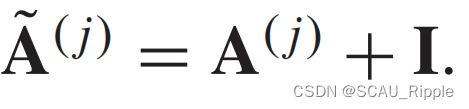 。
。
message-passing neural network (MPNN):提出了一个基于空间的ConvGNN的通用框架。将图卷积操作视为一个信息传递的过程,这个过程中信息从一个结点直接传递到另一个结点。MPNN执行K步的信息传递迭代使得信息可以传递得更远。信息传递函数(即,空间图卷积)定义如下:
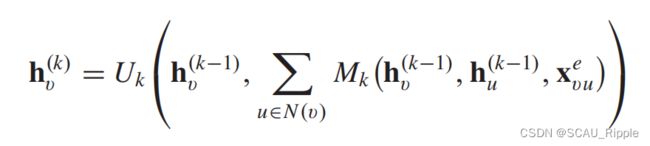
其中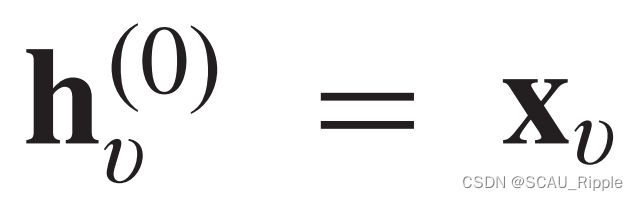 ,
,![]() 和
和![]() 都是有可学习参数的函数。在得到每个节点的隐藏表示之后,
都是有可学习参数的函数。在得到每个节点的隐藏表示之后,![]() 可以被传递至输出层做结点级的预测任务或者是传递至readout层做图级的预测任务。readout函数基于每一个潜在特征表示去生成一整个图的表示。定义如下:
可以被传递至输出层做结点级的预测任务或者是传递至readout层做图级的预测任务。readout函数基于每一个潜在特征表示去生成一整个图的表示。定义如下:
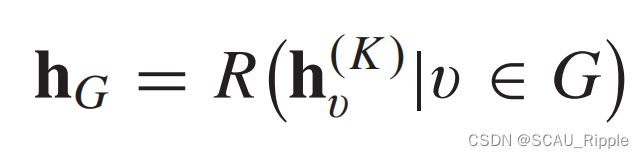
其中,![]() 代表readout函数。MPNN可以覆盖很多现有的GNN方法,通过假设
代表readout函数。MPNN可以覆盖很多现有的GNN方法,通过假设![]() ,
,![]()
和 ![]() 有不同的形式。
有不同的形式。
graph isomorphism network (GIN):GIN发现基于MPNN的方法没办法根据生成的嵌入区别不同的图结构。为解决这个问题,GIN根据可学习的参数![]() 调整中心结点的权重。在图卷积操作上表现为:
调整中心结点的权重。在图卷积操作上表现为:
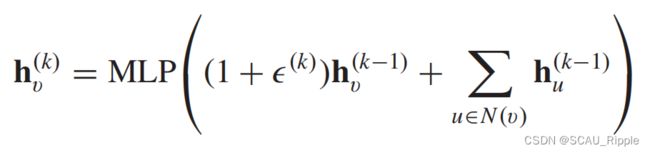
GraphSage:为解决邻居结点数量过多,无法全部利用的问题。GraphSage通过采样的方法获得一定量固定数目的邻居结点。在图卷积操作上表现为:
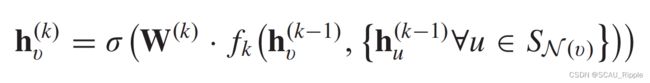
其中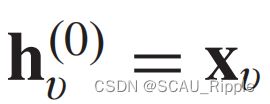 ,
,![]() 是聚合函数,
是聚合函数,![]() 是随机采样结点的邻居结点。聚合函数对于节点排序的排列应该是不变的,比如mean、sum或max函数。
是随机采样结点的邻居结点。聚合函数对于节点排序的排列应该是不变的,比如mean、sum或max函数。
Graph attention network (GAT):GAT假设相邻节点对中心节点的贡献既不像GraphSage那样完全相同,也不像GCN那样预先确定(两者区别如图四所示)。
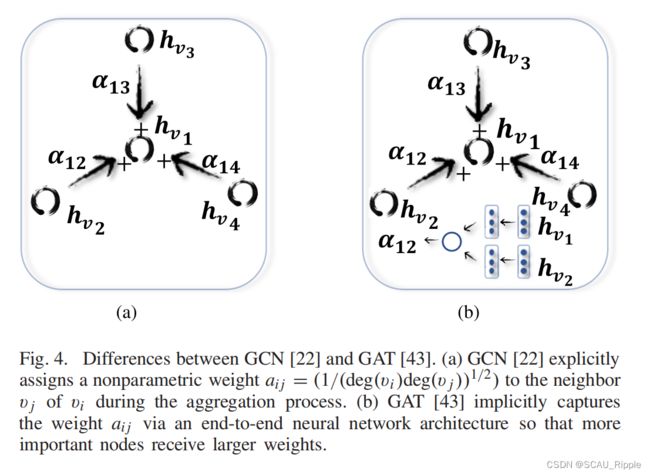
GAT加入了注意力机制去学习两个相连结点的相关权重。图卷积操作如下:
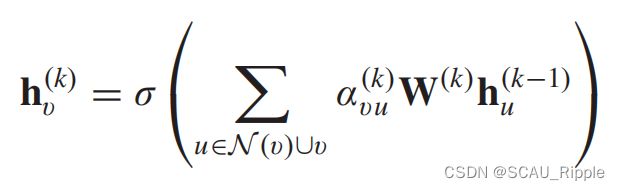
其中 ,注意力参数
,注意力参数![]() 衡量结点和其邻居结点的链接强度:
衡量结点和其邻居结点的链接强度:
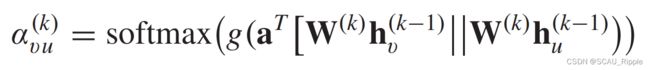
其中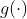 是LeakyReLU激活函数,
是LeakyReLU激活函数,![]() 是一个由可学习参数组成的向量。Softmax函数保证结点的所有邻居点的注意力权重都求和。GAT进一步采用了多头注意力来提高模型的表达能力。
是一个由可学习参数组成的向量。Softmax函数保证结点的所有邻居点的注意力权重都求和。GAT进一步采用了多头注意力来提高模型的表达能力。
gated attention network (GAAN):GAT认为所有的注意力头的贡献是相同的。GAAN引入一种自注意力机制来对每一个注意力头计算一个注意力得分。
GeniePath:进一步提出了一种类似LSTM的门控机制来控制跨图卷积层的信息流。
Mixture model network (MoNet) :采用了一种不同的方法,为节点的邻居分配不同的权值。它引入节点伪坐标来确定节点与其相邻节点之间的相对位置。一旦两个结点的相对位置是已知的,用一个权重函数会将两个结点的相对位置映射到相对权重上。这种过程下,图滤波器的参数可以在不同的位置共享。MoNet有很多推广形式。MoNet还提出了一个具有可学习参数的高斯核来自适应学习权函数。
另一种不同的方法是,根据特定的标准对节点的邻居进行排名,并将每个排名与可学习的权重关联起来,从而实现不同位置的权重共享。
PATCHY-SAN:根据图的标签对邻居结点进行排序,并且选择top- 邻居。图标签本质上是节点分数,可以通过节点度、中心性和Weisfeiler - Lehman (WL)颜色导出。由于现在每个节点都有固定数量的有序邻居,因此可以将图结构数据转换为网格结构数据。PATCHY-SAN使用标准的1-D卷积滤波器去聚合邻居信息,滤波器的参数与结点的邻居顺序相关。PATCHY-SAN的排序准则只考虑图结构,数据处理的计算量较大。
邻居。图标签本质上是节点分数,可以通过节点度、中心性和Weisfeiler - Lehman (WL)颜色导出。由于现在每个节点都有固定数量的有序邻居,因此可以将图结构数据转换为网格结构数据。PATCHY-SAN使用标准的1-D卷积滤波器去聚合邻居信息,滤波器的参数与结点的邻居顺序相关。PATCHY-SAN的排序准则只考虑图结构,数据处理的计算量较大。
Large-scale GCN (LGCN):LGCN根据结点的特征信息来对结点的邻居进行排序。对于每个结点,LGCN生成一个特征矩阵,该矩阵由结点的邻居结点组成,并沿着每一列排序这个特征矩阵。将排序后的特征矩阵的前行作为中心节点的输入数据。
1)对训练效率的提升
训练ConvGNN往往需要将一整个图的数据点和结点的状态输入内存中,这导致对内存的要求很高。
GraphSage:为了节省内存,GraphSage提出了batch-training的方法,通过K步的固定容量递归来扩展根节点的邻域,对每个节点的根树进行采样。对于每个采样树,GraphSage通过从下到上分层地聚合隐藏节点表示来计算根节点的隐藏表示。
Fast learning with GCN (FastGCN):为每个图卷积层采样固定数量的节点,而不是GraphSage那样为每个节点采样固定数量的邻居。它将图卷积解释为概率测度下节点嵌入函数的积分变换。由于FastGCN对每一层独立采样节点,因此层之间的连接可能是稀疏的。
Huang等人提出了一种自适应逐层抽样方法,下层的节点抽样以上层为条件。与FastGCN相比,该方法采用了更为复杂的采样方案,但取得了更高的精度。
stochastic training of GCNs (StoGCN):减小图卷积的感受野到一个随机的小尺寸,利用历史结点特征作为控制变量。
Cluster-GCN:使用图聚类算法采样子图,然后在采样的子图中间进行图卷积操作。由于邻域搜索也限制在采样子图中,Cluster-GCN能够处理更大的图,同时使用更深入的架构,花费更短的时间和更少的内存。
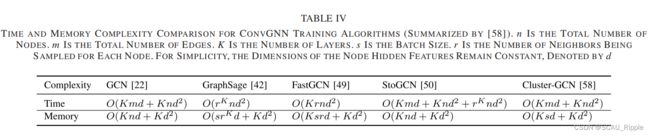
2)基于光谱模型与基于空间模型对比
基于光谱的模型在信号处理学中有坚实的理论基础。通过设计不同的图滤波器就可以构建新的ConvGNN模型。然而,由于效率、通用性和灵活性问题,空间模型优于光谱模型。
(1)效率:光谱模型要么需要进行特征向量计算,要么同时处理整个图。空间模型对大型图具有更强的可伸缩性,因为它们通过信息传播直接在图域中执行卷积。计算可以在一个batch节点中执行,而不是在整个图中
(2)通用性:依赖于傅立叶基的光谱模型很难推广到新的图。假设图形是固定的。图的任何扰动都会导致图的基本特征的改变。另一方面,基于空间的模型在每个节点上局部执行图卷积,其中的权值可以很容易地跨不同的位置和结构共享。
(3)灵活性:基于光谱的模型局限于对无向图的操作。基于空间的模型在处理多源图输入时更加灵活,如边输入、有向图、签名图和异构图,因为这些图输入可以合并到易聚合函数中。
(C)图池化模块
在GNN生成结点特征后,我们可以将结点特征用于最后的任务。但是直接对结点特征进行计算会导致计算开销比较大,于是引入了下采样策略。
根据目标函数的不同,策略的名称也不一样:
(1)pooling操作:目标是通过下采样的方式减小参数的尺寸,生成更小的特征并且避免过拟合,排列不变性和计算复杂度问题
(2)readout操作:主要用来生成基于结点表征的图级的表达。
在本节中,使用池化来介绍应用于GNN的各种下采样策略。在早期的一些研究中,图粗化算法使用特征分解来根据拓扑结构对图进行粗化。但是这些方法往往是非常耗时的。
Graclus算法:是一种特征分解的替代方法,用来计算原始图的聚类。
目前,由于在池化窗口中计算mean/max/sum的速度很快,因此mean/max/sum池化是实现下采样最原始、最有效的方法

其中 是最后一层卷积层的编号。
是最后一层卷积层的编号。
Henaff等人表明,在网络的开始执行一个简单的max/mean池化对于降低图域的维数和减轻昂贵的图傅里叶变换操作的代价尤其重要。
甚至在注意力机制中,降维操作并不是必须的,可以无视图的尺寸生成一个固定尺寸的嵌入。
Vinyals等人提出了Set2Set方法来产生随输入大小变化的内存然后,它实现了一个LSTM,该LSTM打算在应用减少之前将与顺序相关的信息集成到内存嵌入中,否则将破坏该信息。
Defferrard等人以另一种方式解决了这个问题,以一种有意义的方式重新排列图的节点。他们在他们的ChebNet中提出了一种有效的池化策略。首先通过Graclus算法将输入图粗化为多个层次,粗化后,输入图和粗化后的图的节点重新排列成一棵平衡二叉树。从下到上任意地聚合平衡二叉树会将相似的节点排列在一起。池化这样一个重新排列的信号比池化原始信号效率高得多。
Zhang等人提出了带有类似池化策略的DGCNN,名为SortPooling,通过按有意义的顺序重新排列节点来执行池化。与ChebNet不同之处在于,DGCNN在图的内部根据结点的结构角色对结点进行排序。将空间图卷积得到的图的无序节点特征视为连续的WL color,然后由此对节点进行排序。除了对节点特征进行排序外,它还通过截断/扩展节点特征矩阵将图的大小统一为。如果![]() ,则所有的
,则所有的![]() 行会被丢弃;否则,添加
行会被丢弃;否则,添加![]() 行的零向量。
行的零向量。
上面提到的池化操作,主要考虑了图特征但是忽略了图的结构信息。
differentiable pooling (DiffPool) :生成层次化的图谱特征信息。DiffPool不是简单地将图中的节点聚类,而是在第层学习的聚类分配矩阵![]() ,有
,有![]() ,其中
,其中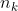 是第层的节点数。
是第层的节点数。![]() 中的概率值,是利用节点特征和拓扑结构生成的,公式如下:
中的概率值,是利用节点特征和拓扑结构生成的,公式如下:
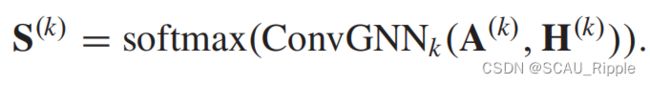
核心思想是学习一个复合的结点分配,同时考虑图的特征信息和拓扑结构。DiffPool的缺点是池化后会生成稠密图,计算消耗会增加。
SAGPool:同时考虑结点特征和图的拓扑结构,并且以自注意力的方式学习池化。
(D)理论方面的探讨
(1)感受野(接受域)的形状:节点的接受域是节点的集合,它有助于确定其最终节点表示。在合成多个空间图卷积层时,节点的接收域每次都向前增长一步。在空间图卷积层中,存在有限个数的结点,这些结点的接受域可以覆盖整个图谱。结论是,ConvGNN可以通过堆叠局部图卷积层来提取全局信息。
(2)VC维度:VC维度是衡量模型复杂性的一个指标,定义为一个模型能被击碎的最大结点数量。给定模型的参数数量 和结点数量
和结点数量 ,Scarsilli等人提出,GNN*如果采用sigmoid或者正切双曲激活(tangent hyperbolic activation)则VC维度为
,Scarsilli等人提出,GNN*如果采用sigmoid或者正切双曲激活(tangent hyperbolic activation)则VC维度为![]() ,如果使用分段多项式激活函数(piecewise polynomial activation function)则为
,如果使用分段多项式激活函数(piecewise polynomial activation function)则为![]() 。结论是在参数数量和结点数量的情况下,GNN*的模型复杂度在使用激活函数的情况下会变得复杂。
。结论是在参数数量和结点数量的情况下,GNN*的模型复杂度在使用激活函数的情况下会变得复杂。
(3)图的同构(Graph Isomorphism):如果两个图在拓扑上是相同的,那么它们就是同构的。给定两个非同构的图谱![]() ,Xu等人证明了如果GNN将
,Xu等人证明了如果GNN将![]() 映射到不同的嵌入中,通过同构性的WL检验,可以确定这两个图是非同构的。这个特性在常用的GNN中都会出现。Xu等人进一步证明了如果GNN的聚集函数和readout函数都是单射的,则GNN在区分不同图方面的能力不逊于WL检验。
映射到不同的嵌入中,通过同构性的WL检验,可以确定这两个图是非同构的。这个特性在常用的GNN中都会出现。Xu等人进一步证明了如果GNN的聚集函数和readout函数都是单射的,则GNN在区分不同图方面的能力不逊于WL检验。
(4)等方差和不变性:在执行节点级任务时,GNN必须是一个等变函数,在执行图级任务时必须是一个不变函数。在结点级的任务上,用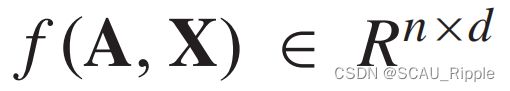 表示一个GNN,用
表示一个GNN,用 表示任何改变结点顺序的置换矩阵。如果GNN满足
表示任何改变结点顺序的置换矩阵。如果GNN满足![]() ,则它是等变的。对于图级的任务,有。如果GNN满足
,则它是等变的。对于图级的任务,有。如果GNN满足![]() ,则它是等变的。为了实现等方差或不变性,GNN的分量必须对节点排序不变性。Maron等人从理论上研究了图数据的排列不变和等变线性层的特征。
,则它是等变的。为了实现等方差或不变性,GNN的分量必须对节点排序不变性。Maron等人从理论上研究了图数据的排列不变和等变线性层的特征。
(5)普遍的近似:众所周知,具有一个隐层的MLP前馈神经网络可以逼近任何波莱尔可测函数(Borel measurable function)。Hammer等证明级联相关可以近似具有结构化输出的函数。Scarselli等人证明了RecGNN可以近似在任何精度上保持展开等价的任何函数。如果两个节点的展开树相同,则为展开等价,其中一个节点的展开树是通过在一定深度上迭代扩展节点的邻域来构建的。Xu等人证明了消息传递框架下的ConvGNN并不是定义在多集上的连续函数的通用逼近器。Maron等人证明了不变图网络可以近似定义在图上的任意不变函数。
图自编码器
图自编码器(Graph AutoEncoder,GAE)是一种深度神经结构,可以将结点映射到潜在特征空间以及从特征空间将图信息进行解码。GAE可以用来学习网络嵌入或者生成新的图谱,主要的GAE由表五所示,如下
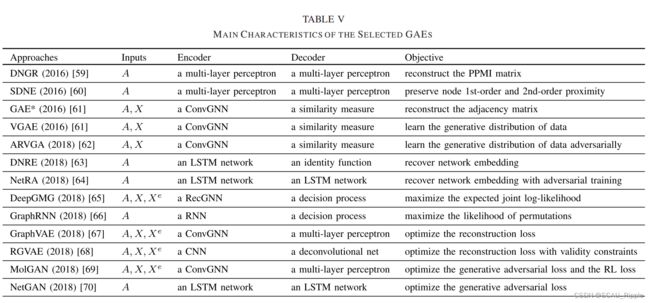
本文把GAE分成两个类别:网络嵌入和图谱生成
(1)网络嵌入
网络嵌入是一种低维的向量,该向量保存的结点的拓扑结构信息。GAE通过编码器来提取网络的特征嵌入,并且用一个解码器来迫使网络嵌入保存图拓扑结构,比如PPMI矩阵和邻接矩阵。早期的方法往往使用多层感知机(MLP)来构建GAE。
Deep neural networks for graph representations (DNGRs):用一个堆叠的降噪自编码器来对PPMI进行编码和解码。
structural deep network embedding (SDNE):采用堆叠式自动编码器,同时保持节点的一阶邻近性和二阶邻近性。对编码器的输出和解码器的输出分别提出了一种损失函数。对编码器设计的损失函数使得网络通过最小化结点嵌入与其邻居之间的距离,来保存结点的一阶邻接性,一阶损失![]() 定义如下:
定义如下:
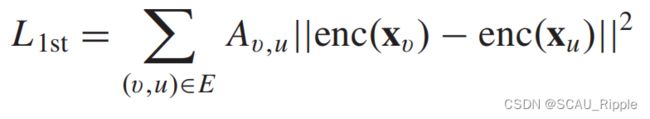
其中![]() ,
,![]() 是一个由单层MLP构成的编码器。对解码器设计的损失本质上为一种重构误差,
是一个由单层MLP构成的编码器。对解码器设计的损失本质上为一种重构误差,![]() 定义如下
定义如下
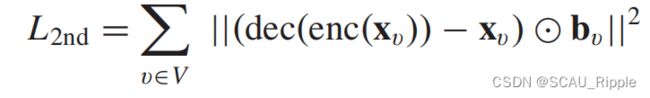
其中如果![]() 则
则![]() ,否则
,否则![]() ,
,![]() 是一个由单层MLP构成的解码器
是一个由单层MLP构成的解码器
DNGR ,SDNE:只考虑了结点对的结构信息,却忽略了结点可能存在的特征信息。GAE*(特指GAE这个算法,而不是泛指的大类)利用GCN来同时编码结点的结构信息和结点的特征信息。GAE*由两个图卷积层构成,公式如下
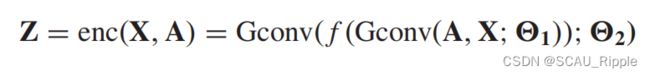
其中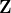 表示网络对一个图谱的嵌入特征矩阵,表示ReLU激活函数
表示网络对一个图谱的嵌入特征矩阵,表示ReLU激活函数![]() 表示图卷积层。GAE*的解码器目标是通过重构图邻接矩阵来从图谱嵌入中解码出相关信息,公式如下:
表示图卷积层。GAE*的解码器目标是通过重构图邻接矩阵来从图谱嵌入中解码出相关信息,公式如下:
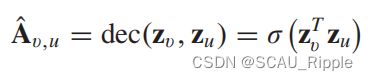
其中![]() 是结点的嵌入。GAE*是根据真实邻接矩阵和重构的邻接矩阵
是结点的嵌入。GAE*是根据真实邻接矩阵和重构的邻接矩阵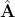 计算负的交叉熵进行训练的。
计算负的交叉熵进行训练的。
简单地重构图邻接矩阵可能会由于自编码器的容量而导致过拟合。
Variational GAE (VGAE):VGAE优化变分最低下界 ,公式如下:
,公式如下:
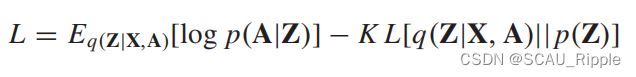
其中,![]() 代表KL散度,衡量两个分布之间的距离。
代表KL散度,衡量两个分布之间的距离。![]() 是高斯先验分布,有
是高斯先验分布,有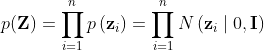 ,
,![]() ,以及
,以及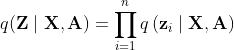 在
在![]() 的条件下。均值向量
的条件下。均值向量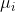 是编码器的第行输出,
是编码器的第行输出,![]() 是由与另一个编码器的相似性推导出的结果。VGAE假设经验分布
是由与另一个编码器的相似性推导出的结果。VGAE假设经验分布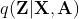 应该与先验分布
应该与先验分布![]() 尽可能靠近。
尽可能靠近。
adversarially regularized VGAE (ARVGA):为了进一步迫使经验分布应该与先验分布![]() 靠近,使用了生成对抗网络(GAN)。ARVGA目标是训练一个编码器,该编码器的生成的经验分布难以与先验分布
靠近,使用了生成对抗网络(GAN)。ARVGA目标是训练一个编码器,该编码器的生成的经验分布难以与先验分布![]() 区分开来。GraphSage
区分开来。GraphSage
GraphSage:与GAE*相似,使用两层的GCL来编码结点特征。GraphSage没有使用重构误差,而是展示了通过以下的损失函数,两个结点之间的关系可以被负采样保存:
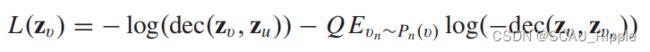
其中是结点的邻居结点,结点 是距离结点较远的结点,并且结点是从负采样分布
是距离结点较远的结点,并且结点是从负采样分布![]() 中采样的,是负样本的数量。这个损失函数本质上强制近节点具有相似的表示,远节点具有不同的表示。
中采样的,是负样本的数量。这个损失函数本质上强制近节点具有相似的表示,远节点具有不同的表示。
DGI:通过最大化局部互信息来驱动局部网络嵌入以获取全局结构信息。它在实验上显示了对GraphSage的明显改进。
上面提到的算法,基本是通过解决一个链接预测问题来训练网络。然而,图的稀疏性,导致了正节点对的数量远小于负节点对的数量。为了缓解学习网络嵌入中的数据稀疏问题,另一些工作通过随机排列或随机游走将一个图转换成序列。这种转换后,那些适用于序列的深度学习方法可以直接用于图的处理。
Deep recursive network embedding (DRNE):假设节点的网络嵌入应该近似于其邻居网络嵌入的集合。利用长短期记忆网络(Long Short-Term Memory,LSTM)去聚合结点的邻居结点。DRNE的重构误差如下:
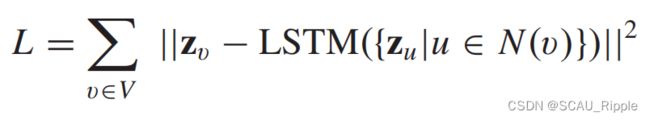
其中![]() 是结点的网络嵌入,通过一个字典的查询操作获得,然后LSTM的网络将关于结点的邻居结点的随机序列作为网络输入。DRNE通过LSTM网络隐式学习网络嵌入,而不是使用LSTM网络生成网络嵌入。它避免了LSTM网络对节点序列的排列不是不变的问题。
是结点的网络嵌入,通过一个字典的查询操作获得,然后LSTM的网络将关于结点的邻居结点的随机序列作为网络输入。DRNE通过LSTM网络隐式学习网络嵌入,而不是使用LSTM网络生成网络嵌入。它避免了LSTM网络对节点序列的排列不是不变的问题。
Network representations with adversarially regularized autoencoders (NetRAs):提出了一个图编码器——解码器框架以及一个普适的损失函数,定义如下
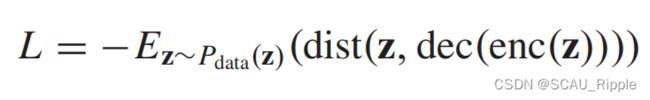
其中![]() 衡量结点嵌入
衡量结点嵌入![]() 与其重构之间的距离。NetRA的编码器和解码器是带随机游走的LSTM网络,将每一个结点
与其重构之间的距离。NetRA的编码器和解码器是带随机游走的LSTM网络,将每一个结点![]() 作为输入。与ARVGA相似,NetRA通过对抗训练得到一个先验分布,然后用这个先验分布来对学习到的网络嵌入做一个正则化。虽然NetRA忽略了LSTM网络的节点排列变化问题,但实验结果验证了NetRA的有效性。
作为输入。与ARVGA相似,NetRA通过对抗训练得到一个先验分布,然后用这个先验分布来对学习到的网络嵌入做一个正则化。虽然NetRA忽略了LSTM网络的节点排列变化问题,但实验结果验证了NetRA的有效性。
(2)图谱生成
对于多个图,GAEs能够通过将图编码为隐藏表示并解码给定隐藏表示的图结构来学习图的生成分布。大多数用于图生成的GAEs都是为了解决分子图生成问题而设计的,在药物发现中具有很高的实用价值。
SMILES:用CNN和RNN分别作为编码器和解码器。虽然这些方法是适用于特定领域的,但可选的解决方案适用于一般图,通过迭代地向增长图添加节点和边,直到满足某个条件
Deep generative model of graphs (DeepGMG):假设图的概率是所有结点的概率之和
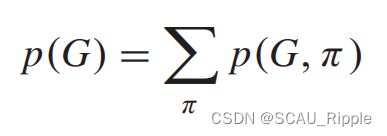
其中 表示结点的顺序。它捕捉了图谱中所有结点和边的复杂的联合概率分布。DeepGMG通过一系列决策生成图,即是否添加节点、添加哪个节点、是否添加边、连接哪个节点到新节点。生成边和结点的决策过程是取决于RecGNN更新的图谱中的结点状态和图谱的状态。
表示结点的顺序。它捕捉了图谱中所有结点和边的复杂的联合概率分布。DeepGMG通过一系列决策生成图,即是否添加节点、添加哪个节点、是否添加边、连接哪个节点到新节点。生成边和结点的决策过程是取决于RecGNN更新的图谱中的结点状态和图谱的状态。
GraphRNN:提出了在模型生成结点和边的过程中,图级的RNN和边级的RNN。图级的RNN没次向结点队列中添加新的结点,如此同时,边级的RNN生成一个二进制的队列表示新结点和旧结点之间的链接关系。
Graph variational autoencoder (GraphVAE):将结点和边视为独立的随机变量。假设有,由编码器定义的后验分布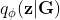 和由解码器定义的生成分布
和由解码器定义的生成分布![]() ,图变分自编码器优化变分下界
,图变分自编码器优化变分下界
![]()
其中![]() 是从一个高斯先验中生成的。
是从一个高斯先验中生成的。 和
和 是可学习的参数。用ConvGNN作为编码器,一个简单的MLP做为解码器,GraphVAE输出一个生成图谱及其邻接矩阵,结点特征以及边特征。
是可学习的参数。用ConvGNN作为编码器,一个简单的MLP做为解码器,GraphVAE输出一个生成图谱及其邻接矩阵,结点特征以及边特征。
Regularized GraphVAE(RGVAE):进一步提升对GraphVAE的有效性约束,使解码器的输出分布规范化。
Molecular GAN (MolGAN):ConvGNN和GAN,以及强化学习的结合,目标是生成有目标属性的图谱。MolGAN由生成带有特征矩阵的假图谱的生成器和目的是区分假图谱的判别器构成。还一个一个反馈网络和判别器一起,鼓励生成的图谱更加具有具体的特征。
NetGAN:将LSTM与Wasserstein GAN结合,从随机游走中生成图谱。NetGAN训练一个生成器,通过LSTM网络去生成合理的随机游走,并且要求判别器去判断随机游走的真伪。训练后,通过归一化基于生成器产生的随机漫步计算的节点共现矩阵,得到一个新的图谱
时间-空间图神经网络
图谱在现实用的应用往往图结构和图输入都是动态变化的。STGNN在捕捉图的变化中非常重要。这种类型的模型往往需要掌握动态的结点输入,同时假设结点之间的联系是独立的。STGNN同时捕捉图的时间和空间依赖性。STGNN的任务是预测未来结点的权值\标签,或者是预测时空图的标签。STGNN可以分为两类:基于RNN和基于CNN。
基于RNN的方法
大多数基于RNN的方法都是通过过滤输入来捕捉时空依赖性,并且使用图卷积来传递隐藏结点的状态。假设有一个简单的RNN如下所示:
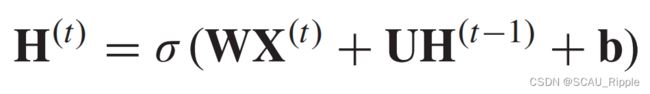
其中 是结点的在
是结点的在 时刻的特征矩阵。在插入图卷积操作后,公式变成如下形式
时刻的特征矩阵。在插入图卷积操作后,公式变成如下形式
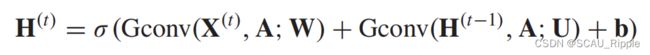
其中![]() 代表图卷积层。
代表图卷积层。
Graph convolutional recurrent network (GCRN):将LTSM和ChebNet结合。
Diffusion convolutional RNN (DCRNN):包含了一个扩散图卷积层(diffusion graph convolutional layer)的GRU网络。此外,DCRNN还应用了一个编码器——解码器的框架来预测未来步的结点值。
Structural-RNN:提出了一个循环框架来预测每个时间步的节点标签。这个模型包含两种RNN,一个node-RNN一个edge-RNN,每个结点和边的信息通过这两个RNN分别进行传递。为了包含空间信息,node-RNN的输入为edge-RNN的输出。因为不同的结点和边的RNN会提高模型的复杂性,该模型将结点和边分割成不同的语义类作为替代。同一个语义组的结点或边共用一个RNN,这可以省下很多计算资源。
基于CNN的方法
基于RNN的方法往往有时间开销大和梯度消失两个问题。作为一种替代解法,基于CNN的方法用一种非循环的方式应对时空图,这有平行计算、稳定的梯度、对内存要求低的好处。在图2(d)中所示。基于CNN的方法交错使用1-D-CNN层与图卷积层,去分别学习时间和空间的依赖性。假设输入到STGNN的是一个张量 ,并且1-D-CNN层沿着时间轴在
,并且1-D-CNN层沿着时间轴在![]() 上滑动,聚合每个节点的时间信息,而图卷积层在每个时间步上对
上滑动,聚合每个节点的时间信息,而图卷积层在每个时间步上对![]() 进行运算,聚合空间信息。
进行运算,聚合空间信息。
CGCN:交替使用1-D卷积层和ChebNet活GCN层。通过堆叠一个门控的1-D卷积层,一个图卷积层,和另一个门控1-D卷积层在一个序列中构建时间-空间块。
ST-GCN:使用一个1-D的卷积层和一个PGC层整合了一个时空块。
早期的方法是使用一个预定义的图结构。他们假设预定义的图结构反映了节点之间真正的依赖关系。然而,在一个时空环境中有许多图数据的快照,可以从数据中自动学习潜在的静态图结构。
Graph WaveNet:提出了一个自适应邻接矩阵来实现图的卷积。自适应邻接矩阵定义如下:
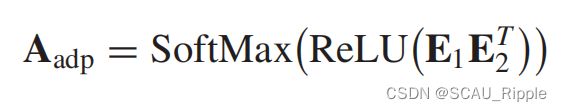
其中softmax函数在在行维度上计算的,![]() 代表了源结点嵌入,
代表了源结点嵌入,![]() 代表了目标结点的嵌入。通过重复应用
代表了目标结点的嵌入。通过重复应用![]() ,可以得到源结点和目标结点的依赖权重。通过使用一个复杂的基于CNN的时空神经网络,GraphWaveNet在没有邻接矩阵的情况下也取得了很好的效果。
,可以得到源结点和目标结点的依赖权重。通过使用一个复杂的基于CNN的时空神经网络,GraphWaveNet在没有邻接矩阵的情况下也取得了很好的效果。
学习潜在的静态空间依赖性可以帮助研究人员发现网络中不同实体之间可解释的和稳定的相关性。在一些算法中,学习潜在动态的时空依赖性会进一步提升模型的准确性。
GaAN:通过基于RNN的方法应用了注意力机制学习动态的空间依赖。在给定两个连接节点的当前节点输入的情况下,使用注意函数更新两个连接节点之间的边权值。
ASTGCN:用一个基于CNN的方法,进一步包括了一个空间注意力函数和一个时间注意力函数,去学习潜在的动态空间依赖和动态时间依赖。
应用
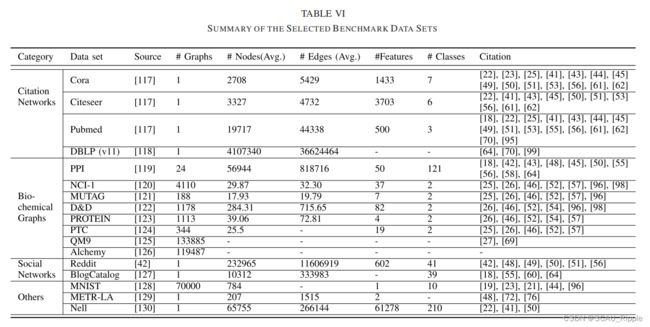
数据集
主要包括四种:引文网络,生化网络,设计网络和其他
评估和开源实现
主要分为结点分类和图分类
结点分类
首先,在所有实验中使用相同的train/valid/test分割会低估泛化误差。
其次,不同的方法采用不同的训练技术,如超参数调整、参数初始化、学习速率衰减和早期停止
图分类
往往使用交叉验证来评估模型。一个经常遇到的问题是,每个折叠的外部测试集既用于模型选择,又用于模型评估。应用分成十份的交叉验证,来获得模型泛化性能的估计,并使用90%/10%的训练/验证分割进行模型选择的内部抵抗技术
部分应用
(1)计算机视觉(2)自然语言处理(3)交通(4)推荐系统(5)化学(6)其他
未来研究方向
(1)模型深度(2)可伸缩性的权衡(3)异构图应用(4)动态性
论文好句摘抄(个人向)
(1)Deep learning has revolutionized many machine learning tasks in recent years, ranging from image classifification and video processing to speech recognition and natural language understanding.
(2)The complexity of graph data has imposed signifificant challenges on the existing machine learning algorithms.
(3)The aforementioned pooling methods mainly consider graph features and ignore the structural information of graphs.